Improving Neural Network Training by Decoupling the Magnitude and Direction of Weight Vectors
Pith reviewed 2026-06-25 20:03 UTC · model grok-4.3
The pith
MD Decoupling separates magnitude from direction in each weight matrix so they can be updated at independent learning rates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
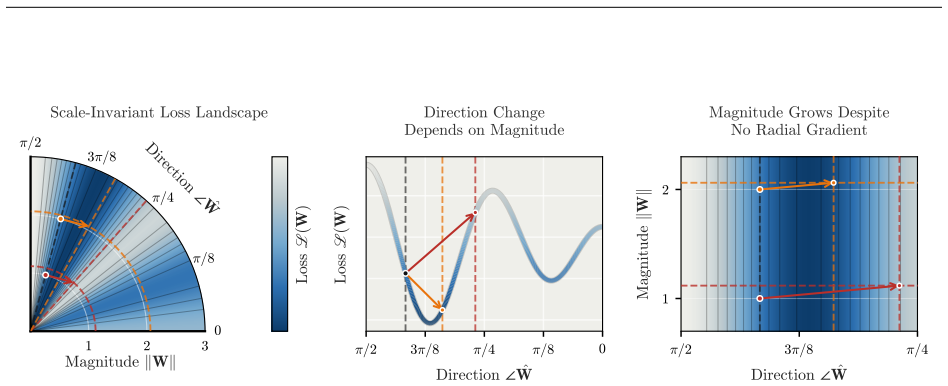
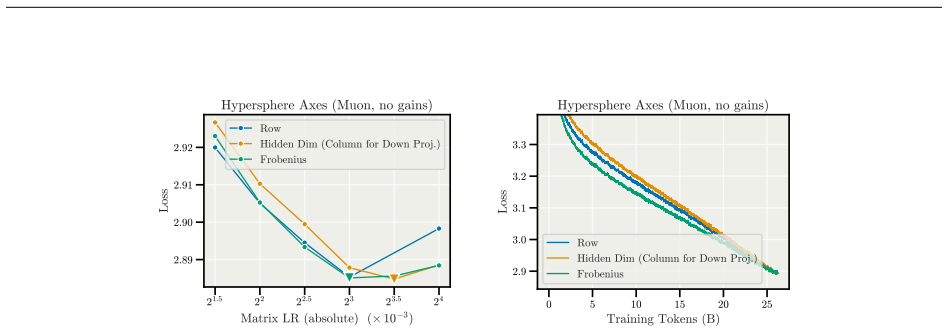
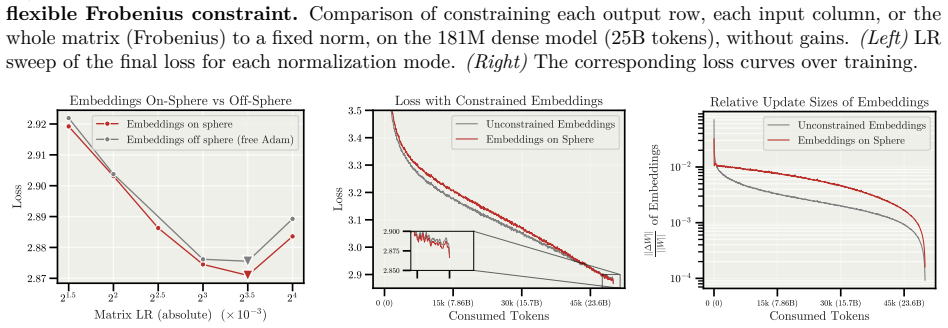
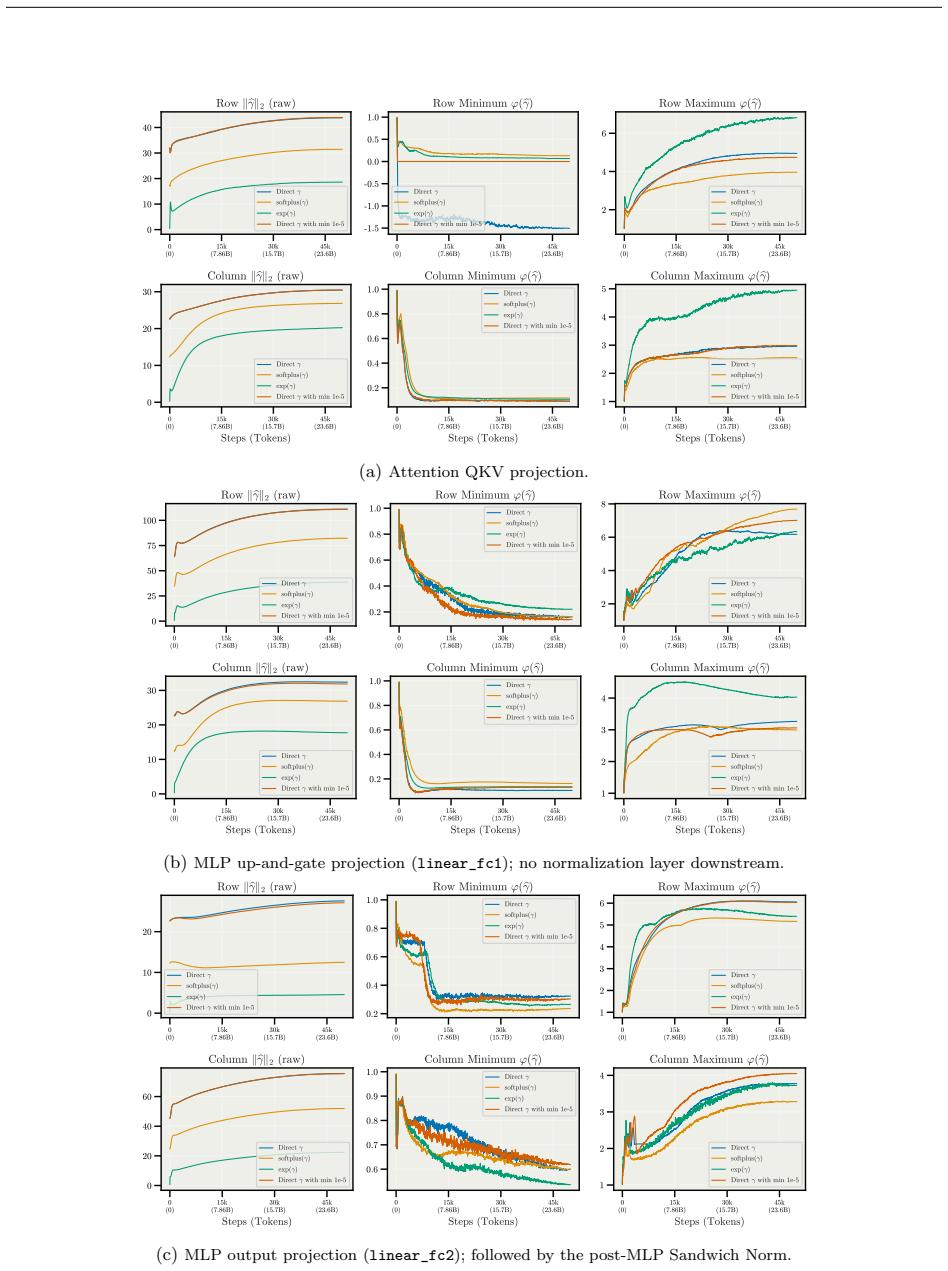
MD Decoupling factorizes each weight matrix into a fixed-norm direction on the hypersphere together with learnable per-row and per-column magnitude gains that are stepped at separate learning rates; the model still sees only the fused weight tensor, yet the separation removes the indirect coupling that normally forces reliance on weight decay and warmup.
