LLM-Based Discovery of Latent Requirements from Stakeholder Conversations: Preliminary Results from Industry
Pith reviewed 2026-06-25 19:56 UTC · model grok-4.3
The pith
LENS uses LLMs to extract explicit requirements from stakeholder interviews at 84.4 percent F1-score while surfacing latent requirements judged useful by experts 75 percent of the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
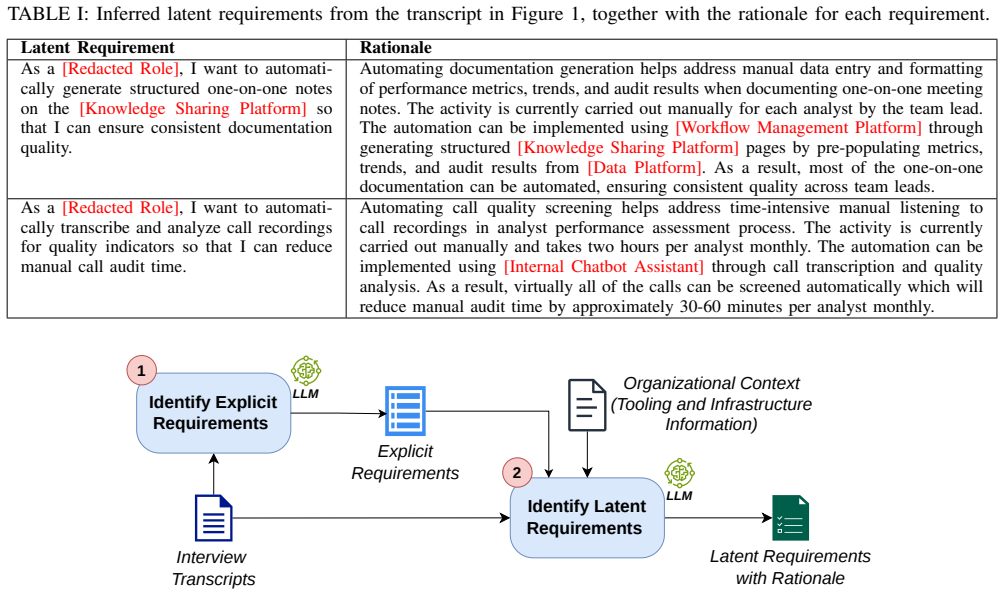
LENS analyzes stakeholder interview transcripts to extract explicit requirements and infer additional latent requirements by reasoning over stakeholder statements together with contextual information about organizational tools and infrastructure, with both represented as user stories linked to transcript excerpts for traceability.
What carries the argument
LENS (LLM-Enabled Needs Discovery from Stakeholder Interviews), an LLM pipeline that reasons over transcripts plus organizational context to produce traceable explicit and latent user stories.
If this is right
- Requirements elicitation can incorporate automated analysis of full interview transcripts rather than relying only on explicit statements.
- Latent requirements become a systematic output instead of items discovered late or missed entirely.
- Traceability links from each requirement back to transcript excerpts allow quick validation by engineers or stakeholders.
- The same transcript can yield both explicit needs already voiced and additional opportunities tied to current tools.
Where Pith is reading between the lines
- If the usefulness rate holds across other industries, interview analysis could become a standard early step rather than an ad-hoc review.
- Pairing LENS output with system usage logs would let teams test whether the inferred requirements actually reduce workload.
- Extending the context fed to the LLM beyond tools to include regulatory or compliance documents might surface additional latent needs.
Load-bearing premise
Expert judgments that latent requirements would save time or enable automation serve as a reliable stand-in for their actual value once implemented in a live system.
What would settle it
A study that implements a sample of the latent requirements, then measures actual usage time or automation gains against the original expert ratings.
