Tensor network characterization and mitigation of readout errors
Pith reviewed 2026-06-25 19:57 UTC · model grok-4.3
The pith
A matrix product operator models correlated readout errors on quantum processors with near-linear sample cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
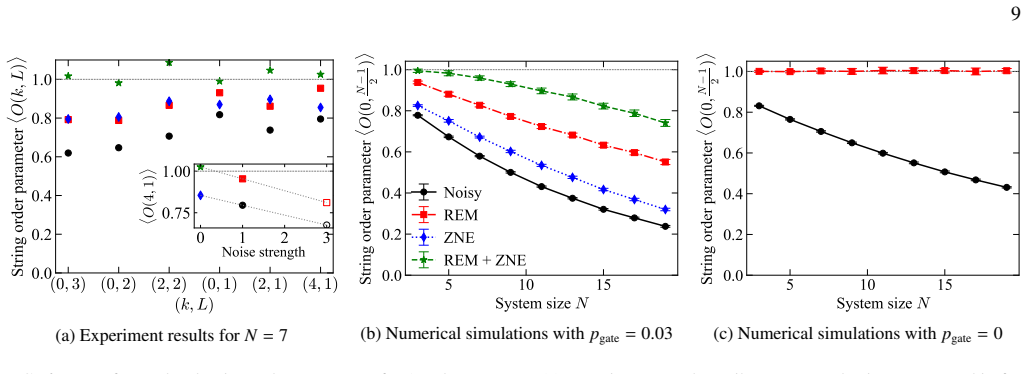
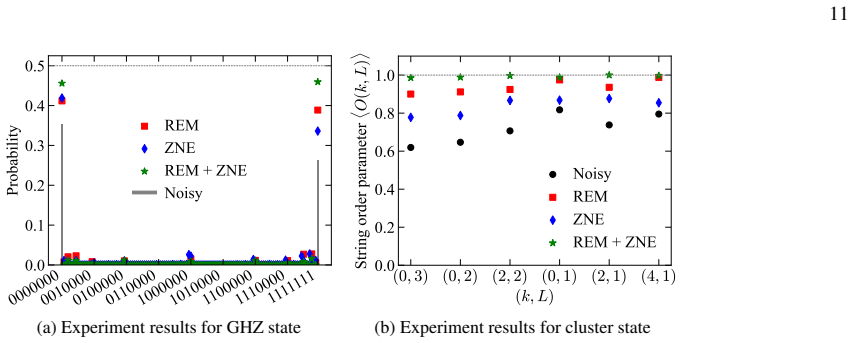
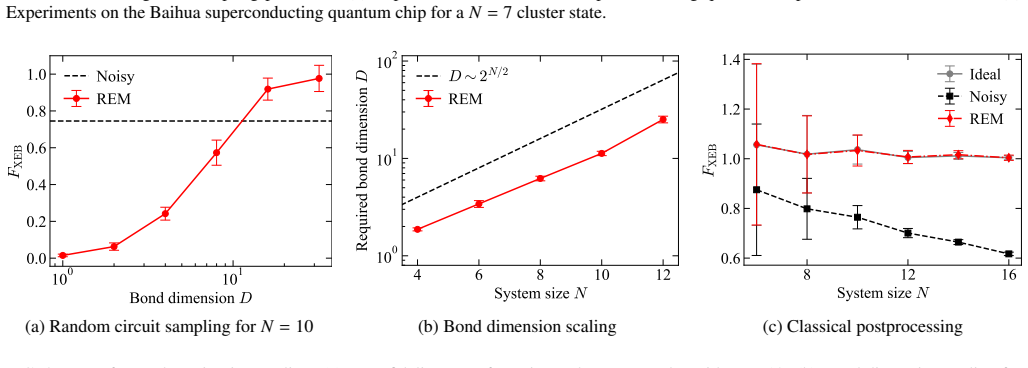
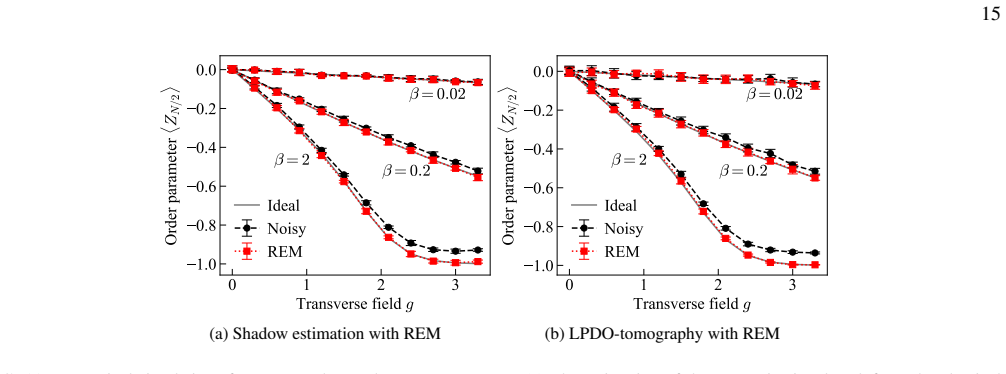
The readout process is represented as a matrix product operator that is trained on calibration data via likelihood maximization; the resulting model mitigates correlated errors in nonlocal observable estimation, random circuit sampling, classical shadows, and learning-based tomography, with experimental and numerical evidence that it outperforms uncorrelated models while requiring a sample cost that scales near-linearly with the number of qubits.
