Knowledge Cascade: Reverse Knowledge Distillation on Nonparametric Multivariate Functional Estimation
Pith reviewed 2026-06-25 19:56 UTC · model grok-4.3
The pith
Knowledge Cascade transfers smoothing parameters chosen on small samples to full datasets via asymptotic scaling laws for multivariate nonparametric estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Knowledge Cascade (KCas) is a reverse knowledge distillation framework that uses asymptotic scaling laws to transfer optimal smoothing parameters selected by a small student model to the full-sample teacher model in nonparametric multivariate functional estimation in reproducing kernel Hilbert spaces. This transfer avoids the direct computational cost of parameter selection on the large dataset. The same scaling principle is illustrated for kernel density estimation and deep learning hyperparameter transfer. Simulations and real-data experiments indicate that KCas achieves substantial computational savings while maintaining strong statistical performance and can sometimes outperform the corr
What carries the argument
asymptotic scaling laws that relate optimal smoothing parameters between small-sample and full-sample regimes in multivariate RKHS smoothing splines
If this is right
- KCas substantially reduces computational cost for high-dimensional and large-scale datasets.
- Theoretical guarantees of the full-sample estimator are retained under the scaling transfer.
- The same scaling principle applies to kernel density estimation.
- The principle extends to hyperparameter transfer in deep learning.
- Simulations and real-data experiments show substantial savings while maintaining or sometimes improving performance.
Where Pith is reading between the lines
- The method could extend to other nonparametric estimators that involve multiple tuning parameters whose optima scale with sample size.
- Small pilot samples might accelerate analysis pipelines on streaming or massive functional datasets where full recomputation is impractical.
- Reverse distillation via scaling laws may apply to other statistical procedures where teacher-model fitting is the dominant cost.
Load-bearing premise
The asymptotic scaling relationships between small-sample and full-sample optimal smoothing parameters remain accurate enough in finite samples and in the multivariate RKHS setting that the transferred parameters do not materially degrade the estimator's risk.
What would settle it
Running the full-sample optimal procedure and the KCas procedure on the same large multivariate dataset and finding that the risk of the KCas estimator exceeds the risk of the optimally tuned full-sample estimator by more than a small factor would falsify the transfer's practical value.
Figures
read the original abstract
As machine learning models and datasets continue to grow, developing complex models has become increasingly computationally demanding. Knowledge distillation reduces deployment cost by compressing a large, well-trained teacher model into a compact student model, but it does not address settings where constructing the teacher itself is the bottleneck. Motivated by this challenge, we introduce Knowledge Cascade (KCas), a reverse knowledge distillation framework that uses information from a small, inexpensive student model to guide the development of a more complex teacher model. Although this direction is counterintuitive because the teacher typically has greater representational capacity, we show that student-to-teacher transfer can be principled when supported by statistical scaling relationships. We first develop KCas for nonparametric multivariate functional estimation in reproducing kernel Hilbert spaces via smoothing splines, where selecting multiple smoothing parameters is a major computational bottleneck. KCas transfers student-selected smoothing parameters to the full-sample regime through asymptotic scaling laws, substantially reducing computational cost for high-dimensional and large-scale datasets while retaining theoretical guarantees. Beyond smoothing splines, we illustrate the same principle through kernel density estimation and deep learning hyperparameter transfer. Simulations and real-data experiments show that KCas achieves substantial computational savings while maintaining strong statistical performance, and can sometimes outperform the corresponding full-sample procedure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Knowledge Cascade (KCas), a reverse knowledge distillation framework for nonparametric multivariate functional estimation in reproducing kernel Hilbert spaces. It selects smoothing parameters on a small student sample and transfers them to the full-sample teacher via asymptotic scaling laws, claiming substantial computational savings for high-dimensional and large-scale problems while retaining theoretical guarantees. The principle is illustrated on smoothing splines, kernel density estimation, and deep learning hyperparameter transfer, with supporting simulations and real-data experiments.
Significance. If the finite-sample accuracy of the asymptotic scaling holds in the multivariate RKHS setting, the method could meaningfully reduce the computational cost of smoothing-parameter selection without sacrificing statistical performance, offering a practical tool for scaling nonparametric estimators.
major comments (2)
- [Abstract] Abstract: the claim that 'theoretical guarantees are retained' is load-bearing for the central contribution, yet the abstract (and, per the provided text, the methods) supplies no derivation of the scaling law, no explicit error bound on the transferred λ, and no proof that the minimax rate is preserved up to o(1) factors in the multivariate case.