What carries the argument
Magnitude-Direction (MD) Decoupling: the factorization of each weight into fixed-norm direction plus independently learned per-row and per-column magnitude gains.
If this is right
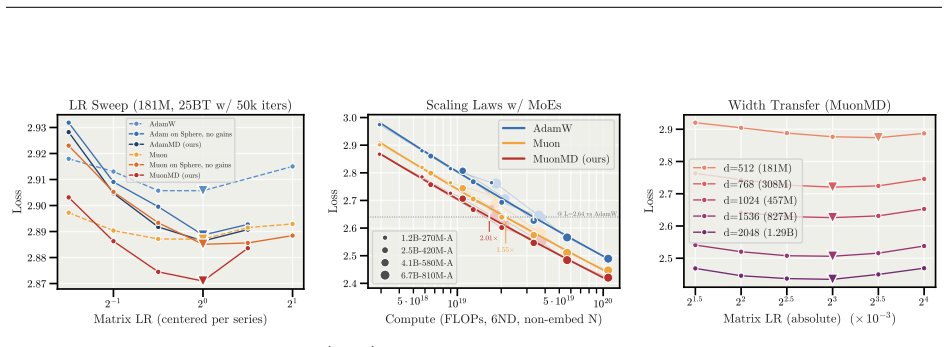
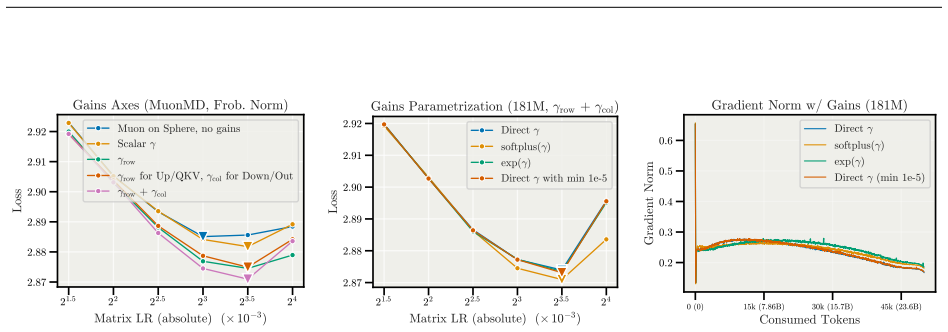
- Both Adam and Muon with MD Decoupling outperform their well-tuned baselines on the tested tasks.
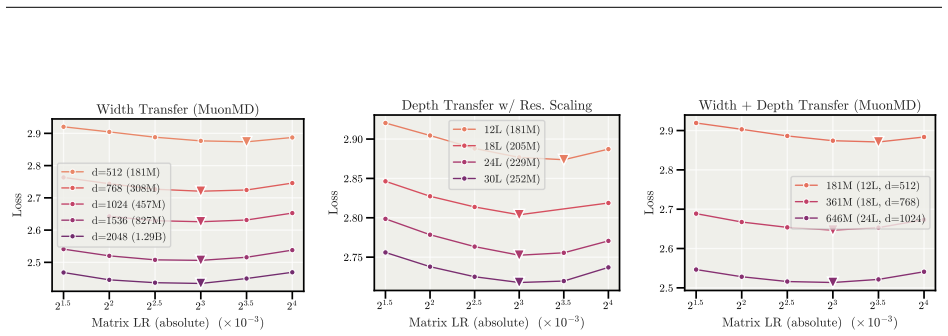
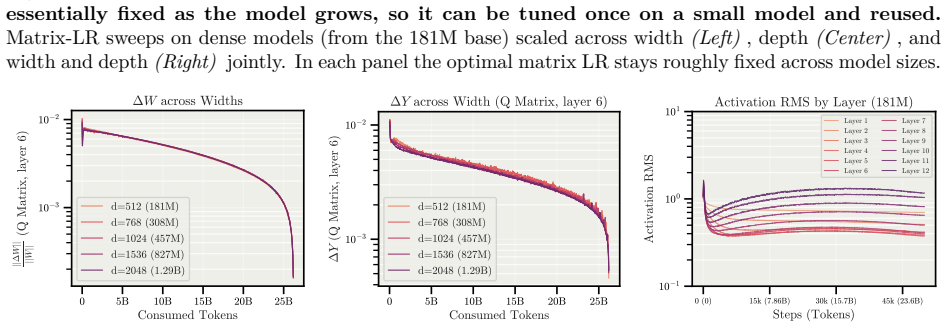
- The optimal learning rate found on one model width remains optimal when width changes, removing the need to retune.
