AI-Assisted Computational Reproducibility on the FABRIC Testbed
Pith reviewed 2026-06-25 19:17 UTC · model grok-4.3
The pith
AI coding assistants on the FABRIC testbed cut reproduction effort for published experiments by a factor of four to six.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
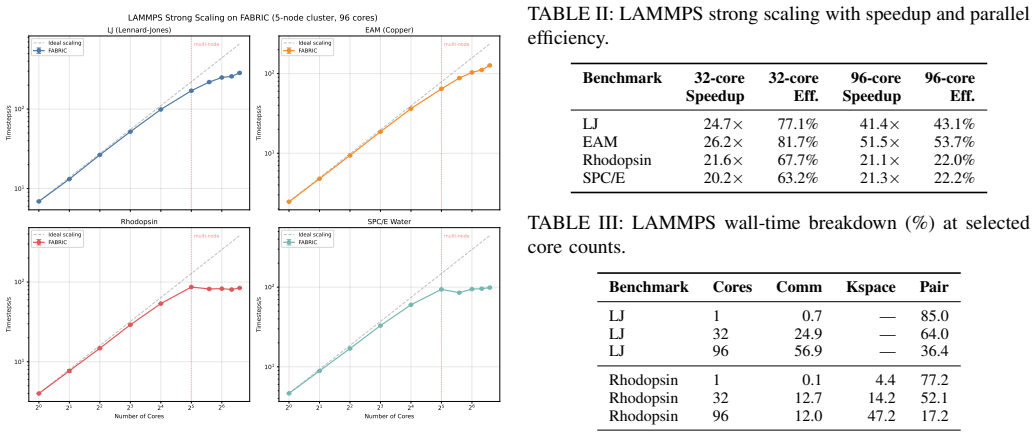
Across the three case studies, the AI-assisted workflow on FABRIC reduced reproduction effort by roughly 4--6 times while the reproduced experiments supported the same scientific conclusions as the original studies.
What carries the argument
AI-assisted workflow that uses large language model coding assistants through LoomAI on the FABRIC testbed to automate setup, code adaptation, and debugging.
If this is right
- Reproduction success is judged by whether the same scientific conclusions are reached rather than by exact numerical match.
- AI tools prove useful for environment setup and debugging but need human guidance when analysis lacks a clearly defined workflow.
- The approach yields concrete recommendations for using AI assistants on shared research testbeds.
Where Pith is reading between the lines
- The same testbed-plus-AI pattern could be tested on other distributed research infrastructures.
- Adding tools that automatically extract data dependencies might reduce the remaining human effort in analysis stages.
- Repeating the exercise with a larger and more varied set of published papers would test whether the 4--6x factor generalizes.
Load-bearing premise
That effort reduction can be measured consistently across domains and that the three chosen case studies are representative without selection bias.
What would settle it
A side-by-side measurement of person-hours required to reproduce the same three experiments once with the AI assistant and once without it.
Figures

read the original abstract
Computational reproducibility remains difficult despite being central to scientific research. In this paper, we show how the international FABRIC testbed, combined with large language model (LLM) coding assistants through LoomAI, can simplify reproducing published experiments across multiple domains. We reproduced three case studies on FABRIC, covering BBR-family congestion-control evaluations, LAMMPS molecular dynamics scaling benchmarks on a CPU-only MPI cluster, and stress protein homeostasis genomics pipelines. Rather than focusing only on matching numerical outputs, we evaluate whether the reproduced experiments support the same scientific conclusions as the original studies. The AI assistant was effective in setting up the environment, adapting code, and debugging, but struggled with the analysis stages that lacked clearly defined workflows, which required human guidance to establish execution order and data dependencies. Across the case studies, the AI-assisted workflow reduced reproduction effort by roughly 4--6 times. We conclude with practical recommendations for improving AI-assisted reproducibility on research testbeds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes three case studies reproducing published experiments (BBR congestion-control evaluations, LAMMPS molecular-dynamics scaling benchmarks, and a genomics protein-homeostasis pipeline) on the FABRIC testbed with the assistance of LLM coding tools via LoomAI. Rather than exact numerical matching, the authors assess whether the reproduced runs support the original scientific conclusions. They report that the AI assistant handled environment setup, code adaptation, and debugging effectively but required human intervention for analysis stages lacking clear workflows. The central claim is that the AI-assisted approach reduced reproduction effort by a factor of roughly 4–6 across the cases, accompanied by practical recommendations for AI-assisted reproducibility on research testbeds.