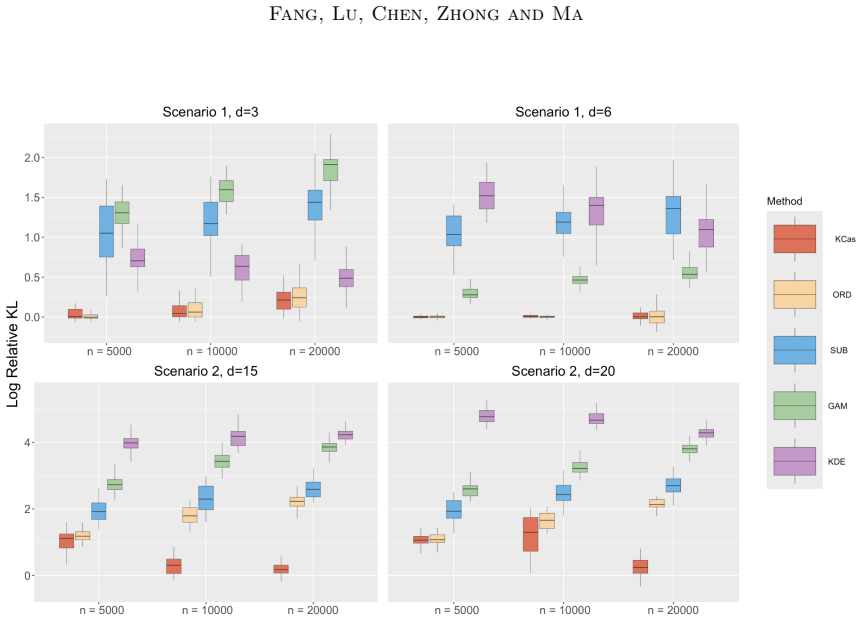
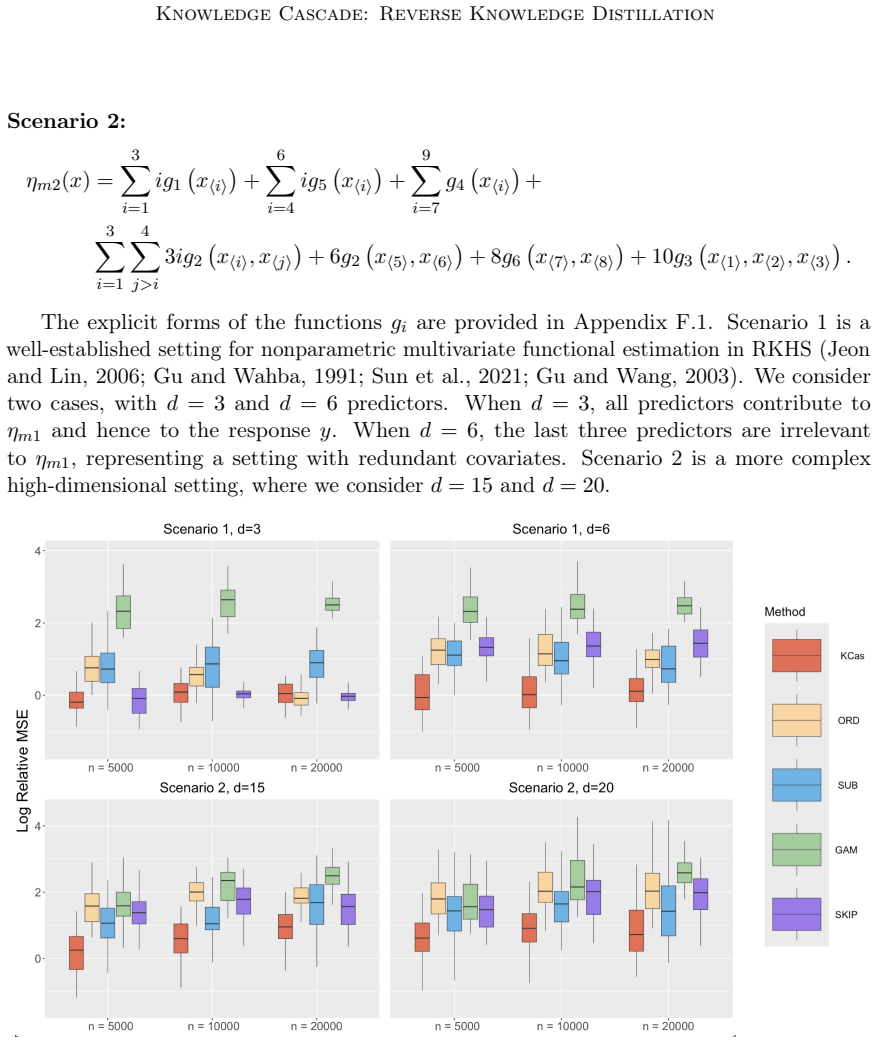
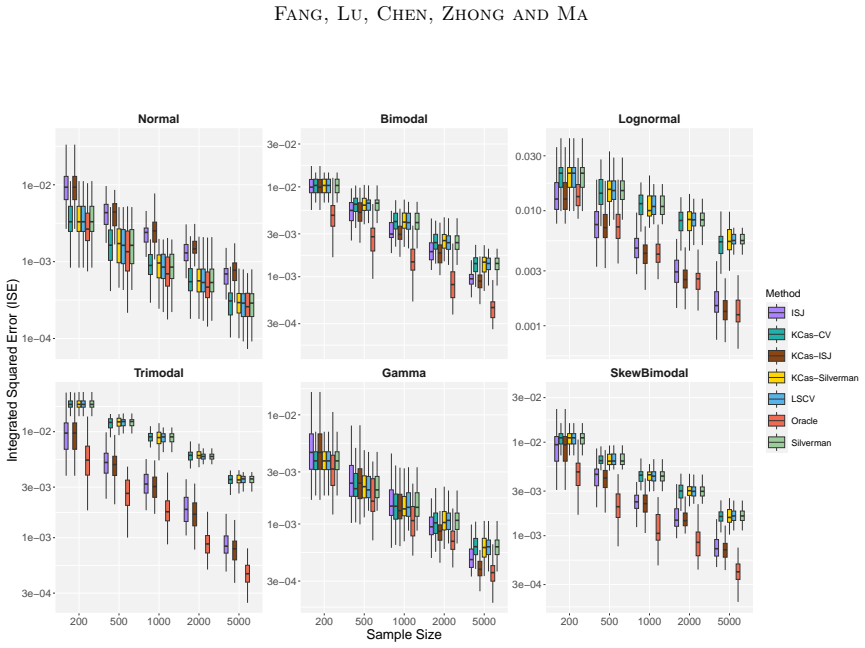
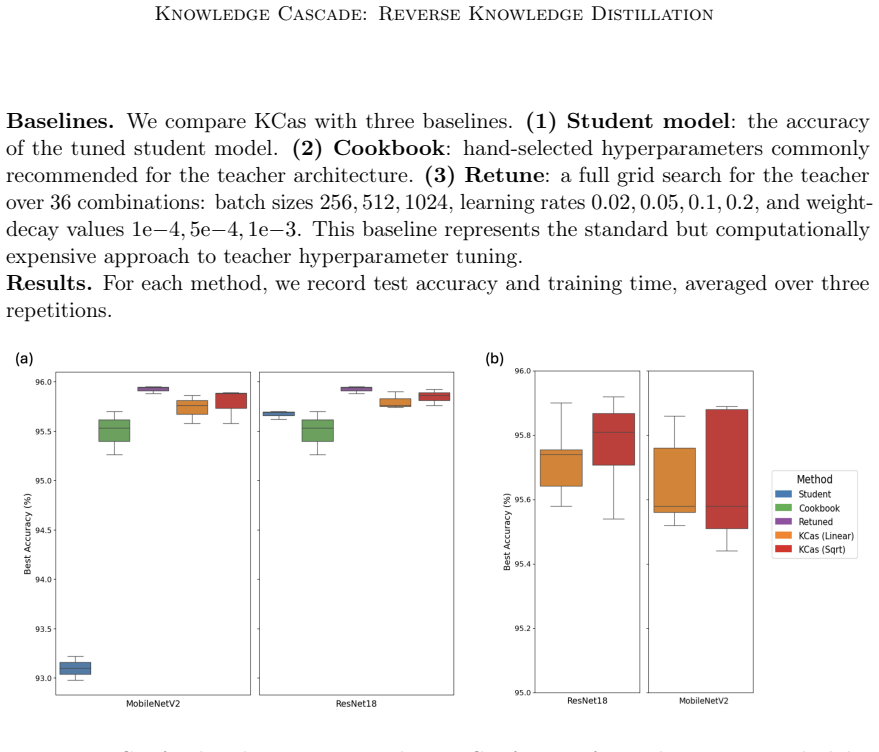
- [Simulations] Simulations section: strong empirical performance is reported, but the text provides neither error-bar information nor a direct risk comparison between KCas-transferred parameters and the full-sample optimum, leaving the weakest assumption (finite-sample accuracy of the scaling) unverified beyond point estimates.
minor comments (2)
- [Notation] Notation for the scaling constants (e.g., how E_p or the leading asymptotic term is defined) should be introduced earlier and used consistently across the spline, KDE, and DL examples.
- [Experiments] A short table summarizing the computational complexity before and after KCas for each example would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate planned revisions to clarify the theoretical claims and strengthen the empirical evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'theoretical guarantees are retained' is load-bearing for the central contribution, yet the abstract (and, per the provided text, the methods) supplies no derivation of the scaling law, no explicit error bound on the transferred λ, and no proof that the minimax rate is preserved up to o(1) factors in the multivariate case.
