DT²: Decision-Targeted Digital Twins
Pith reviewed 2026-06-25 20:06 UTC · model grok-4.3
The pith
Digital twins trained to minimize transition errors can rank policies suboptimally, but DT² targets rankings to improve selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
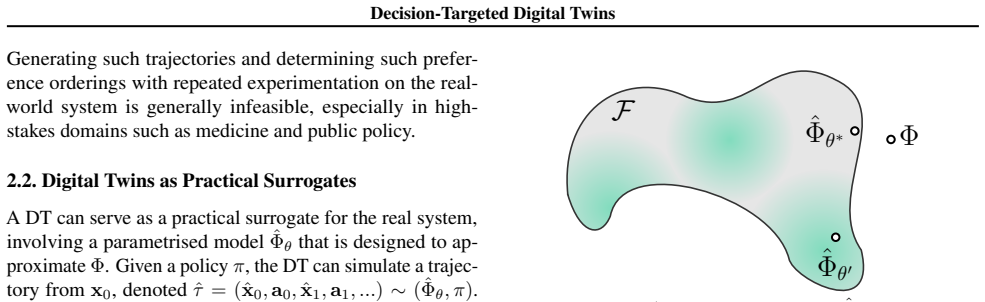
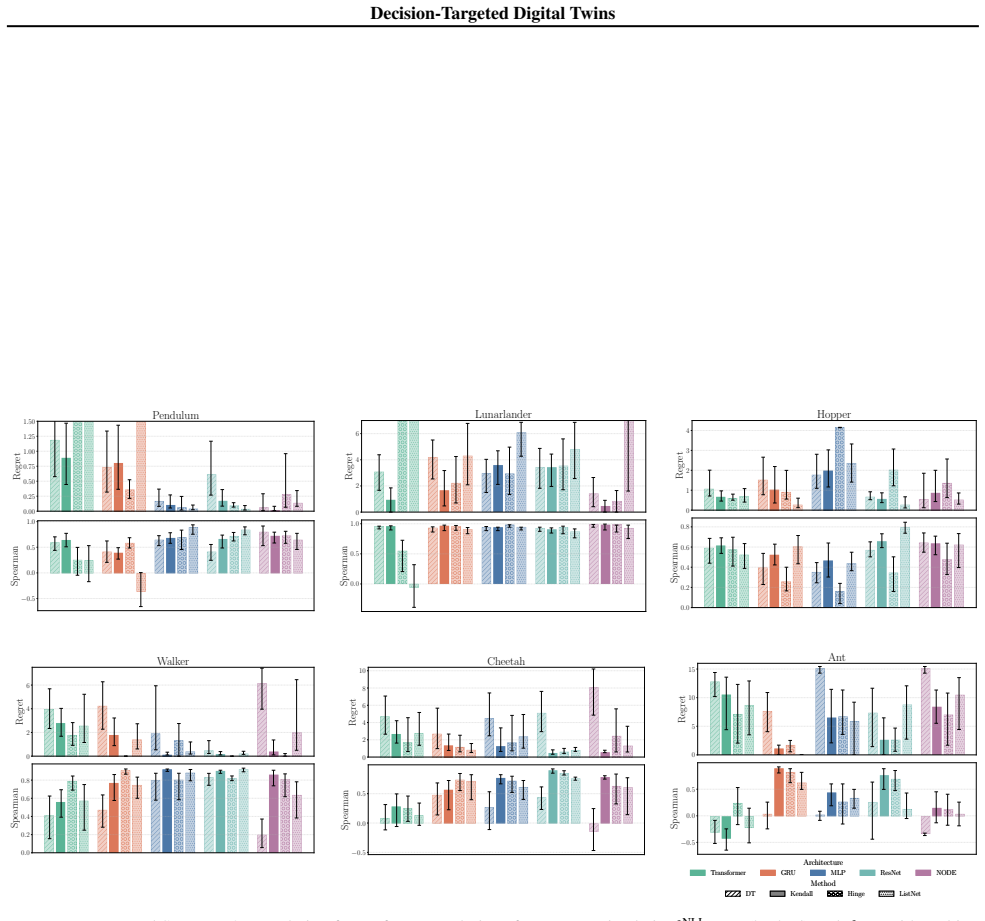
When model capacity is limited, training DTs to minimise one-step transition errors can produce suboptimal models for ranking sets of policies according to a reward function. DT² uses fitted Q-evaluation to estimate values of candidate policies from offline data. A DT is then trained to generate rollouts that preserve pairwise policy rankings derived from these proxy ground-truth values with an architecture-agnostic loss function.
