CodeChat-Eval: Evaluating Large Language Models in Multi-Turn Code Refinement Dialogues
Pith reviewed 2026-07-01 07:03 UTC · model grok-4.3
The pith
Large language models lose 19 to 69 percent of functional correctness when refining code across multiple dialogue turns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
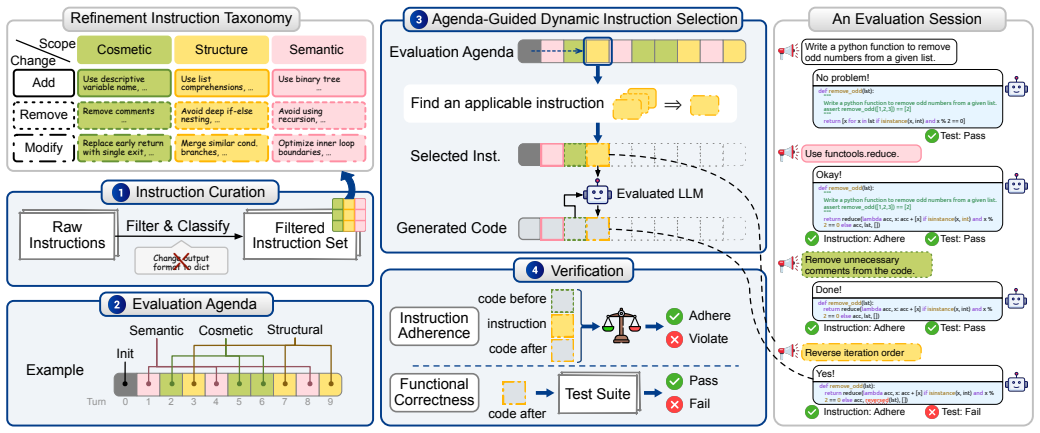
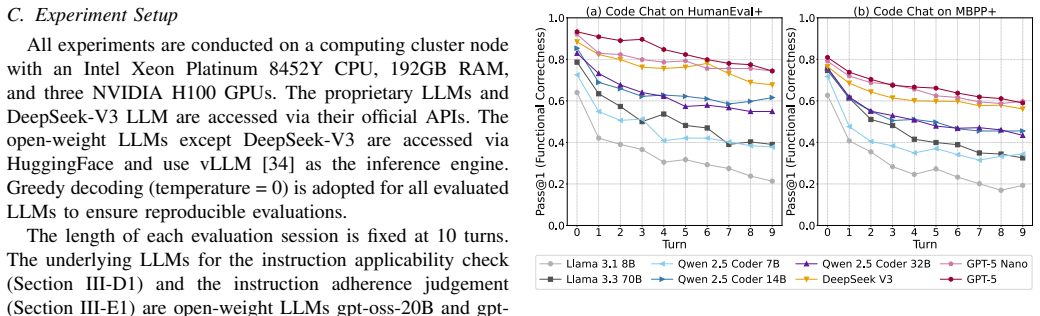
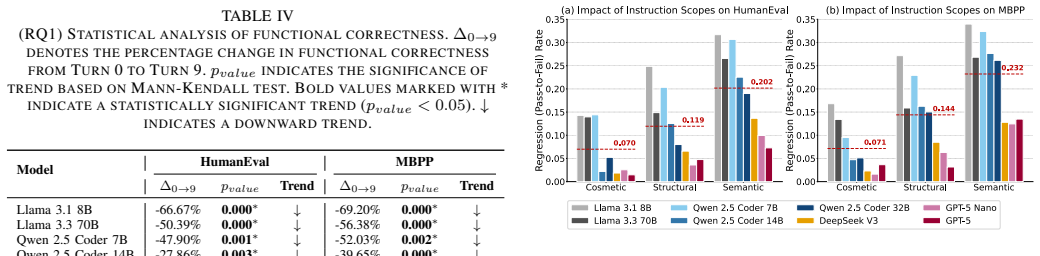
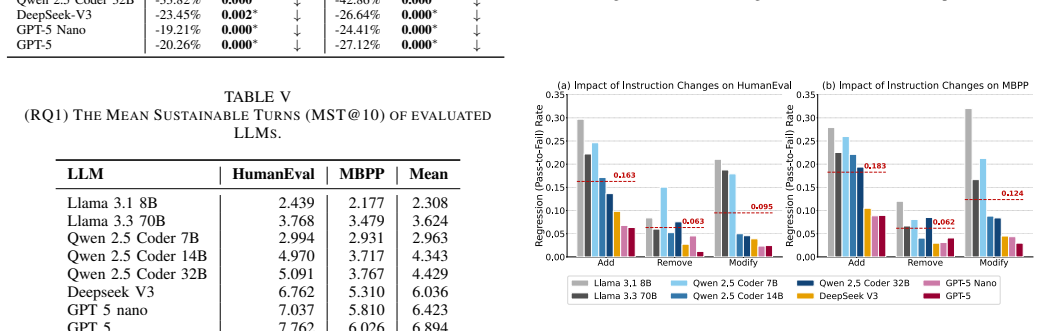
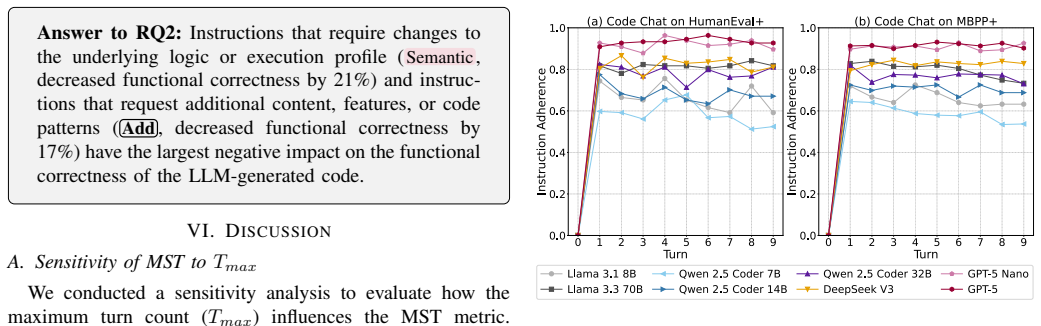
CodeChat-Eval constructs evaluation sessions from multi-turn code refinement dialogues using a dynamic instruction selection algorithm. Our empirical study on open-weight and proprietary LLMs observes a statistically significant decrease ranging from 19.2% (GPT-5 Nano) to 69.2% (Llama 3.1 8B) in functional correctness over multi-turn refinement. The largest correctness drops are associated with logic-level refinements and additive change requests. These findings indicate that LLMs struggle to maintain functional correctness during multi-turn code refinement dialogues, and highlight the need for benchmarks that evaluate functionality-preserving refinement beyond single-turn generation.
What carries the argument
CodeChat-Eval, the evaluation framework that builds multi-turn refinement sessions with a dynamic instruction selection algorithm to test preservation of functional correctness against the original test suite.
If this is right
- Correctness declines more for logic-level refinements than for style or structural ones.
- Additive change requests produce larger losses than other request types.
- The decline appears across both open-weight and proprietary models, though the magnitude varies.
- Benchmarks limited to single-turn generation miss the dominant failure pattern in iterative code work.
Where Pith is reading between the lines
- The pattern suggests models may be overwriting core logic when incorporating new requirements rather than integrating them cleanly.
- Developers relying on repeated refinements may need extra verification steps after the second or third turn to catch introduced bugs.
- Training approaches that explicitly penalize behavior changes across edit sequences could reduce the observed drops.
Load-bearing premise
The dynamic instruction selection algorithm produces sessions that accurately reflect ordinary developer refinement requests without systematically favoring change types that current models handle poorly.
What would settle it
A replication on the same sessions that finds no statistically significant correctness drop for any tested model would falsify the central observation of consistent degradation.