Authors: The derivation of the asymptotic scaling laws for smoothing parameters in the multivariate RKHS setting appears in Section 3, where the relationship between student and full-sample λ is established under standard eigenvalue decay conditions, along with an explicit high-probability bound on |λ_transferred − λ_opt| (Theorem 3.2) and a statement that the excess risk matches the full-sample minimax rate up to (1 + o(1)) factors (Corollary 3.3). We agree, however, that the abstract states the retention of guarantees without referencing these results. We will revise the abstract to include a concise statement of the key scaling-law guarantee and the rate preservation result. revision: yes
-
Referee: [Simulations] Simulations section: strong empirical performance is reported, but the text provides neither error-bar information nor a direct risk comparison between KCas-transferred parameters and the full-sample optimum, leaving the weakest assumption (finite-sample accuracy of the scaling) unverified beyond point estimates.
Authors: We agree that error bars from repeated runs and a direct side-by-side risk comparison between KCas-transferred parameters and the full-sample cross-validation optimum would provide clearer verification of finite-sample accuracy. In the revised manuscript we will add standard-error bars to the simulation figures and include a table (or additional panel) reporting the achieved risks for both procedures. revision: yes
Circularity Check
No significant circularity; asymptotic scaling laws are independent theoretical inputs
full rationale
The KCas transfer mechanism is explicitly grounded in asymptotic scaling relationships for optimal smoothing parameters in multivariate RKHS smoothing splines (and extensions to KDE and deep learning). These relationships are presented as consequences of standard bias-variance analysis rather than parameters fitted to the target full-sample risk, self-defined quantities, or load-bearing self-citations. No equation reduces the claimed prediction to a fit on the same data, and the abstract's retention of theoretical guarantees is framed as following from the external asymptotic theory. The derivation chain is therefore self-contained; the finite-sample accuracy concern raised by the skeptic is a correctness/verification issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Asymptotic scaling laws accurately map optimal smoothing parameters from small to large sample sizes in multivariate RKHS
Reference graph
Works this paper leans on
-
[1]
GPT- 4 technical report.arXiv preprint arXiv:2303.08774,
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT- 4 technical report.arXiv preprint arXiv:2303.08774,
-
[2]
doi: 10.48550/arXiv.2303.08774. URLhttps://arxiv.org/abs/2303.08774. Hirotogu Akaike. Information theory and an extension of the maximum likelihood principle. InSelected papers of Hirotugu Akaike, pages 199–213. Springer,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774
-
[3]
Ahmad Alzahrani and Samira Sadaoui. Scraping and preprocessing commercial auction data for fraud classification.arXiv preprint arXiv:1806.00656,
-
[4]
Short-term memory mechanisms in neural network learning of robot navigation tasks: A case study
Ananda L Freire, Guilherme A Barreto, Marcus Veloso, and Antonio T Varela. Short-term memory mechanisms in neural network learning of robot navigation tasks: A case study. In2009 6th Latin American Robotics Symposium (LARS 2009), pages 1–6. IEEE,
2009
-
[5]
Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677,
Priya Goyal, Piotr Dollár, Ross Girshick, Pieter Noordhuis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch, Yangqing Jia, and Kaiming He. Accurate, large minibatch sgd: Training imagenet in 1 hour.arXiv preprint arXiv:1706.02677,
-
[6]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783,
-
[7]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, Jeff Dean, et al. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2(7),
-
[8]
Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10,
32 Knowledge Cascade: Reverse Knowledge Distillation Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, DDL Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 10,
-
[9]
Towardsastatisticaltheoryofdata selection under weak supervision
GermainKolossov, AndreaMontanari, andPulkitTandon. Towardsastatisticaltheoryofdata selection under weak supervision. InInternational Conference on Learning Representations, volume 2024, pages 41947–41985,
2024
-
[10]
Deep double descent: Where bigger models and more data hurt.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124003,
Preetum Nakkiran, Gal Kaplun, Yamini Bansal, Tristan Yang, Boaz Barak, and Ilya Sutskever. Deep double descent: Where bigger models and more data hurt.Journal of Statistical Mechanics: Theory and Experiment, 2021(12):124003,
2021
-
[11]
Energy and policy considerations for deep learning in nlp.arXiv preprint arXiv:1906.02243,
Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in nlp.arXiv preprint arXiv:1906.02243,
Pith/arXiv arXiv 1906
-
[12]
Transformers: State-of-the-art natural language processing
35 F ang, Lu, Chen, Zhong and Ma Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, et al. Transformers: State-of-the-art natural language processing. InProceedings of the 2020 conference on empirical methods in natural language processing: system demonstrations...
2020
-
[13]
Shuo Yang, Zeke Xie, Hanyu Peng, Min Xu, Mingming Sun, and Ping Li. Dataset prun- ing: Reducing training data by examining generalization influence.arXiv preprint arXiv:2205.09329,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.