What carries the argument
Architecture-agnostic loss that trains the digital twin to preserve pairwise policy rankings obtained from fitted Q-evaluation on offline data.
If this is right
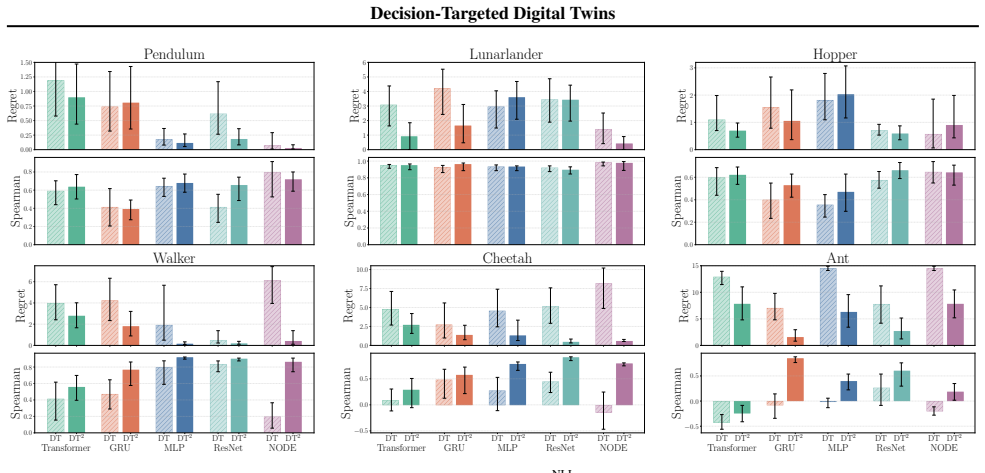
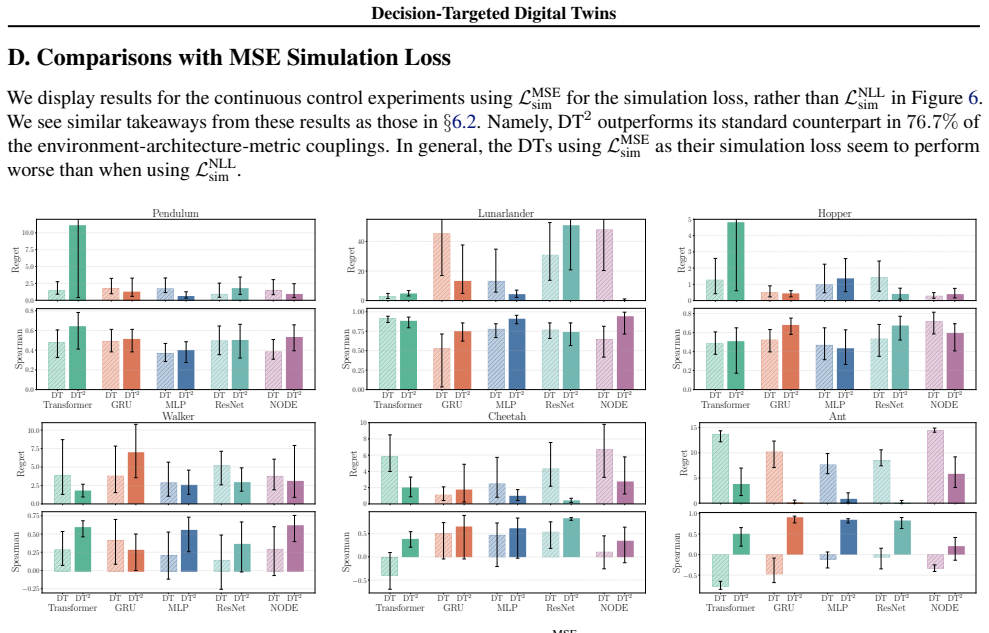
- DT² yields higher accuracy when ranking policies by expected reward.