What carries the argument
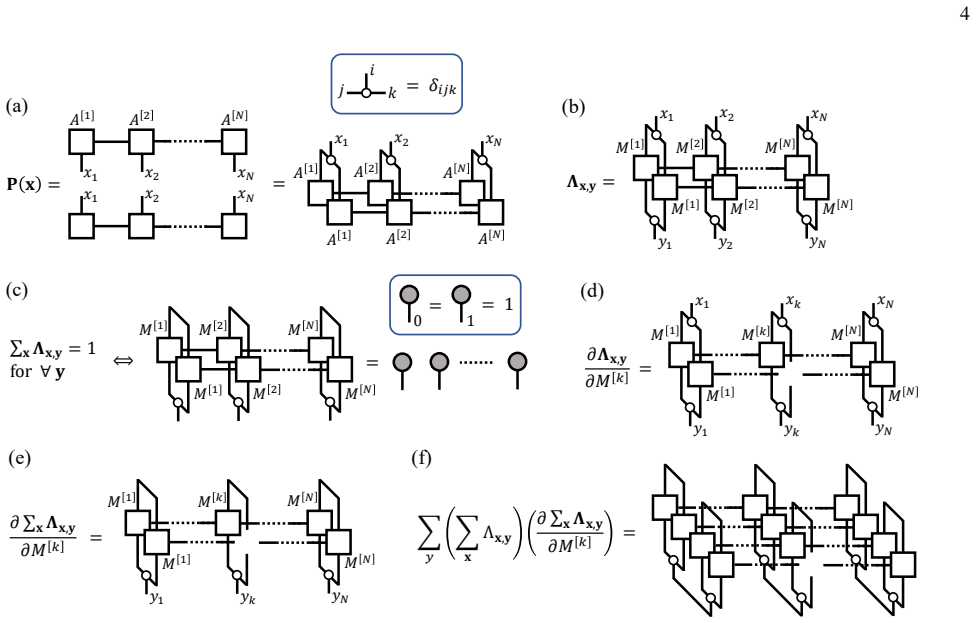
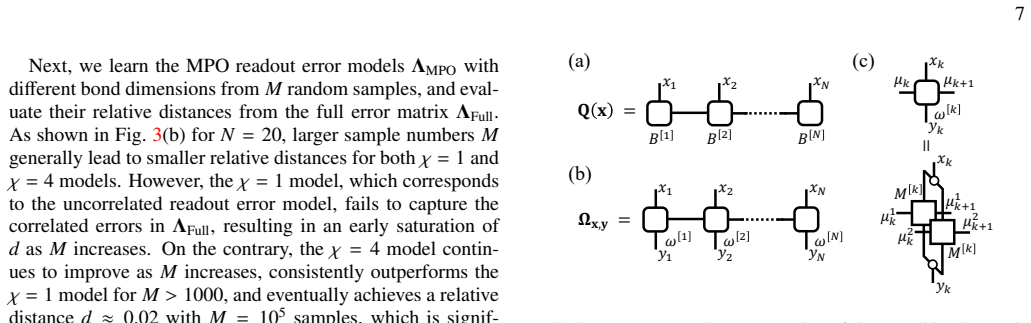
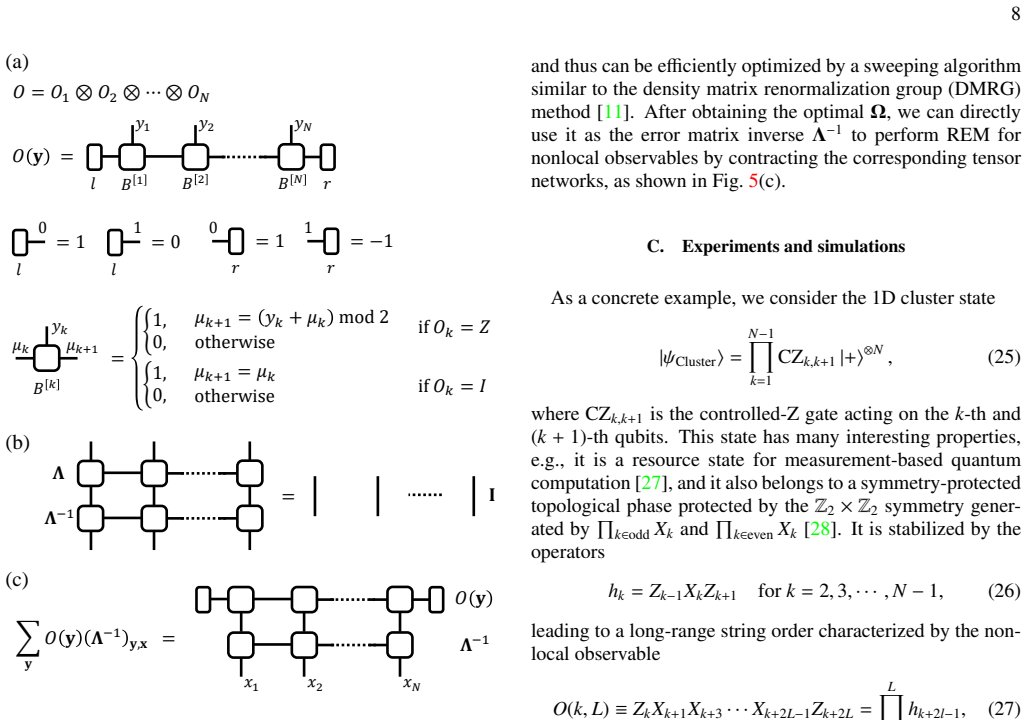
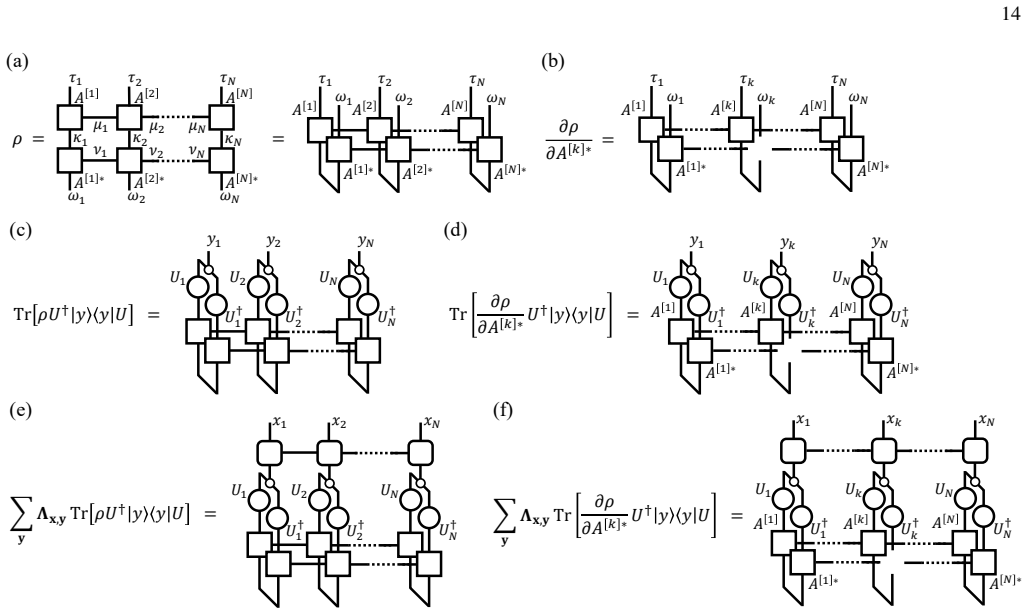
The matrix product operator (MPO) representation of the readout error channel, which encodes multi-qubit correlations in a compact tensor-train form that can be learned and applied efficiently.
If this is right
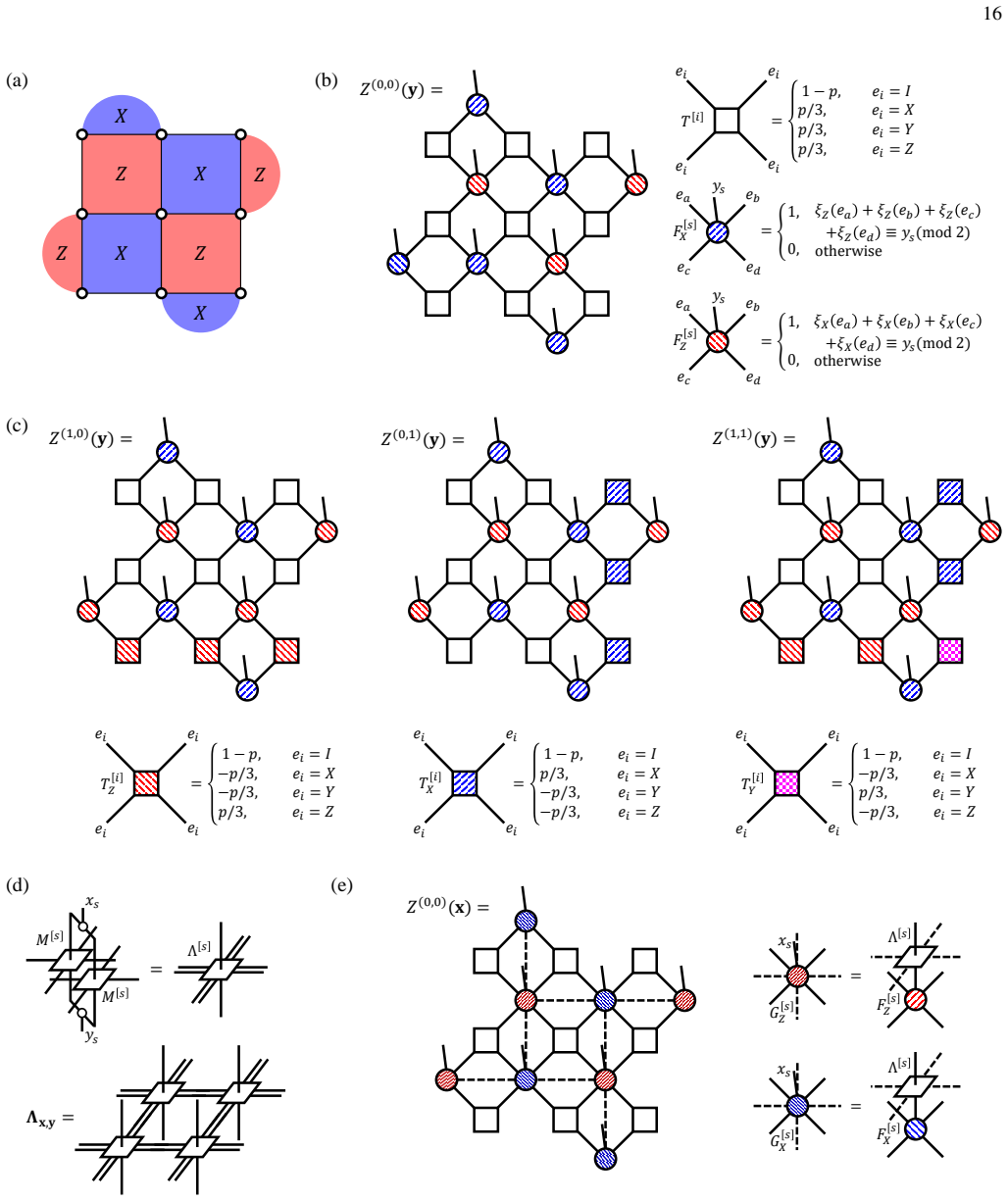
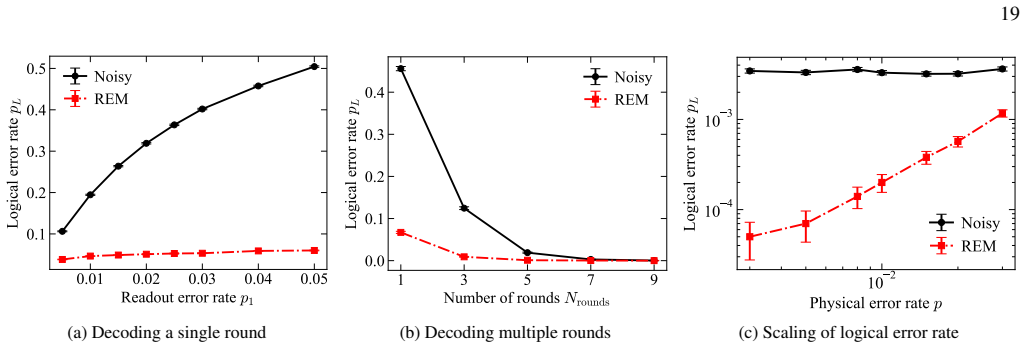
- The same MPO can be used for joint inference with tensor-network decoders on two-dimensional error-corrected systems.
- Nonlocal observables can be estimated with reduced bias once the MPO is learned.
- Random-measurement protocols such as classical shadows become noise-aware without exponential overhead.
- The sample complexity remains near-linear rather than exponential in system size when correlations are present.
Where Pith is reading between the lines
- The MPO construction might extend to modeling other spatially correlated noise sources such as gate errors or decoherence.
- Integration with existing tensor-network simulators could allow end-to-end noise-aware circuit optimization.
- If the bond dimension stays small on larger devices, the method offers a practical route to scalable readout correction without full process tomography.
Load-bearing premise
The actual readout error process admits an accurate low-bond-dimension matrix product operator description that can be recovered reliably from finite calibration measurements.
What would settle it
A direct comparison on the same 20-qubit superconducting device in which the MPO mitigation shows no improvement over independent-error mitigation or requires sample counts that grow exponentially with qubit number would falsify the central claim.
