Constraint Tax in Open-Weight LLMs: An Empirical Study of Tool Calling Suppression Under Structured Output Constraints
Pith reviewed 2026-06-25 20:56 UTC · model grok-4.3
The pith
Joint tool calling and JSON schema constraints in open-weight LLMs cause models to stop invoking tools while still producing schema-compliant output.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
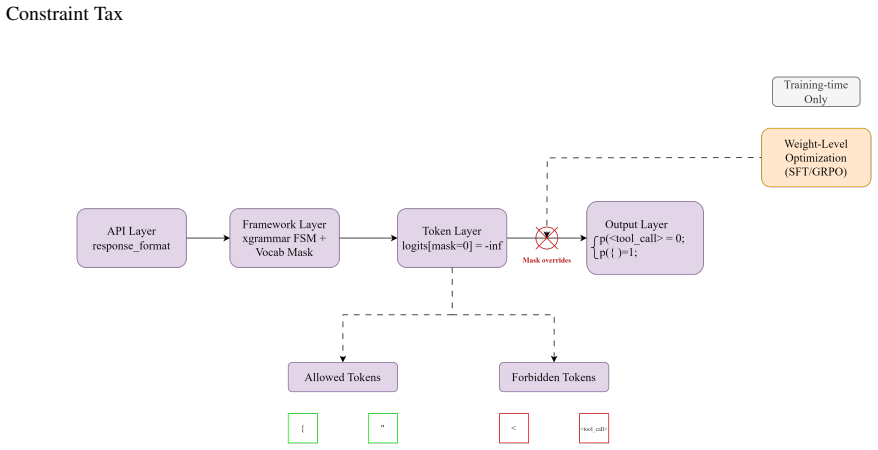
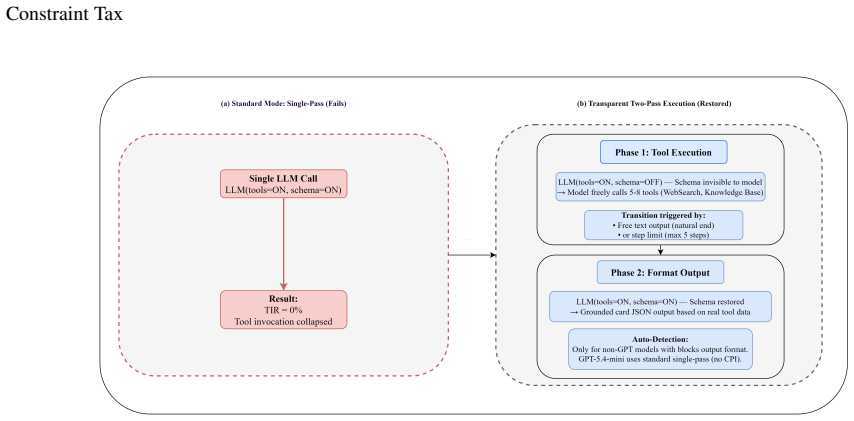
When Tool Calling and JSON Schema constraints are simultaneously enabled, multiple open-weight models cease invoking tools despite maintaining high schema compliance. JSON Schema constraints are compiled into grammar-based token masks, causing tool-call tokens to become unreachable during decoding. This provides an implementation-level explanation for the observed behavior. The Constraint Priority Inversion hypothesis suggests that schema satisfaction may dominate action-selection behavior under multiple simultaneous constraints. Transparent Two-Pass Execution decouples tool execution from schema-constrained response generation and restores tool invocation while preserving structured output
What carries the argument
Grammar-based token masks compiled from JSON Schema constraints, which narrow the allowed token set during decoding and make tool-call tokens unreachable.
If this is right
- Tool suppression appears consistently across multiple model families when both constraints are applied together.
- Schema compliance stays high even while tool invocation drops to zero under joint constraints.
- Evaluating tool use and structured output in isolation misses the interaction failure.
- Transparent Two-Pass Execution restores tool calls while keeping structured output without retraining.
- Production agent systems that combine both features can encounter reliability issues not visible in separate tests.
Where Pith is reading between the lines
- Agent builders may need to test every combination of constraints rather than assuming independent behavior.
- The same masking mechanism could affect other structured output formats beyond JSON schema.
- Inference-time decoupling strategies might apply to additional constraint types that compete for token space.