- Decision regret drops during policy selection from the ranked set.
- Gains appear for both policies present in the offline data and for new policies.
- Simulation fidelity measured by raw transition error stays comparable to baseline training.
Where Pith is reading between the lines
- Training objectives for simulators used in decisions should align directly with downstream ranking or selection tasks rather than generic prediction metrics.
- The ranking-preservation idea could apply to other model-based planning systems where the end goal is comparative evaluation of action sequences.
- Testing the method on continuous policy parameterizations would show whether the pairwise approach scales beyond discrete candidate sets.
Load-bearing premise
Pairwise policy rankings from fitted Q-evaluation on offline data serve as a reliable proxy for true relative policy values.
What would settle it
A controlled benchmark with known true policy values where DT² produces higher decision regret than a transition-error trained twin on the same data and architecture.
Figures


read the original abstract
A digital twin (DT) is a virtual model of a real-world system that can assist decision-making by simulating scenarios induced by different policies. However, typical machine learning-based DTs do not optimise for this use case. We prove that, when model capacity is limited, training DTs to minimise one-step transition errors can produce suboptimal models for ranking sets of policies according to a reward function. We further show that this holds empirically, even with expressive model classes. To address this, we introduce $\text{DT}^2$, a decision-targeted DT training paradigm. Firstly, $\text{DT}^2$ uses fitted Q-evaluation to estimate values of candidate policies from offline data. A DT is then trained to generate rollouts that preserve pairwise policy rankings derived from these proxy ground-truth values with an architecture-agnostic loss function. We empirically demonstrate the efficacy of our method across a range of settings and architectures. $\text{DT}^2$ consistently improves policy ranking and reduces decision regret during policy selection relative to conventional DT training, both for policies used during training and for unseen policies, while maintaining a good level of raw simulation fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that conventional digital twin (DT) training via one-step transition error minimization can lead to suboptimal models for ranking policies by their values under a reward function, with a proof provided for limited model capacity and empirical evidence even for expressive models. To address this, DT² is introduced, which first applies fitted Q-evaluation (FQE) to offline data to obtain proxy policy values, then trains the DT using an architecture-agnostic loss to preserve the pairwise rankings induced by these proxies. Empirical results demonstrate that DT² improves policy ranking accuracy and reduces decision regret for both in-training and unseen policies compared to standard training, while preserving simulation fidelity.
Significance. If the results hold, this paper makes a significant contribution by highlighting the misalignment between standard simulation objectives and decision-making utility in digital twins, offering a targeted training approach that directly optimizes for policy ranking. The provision of a proof for the limited-capacity case and consistent empirical improvements across multiple settings and architectures are strengths that could guide future work in model-based RL and digital twin applications. The architecture-agnostic nature of the loss is particularly practical.
major comments (2)
- [Abstract and method description] The central claim that DT² yields better policy selection relies on the assumption that FQE-derived pairwise rankings serve as a reliable proxy for true policy values. However, the manuscript does not appear to include an independent validation of this proxy (e.g., via on-policy rollouts in environments with known ground truth), which is load-bearing for the decision-targeted objective and the reported reductions in decision regret.
- [Proof section (referenced in abstract)] The proof establishes suboptimality only under limited model capacity; the extension to expressive model classes is purely empirical. If the proof technique cannot be extended, this should be explicitly discussed as a limitation of the theoretical contribution.
minor comments (2)
- [Abstract] The abstract states that DT² 'consistently improves' but does not quantify the improvements or mention the number of environments/architectures tested; adding such details would strengthen the summary.
- [Notation] Ensure that the definition of the loss function in the DT² paradigm is clearly distinguished from standard transition losses, perhaps with an equation number for easy reference.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of our theoretical and empirical claims. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract and method description] The central claim that DT² yields better policy selection relies on the assumption that FQE-derived pairwise rankings serve as a reliable proxy for true policy values. However, the manuscript does not appear to include an independent validation of this proxy (e.g., via on-policy rollouts in environments with known ground truth), which is load-bearing for the decision-targeted objective and the reported reductions in decision regret.