- The same modification continues to improve training on large Mixture-of-Experts models.
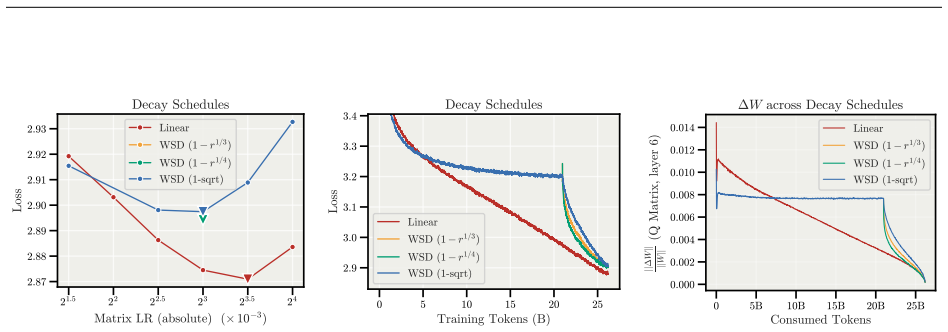
- Weight decay and warmup can be removed while training remains stable.
Where Pith is reading between the lines
- The same factorization could be tested on other first-order methods beyond Adam and Muon.
- If magnitude control becomes explicit, scale-related instabilities in very deep or wide networks may become easier to diagnose.
- Training recipes that currently rely on normalization layers to absorb all scale changes might be simplified.
Load-bearing premise
Updating per-row and per-column magnitude gains at separate learning rates will produce more stable and transferable dynamics than the coupled updates performed by ordinary optimizers.
What would settle it
A controlled run on a standard benchmark where MD Decoupling either matches or underperforms a well-tuned baseline after removing weight decay and warmup, or where the optimal learning rate still changes when model width is varied.
Figures

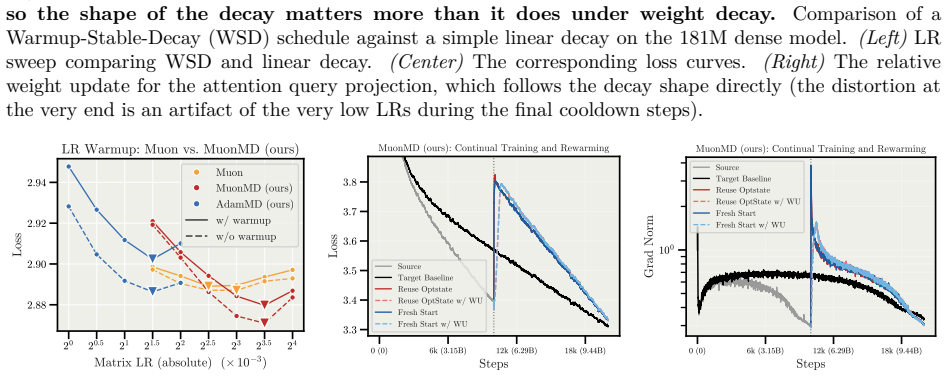
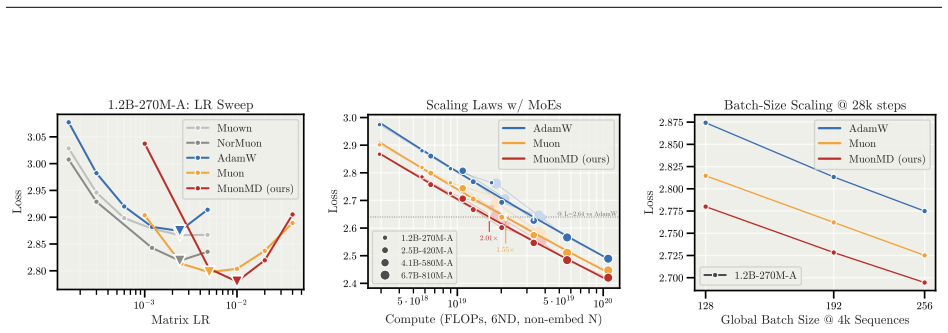
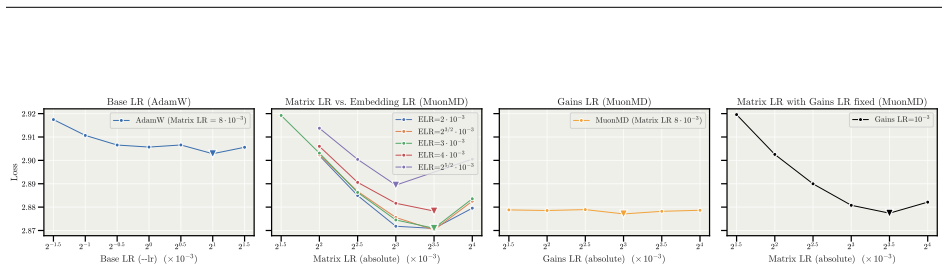
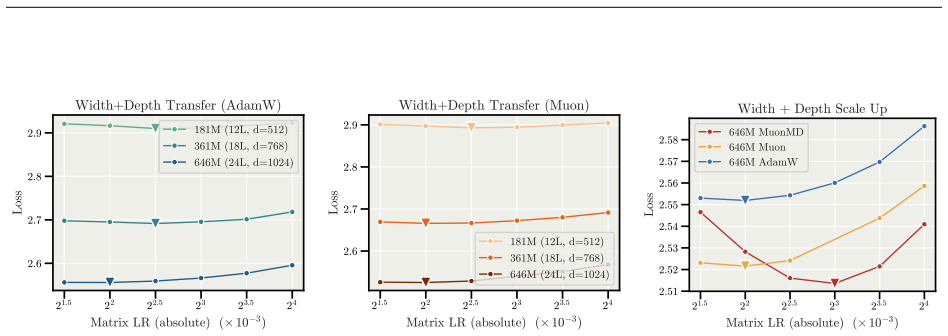
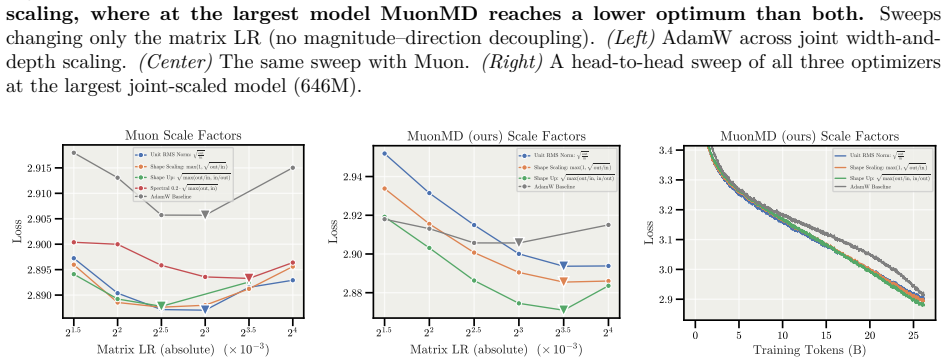
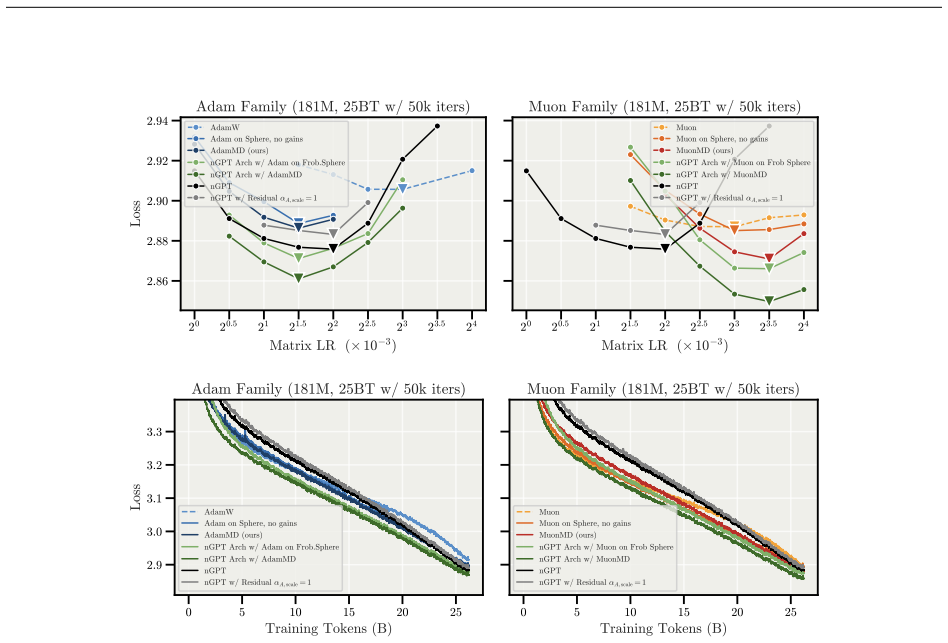
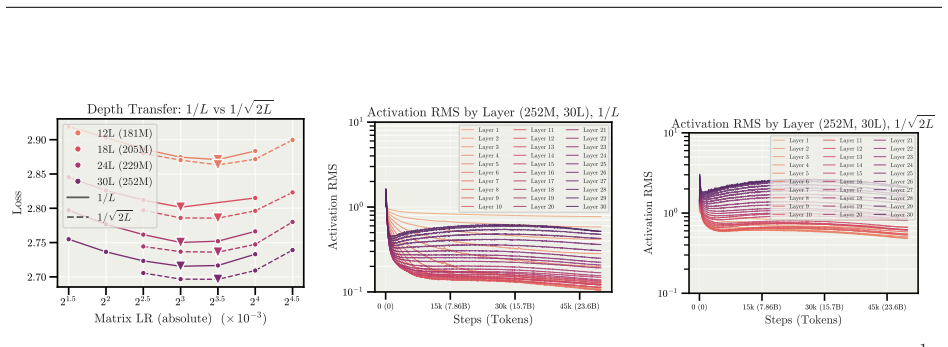
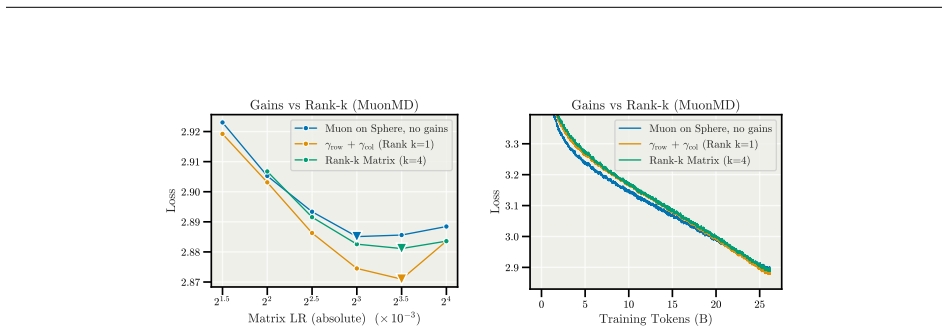
read the original abstract
Modern neural network training relies on optimizers such as Adam and Muon which act on each weight matrix as a single object. Yet every weight matrix carries two distinct quantities -- a \emph{magnitude} and a \emph{direction} -- and all optimizers stepping in the matrix as a whole couple their dynamics: the directional change from an update depends on the current magnitude, while the magnitude drifts as a byproduct of learning the