- Model providers could expose the active token mask during generation to help diagnose similar interactions.
Load-bearing premise
The observed tool suppression is caused by the grammar-based token masking mechanism rather than by prompt construction, training data, or sampling parameters.
What would settle it
A controlled decoding trace that shows tool-call tokens remaining reachable in the grammar mask under an active JSON schema, or an open-weight model that maintains both tool calling and schema compliance without suppression under identical joint conditions.
Figures
read the original abstract
Tool Calling and Structured Output are two core capabilities of modern Agent systems, yet their interaction under joint deployment conditions remains insufficiently understood. This paper reports a reproducible phenomenon observed in a production Agent system: when Tool Calling and JSON Schema constraints are simultaneously enabled, multiple open-weight models cease invoking tools despite maintaining high schema compliance. We refer to this behavior as Tool Suppression. Through controlled experiments across multiple model families and deployment settings, we consistently reproduce Tool Suppression under joint constraints, while tool execution and schema compliance remain functional when evaluated independently. Further analysis reveals that JSON Schema constraints are compiled into grammar-based token masks, causing tool-call tokens to become unreachable during decoding. This provides an implementation-level explanation for the observed behavior. To interpret the phenomenon, we formulate the Constraint Priority Inversion (CPI) hypothesis, which suggests that schema satisfaction may dominate action-selection behavior under multiple simultaneous constraints. We present CPI as a behavioral hypothesis consistent with the observed evidence rather than a verified internal mechanism. To mitigate the problem, we propose Transparent Two-Pass Execution, an inference-time strategy that decouples tool execution from schema-constrained response generation. Experimental results show that this approach restores tool invocation while preserving structured output guarantees without requiring model retraining. These findings suggest that evaluating tool use and structured output separately may overlook important reliability issues in production Agent systems. Code, data, and docs will be released at https://github.com/Fzsama/Constrain-Tax-26-06.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that simultaneously enabling tool calling and JSON Schema structured output constraints in open-weight LLMs produces 'Tool Suppression': models cease tool invocations while retaining high schema compliance. The authors attribute this to grammar-based token masks (derived from the schema) rendering tool-call tokens unreachable at decode time. They introduce the Constraint Priority Inversion (CPI) hypothesis as an interpretive frame and propose Transparent Two-Pass Execution as an inference-time mitigation that restores tool use without retraining. The work is positioned as an empirical observation with code release promised.
Significance. If the reported suppression effect proves robust and the token-masking mechanism is directly verified, the result would be significant for production agent systems that combine tool use with structured outputs. The practical mitigation is a clear engineering contribution, and the stated intent to release code, data, and documentation would enable independent verification and extension.
major comments (2)
- [Abstract] Abstract: the claim of consistent reproduction 'across multiple model families and deployment settings' is stated without any quantitative metrics, error bars, sample sizes, or full experimental protocol, leaving the magnitude and reliability of Tool Suppression difficult to evaluate.
- [Further analysis (token masking explanation)] Further analysis section (token-masking explanation): the assertion that JSON Schema constraints are compiled into grammar-based token masks that make tool-call tokens unreachable is presented as the implementation-level cause, yet no direct evidence (e.g., reported token masks, allowed sets, or mask inspection at positions where a tool call would begin) is supplied. Without this, the causal link remains unverified and alternative factors are not isolated.
minor comments (1)
- [Abstract] Abstract: the CPI hypothesis is introduced as interpretive rather than verified; a brief statement of what would constitute a test of the hypothesis would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and will revise the manuscript to improve clarity, evidence, and quantitative reporting. The work remains an empirical study, and we agree that strengthening the presentation of metrics and mechanistic evidence will enhance the contribution.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of consistent reproduction 'across multiple model families and deployment settings' is stated without any quantitative metrics, error bars, sample sizes, or full experimental protocol, leaving the magnitude and reliability of Tool Suppression difficult to evaluate.
Authors: We agree the abstract would benefit from explicit quantitative indicators. In the revision we will add suppression rates (with sample sizes and standard deviations), the number of model families and deployment backends tested, and a concise statement of the experimental protocol. The full protocol and per-model breakdowns already appear in Section 3 and the appendix; we will also reference them explicitly from the abstract. revision: yes
-
Referee: [Further analysis (token masking explanation)] Further analysis section (token-masking explanation): the assertion that JSON Schema constraints are compiled into grammar-based token masks that make tool-call tokens unreachable is presented as the implementation-level cause, yet no direct evidence (e.g., reported token masks, allowed sets, or mask inspection at positions where a tool call would begin) is supplied. Without this, the causal link remains unverified and alternative factors are not isolated.