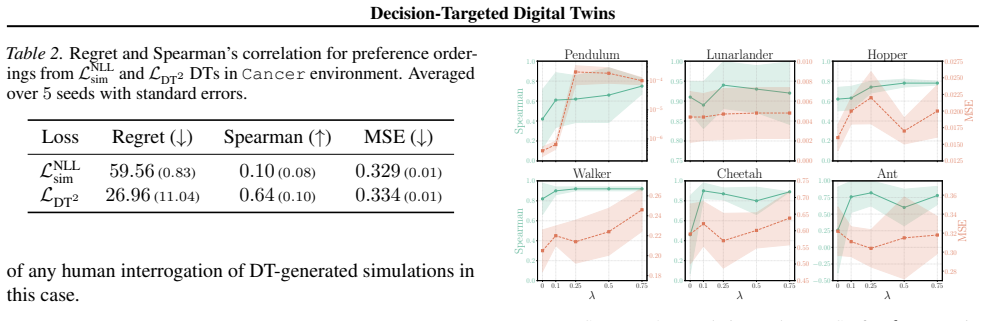
Authors: We agree that validating the FQE proxy is important for the decision-targeted objective. While our empirical results already measure final policy selection quality and decision regret using ground-truth values (via on-policy evaluation in the benchmark environments), we did not explicitly compare FQE estimates against these ground-truth values in the original manuscript. In the revision, we will add a dedicated validation subsection reporting the correlation between FQE-derived rankings and true policy values across the environments, thereby confirming the proxy's reliability in the settings studied. revision: yes
-
Referee: [Proof section (referenced in abstract)] The proof establishes suboptimality only under limited model capacity; the extension to expressive model classes is purely empirical. If the proof technique cannot be extended, this should be explicitly discussed as a limitation of the theoretical contribution.
Authors: The referee is correct: the formal proof applies only to limited-capacity models, with the expressive-model case supported solely by experiments. We will revise the manuscript to explicitly state this scope as a limitation of the theoretical contribution and note that extending the proof technique to general function classes is left for future work. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central derivation consists of a capacity-limited proof that one-step transition minimization can be suboptimal for policy ranking, plus an empirical method that explicitly trains on FQE-derived pairwise rankings as an external proxy target via a new loss. This does not reduce any claimed result to its inputs by construction, nor does it involve self-definitional mappings, fitted inputs renamed as predictions, load-bearing self-citations, imported uniqueness theorems, smuggled ansatzes, or renamed known results. The FQE proxy is treated as an independent (if imperfect) benchmark rather than being generated from the DT itself, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Fitted Q-evaluation on offline data produces reliable pairwise policy rankings that should be preserved by the digital twin.
Reference graph
Works this paper leans on
-
[1]
Journal of medical Internet research , volume=
Optimal treatment selection in sequential systemic and locoregional therapy of oropharyngeal squamous carcinomas: deep Q-learning with a patient-physician digital twin dyad , author=. Journal of medical Internet research , volume=. 2022 , publisher=
2022
-
[2]
The International Journal of Advanced Manufacturing Technology , volume=
Digital twin-driven product design, manufacturing and service with big data , author=. The International Journal of Advanced Manufacturing Technology , volume=. 2018 , publisher=
2018
-
[3]
European Heart Journal , volume =
Corral-Acero, Jorge and Margara, Francesca and Marciniak, Maciej and Rodero, Cristobal and Loncaric, Filip and Feng, Yingjing and Gilbert, Andrew and Fernandes, Joao F and Bukhari, Hassaan A and Wajdan, Ali and Martinez, Manuel Villegas and Santos, Mariana Sousa and Shamohammdi, Mehrdad and Luo, Hongxing and Westphal, Philip and Leeson, Paul and DiAchille...