Figures

read the original abstract
Readout errors are a major bottleneck to extracting reliable information from near-term quantum processors, especially when spatial correlations are non-negligible. We present a unified tensor-network framework that models the readout process as a matrix product operator (MPO), enabling efficient characterization and mitigation beyond uncorrelated approximations. The MPO model is trained via likelihood optimization on calibration data and applies to multiple tasks, including nonlocal observable estimation, random circuit sampling, and random-measurement protocols, such as classical shadows and learning-based tomography. Experiments on a superconducting processor and numerical simulations up to 20 qubits show that the MPO model captures correlated readout errors that uncorrelated models miss, with a sample cost that grows only near-linearly with system size. When extended to two-dimensional systems, the framework can also be integrated with tensor-network quantum error-correction decoders by performing joint inference over data and readout errors. These results establish tensor-network readout error mitigation as a scalable and versatile approach for noise-aware quantum data processing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a tensor-network framework using matrix product operators (MPOs) to characterize and mitigate spatially correlated readout errors in quantum processors. The MPO is learned from calibration data via likelihood optimization and applied to tasks like observable estimation, random circuit sampling, and classical shadows. Experiments on superconducting processors and simulations up to 20 qubits claim that the model captures correlations missed by independent error models, with sample costs scaling near-linearly in system size. Extension to 2D systems with error-correction decoders is also discussed.
Significance. If the central claims hold, particularly the bounded bond dimension enabling near-linear scaling, this work offers a practical and scalable approach to readout error mitigation that goes beyond standard uncorrelated assumptions, potentially improving the reliability of near-term quantum computations involving correlated noise. The integration with tensor-network decoders is a notable strength for fault-tolerant contexts.
major comments (2)
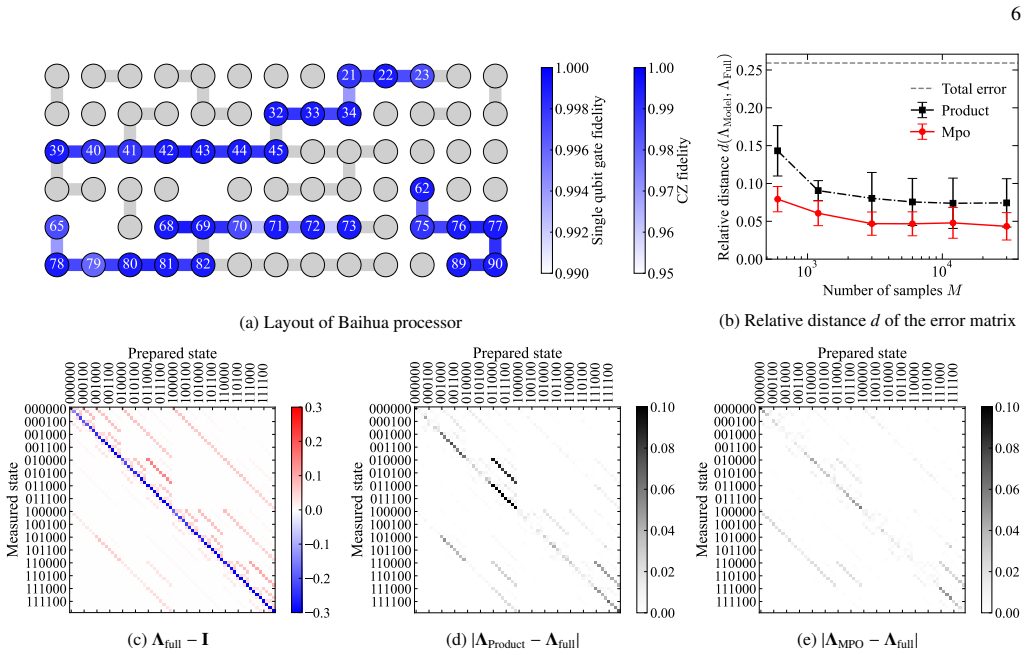
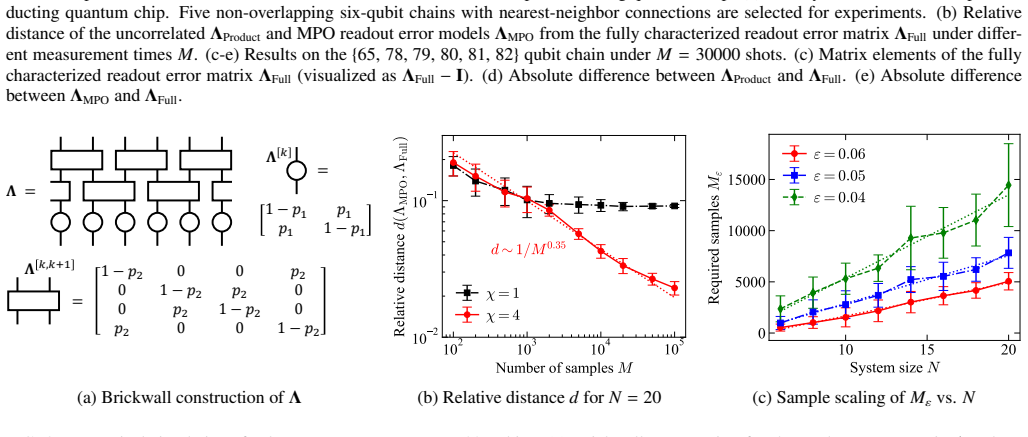
- [Numerical simulations and experiments] Numerical results up to 20 qubits: The headline claim of near-linear sample cost with system size requires that the MPO bond dimension χ remain O(1) or grow slowly so that the parameter count O(n χ²) stays linear. No table, plot, or reported values of χ(n) are provided to substantiate this, leaving the scaling assertion unsupported by the presented data.