direction, so neither is governed directly by the learning rate. Typical training therefore leans on surrounding recipes such as weight decay and warmup to keep learning stable at scale, though these regulate the coupling only indirectly; other recent methods instead constrain the weight to a fixed-norm sphere, but add no learnable magnitude, leaving scale control to normalization layers alone. We propose \emph{Magnitude--Direction (MD) Decoupling}, an optimizer modification that factorizes each weight into a fixed-norm direction on a hypersphere and learnable per-row and per-column magnitude gains, updated at separate learning rates, all while the model still sees a single fused weight tensor. The method is agnostic to the base optimizer and removes the need for weight decay and warmup. Across both Adam and Muon, MD Decoupling improves on well-tuned baselines, transfers the optimal LR across model width without retuning, and continues to help at scale on large Mixture-of-Experts (MoE) models. Treating magnitude and direction as separately controlled quantities thus yields more predictable training dynamics and a simple, broadly applicable improvement to modern optimizers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Magnitude-Direction (MD) Decoupling, a modification to optimizers such as Adam and Muon. Each weight matrix is factorized into a fixed-norm direction on the hypersphere plus learnable per-row and per-column magnitude gains that receive separate learning rates; the network still receives a single fused tensor at inference. The central claims are that this yields better performance than well-tuned baselines, eliminates the need for weight decay and warmup, transfers the optimal learning rate across model widths without retuning, and continues to help at the scale of large Mixture-of-Experts models.