-
[4]
Energy , volume=
Hybrid mechanistic and neural network modeling of nuclear reactors , author=. Energy , volume=. 2023 , publisher=
2023
-
[5]
Current Opinion in Chemical Engineering , volume=
Hybrid modeling—a key enabler towards realizing digital twins in biopharma? , author=. Current Opinion in Chemical Engineering , volume=. 2021 , publisher=
2021
-
[6]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Automatically Learning Hybrid Digital Twins of Dynamical Systems , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[7]
IEEE Transactions on Knowledge and Data Engineering , year=
Promptcast: A new prompt-based learning paradigm for time series forecasting , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[8]
Advances in Neural Information Processing Systems , volume=
Large language models are zero-shot time series forecasters , author=. Advances in Neural Information Processing Systems , volume=. 2024 , url=
2024
-
[9]
The Twelfth International Conference on Learning Representations , year=
Time-LLM: Time Series Forecasting by Reprogramming Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[10]
2024.Foundational Research Gaps and Future Directions for Digital Twins
Foundational Research Gaps and Future Directions for Digital Twins , isbn =. doi:10.17226/26894 , year =
-
[11]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=. 2020 , url=
2020
-
[12]
Advances in neural information processing systems , volume=
One fits all: Power general time series analysis by pretrained LM , author=. Advances in neural information processing systems , volume=. 2023 , url=
2023
-
[13]
Advances in neural information processing systems , volume=
Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting , author=. Advances in neural information processing systems , volume=. 2021 , url=
2021
-
[14]
arXiv preprint arXiv:2004.04906 , year=
Dense passage retrieval for open-domain question answering , author=. arXiv preprint arXiv:2004.04906 , year=
Pith/arXiv arXiv 2004
-
[15]
2024 , url =
Novel Drug Therapy Approvals 2024 , journal =. 2024 , url =
2024
-
[16]
Journal of Rare Diseases , volume=
Emerging biomarkers for precision diagnosis and personalized treatment of cystic fibrosis , author=. Journal of Rare Diseases , volume=. 2024 , publisher=
2024
-
[17]
International conference on machine learning , pages=
Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting , author=. International conference on machine learning , pages=. 2022 , organization=
2022
-
[18]
arXiv preprint arXiv:2211.14730 , year=
A time series is worth 64 words: Long-term forecasting with transformers , author=. arXiv preprint arXiv:2211.14730 , year=
-
[19]
The Thirty-Fifth
Haoyi Zhou and Shanghang Zhang and Jieqi Peng and Shuai Zhang and Jianxin Li and Hui Xiong and Wancai Zhang , title =. The Thirty-Fifth
-
[20]
arXiv preprint arXiv:2402.19072 , year=
Timexer: Empowering transformers for time series forecasting with exogenous variables , author=. arXiv preprint arXiv:2402.19072 , year=
-
[21]
Statistics and computing , volume=
Genetic programming as a means for programming computers by natural selection , author=. Statistics and computing , volume=. 1994 , publisher=
1994
-
[22]
Brunton and Joshua L
Steven L. Brunton and Joshua L. Proctor and J. Nathan Kutz , title =. Proceedings of the National Academy of Sciences , volume =. 2016 , doi =
2016
-
[23]
International Conference on Learning Representations , year=
D-code: Discovering closed-form odes from observed trajectories , author=. International Conference on Learning Representations , year=
-
[24]
Journal of Computational physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational physics , volume=. 2019 , publisher=
2019
-
[25]
Journal of Statistical Mechanics: Theory and Experiment , volume=
Augmenting physical models with deep networks for complex dynamics forecasting , author=. Journal of Statistical Mechanics: Theory and Experiment , volume=. 2021 , publisher=
2021
-
[26]
Advances in Neural Information Processing Systems , volume=
Integrating expert ODEs into neural ODEs: pharmacology and disease progression , author=. Advances in Neural Information Processing Systems , volume=. 2021 , url=
2021
-
[27]
arXiv preprint arXiv:2202.03881 , year=
Robust hybrid learning with expert augmentation , author=. arXiv preprint arXiv:2202.03881 , year=
-
[28]
arXiv preprint arXiv:2310.04948 , year=
Tempo: Prompt-based generative pre-trained transformer for time series forecasting , author=. arXiv preprint arXiv:2310.04948 , year=
-
[29]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Med-Real2Sim: Non-Invasive Medical Digital Twins using Physics-Informed Self-Supervised Learning , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[30]
Advances in Neural Information Processing Systems , volume=
Synctwin: Treatment effect estimation with longitudinal outcomes , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
New England Journal of Medicine , volume=
A CFTR potentiator in patients with cystic fibrosis and the G551D mutation , author=. New England Journal of Medicine , volume=. 2011 , publisher=
2011
-
[32]
International Conference on Learning Representations , year=