Figures


read the original abstract
Large Language Models (LLMs) are increasingly used in software engineering to generate and refine code. In practice, developers often continue from an initial code generation request with follow-up refinement instructions, such as requests to improve style, restructure implementation, or change the execution strategy while preserving the intended behaviour. However, existing benchmarks generally omit this multi-turn code refinement dialogue setting and therefore cannot evaluate whether LLMs maintain functional correctness, i.e., whether the refined code still passes the test suite for the original task. To address this limitation, we introduce CodeChat-Eval, an evaluation framework that constructs evaluation sessions from multi-turn code refinement dialogues using a dynamic instruction selection algorithm. Our empirical study on open-weight and proprietary LLMs observes a statistically significant decrease ranging from 19.2% (GPT-5 Nano) to 69.2% (Llama 3.1 8B) in functional correctness over multi-turn refinement. The largest correctness drops are associated with logic-level refinements and additive change requests. These findings indicate that LLMs struggle to maintain functional correctness during multi-turn code refinement dialogues, and highlight the need for benchmarks that evaluate functionality-preserving refinement beyond single-turn generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CodeChat-Eval, a framework that constructs multi-turn code refinement evaluation sessions via a dynamic instruction selection algorithm. It reports statistically significant drops in functional correctness (19.2% for GPT-5 Nano to 69.2% for Llama 3.1 8B) across open-weight and proprietary LLMs, with the largest drops linked to logic-level refinements and additive change requests, and concludes that LLMs struggle to maintain correctness in such dialogues.
Significance. If the constructed sessions are representative of real developer refinement dialogues, the results would demonstrate a practically relevant limitation of current LLMs in iterative, functionality-preserving code changes. This would strengthen the case for benchmarks that go beyond single-turn generation and could guide improvements in model training for software engineering tasks. The broad model coverage (open and proprietary) is a positive aspect of the empirical design.
major comments (2)
- [Abstract] Abstract: The headline claim of statistically significant correctness drops (19.2–69.2%) and their association with specific refinement types rests on the assumption that the dynamic instruction selection algorithm produces sessions whose change-type distribution matches typical real-world multi-turn developer behavior without systematic bias toward harder categories (logic-level, additive). No validation against external data (e.g., GitHub PR comments or chat logs) or ablation showing robustness to uniform/real-world resampling is described.
- [Abstract] Abstract: The reported drops cannot be independently assessed because the abstract supplies no information on dataset construction, the exact test suites used to measure functional correctness, the prompting templates for the LLMs, or controls for confounding variables such as session length or initial code quality.
minor comments (1)
- [Abstract] The abstract would be clearer if it stated the total number of evaluation sessions, the number of models tested, and the statistical test used to establish significance.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our evaluation framework. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of statistically significant correctness drops (19.2–69.2%) and their association with specific refinement types rests on the assumption that the dynamic instruction selection algorithm produces sessions whose change-type distribution matches typical real-world multi-turn developer behavior without systematic bias toward harder categories (logic-level, additive). No validation against external data (e.g., GitHub PR comments or chat logs) or ablation showing robustness to uniform/real-world resampling is described.
Authors: The dynamic instruction selection algorithm was designed to produce diverse multi-turn sessions by iteratively selecting instructions that build on prior turns, explicitly including logic-level and additive changes to reflect common refinement patterns. While the manuscript does not include external validation against GitHub PR comments or chat logs, nor an ablation on uniform resampling, the observed drops are statistically significant and consistent across both open-weight and proprietary models. We will add an explicit discussion of this limitation and the algorithm's design rationale in a revised Limitations section. revision: partial
-
Referee: [Abstract] Abstract: The reported drops cannot be independently assessed because the abstract supplies no information on dataset construction, the exact test suites used to measure functional correctness, the prompting templates for the LLMs, or controls for confounding variables such as session length or initial code quality.
Authors: Abstracts are intentionally concise and focus on key results. Full details on dataset construction (Section 3), test suites for functional correctness (Section 4), prompting templates (Section 3.2), and controls for session length and initial code quality (Section 4.3) are provided in the main manuscript body, enabling independent assessment. revision: no
Circularity Check
No significant circularity; empirical measurements only.
full rationale
The paper introduces CodeChat-Eval as an empirical benchmark and reports direct measurements of functional correctness (test-suite passage rates) across LLMs in multi-turn dialogues. No equations, fitted parameters, or predictions are defined in terms of the target results. The dynamic instruction selection algorithm is presented as a construction method without any self-referential fitting or renaming of known results. Central claims rest on observed deltas (19.2%–69.2% drops) rather than quantities derived by construction from the same data. No load-bearing self-citations or uniqueness theorems are invoked. This is a standard empirical study with no circular derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Test suites adequately capture the intended functional behavior of the code after refinements.