Significance. If the reported gains survive controls that isolate the decoupling effect from the added per-row/column parameters and optimizer states, the approach would constitute a simple, optimizer-agnostic change that makes training dynamics more directly controllable and reduces reliance on indirect stabilization recipes. The empirical demonstration on both Adam and Muon plus scaling to MoE models would be a practical contribution to the optimizer literature.
major comments (3)
- [Abstract and Method] Abstract and Method description: MD Decoupling introduces additional trainable per-row and per-column magnitude parameters (and corresponding optimizer states) that are absent from the Adam/Muon baselines. The manuscript must clarify whether baselines were augmented with an equivalent number of extra parameters or whether an ablation demonstrates that the gains persist when parameter count is matched; otherwise the headline improvements, LR transfer, and MoE-scale benefits cannot be attributed to decoupling rather than increased capacity.
- [Abstract] Abstract: The claim that the method 'removes the need for weight decay and warmup' is load-bearing for the central thesis yet is stated without reference to the specific experimental controls (e.g., training curves or tables) that establish stable convergence in their absence. Explicit comparison of runs with and without these components under MD Decoupling versus baselines is required.
- [Experiments] Experiments section: The statements that optimal LR transfers across widths and that benefits continue at MoE scale rest on empirical results whose robustness (multiple seeds, error bars, or statistical tests) is not visible in the provided description. Tables reporting these quantities are needed to substantiate the transferability and scaling claims.
minor comments (1)
- [Method] The factorization into direction and magnitude gains would benefit from an explicit equation (e.g., W = D ⊙ M_row ⊙ M_col or equivalent) placed in the main text rather than left implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation and controls.
read point-by-point responses
-
Referee: [Abstract and Method] Abstract and Method description: MD Decoupling introduces additional trainable per-row and per-column magnitude parameters (and corresponding optimizer states) that are absent from the Adam/Muon baselines. The manuscript must clarify whether baselines were augmented with an equivalent number of extra parameters or whether an ablation demonstrates that the gains persist when parameter count is matched; otherwise the headline improvements, LR transfer, and MoE-scale benefits cannot be attributed to decoupling rather than increased capacity.
Authors: We agree that isolating the decoupling mechanism from the effect of added parameters is essential. The original experiments compared against standard Adam/Muon without extra parameters. In the revision we will add a controlled ablation in which the baselines are augmented with an equivalent number of extra learnable per-row/column parameters (updated at the same rate as the weights) and demonstrate that the reported gains, LR transfer, and MoE benefits remain attributable to the independent magnitude/direction updates and fixed-norm constraint. revision: yes
-
Referee: [Abstract] Abstract: The claim that the method 'removes the need for weight decay and warmup' is load-bearing for the central thesis yet is stated without reference to the specific experimental controls (e.g., training curves or tables) that establish stable convergence in their absence. Explicit comparison of runs with and without these components under MD Decoupling versus baselines is required.
Authors: We will revise the abstract to reference the supporting experiments and add explicit side-by-side comparisons (training curves and summary tables) in the Experiments section. These will show stable convergence of MD Decoupling without weight decay or warmup, contrasted with the divergence or degraded performance of the baselines under identical conditions, thereby providing the requested controls. revision: yes
-
Referee: [Experiments] Experiments section: The statements that optimal LR transfers across widths and that benefits continue at MoE scale rest on empirical results whose robustness (multiple seeds, error bars, or statistical tests) is not visible in the provided description. Tables reporting these quantities are needed to substantiate the transferability and scaling claims.
Authors: We acknowledge the importance of statistical robustness. The revised manuscript will include expanded tables for the width-transfer and MoE-scale experiments that report results across multiple random seeds, with means, standard deviations or error bars, and, where appropriate, statistical significance tests. This will directly substantiate the transferability and scaling claims. revision: yes
Circularity Check
No circularity: empirical algorithmic proposal validated externally
full rationale
The paper proposes an optimizer modification (MD Decoupling) that factorizes weights into fixed-norm directions plus learnable per-row/column magnitudes updated at separate rates. All claims of improvement, LR transfer, and scaling benefits are presented as outcomes of training runs on external benchmarks, not as mathematical predictions derived from the method itself. No equations, fitted parameters renamed as predictions, self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The central contribution is an algorithmic change whose value is measured by independent experiments rather than internal redefinition or construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- separate learning rate for magnitude gains
- per-row and per-column magnitude initialization
Reference graph
Works this paper leans on
-
[3]
Project Apertus, Alejandro Hern\'andez-Cano, Alexander H\"agele, Allen Hao Huang, Angelika Romanou, Antoni-Joan Solergibert i Llaquet, Barna P\'asztor, Bettina Messmer, Dhia Garbaya, Eduard Frank D urech, Ido Hakimi, Juan Garc\'ia Giraldo, Mete Ismayilzada, Negar Foroutan, Skander Moalla, Tiancheng Chen, Vinko Sabol c ec, Yixuan Xu, Michael Aerni, Badr Al...