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis , author=. International Conference on Learning Representations , year=
-
[33]
arXiv preprint arXiv:2407.13278 , year=
Deep Time Series Models: A Comprehensive Survey and Benchmark , author=. arXiv preprint arXiv:2407.13278 , year=
-
[34]
Proceedings of the AAAI conference on artificial intelligence , volume=
Are transformers effective for time series forecasting? , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[35]
Advances in Neural Information Processing Systems , volume=
Non-stationary transformers: Exploring the stationarity in time series forecasting , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
arXiv preprint arXiv:2405.14616 , year=
Timemixer: Decomposable multiscale mixing for time series forecasting , author=. arXiv preprint arXiv:2405.14616 , year=
-
[37]
IEEE transactions on knowledge and data engineering , volume=
Learning under concept drift: A review , author=. IEEE transactions on knowledge and data engineering , volume=. 2018 , publisher=
2018
-
[38]
Frontiers of Computer Science , volume=
Large language models make sample-efficient recommender systems , author=. Frontiers of Computer Science , volume=. 2025 , publisher=
2025
-
[39]
npj Digital Medicine , volume=
Large language models forecast patient health trajectories enabling digital twins , author=. npj Digital Medicine , volume=. 2025 , publisher=
2025
-
[40]
NPJ Digital Medicine , volume=
Digital twins for health: a scoping review , author=. NPJ Digital Medicine , volume=. 2024 , publisher=
2024
-
[41]
doi: https://doi.org/10.1016/0364-0213(90)90002-E
Finding structure in time , journal =. 1990 , issn =. doi:https://doi.org/10.1016/0364-0213(90)90002-E , url =
-
[42]
Supervised Sequence Labelling with Recurrent Neural Networks , pages=
Long Short-Term Memory , author=. Supervised Sequence Labelling with Recurrent Neural Networks , pages=. 2012 , publisher=
2012
-
[43]
International Conference on Machine Learning , pages=
Causal transformer for estimating counterfactual outcomes , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[44]
Advances in neural information processing systems , volume=
Neural ordinary differential equations , author=. Advances in neural information processing systems , volume=. 2018 , url=
2018
-
[45]
Advances in neural information processing systems , volume=
Augmented neural odes , author=. Advances in neural information processing systems , volume=. 2019 , url=
2019
-
[46]
Advances in Neural Information Processing Systems , volume=
Physics-integrated variational autoencoders for robust and interpretable generative modeling , author=. Advances in Neural Information Processing Systems , volume=. 2021 , url=
2021
-
[47]
UPRISE : Universal Prompt Retrieval for Improving Zero-Shot Evaluation
Cheng, Daixuan and Huang, Shaohan and Bi, Junyu and Zhan, Yuefeng and Liu, Jianfeng and Wang, Yujing and Sun, Hao and Wei, Furu and Deng, Weiwei and Zhang, Qi. UPRISE : Universal Prompt Retrieval for Improving Zero-Shot Evaluation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.758
-
[48]
Findings of the Association for Computational Linguistics ACL 2024 , pages=
se2: Sequential example selection for in-context learning , author=. Findings of the Association for Computational Linguistics ACL 2024 , pages=. 2024 , url=
2024
-
[49]
nature , volume=
Learning representations by back-propagating errors , author=. nature , volume=. 1986 , publisher=
1986
-
[50]
arXiv preprint arXiv:2009.04278 , year=
Dynode: Neural ordinary differential equations for dynamics modeling in continuous control , author=. arXiv preprint arXiv:2009.04278 , year=
arXiv 2009
-
[51]
Journal of the American statistical Association , volume=
Strictly proper scoring rules, prediction, and estimation , author=. Journal of the American statistical Association , volume=. 2007 , publisher=
2007
-
[52]
arXiv preprint arXiv:1807.03748 , year=
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
-
[53]
International conference on artificial neural networks , pages=
Multi-dimensional recurrent neural networks , author=. International conference on artificial neural networks , pages=. 2007 , organization=
2007
-
[54]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. 2021 , isbn =. doi:10.1145/3442188.3445922 , booktitle =
-
[55]
arXiv preprint arXiv:2412.13663 , year=
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference , author=. arXiv preprint arXiv:2412.13663 , year=
-
[56]
International Conference on Learning Representations (ICLR) , year =
Adam: A Method for Stochastic Optimization , author =. International Conference on Learning Representations (ICLR) , year =. 1412.6980 , archivePrefix =
-
[57]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=. 2019 , url=
2019
-
[58]
arXiv preprint arXiv:1704.08863 , year=
On weight initialization in deep neural networks , author=. arXiv preprint arXiv:1704.08863 , year=
-
[59]
Thomas Wolf and Lysandre Debut and Victor Sanh and Julien Chaumond and Clement Delangue and Anthony Moi and Pierric Cistac and Tim Rault and Rémi Louf and Morgan Funtowicz and Joe Davison and Sam Shleifer and Patrick von Platen and Clara Ma and Yacine Jernite and Julien Plu and Canwen Xu and Teven Le Scao and Sylvain Gugger and Mariama Drame and Quentin L...