Figures




read the original abstract
Stakeholder interviews are an important source of information for requirements elicitation, yet many relevant requirements remain implicit in such conversations. Stakeholders frequently describe workflows, challenges, and operational practices without explicitly articulating the software capabilities that could address them. Recent work has considered the use of LLMs to analyze conversational data and extract requirements from stakeholder interviews. Existing approaches, however, primarily focus on identifying explicitly stated requirements, leaving implicit opportunities largely unexplored. In this paper, we present LENS (LLM-Enabled Needs Discovery from Stakeholder Interviews), an approach that analyzes stakeholder interview transcripts to both extract explicit requirements and infer additional latent requirements. LENS performs this inference by reasoning over stakeholder statements together with contextual information about organizational tools and infrastructure. Both extracted and inferred requirements are represented as user stories and linked to transcript excerpts to ensure traceability. We conduct a preliminary evaluation of LENS using twelve stakeholder interview transcripts collected in an industrial setting involving cybersecurity operations. We show that LENS achieves an average F1-score of 84.4% for extracting explicit requirements, while, on average, 75% of the latent requirements identified by LENS were perceived as providing useful automation or time-saving potential by domain experts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LENS, an LLM-based approach that processes stakeholder interview transcripts to extract explicit requirements and infer latent requirements, representing both as traceable user stories. Using 12 industrial cybersecurity operations transcripts, it reports an average F1-score of 84.4% on explicit requirements and states that domain experts rated 75% of the inferred latent requirements as providing useful automation or time-saving potential.
Significance. If the evaluation protocol and validation gaps are addressed, the work could contribute to requirements elicitation by demonstrating LLM use for implicit needs in real industrial data, with traceability as a practical strength. The industrial setting and dual focus on explicit/latent extraction differentiate it from prior explicit-only methods, though the preliminary scope and perception-based proxy for latent value constrain broader claims.
major comments (2)
- [Evaluation] Evaluation section: The 75% usefulness rating for latent requirements rests entirely on domain-expert perception of automation/time-saving potential, with no follow-up implementation, A/B testing, or measured productivity outcomes in the cybersecurity setting. This leaves the central claim about practical benefit for inferred requirements as an unvalidated proxy.
- [Evaluation] Evaluation section: No details are provided on the LLM prompting strategy, how organizational context about tools/infrastructure is supplied, inter-rater reliability for human labels, or the exact protocol used to compute the 84.4% F1 and 75% figures, preventing assessment of the reported metrics.
minor comments (2)
- Clarify the exact number of latent requirements generated per transcript and any filtering steps applied before expert review.
- The abstract states 'preliminary results' but the manuscript should explicitly discuss threats to validity arising from the small sample of 12 transcripts.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our preliminary study. We address each major comment below and will revise the manuscript to improve clarity on methodology and to better frame the scope and limitations of the evaluation.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The 75% usefulness rating for latent requirements rests entirely on domain-expert perception of automation/time-saving potential, with no follow-up implementation, A/B testing, or measured productivity outcomes in the cybersecurity setting. This leaves the central claim about practical benefit for inferred requirements as an unvalidated proxy.
Authors: We agree that the assessment of latent requirements relies on expert perception of potential utility rather than direct implementation or measured outcomes. This aligns with the paper's framing as preliminary results from 12 transcripts. In the revision, we will add an explicit Limitations subsection (in Discussion) that acknowledges this as a proxy measure, discusses the rationale for perception-based validation in early-stage work, and outlines future directions including implementation pilots and productivity metrics. We maintain that the current results provide a useful initial signal for the approach while transparently noting the validation gap. revision: partial
-
Referee: [Evaluation] Evaluation section: No details are provided on the LLM prompting strategy, how organizational context about tools/infrastructure is supplied, inter-rater reliability for human labels, or the exact protocol used to compute the 84.4% F1 and 75% figures, preventing assessment of the reported metrics.