arXiv 2026
-
[6]
Power lines: Scaling laws for weight decay and batch size in LLM pre-training
Shane Bergsma, Nolan Dey, Gurpreet Gosal, Gavia Gray, Daria Soboleva, and Joel Hestness. Power lines: Scaling laws for weight decay and batch size in LLM pre-training. arXiv preprint arXiv:2505.13738, 2025 a . URL https://arxiv.org/abs/2505.13738
arXiv 2025
-
[7]
Scaling with collapse: Efficient and predictable training of LLM families
Shane Bergsma, Bin Claire Zhang, Nolan Dey, Shaheer Muhammad, Gurpreet Gosal, and Joel Hestness. Scaling with collapse: Efficient and predictable training of LLM families. arXiv preprint arXiv:2509.25087, 2025 b . URL https://arxiv.org/abs/2509.25087
arXiv 2025
-
[8]
Jeremy Bernstein. Modular manifolds. Thinking Machines Lab: Connectionism, 2025. doi:10.64434/tml.20250926. https://thinkingmachines.ai/blog/modular-manifolds/
-
[10]
Damai Dai, Chengqi Deng, Chenggang Zhao, R. X. Xu, Huazuo Gao, Deli Chen, Jiashi Li, Wangding Zeng, Xingkai Yu, Y. Wu, et al. Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), pp.\ 1280--1297, 2024. URL https://arxiv.o...
Pith/arXiv arXiv 2024
-
[14]
Don't be lazy: CompleteP enables compute-efficient deep transformers
Nolan Dey, Bin Claire Zhang, Lorenzo Noci, Mufan Li, Blake Bordelon, Shane Bergsma, Cengiz Pehlevan, Boris Hanin, and Joel Hestness. Don't be lazy: CompleteP enables compute-efficient deep transformers. In Advances in Neural Information Processing Systems (NeurIPS), 2025. URL https://arxiv.org/abs/2505.01618
arXiv 2025
-
[15]
Improving our llm pretraining efficiency
Larry Dial. Improving our llm pretraining efficiency. https://www.openathena.ai/blog/pretraining-speedup/, jun 2026. Open Athena Blog
2026
-
[17]
Training dynamics of the cooldown stage in warmup-stable-decay learning rate scheduler
Aleksandr Dremov, Alexander H\"agele, Atli Kosson, and Martin Jaggi. Training dynamics of the cooldown stage in warmup-stable-decay learning rate scheduler. Transactions on Machine Learning Research, 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=ZnSYEcZod3
2025
-
[28]
Adamp: Slowing down the slowdown for momentum optimizers on scale-invariant weights
Byeongho Heo, Sanghyuk Chun, Seong Joon Oh, Dongyoon Han, Sangdoo Yun, Gyuwan Kim, Youngjung Uh, and Jung-Woo Ha. Adamp: Slowing down the slowdown for momentum optimizers on scale-invariant weights. In International Conference on Learning Representations (ICLR), 2021. URL https://arxiv.org/abs/2006.08217
arXiv 2021
-
[31]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. URL https://arxiv.org/abs/2106.09685
Pith/arXiv arXiv 2022
-
[32]
MiniCPM : Unveiling the potential of small language models with scalable training strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, et al. MiniCPM : Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395, 2024. URL https://arxiv.org/abs/2404.06395
Pith/arXiv arXiv 2024
-
[34]
Muon: An optimizer for hidden layers in neural networks
Keller Jordan, Yuchen Jin, Vlado Boza, Jiacheng You, Franz Cesista, Laker Newhouse, and Jeremy Bernstein. Muon: An optimizer for hidden layers in neural networks. https://kellerjordan.github.io/posts/muon/, 2024 a . URL https://kellerjordan.github.io/posts/muon/
2024
-
[35]
modded-nanogpt: Speedrunning the nanogpt baseline
Keller Jordan et al. modded-nanogpt: Speedrunning the nanogpt baseline. https://github.com/KellerJordan/modded-nanogpt, 2024 b . URL https://github.com/KellerJordan/modded-nanogpt
2024
-
[42]
On Balanced Representation Learning in Neural Networks
Atli Kosson. On Balanced Representation Learning in Neural Networks. PhD thesis, \'Ecole Polytechnique F\'ed\'erale de Lausanne (EPFL), 2026. URL https://infoscience.epfl.ch/entities/publication/2766967a-1920-4f95-bacf-60ecf7a40eaf
arXiv 2026
-
[54]
Normalization and effective learning rates in reinforcement learning
Clare Lyle, Zeyu Zheng, Khimya Khetarpal, James Martens, Hado van Hasselt, Razvan Pascanu, and Will Dabney. Normalization and effective learning rates in reinforcement learning. Advances in Neural Information Processing Systems (NeurIPS), 2024. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/c04d37be05ba74419d2d5705972a9d64-Abstract-Conference.html
2024
-
[55]
On the SDE s and scaling rules for adaptive gradient algorithms
Sadhika Malladi, Kaifeng Lyu, Abhishek Panigrahi, and Sanjeev Arora. On the SDE s and scaling rules for adaptive gradient algorithms. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pp.\ 7697--7711, 2022. URL https://arxiv.org/abs/2205.10287
arXiv 2022
-
[56]
Enhancing multilingual LLM pretraining with model-based data selection
Bettina Messmer, Vinko Sabol c ec, and Martin Jaggi. Enhancing multilingual LLM pretraining with model-based data selection. In Jonathan Gerber, Mark Cieliebak, Don Tuggener, and Manuela H \"u rlimann (eds.), Proceedings of the 10th edition of the Swiss Text Analytics Conference, pp.\ 31--56, Winterthur, Switzerland, May 2025. Association for Computationa...