Significance. If the effort-reduction factor can be placed on a reproducible, objective footing with explicit baselines and measurement protocols, the work would supply concrete, domain-spanning evidence on the current capabilities and limits of LLM assistants for computational reproducibility tasks. Such evidence is scarce and would be useful to both testbed operators and researchers seeking to lower barriers to reproduction.
major comments (2)
- [Abstract and case-study results sections] The 4–6× effort-reduction claim (stated in the abstract and repeated in the conclusions) is load-bearing for the paper’s contribution, yet no measurement protocol, definition of “effort,” or controlled baseline is supplied. It is therefore impossible to determine whether the factor derives from logged person-hours, number of human–AI turns, wall-clock time, or post-hoc author estimates, nor whether identical tasks were performed with and without the AI assistant.
- [Introduction and case-study selection] The three chosen case studies (BBR, LAMMPS, genomics) are presented as representative, but the manuscript provides no discussion of selection criteria or potential bias toward domains where LLM assistance is unusually effective. Without such justification, generalization of the reported speedup remains unsupported.
minor comments (2)
- [Abstract] The abstract states that the AI “struggled with the analysis stages that lacked clearly defined workflows,” but the manuscript does not enumerate which specific analysis steps required human guidance or how those steps were ultimately resolved.
- [Methods / LoomAI description] Notation for the LoomAI interface and the precise version of the LLM used is introduced without a dedicated methods subsection, making it difficult for readers to replicate the exact assistant configuration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where the manuscript can be strengthened by adding explicit methodological detail. We address each point below and will incorporate revisions in the next version.
read point-by-point responses
-
Referee: [Abstract and case-study results sections] The 4–6× effort-reduction claim (stated in the abstract and repeated in the conclusions) is load-bearing for the paper’s contribution, yet no measurement protocol, definition of “effort,” or controlled baseline is supplied. It is therefore impossible to determine whether the factor derives from logged person-hours, number of human–AI turns, wall-clock time, or post-hoc author estimates, nor whether identical tasks were performed with and without the AI assistant.
Authors: We agree that the current manuscript lacks an explicit measurement protocol. The reported 4–6× factor reflects the authors’ post-hoc estimates of total person-hours spent on each reproduction, based on detailed interaction logs with the LLM assistant and our prior experience performing comparable tasks without AI assistance. No controlled, side-by-side experiment with identical tasks was conducted. In revision we will add a dedicated subsection that (1) defines effort as cumulative person-hours, (2) describes the logging of human–AI turns and time stamps, and (3) states the limitations of the baseline estimation. We will also qualify the claim in the abstract and conclusions to reflect this methodology. revision: yes
-
Referee: [Introduction and case-study selection] The three chosen case studies (BBR, LAMMPS, genomics) are presented as representative, but the manuscript provides no discussion of selection criteria or potential bias toward domains where LLM assistance is unusually effective. Without such justification, generalization of the reported speedup remains unsupported.
Authors: The three experiments were chosen to cover distinct computational domains (networking, molecular dynamics, and bioinformatics) that are commonly reproduced on testbeds and that exercise different aspects of the FABRIC environment. We will revise the Introduction to state these selection criteria explicitly, note that the domains were not chosen to maximize LLM success, and add a short limitations paragraph discussing possible selection bias and the consequent limits on generalizability. revision: yes
Circularity Check
No circularity: empirical case-study report with no derivations or self-referential predictions
full rationale
The paper reports three case studies (BBR, LAMMPS, genomics) on AI-assisted reproduction using the FABRIC testbed and LoomAI. The central claim of 4-6x effort reduction is presented as an empirical observation from these reproductions rather than a derived prediction, fitted parameter, or result obtained via equations. No mathematical derivations, ansatzes, uniqueness theorems, or self-citation chains appear in the provided text. The work is self-contained as a descriptive evaluation of practical workflows and does not reduce any load-bearing claim to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