- [Calibration and training] Training and validation procedure: The likelihood optimization on finite calibration shots is data-driven, yet no cross-validation, hold-out analysis, or overfitting diagnostics are described. This is load-bearing for the claim that the learned MPO reliably generalizes to mitigation tasks without model mismatch.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the typical bond dimensions employed, to allow readers to immediately assess the scaling claim.
Simulated Author's Rebuttal
We thank the referee for the constructive report and positive assessment of the work's potential. We address the two major comments below and will revise the manuscript to strengthen the supporting evidence for the scaling claims and training procedures.
read point-by-point responses
-
Referee: [Numerical simulations and experiments] Numerical results up to 20 qubits: The headline claim of near-linear sample cost with system size requires that the MPO bond dimension χ remain O(1) or grow slowly so that the parameter count O(n χ²) stays linear. No table, plot, or reported values of χ(n) are provided to substantiate this, leaving the scaling assertion unsupported by the presented data.
Authors: We agree that explicit reporting of the bond dimension χ(n) is necessary to substantiate the near-linear scaling. In the simulations and experiments, χ was kept small and bounded (typically χ ≤ 8 across n up to 20), yielding O(n) parameters. We will add a table and/or plot of the fitted χ values versus system size in the revised numerical results section to directly support the claim. revision: yes
-
Referee: [Calibration and training] Training and validation procedure: The likelihood optimization on finite calibration shots is data-driven, yet no cross-validation, hold-out analysis, or overfitting diagnostics are described. This is load-bearing for the claim that the learned MPO reliably generalizes to mitigation tasks without model mismatch.
Authors: The referee correctly notes the absence of explicit validation diagnostics. The original training used a fixed calibration dataset without reported hold-out splits. We will add a dedicated subsection on the training procedure that includes cross-validation results, hold-out performance metrics on mitigation tasks, and checks for overfitting to confirm generalization. revision: yes
Circularity Check
No significant circularity; claims rest on empirical validation
full rationale
The paper models readout errors as an MPO trained via likelihood optimization on calibration data and applies the model to tasks such as observable estimation and classical shadows. The headline claims (capture of correlated errors missed by uncorrelated models, near-linear sample cost) are presented as outcomes of experiments on a superconducting processor and simulations up to 20 qubits. No derivation step reduces a prediction to its inputs by construction, renames a fitted quantity, or relies on a load-bearing self-citation whose content is unverified; the framework remains data-driven with independent validation, so the derivation is self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Readout errors admit a low-bond-dimension MPO representation
Forward citations
Cited by 1 Pith paper
-
Repetition-code-based readout error detection and correction across hardware platforms and generations
Repetition-code encoding before measurement improves readout fidelity on IBM superconducting and Quantinuum trapped-ion processors, with larger code distances helping trapped ions more than superconductors.
Reference graph
Works this paper leans on
-
[1]
Kandala, A
A. Kandala, A. Mezzacapo, K. Temme, M. Takita, J. M. Chow, and J. M. Gambetta, Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets, Nature 549, 242 (2017)
2017
-
[2]
Aruteet al., Quantum supremacy using a programmable su- perconducting processor, Nature574, 505 (2019)
F. Aruteet al., Quantum supremacy using a programmable su- perconducting processor, Nature574, 505 (2019)
2019
-
[3]
Cerezo, A
M. Cerezo, A. Arrasmith, R. Babbush, S. C. Benjamin, S. Endo, K. Fujii, J. R. McClean, K. Mitarai, X. Yuan, L. Cincio, and P. J. Coles, Variational quantum algorithms, Nature Reviews Physics3, 625 (2021)
2021
-
[4]
Preskill, Quantum computing in the nisq era and beyond, Quantum2, 79 (2018)