2025
-
[63]
Training deep learning models with norm-constrained lmos
Thomas Pethick, Wanyun Xie, Kimon Antonakopoulos, Zhenyu Zhu, Antonio Silveti-Falls, and Volkan Cevher. Training deep learning models with norm-constrained lmos. In International Conference on Machine Learning, pp.\ 49069--49104. PMLR, 2025
2025
-
[65]
Zero: Memory optimizations toward training trillion parameter models, 2020
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models, 2020. URL https://arxiv.org/abs/1910.02054
Pith/arXiv arXiv 2020
-
[68]
The surprising agreement between convex optimization theory and learning-rate scheduling for large model training
Fabian Schaipp, Alexander H \"a gele, Adrien Taylor, Umut Simsekli, and Francis Bach. The surprising agreement between convex optimization theory and learning-rate scheduling for large model training. In International Conference on Machine Learning, pp.\ 53267--53294. PMLR, 2025
2025
-
[72]
Megatron- LM : Training multi-billion parameter language models using model parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron- LM : Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019. URL https://arxiv.org/abs/1909.08053
Pith/arXiv arXiv 1909
-
[75]
L2 regularization versus batch and weight normalization
Twan van Laarhoven. L2 regularization versus batch and weight normalization. arXiv preprint arXiv:1706.05350, 2017. URL https://arxiv.org/abs/1706.05350
Pith/arXiv arXiv 2017
-
[77]
SOAP : Improving and stabilizing shampoo using adam
Nikhil Vyas, Depen Morwani, Rosie Zhao, Mujin Kwun, Itai Shapira, David Brandfonbrener, Lucas Janson, and Sham Kakade. SOAP : Improving and stabilizing shampoo using adam. arXiv preprint arXiv:2409.11321, 2024. URL https://arxiv.org/abs/2409.11321
Pith/arXiv arXiv 2024
-
[78]
Spherical motion dynamics: Learning dynamics of normalized neural network using SGD and weight decay
Ruosi Wan, Zhanxing Zhu, Xiangyu Zhang, and Jian Sun. Spherical motion dynamics: Learning dynamics of normalized neural network using SGD and weight decay. In Advances in Neural Information Processing Systems (NeurIPS), 2021. URL https://arxiv.org/abs/2006.08419
arXiv 2021
-
[81]
How to set AdamW 's weight decay as you scale model and dataset size
Xi Wang and Laurence Aitchison. How to set AdamW 's weight decay as you scale model and dataset size. In International Conference on Machine Learning (ICML), 2025. URL https://arxiv.org/abs/2405.13698
arXiv 2025
-
[83]
Fantastic pretraining optimizers and where to find them 2.1: Hyperball optimization
Kaiyue Wen, Xingyu Dang, Kaifeng Lyu, Tengyu Ma, and Percy Liang. Fantastic pretraining optimizers and where to find them 2.1: Hyperball optimization. https://tinyurl.com/muonh, 2026. URL https://tinyurl.com/muonh
2026
-
[89]
Tensor programs VI : Feature learning in infinite-depth neural networks
Greg Yang, Dingli Yu, Chen Zhu, and Soufiane Hayou. Tensor programs VI : Feature learning in infinite-depth neural networks. In International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2310.02244
arXiv 2024
-
[94]
arXiv preprint arXiv:2605.11125 , year=
Language Modeling with Hyperspherical Flows , author=. arXiv preprint arXiv:2605.11125 , year=. 2605.11125 , archivePrefix=
-
[95]
International Conference on Machine Learning (ICML) , year=
Rotational Equilibrium: How Weight Decay Balances Learning Across Neural Networks , author=. International Conference on Machine Learning (ICML) , year=. 2305.17212 , archivePrefix=
-
[96]
arXiv preprint arXiv:2507.20534 , year=
Kimi K2: Open Agentic Intelligence , author=. arXiv preprint arXiv:2507.20534 , year=. 2507.20534 , archivePrefix=
-
[97]
Advances in Neural Information Processing Systems (NeurIPS) , year=
CogView: Mastering Text-to-Image Generation via Transformers , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 2105.13290 , archivePrefix=
-
[98]
International Conference on Machine Learning (ICML) , year=
Peri-LN: Revisiting Normalization Layer in the Transformer Architecture , author=. International Conference on Machine Learning (ICML) , year=. 2502.02732 , archivePrefix=
-
[99]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Analyzing and Improving the Training Dynamics of Diffusion Models , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 2312.02696 , archivePrefix=
-
[100]
International Conference on Learning Representations (ICLR) , year=
nGPT: Normalized Transformer with Representation Learning on the Hypersphere , author=. International Conference on Learning Representations (ICLR) , year=. 2410.01131 , archivePrefix=
-
[101]
2026 , howpublished =
Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization , author =. 2026 , howpublished =
2026
-
[102]
arXiv preprint arXiv:2603.28743 , year=
Rethinking Language Model Scaling under Transferable Hypersphere Optimization , author=. arXiv preprint arXiv:2603.28743 , year=. 2603.28743 , archivePrefix=
-
[103]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Scaling Laws and Compute-Optimal Training Beyond Fixed Training Durations , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 2405.18392 , archivePrefix=
-
[104]
International Conference on Machine Learning , pages=
The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[105]
Transactions on Machine Learning Research , issn=
Training Dynamics of the Cooldown Stage in Warmup-Stable-Decay Learning Rate Scheduler , author=. Transactions on Machine Learning Research , issn=. 2025 , url=
2025
-
[106]
arXiv preprint arXiv:2512.22382 , year=
Completed Hyperparameter Transfer across Modules, Width, Depth, Batch and Duration , author=. arXiv preprint arXiv:2512.22382 , year=. 2512.22382 , archivePrefix=
-
[107]
International Conference on Learning Representations (ICLR) , year=
Weight Decay may matter more than muP for Learning Rate Transfer in Practice , author=. International Conference on Learning Representations (ICLR) , year=. 2510.19093 , archivePrefix=
-
[108]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Analyzing & Reducing the Need for Learning Rate Warmup in GPT Training , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 2410.23922 , archivePrefix=
-
[109]
arXiv preprint arXiv:2605.10797 , year=
Muown: Row-Norm Control for Muon Optimization , author=. arXiv preprint arXiv:2605.10797 , year=. 2605.10797 , archivePrefix=
-
[110]
arXiv preprint arXiv:2606.23637 , year=
Muown Implicitly Performs Angular Step-size Decay , author=. arXiv preprint arXiv:2606.23637 , year=. 2606.23637 , archivePrefix=
-
[111]