1,500 scientists lift the lid on reproducibility,
M. Baker, “1,500 scientists lift the lid on reproducibility,”Nature, vol. 533, no. 7604, pp. 452–454, 2016
2016
-
[2]
An empirical analysis of journal policy effectiveness for computational reproducibility,
V . Stodden, J. Seiler, and Z. Ma, “An empirical analysis of journal policy effectiveness for computational reproducibility,”Proceedings of the National Academy of Sciences, vol. 115, no. 11, pp. 2584–2589, 2018
2018
-
[3]
Repeatability in computer systems research,
C. Collberg and T. A. Proebsting, “Repeatability in computer systems research,”Communications of the ACM, vol. 59, no. 3, pp. 62–69, 2016
2016
-
[4]
Lessons learned from the Chameleon testbed,
K. Keahey, J. Anderson, Z. Zhen, P. Riteau, P. Ruth, D. Stanzione, M. Cevik, J. Colleran, H. S. Gunawi, C. Hammock, J. Mambretti, A. Barnes, F. Halbach, A. Roez, and J. Tracey, “Lessons learned from the Chameleon testbed,” inProceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC’20), 2020, pp. 219–233
2020
-
[5]
The design and operation of CloudLab,
D. Duplyakin, R. Ricci, A. Maricq, G. Wong, J. Duerig, E. Eide, L. Stoller, M. Hibler, D. Johnson, K. Webb, A. Naber, N. Ezzelle, and J. Stutzman, “The design and operation of CloudLab,” inProceedings of the 2019 USENIX Annual Technical Conference (USENIX ATC’19), 2019, pp. 1–14
2019
-
[6]
FABRIC: A national-scale programmable experimental network infras- tructure,
I. Baldin, A. Mandal, P. Ruth, R. McGeer, J. Chase, and T. Nyczyk, “FABRIC: A national-scale programmable experimental network infras- tructure,” inIEEE Internet Computing, vol. 23, no. 6, 2019, pp. 38–47
2019
-
[7]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. d. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[8]
Claude: AI assistant by Anthropic,
Anthropic, “Claude: AI assistant by Anthropic,” https://www.anthropic. com/claude, 2024, accessed: 2026-04-01
2024
-
[9]
LoomAI: An AI-augmented interface for designing, deploying, and automating experiments on FABRIC,
P. Ruth and K. Thareja, “LoomAI: An AI-augmented interface for designing, deploying, and automating experiments on FABRIC,” in Practice and Experience in Advanced Research Computing (PEARC ’26). ACM, 2026, to appear
2026
-
[10]
Performance of molecular dynamics acceleration strategies on composable cyberinfrastructure,
R. Lawrence, D. K. Chakravorty, F. Dang, L. M. Perez, W. Brashear, Z. He, H. Liu, J. X. Mao, and C.-Y . Lu, “Performance of molecular dynamics acceleration strategies on composable cyberinfrastructure,” in Practice and Experience in Advanced Research Computing (PEARC ’24). ACM, 2024, pp. 1–5
2024
-
[11]
Stress testing reveals selective vulnerabilities in protein homeostasis,
B. Aldikactiet al., “Stress testing reveals selective vulnerabilities in protein homeostasis,”Cell Reports, 2026, in press
2026
-
[12]
Claude code: AI-powered coding assistant CLI,
Anthropic, “Claude code: AI-powered coding assistant CLI,” https: //docs.anthropic.com/en/docs/claude-code, 2025, accessed: 2026-04-01
2025
-
[13]
Artifact review and badging, version 1.1,
ACM, “Artifact review and badging, version 1.1,” https://www.acm. org/publications/policies/artifact-review-and-badging-current, 2020, ac- cessed: 2026-04-01
2020
-
[14]
Characterization of leptazolines A–D, polar non-ribosomal peptides of the associated cyanobacterium,
J. Bhandari Neupane, R. P. Neupane, Y . Luo, W. Y . Yoshida, R. Sun, and P. G. Williams, “Characterization of leptazolines A–D, polar non-ribosomal peptides of the associated cyanobacterium,”Molecules, vol. 27, no. 7, p. 2233, 2022, placeholder – replace with actual bioinformatics reproducibility citation
2022
-
[15]
BBR: Congestion-based congestion control,
N. Cardwell, Y . Cheng, C. S. Gunn, S. H. Yeganeh, and V . Jacobson, “BBR: Congestion-based congestion control,” inCommunications of the ACM, vol. 60, no. 2, 2017, pp. 58–66
2017
-
[16]
BBRv3: Algorithm bug fixes and public internet deployment,
N. Cardwell, Y . Cheng, S. H. Yeganeh, I. Swett, and V . Jacobson, “BBRv3: Algorithm bug fixes and public internet deployment,” IETF 115 Presentation, 2022, replace with the specific BBRv3 paper(s) being reproduced
2022
-
[17]
LAMMPS — a flexible simulation tool for particle- based materials modeling at the atomic, meso, and continuum scales,
A. P. Thompson, H. M. Aktulga, R. Berger, D. S. Bolintineanu, W. M. Brown, P. S. Crozier, P. J. in ’t Veld, A. Kohlmeyer, S. G. Moore, T. D. Nguyen, R. Shan, M. J. Stevens, J. Tranchida, C. Trott, and S. J. Plimpton, “LAMMPS — a flexible simulation tool for particle- based materials modeling at the atomic, meso, and continuum scales,” Computer Physics Com...