J. Preskill, Quantum computing in the nisq era and beyond, Quantum2, 79 (2018)
2018
-
[5]
F. B. Maciejewski, Z. Zimbor ´as, and M. Oszmaniec, Mitiga- tion of readout noise in near-term quantum devices by classical post-processing based on detector tomography, Quantum4, 257 (2020)
2020
-
[6]
Bravyi, S
S. Bravyi, S. Sheldon, A. Kandala, D. C. Mckay, and J. M. Gambetta, Mitigating measurement errors in multiqubit experi- ments, Phys. Rev. A103, 042605 (2021)
2021
-
[7]
Huang, R
H.-Y . Huang, R. Kueng, and J. Preskill, Predicting many prop- erties of a quantum system from very few measurements, Nat. Phys.16, 1050 (2020)
2020
-
[8]
Torlai, C
G. Torlai, C. J. Wood, A. Acharya, G. Carleo, J. Carrasquilla, and L. Aolita, Quantum process tomography with unsupervised learning and tensor networks, Nat. Commun.14, 2858 (2023)
2023
-
[9]
Y . Chen, M. Farahzad, S. Yoo, and T.-C. Wei, Detector tomog- raphy on ibm quantum computers and mitigation of an imper- fect measurement, Phys. Rev. A100, 052315 (2019)
2019
-
[10]
F. B. Maciejewski, F. Baccari, Z. Zimbor´as, and M. Oszmaniec, Modeling and mitigation of cross-talk effects in readout noise with applications to the Quantum Approximate Optimization Algorithm, Quantum5, 464 (2021)
2021
-
[11]
Schollw ¨ock, The density-matrix renormalization group in the age of matrix product states, Ann
U. Schollw ¨ock, The density-matrix renormalization group in the age of matrix product states, Ann. Phys.326, 96 (2011), january 2011 Special Issue
2011
-
[12]
Or ´us, A practical introduction to tensor networks: Matrix product states and projected entangled pair states, Annals of Physics349, 117 (2014)
R. Or ´us, A practical introduction to tensor networks: Matrix product states and projected entangled pair states, Annals of Physics349, 117 (2014)
2014
-
[13]
Nachman, M
B. Nachman, M. Urbanek, W. A. de Jong, and C. W. Bauer, Un- folding quantum computer readout noise, npj Quantum Inform. 6, 84 (2020)
2020
-
[14]
P. D. Nation, H. Kang, N. Sundaresan, and J. M. Gambetta, Scalable mitigation of measurement errors on quantum com- puters, PRX Quantum2, 040326 (2021)
2021
-
[15]
Wuet al., Strong quantum computational advantage using a superconducting quantum processor, Phys
Y . Wuet al., Strong quantum computational advantage using a superconducting quantum processor, Phys. Rev. Lett.127, 180501 (2021)
2021
-
[16]
Hayden, D
P. Hayden, D. W. Leung, and A. Winter, Aspects of generic entanglement, Commun. Math. Phys.265, 95 (2006)
2006
-
[17]
A. W. Harrow and R. A. Low, Random quantum circuits are approximate 2-designs, Commun. Math. Phys.291, 257 (2009)
2009
-
[18]
Aaronson and L
S. Aaronson and L. Chen, Complexity-theoretic foundations of quantum supremacy experiments, inProceedings of the 32nd Computational Complexity Conference, CCC ’17 (Schloss Dagstuhl–Leibniz-Zentrum fuer Informatik, Dagstuhl, DEU, 2017)
2017
-
[19]
Gebhart, R
V . Gebhart, R. Santagati, A. A. Gentile, E. M. Gauger, D. Craig, N. Ares, L. Banchi, F. Marquardt, L. Pezz `e, and C. Bonato, Learning quantum systems, Nat. Rev. Phys.5, 141 (2023)
2023
-
[20]
Stoudenmire and D
E. Stoudenmire and D. J. Schwab, Supervised learning with ten- sor networks, inAdvances in Neural Information Processing Systems, V ol. 29, edited by D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett (Curran Associates, Inc., 2016)
2016
-
[21]
Z.-Y . Han, J. Wang, H. Fan, L. Wang, and P. Zhang, Unsuper- vised generative modeling using matrix product states, Phys. Rev. X8, 031012 (2018)
2018
-
[22]
P ´erez-Garc´ıa, F
D. P ´erez-Garc´ıa, F. Verstraete, M. M. Wolf, and J. I. Cirac, Ma- trix product state representations, Quantum Info. Comput.7, 401–430 (2007)
2007
-
[23]
Ignacio Cirac, D
J. Ignacio Cirac, D. Perez-Garcia, N. Schuch, and F. Verstraete, Matrix product unitaries: structure, symmetries, and topologi- cal invariants, J. Stat. Mech: Theory Exp.2017, 083105 (2017)
2017
-
[24]
D. P. Kingma and J. Ba, Adam: A method for stochastic opti- mization (2017), arXiv:1412.6980
Pith/arXiv arXiv 2017
-
[25]
Chen, Y .-H
C.-T. Chen, Y .-H. Shi, Z. Xiang, Z.-A. Wang, T.-M. Li, H.-Y . Sun, T.-S. He, X. Song, S. Zhao, D. Zheng, K. Xu, and H. Fan, 21 Scq cloud quantum computation for generating greenberger- horne-zeilinger states of up to 10 qubits, Sci. China-Phys. Mech. Astron.65, 110362 (2022)
2022
-
[26]