Authors: We accept that the initial submission did not include direct mask inspection. We will add a new subsection (and accompanying figure) that reports the allowed token sets produced by the grammar compiler at the first decoding step of a tool-call sequence, demonstrating that the relevant tool-call tokens are excluded. These examples will be drawn from the same open inference engines used in the experiments, thereby providing the requested direct evidence and helping isolate the masking mechanism from other potential factors. revision: yes
Circularity Check
No circularity: empirical observations and hypothesis formulation independent of inputs
full rationale
The paper presents an empirical study of tool suppression under joint constraints, reproducing the phenomenon across models via controlled experiments. The explanation that JSON Schema constraints compile to grammar-based token masks is stated as arising from 'further analysis' of inference mechanics, but no equations, fitted parameters, or derivations are provided that reduce to the observations by construction. The CPI hypothesis is explicitly framed as a behavioral interpretation consistent with evidence rather than a verified mechanism or self-referential definition. The mitigation strategy (Transparent Two-Pass Execution) is proposed and tested independently. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing. The central claims rest on direct experimental reproduction and code-level inference inspection, making the work self-contained against external benchmarks with no reduction of outputs to inputs.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Constraint Priority Inversion (CPI)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models. InICLR 2023, 2022
2023
-
[2]
Schick, J
T. Schick, J. Dwivedi-Yu, R. Dessi, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom. Toolformer: Language models can teach themselves to use tools. InNeurIPS 2023, 2023
2023
-
[3]
Y . Qin and et al. Tool learning with foundation models.arXiv:2304.08354, 2023
Pith/arXiv arXiv 2023
-
[4]
X. Lin, J. H. Liew, S. Savarese, and J. Li. W&d: Scaling parallel tool calling for efficient deep research agents. arXiv:2602.07359, 2026
arXiv 2026
-
[5]
W. Shen, C. Li, H. Chen, M. Yan, X. Quan, H. Chen, and J. Ji. Small llms are weak tool learners: A multi-llm agent.arXiv:2401.07324, 2024
arXiv 2024
-
[6]
R. Wang, H. Li, X. Han, Y . Zhang, and T. Baldwin. Learning from failure: Integrating negative examples when fine-tuning large language models as agents.arXiv:2402.11651, 2024
arXiv 2024
-
[7]
M. X. Liu, F. Liu, A. J. Fiannaca, T. Koo, L. Dixon, M. Terry, and C. J. Cai. ”We Need Structured Output”: Towards User-centered Constraints on Large Language Model Output.arXiv:2404.07362, 2024
arXiv 2024
-
[8]
H. Deng, T. Jiang, Y . Shi, C. Zhou, and F. Huang. Decoupling task-solving and output formatting in llm generation. arXiv:2510.03595, 2025
arXiv 2025
-
[9]
J. Ray. The constraint tax: Measuring validity-correctness tradeoffs in structured outputs for small language models.arXiv:2605.26128, 2026
Pith/arXiv arXiv 2026
-
[10]
Agyemang, J
P. Agyemang, J. Williams, and T. Chen. Output generation capacity in small language models.Preprint, 2026
2026
-
[11]
C. Garbacea and Q. Mei. Why is constrained neural language generation particularly challenging? arXiv:2206.05395, 2022
arXiv 2022
- [12]
-
[13]
L. Wang and et al. A survey on large language model based autonomous agents.arXiv:2308.11432, 2023
Pith/arXiv arXiv 2023
-
[14]
Garcia, A
M. Garcia, A. Singh, and P. Li. Recency bias in mixture-of-experts language models. InACL 2025, 2025
2025
-
[15]
C. Xu, Q. Sun, K. Zheng, X. Geng, P. Zhao, J. Feng, C. Tao, and D. Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions.arXiv:2304.12244, 2023. A Test Case Design and Tool/Schema Definitions This appendix provides detailed documentation of the test case design, tool definitions, schema specifications, and experiment...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.