2022
-
[18]
Sustainable data analysis with Snakemake,
F. M ¨older, K. P. Jablonski, B. Letcher, M. B. Hall, C. H. Tomkins-Tinch, V . Sochat, J. Forster, S. Lee, S. O. Twardziok, A. Kanitz, A. Wilm, M. Holtgrewe, S. Rahmann, A. Narechania, and J. K ¨oster, “Sustainable data analysis with Snakemake,”F1000Research, vol. 10, p. 33, 2021
2021
-
[19]
Nextflow enables reproducible computational work- flows,
P. Di Tommaso, M. Chatzou, E. W. Floden, P. P. Barja, E. Palumbo, and C. Notredame, “Nextflow enables reproducible computational work- flows,”Nature Biotechnology, vol. 35, no. 4, pp. 316–319, 2017
2017
-
[20]
OpenAI, “GPT-4 technical report,” arXiv preprint arXiv:2303.08774, 2023
Pith/arXiv arXiv 2023
-
[21]
Gemini: A family of highly capable multimodal models,
Google DeepMind, “Gemini: A family of highly capable multimodal models,” arXiv preprint arXiv:2312.11805, 2024
Pith/arXiv arXiv 2024
-
[22]
Autonomous chemical research with large language models,
D. A. Boiko, R. MacKnight, B. Kline, and G. Gomes, “Autonomous chemical research with large language models,”Nature, vol. 624, pp. 570–578, 2023
2023
-
[23]
SciPredict: Can LLMs predict the outcomes of scientific experiments in natural sciences?
U. M. Sehwag, E. Lau, H. Ehsani Oskouie, S. Shabihi, E. Liang, A. Toledo, G. Mangialardi, S. Fonrouge, E.-Y . Hernandez Cardona, P. Vergara, U. Tyagi, C. B. C. Zhang, P. Bhatter, N. Johnson, F. Huang, E. G. Hernandez Montoya, and B. Liu, “SciPredict: Can LLMs predict the outcomes of scientific experiments in natural sciences?”arXiv preprint arXiv:2604.10718, 2026
Pith/arXiv arXiv 2026
-
[24]
Barbarians at the gate: How AI is upending systems research,
A. Cheng, S. Liu, M. Pan, Z. Li, B. Wang, A. Krentsel, T. Xia, M. Cemri, J. Park, S. Yang, J. Chen, L. Agrawal, A. Desai, J. Xing, K. Sen, M. Zaharia, and I. Stoica, “Barbarians at the gate: How AI is upending systems research,”arXiv preprint arXiv:2510.06189, 2025
arXiv 2025
-
[25]
Generalization bias in large language model summarization of scientific research,
U. Peters and B. Chin-Yee, “Generalization bias in large language model summarization of scientific research,”Royal Society Open Science, vol. 12, no. 4, p. 241776, 2025
2025
-
[26]
Agentic LLM pipelines for reproducible scientific software: Opportunities and challenges,
A. Adashchik, A. Huraira, Z. Kholmatova, A. Mikriukov, A. Ravveduto, M. Snigireva, G. Succi, A. Tormasov, and E. A. Trofimova, “Agentic LLM pipelines for reproducible scientific software: Opportunities and challenges,” inProceedings of the 9th International Conference on Computer Science and Artificial Intelligence (CSAI ’25). ACM, 2025, pp. 38–46
2025
-
[27]
Some of the internet may be heading towards BBR dominance: An experimental study,
A. Srivastava, F. Fund, and S. S. Panwar, “Some of the internet may be heading towards BBR dominance: An experimental study,” inIEEE INFOCOM 2023 - IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), 2023, pp. 1–7
2023
-
[28]
Understanding the performance of TCP BBRv2 using FABRIC,
J. Gomez, E. Kfoury, J. Crichigno, and G. Srivastava, “Understanding the performance of TCP BBRv2 using FABRIC,” in2023 IEEE In- ternational Black Sea Conference on Communications and Networking (BlackSeaCom), 2023, pp. 259–264
2023
-
[29]
bbr2: Scripts for an emulation-based evaluation of TCP BBRv2 alpha,
J. Gomez Gaona, “bbr2: Scripts for an emulation-based evaluation of TCP BBRv2 alpha,” https://github.com/gomezgaona/bbr2, 2023, ac- cessed: 2026-05-27
2023
-
[30]
bbr3: Resources for BBRv3 performance evaluation,
——, “bbr3: Resources for BBRv3 performance evaluation,” https: //github.com/gomezgaona/bbr3, 2024, accessed: 2026-05-27
2024
-
[31]
Replication: “when to use and when not to use BBR
S. Datta and F. Fund, “Replication: “when to use and when not to use BBR”,” inProceedings of the 2023 ACM Internet Measurement Conference, 2023, pp. 29–34