2020
-
[60]
Transactions of the Association for Computational Linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , publisher=
2024
-
[61]
The Thirteenth International Conference on Learning Representations , year=
No Equations Needed: Learning System Dynamics Without Relying on Closed-Form ODEs , author=. The Thirteenth International Conference on Learning Representations , year=
-
[62]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Context versus Prior Knowledge in Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , organization=
2024
-
[63]
Nature Computational Science , volume=
Digital twins in medicine , author=. Nature Computational Science , volume=. 2024 , publisher=
2024
-
[64]
European Proceedings of Social and Behavioural Sciences , year=
Impact of digital twin technology on the financial performance of corporations , author=. European Proceedings of Social and Behavioural Sciences , year=
-
[65]
Communications Earth & Environment , volume=
Digital twins of the Earth with and for humans , author=. Communications Earth & Environment , volume=. 2024 , publisher=
2024
-
[66]
Artificial intelligence in digital twins—A systematic literature review , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.datak.2024.102304 , url =
-
[67]
Scientific reports , volume=
Prediction of treatment response for combined chemo-and radiation therapy for non-small cell lung cancer patients using a bio-mathematical model , author=. Scientific reports , volume=. 2017 , publisher=
2017
-
[68]
International Conference on Learning Representations , year=
Estimating counterfactual treatment outcomes over time through adversarially balanced representations , author=. International Conference on Learning Representations , year=
-
[69]
International Conference on Machine Learning , pages=
Continuous-Time Modeling of Counterfactual Outcomes Using Neural Controlled Differential Equations , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[70]
Cochrane Database of Systematic Reviews , number=
Dornase alfa for cystic fibrosis , author=. Cochrane Database of Systematic Reviews , number=. 2021 , publisher=
2021
-
[71]
Respiratory Research , volume=
Predicting lung function decline in cystic fibrosis: the impact of initiating ivacaftor therapy , author=. Respiratory Research , volume=. 2024 , publisher=
2024
-
[72]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[73]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Neural Machine Translation of Rare Words with Subword Units , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2016 , organization=
2016
-
[74]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=
On Faithfulness and Factuality in Abstractive Summarization , author=. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages=. 2020 , organization=
2020
-
[75]
arXiv preprint arXiv:2305.14201 , year=
Goat: Fine-tuned llama outperforms gpt-4 on arithmetic tasks , author=. arXiv preprint arXiv:2305.14201 , year=
-
[76]
arXiv preprint arXiv:2302.13971 , year=
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
-
[77]
Nature , volume=
Self-organizing neural network that discovers surfaces in random-dot stereograms , author=. Nature , volume=. 1992 , publisher=
1992
-
[78]
2006 IEEE computer society conference on computer vision and pattern recognition (CVPR'06) , volume=
Dimensionality reduction by learning an invariant mapping , author=. 2006 IEEE computer society conference on computer vision and pattern recognition (CVPR'06) , volume=. 2006 , organization=
2006
-
[79]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[80]
Active Task Disambiguation with
Kasia Kobalczyk and Nicol. Active Task Disambiguation with. The Thirteenth International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.