Reference graph
Works this paper leans on
-
[1]
Llm-based code generation: A systematic literature review with technical and demographic insights,
K. U. Danyaro, M. Nasser, A. Zakari, S. Abdullahi, A. Khanzada, M. M. Yakubu, S. Shoaibet al., “Llm-based code generation: A systematic literature review with technical and demographic insights,”IEEE Access, vol. 13, pp. 194 915–194 939, 2025
2025
-
[2]
Developer-llm conversations: An empirical study of interactions and generated code quality,
S. Zhong, Y . Zou, and B. Adams, “Developer-llm conversations: An empirical study of interactions and generated code quality,”arXiv preprint arXiv:2509.10402, 2025
-
[3]
An empirical study on the potential of llms in automated software refactoring,
B. Liu, Y . Jiang, Y . Zhang, N. Niu, G. Li, and H. Liu, “An empirical study on the potential of llms in automated software refactoring,”arXiv preprint arXiv:2411.04444, 2024
-
[4]
Devgpt: Studying developer-chatgpt conversations,
T. Xiao, C. Treude, H. Hata, and K. Matsumoto, “Devgpt: Studying developer-chatgpt conversations,” inProceedings of the 21st interna- tional conference on mining software repositories, 2024, pp. 227–230
2024
-
[5]
The impact of llm-assistants on software developer productivity: A systematic literature review,
A. Mohamed, M. Assi, and M. Guizani, “The impact of llm-assistants on software developer productivity: A systematic literature review,”arXiv preprint arXiv:2507.03156, 2025
-
[6]
Program Synthesis with Large Language Models
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Leet al., “Program synthesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Evaluating Large Language Models Trained on Code
M. Chen, “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[8]
SWE-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “SWE-bench: Can language models resolve real-world github issues?” inThe Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https: //openreview.net/forum?id=VTF8yNQM66
2024
-
[9]
Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions,
T. Y . Zhuo, M. C. Vu, J. Chim, H. Hu, W. Yu, R. Widyasari, I. N. B. Yusuf, H. Zhan, J. He, I. Paulet al., “Bigcodebench: Benchmarking code generation with diverse function calls and complex instructions,” inInternational Conference on Learning Representations, 2025
2025
-
[10]
Codealignbench: Assessing code generation models on developer-preferred code adjust- ments,
F. Mehralian, R. Shar, J. R. Rae, and A. Hashemi, “Codealignbench: Assessing code generation models on developer-preferred code adjust- ments,”arXiv preprint arXiv:2510.27565, 2025
-
[11]
Claude code,
Anthropic, “Claude code,” https://docs.anthropic.com/en/docs/agent s-and-tools/claude-code/overview, 2025, agentic coding tool for the command line. Accessed: 2026-03-06
2025
-
[12]
Github copilot,
GitHub, “Github copilot,” https://github.com/features/copilot, 2024, aI coding assistant. Accessed: 2024-01-28
2024
-
[13]
Mint: Evaluating llms in multi-turn interaction with tools and language feedback,
X. Wang, Z. Wang, J. Liu, Y . Chen, L. Yuan, H. Peng, and H. Ji, “Mint: Evaluating llms in multi-turn interaction with tools and language feedback,” inThe Twelfth International Conference on Learning Repre- sentations, 2024
2024
-
[14]
CodeIF: Benchmarking the instruction-following capabilities of large language models for code generation,
K. Yan, H. Guo, X. Shi, S. Cao, D. Di, and Z. Li, “CodeIF: Benchmarking the instruction-following capabilities of large language models for code generation,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track), G. Rehm and Y . Li, Eds. Vienna, Austria: Association for Computational Linguisti...