Authors: We acknowledge that the Evaluation section lacks sufficient methodological detail. In the revised version, we will expand this section (and add an appendix if needed) to fully describe: the LLM prompting strategy and templates; the mechanism for supplying organizational context on tools and infrastructure; inter-rater reliability statistics for the human annotations of explicit requirements; and the precise computation protocol for the F1-score (including how true positives were determined) and the 75% usefulness rating (including the expert rating scale and aggregation method). These additions will support reproducibility and metric assessment. revision: yes
Circularity Check
No circularity: empirical evaluation of LLM tool on labeled transcripts
full rationale
The paper reports an empirical study: LENS extracts explicit requirements (F1 84.4% vs. human annotations) and infers latent ones whose usefulness is rated by domain experts (75%). No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method. Results are computed directly from external human labels and expert judgments on the given transcripts; the evaluation chain does not reduce to its own inputs by construction. This is the normal case of a self-contained empirical paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can accurately infer latent requirements by reasoning over stakeholder statements together with contextual information about organizational tools and infrastructure
Reference graph
Works this paper leans on
-
[1]
C. Almeida, I. Copque, A. Oliveira, M. Arouca, A. Barbosa, S. Freire, M. Mendonc ¸a, and J. C. Leite. From elicitation interviews to software requirements: Evaluating LLM performance in requirement generation. InWorkshop on Requirement s Engineering (WER), 2025. https://doi. org/10.29327/1588952.28-12
-
[2]
Introducing Claude Sonnet 4.5
Anthropic. Introducing Claude Sonnet 4.5. https://www.anthropic.com/ news/claude-sonnet-4-5, 2025
2025
-
[3]
Claude Sonnet 4.5 API Reference
Anthropic. Claude Sonnet 4.5 API Reference. https://docs.aimlapi.com/ api-references/text-models-llm/anthropic/claude-4-5-sonnet, 2026
2026
-
[4]
Context windows
Anthropic Claude API Docs. Context windows. https://platform.claude. com/docs/en/build-with-claude/context-windows, 2026
2026
-
[5]
C. Burnay, I.J. Jureta, and S. Faulkner. What stakeholders will or will not say: A theoretical and empirical study of topic importance in requirements engineering elicitation interviews.Information Systems, 46:61–81, 2014. https://doi.org/10.1016/j.is.2014.05.006
-
[6]
J. Cohen. A coefficient of agreement for nominal scales.Educational and Psychological Measurement, 20(1):37–46, 1960
1960
-
[7]
C. Jain, P. R. Anish, A. Singh, and S. Ghaisas. A transformer- based approach for abstractive summarization of requirements from obligations in software engineering contracts. InIEEE 31st International Requirements Engineering Conference (RE), pages 169–179, 2023. https://doi.org/10.1109/RE57278.2023.00025
-
[8]
G. Lucassen, F. Dalpiaz, J.M.E. van der Werf, and S. Brinkkemper. Improving Agile Requirements: The Quality User Story Framework and Tool.Requirements engineering, 21(3):383–403, 2016. https://doi.org/ 10.1007/s00766-016-0250-x
-
[9]
Maiden, A
N. Maiden, A. Gizikis, and S. Robertson. Provoking creativity: Imagine what your requirements could be like.IEEE software, 21(5):68–75,
-
[10]
https://doi.org/10.1109/MS.2004.1331305
-
[11]
A. Sharfuddin and T. Breaux. Generative goal modeling. InIEEE 33rd International Requirements Engineering Conference (RE), pages 92–103, 2025. https://doi.org/10.1109/RE63999.2025.00019
-
[12]
Spijkman, X
T. Spijkman, X. de Bondt, F. Dalpiaz, and S. Brinkkemper. Sum- marization of elicitation conversations to locate requirements-relevant information. InInternational Working Conference on Requirements Engineering: Foundation for Software Quality, pages 122–139. Springer,
-
[13]
https://doi.org/10.1007/978-3-031-29786-1 9
-
[14]
V oria, F
G. V oria, F. Casillo, C. Gravino, G. Catolino, and F. Palomba. RE- COVER: Toward requirements generation from stakeholders’ conversa- tions.IEEE Transactions on Software Engineering, 51(6):1912–1933,
1912
-
[15]
https://doi.org/10.1109/TSE.2025.3572056. 9
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.