Guo and S
Y . Guo and S. Yang, Quantum error mitigation via matrix prod- uct operators, PRX Quantum3, 040313
-
[27]
Raussendorf and H
R. Raussendorf and H. J. Briegel, A one-way quantum com- puter, Phys. Rev. Lett.86, 5188 (2001)
2001
-
[28]
Chen, Z.-C
X. Chen, Z.-C. Gu, and X.-G. Wen, Classification of gapped symmetric phases in one-dimensional spin systems, Phys. Rev. B83, 035107 (2011)
2011
-
[29]
Temme, S
K. Temme, S. Bravyi, and J. M. Gambetta, Error mitigation for short-depth quantum circuits, Phys. Rev. Lett.119, 180509 (2017)
2017
-
[30]
Li and S
Y . Li and S. C. Benjamin, Efficient variational quantum simu- lator incorporating active error minimization, Phys. Rev. X7, 021050 (2017)
2017
-
[31]
Takagi, S
R. Takagi, S. Endo, S. Minagawa, and M. Gu, Fundamental lim- its of quantum error mitigation, npj Quantum Inf.8, 114 (2022)
2022
-
[32]
Z. Cai, R. Babbush, S. C. Benjamin, S. Endo, W. J. Huggins, Y . Li, J. R. McClean, and T. E. O’Brien, Quantum error mitiga- tion, Rev. Mod. Phys.95, 045005 (2023)
2023
-
[33]
Biamonte, P
J. Biamonte, P. Wittek, N. Pancotti, P. Rebentrost, N. Wiebe, and S. Lloyd, Quantum machine learning, Nature549, 195 (2017)
2017
-
[34]
Benedetti, E
M. Benedetti, E. Lloyd, S. Sack, and M. Fiorentini, Parame- terized quantum circuits as machine learning models, Quantum Sci. Technol.4, 043001 (2019)
2019
-
[35]
Cerezo, G
M. Cerezo, G. Verdon, H.-Y . Huang, L. Cincio, and P. J. Coles, Challenges and opportunities in quantum machine learning, Nat. Comput. Sci.2, 567 (2022)
2022
-
[36]
Torlai and R
G. Torlai and R. G. Melko, Machine-learning quantum states in the nisq era, Annu. Rev. Condens. Matter Phys.11, 325 (2020)
2020
-
[37]
Sharir, Y
O. Sharir, Y . Levine, N. Wies, G. Carleo, and A. Shashua, Deep autoregressive models for the efficient variational simulation of many-body quantum systems, Phys. Rev. Lett.124, 020503 (2020)
2020
-
[38]
Roca-Jerat, M
S. Roca-Jerat, M. Gallego, F. Luis, J. Carrete, and D. Zueco, Transformer wave function for quantum long-range models, Phys. Rev. B110, 205147 (2024)
2024
-
[39]
A. W. Harrow and A. Montanaro, Quantum computational supremacy, Nature549, 203 (2017)
2017
-
[40]
Verstraete, J
F. Verstraete, J. J. Garc´ıa-Ripoll, and J. I. Cirac, Matrix product density operators: Simulation of finite-temperature and dissipa- tive systems, Phys. Rev. Lett.93, 207204 (2004)
2004
-
[41]
Guo and S
Y . Guo and S. Yang, Quantum state tomography with locally purified density operators and local measurements, Commun. Phys.7, 322 (2024)
2024
-
[42]
A. H. Werner, D. Jaschke, P. Silvi, M. Kliesch, T. Calarco, J. Eisert, and S. Montangero, Positive tensor network approach for simulating open quantum many-body systems, Phys. Rev. Lett.116, 237201 (2016)
2016
-
[43]
Guo and S
Y . Guo and S. Yang, Locally purified density operators for noisy quantum circuits, Chin. Phys. Lett.41, 120302 (2024)
2024
-
[44]
Guo, J.-H
Y . Guo, J.-H. Zhang, H.-R. Zhang, S. Yang, and Z. Bi, Locally purified density operators for symmetry-protected topological phases in mixed states, Phys. Rev. X15, 021060 (2025)
2025
-
[45]
Suzuki, S
Y . Suzuki, S. Endo, K. Fujii, and Y . Tokunaga, Quantum er- ror mitigation as a universal error reduction technique: Appli- cations from the nisq to the fault-tolerant quantum computing eras, PRX Quantum3, 010345 (2022)
2022
-
[46]
M. A. Wahl, A. Mari, N. Shammah, W. J. Zeng, and G. S. Ravi, Zero noise extrapolation on logical qubits by scaling the error correction code distance, in2023 IEEE International Confer- ence on Quantum Computing and Engineering (QCE), V ol. 01 (2023) pp. 888–897
2023
-
[47]
Bravyi, M
S. Bravyi, M. Suchara, and A. Vargo, Efficient algorithms for maximum likelihood decoding in the surface code, Phys. Rev. A90, 032326 (2014)
2014
-
[48]
A. J. Ferris and D. Poulin, Tensor networks and quantum error correction, Phys. Rev. Lett.113, 030501 (2014)
2014
-
[49]
C. T. Chubb, General tensor network decoding of 2D Pauli codes (2021), arXiv:2101.04125
arXiv 2021
-
[50]
A. G. Fowler, M. Mariantoni, J. M. Martinis, and A. N. Cleland, Surface codes: Towards practical large-scale quantum compu- tation, Phys. Rev. A86, 032324 (2012)
2012
-
[51]
Google Quantum AI, Suppressing quantum errors by scaling a surface code logical qubit, Nature614, 676 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.