arXiv preprint arXiv:2601.04890 , year=
Learnable Multipliers: Freeing the Scale of Language Model Matrix Layers , author=. arXiv preprint arXiv:2601.04890 , year=. 2601.04890 , archivePrefix=
-
[112]
arXiv preprint arXiv:2605.26895 , year=
Negligible in Size, Significant in Effect: On Scale Vectors in Large Language Models , author=. arXiv preprint arXiv:2605.26895 , year=. 2605.26895 , archivePrefix=
-
[113]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Learning in Compact Spaces with Approximately Normalized Transformer , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 2505.22014 , archivePrefix=
-
[114]
arXiv preprint arXiv:2511.18890 , year=
Nemotron-Flash: Towards Latency-Optimal Hybrid Small Language Models , author=. arXiv preprint arXiv:2511.18890 , year=. 2511.18890 , archivePrefix=
-
[115]
arXiv preprint arXiv:2601.23000 , year=
Mano: Restriking Manifold Optimization for LLM Training , author=. arXiv preprint arXiv:2601.23000 , year=. 2601.23000 , archivePrefix=
-
[116]
arXiv preprint arXiv:2601.08393 , year=
Controlled LLM Training on Spectral Sphere , author=. arXiv preprint arXiv:2601.08393 , year=. 2601.08393 , archivePrefix=
-
[117]
arXiv preprint arXiv:2409.20325 , year=
Old Optimizer, New Norm: An Anthology , author=. arXiv preprint arXiv:2409.20325 , year=. 2409.20325 , archivePrefix=
-
[118]
International Conference on Machine Learning , pages=
Training Deep Learning Models with Norm-Constrained LMOs , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[119]
2026 , month =
Dial, Larry , title =. 2026 , month =
2026
-
[120]
Thinking Machines Lab: Connectionism , year =
Jeremy Bernstein , title =. Thinking Machines Lab: Connectionism , year =
-
[121]
arXiv preprint arXiv:2507.13338 , year=
Training Transformers with Enforced Lipschitz Constants , author=. arXiv preprint arXiv:2507.13338 , year=. 2507.13338 , archivePrefix=
-
[122]
arXiv preprint arXiv:2603.09952 , year=
On the Width Scaling of Neural Optimizers Under Matrix Operator Norms I: Row/Column Normalization and Hyperparameter Transfer , author=. arXiv preprint arXiv:2603.09952 , year=. 2603.09952 , archivePrefix=
-
[123]
arXiv preprint arXiv:2503.17500 , year=
Variance Control via Weight Rescaling in LLM Pre-training , author=. arXiv preprint arXiv:2503.17500 , year=. 2503.17500 , archivePrefix=
-
[124]
International Conference on Machine Learning (ICML) , year=
Learning by Turning: Neural Architecture Aware Optimisation , author=. International Conference on Machine Learning (ICML) , year=. 2102.07227 , archivePrefix=
-
[125]
arXiv preprint arXiv:1708.03888 , year=
Large Batch Training of Convolutional Networks , author=. arXiv preprint arXiv:1708.03888 , year=. 1708.03888 , archivePrefix=
-
[126]
International Conference on Learning Representations (ICLR) , year=
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes , author=. International Conference on Learning Representations (ICLR) , year=. 1904.00962 , archivePrefix=
Pith/arXiv arXiv 1904
-
[127]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Scaling Vision Transformers , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 2106.04560 , archivePrefix=
-
[128]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Normalization and effective learning rates in reinforcement learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[129]
International Conference on Learning Representations (ICLR) , year=
AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights , author=. International Conference on Learning Representations (ICLR) , year=
-
[130]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 1602.07868 , archivePrefix=
-
[131]
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Decoupled Networks , author=. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=. 1804.08071 , archivePrefix=
-
[132]
arXiv preprint arXiv:1903.10520 , year=
Micro-Batch Training with Batch-Channel Normalization and Weight Standardization , author=. arXiv preprint arXiv:1903.10520 , year=. 1903.10520 , archivePrefix=
arXiv 1903
-
[133]
European Conference on Computer Vision (ECCV) , year=
Big Transfer (BiT): General Visual Representation Learning , author=. European Conference on Computer Vision (ECCV) , year=. 1912.11370 , archivePrefix=
arXiv 1912
-
[134]
International Conference on Learning Representations (ICLR) , year=
Spectral Normalization for Generative Adversarial Networks , author=. International Conference on Learning Representations (ICLR) , year=. 1802.05957 , archivePrefix=
-
[135]
International Conference on Learning Representations (ICLR) , year=
Artificial Kuramoto Oscillatory Neurons , author=. International Conference on Learning Representations (ICLR) , year=. 2410.13821 , archivePrefix=
-
[136]
2026 , url=
On Balanced Representation Learning in Neural Networks , author=. 2026 , url=
2026
-
[137]
2024 , howpublished=
Muon: An optimizer for hidden layers in neural networks , author=. 2024 , howpublished=
2024
-
[138]
2024 , howpublished=
modded-nanogpt: Speedrunning the NanoGPT baseline , author=. 2024 , howpublished=
2024
-
[139]
2026 , booktitle=
Project Apertus and Alejandro Hern\'andez-Cano and Alexander H\"agele and Allen Hao Huang and Angelika Romanou and Antoni-Joan Solergibert i Llaquet and Barna P\'asztor and Bettina Messmer and Dhia Garbaya and Eduard Frank. 2026 , booktitle=
2026
-
[140]
International Conference on Learning Representations (ICLR) , year=
Adam: A Method for Stochastic Optimization , author=. International Conference on Learning Representations (ICLR) , year=. 1412.6980 , archivePrefix=
-
[141]
International Conference on Learning Representations (ICLR) , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations (ICLR) , year=. 1711.05101 , archivePrefix=
-
[142]
2017 , eprint=
Loshchilov, Ilya and Hutter, Frank , booktitle=. 2017 , eprint=
2017
-
[143]
arXiv preprint arXiv:1607.06450 , year=
Layer Normalization , author=. arXiv preprint arXiv:1607.06450 , year=. 1607.06450 , archivePrefix=
-
[144]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Root Mean Square Layer Normalization , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 1910.07467 , archivePrefix=
Pith/arXiv arXiv 1910
-
[145]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 2203.03466 , archivePrefix=
-
[146]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Training Compute-Optimal Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=. 2203.15556 , archivePrefix=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.