2023
-
[32]
imcbbrrepro: Artifacts for replication: “when to use and when not to use BBR
——, “imcbbrrepro: Artifacts for replication: “when to use and when not to use BBR”,” https://github.com/sdatta97/imcbbrrepro, 2023, accessed: 2026-05-27
2023
-
[33]
When to use and when not to use BBR: An empirical analysis and evaluation study,
Y . Cao, A. Jain, K. Sharma, A. Balasubramanian, and A. Gandhi, “When to use and when not to use BBR: An empirical analysis and evaluation study,” inProceedings of the 2019 Internet Measurement Conference, 2019, pp. 130–136
2019
-
[34]
BBR’s sharing behavior with CUBIC and Reno,
F. B. Sarpkaya, A. Srivastava, F. Fund, and S. Panwar, “BBR’s sharing behavior with CUBIC and Reno,”arXiv preprint arXiv:2505.07741, 2025
arXiv 2025
-
[35]
TCP BBR behavior over a shared bottleneck: experiment arti- facts,
——, “TCP BBR behavior over a shared bottleneck: experiment arti- facts,” https://github.com/fatihsarpkaya/bbr-shared-bottleneck, 2025, ac- cessed: 2026-05-27
2025
-
[36]
A quantitative measure of fairness and discrimination for resource allocation in shared computer systems,
R. K. Jain, D.-M. W. Chiu, and W. R. Hawe, “A quantitative measure of fairness and discrimination for resource allocation in shared computer systems,”DEC Research Report TR-301, 1984, widely cited as Jain’s fairness index
1984
-
[37]
Supplemental documents for PEARC24: Performance of molecular dynamics acceleration strategies on composable cyberinfras- tructure,
R. Lawrence, “Supplemental documents for PEARC24: Performance of molecular dynamics acceleration strategies on composable cyberinfras- tructure,” https://github.com/rarensu/pearc24-LAMMPS-supplement, 2024
2024
-
[38]
lammps-reproducibility: AI-assisted reproduction of LAMMPS MPI scaling benchmarks on FABRIC,
K. Thareja, “lammps-reproducibility: AI-assisted reproduction of LAMMPS MPI scaling benchmarks on FABRIC,” https://github.com/ kthare10/lammps-reproducibility, 2026, accessed: 2026-05-11
2026
-
[39]
ComBat-seq: batch effect adjustment for RNA-seq count data,
Y . Zhang, G. Parmigiani, and W. E. Johnson, “ComBat-seq: batch effect adjustment for RNA-seq count data,”NAR Genomics and Bioinformatics, vol. 2, no. 3, p. lqaa078, 2020
2020
-
[40]
Panning for gold: ‘model-X’ knockoffs for high dimensional controlled variable selection,
E. Cand `es, Y . Fan, L. Janson, and J. Lv, “Panning for gold: ‘model-X’ knockoffs for high dimensional controlled variable selection,”Journal of the Royal Statistical Society: Series B, vol. 80, no. 3, pp. 551–577, 2018
2018
-
[41]
The earth mover’s distance as a metric for image retrieval,
Y . Rubner, C. Tomasi, and L. J. Guibas, “The earth mover’s distance as a metric for image retrieval,”International Journal of Computer Vision, vol. 40, no. 2, pp. 99–121, 2000
2000
-
[42]
A Bayesian nonpara- metric model for inferring subclonal populations from structured DNA sequencing data,
A. Schein, S. He, V . Sarsani, and P. Flaherty, “A Bayesian nonpara- metric model for inferring subclonal populations from structured DNA sequencing data,”Annals of Applied Statistics, vol. 15, no. 2, 2021
2021
-
[43]
Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2,
M. I. Love, W. Huber, and S. Anders, “Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2,”Genome Biology, vol. 15, no. 12, p. 550, 2014
2014
-
[44]
tnseq-homeostasis: Multilevel Tn-seq analysis,
P. Flaherty, “tnseq-homeostasis: Multilevel Tn-seq analysis,” https:// github.com/flahertylab/tnseq-homeostasis, 2024
2024
-
[45]
stress-protein-homeostasis: AI-assisted reproduction of stress protein homeostasis analysis on FABRIC,
K. Kthare, “stress-protein-homeostasis: AI-assisted reproduction of stress protein homeostasis analysis on FABRIC,” https://github.com/ kthare10/stress-protein-homeostasis, 2026, accessed: 2026-05-10
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.