2025
-
[15]
P. Wang, L. Zhang, F. Liu, L. Shi, M. Li, B. Shen, and A. Fu, “Codeif- bench: Evaluating instruction-following capabilities of large language models in interactive code generation,”arXiv preprint arXiv:2503.22688, 2025
-
[16]
G. Duan, M. Liu, Y . Wang, C. Wang, X. Peng, and Z. Zheng, “A hierarchical and evolvable benchmark for fine-grained code instruction following with multi-turn feedback,”arXiv preprint arXiv:2507.00699, 2025
-
[17]
Convcodeworld: Benchmarking conversational code generation in reproducible feedback environments,
H. Han, S.-w. Hwang, R. Samdani, and Y . He, “Convcodeworld: Benchmarking conversational code generation in reproducible feedback environments,”arXiv preprint arXiv:2502.19852, 2025
-
[18]
Instruction-Following Evaluation for Large Language Models
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following evaluation for large language models,” arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,
J. Liu, C. S. Xia, Y . Wang, and L. Zhang, “Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation,”Advances in Neural Information Processing Systems, vol. 36, pp. 21 558–21 572, 2023
2023
-
[20]
LLMs Get Lost In Multi-Turn Conversation
P. Laban, H. Hayashi, Y . Zhou, and J. Neville, “Llms get lost in multi- turn conversation,”arXiv preprint arXiv:2505.06120, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[22]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[23]
Nonparametric tests against trend,
H. B. Mann, “Nonparametric tests against trend,”Econometrica: Journal of the econometric society, pp. 245–259, 1945
1945
-
[24]
M. G. Kendall,Rank correlation methods.Griffin, 1948
1948
-
[25]
Are we speeding up or slowing down? on temporal aspects of code velocity,
G. Kudrjavets, N. Nagappan, and A. Rastogi, “Are we speeding up or slowing down? on temporal aspects of code velocity,” in2023 IEEE/ACM 20th International Conference on Mining Software Reposi- tories (MSR). IEEE, 2023, pp. 267–271
2023
-
[26]
Wohlin, P
C. Wohlin, P. Runeson, M. H ¨ost, M. C. Ohlsson, B. Regnell, A. Wessl´en et al.,Experimentation in software engineering. Springer, 2012, vol. 236
2012
-
[27]
Restricted mean survival time: an alterna- tive to the hazard ratio for the design and analysis of randomized trials with a time-to-event outcome,
P. Royston and M. K. Parmar, “Restricted mean survival time: an alterna- tive to the hazard ratio for the design and analysis of randomized trials with a time-to-event outcome,”BMC medical research methodology, vol. 13, no. 1, p. 152, 2013
2013
-
[28]
A theory of software reliability and its application,
J. D. Musa, “A theory of software reliability and its application,”IEEE transactions on software engineering, vol. 1, no. 03, pp. 312–327, 1975
1975
-
[29]
P. D. O’connor and A. V . Kleyner,Practical reliability engineering. john wiley & sons, 2025
2025
-
[30]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Luet al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
A. Liu, B. Feng, B. Xue, B. Wang, B. Wu, C. Lu, C. Zhao, C. Deng, C. Zhang, C. Ruanet al., “Deepseek-v3 technical report,”arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Introducing gpt-5,
OpenAI, “Introducing gpt-5,” https://openai.com/index/introducing-gpt -5, 2025
2025
-
[34]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention,” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[35]
gpt-oss-120b & gpt-oss-20b Model Card
S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker, H. Baoet al., “gpt-oss-120b & gpt-oss-20b model card,”arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
J. L. Fleiss, B. Levin, and M. C. Paik,Statistical methods for rates and proportions. john wiley & sons, 2013
2013
-
[37]
Cohen,Statistical power analysis for the behavioral sciences
J. Cohen,Statistical power analysis for the behavioral sciences. rout- ledge, 2013
2013
-
[38]
Mortar: Multi-turn metamorphic testing for llm-based dialogue systems,
G. A. Guo, A. Aleti, N. Neelofar, C. Tantithamthavorn, Y . Qi, and T. Y . Chen, “Mortar: Multi-turn metamorphic testing for llm-based dialogue systems,”IEEE Transactions on Software Engineering, pp. 1–18, 2026
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.