Deep Reinforcement Learning-Enhanced Event-Triggered Data-Driven Predictive Control for a 3D Cable-Driven Soft Robotic Arm
Pith reviewed 2026-06-29 04:39 UTC · model grok-4.3
The pith
A reinforcement learning policy triggers DeePC optimization only when needed for a 3D soft robotic arm, cutting computation frequency by up to 66 percent while preserving tracking accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
An RL policy trained entirely in simulation on state representations built from input-output trajectories can select event triggers for DeePC such that the optimizer runs far less often yet closed-loop tracking performance on a three-dimensional cable-driven soft arm remains comparable to periodic execution, with the policy transferring zero-shot to hardware and yielding more consistent results than a static threshold baseline.
What carries the argument
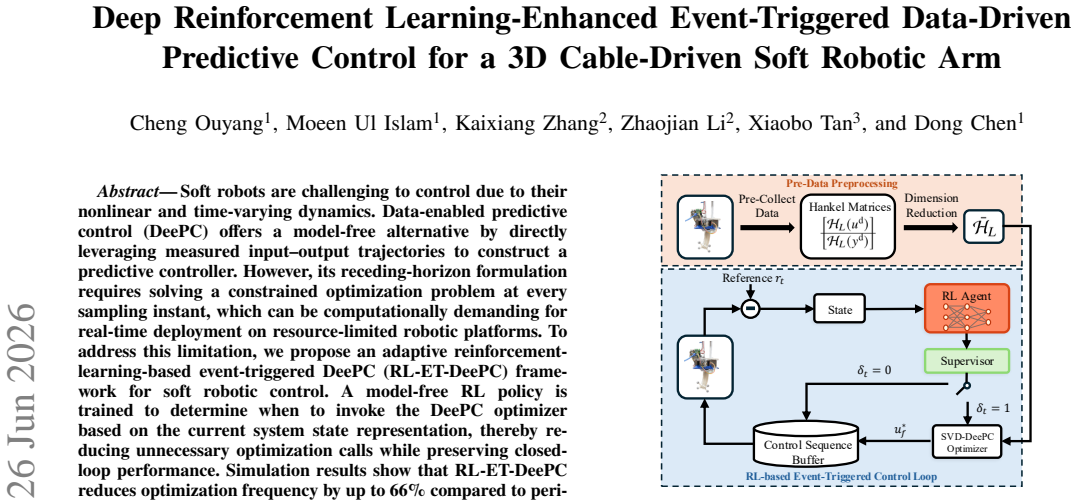
The RL-ET-DeePC framework, in which a model-free reinforcement learning policy outputs event-trigger decisions that decide whether to solve the DeePC quadratic program at each step.
If this is right
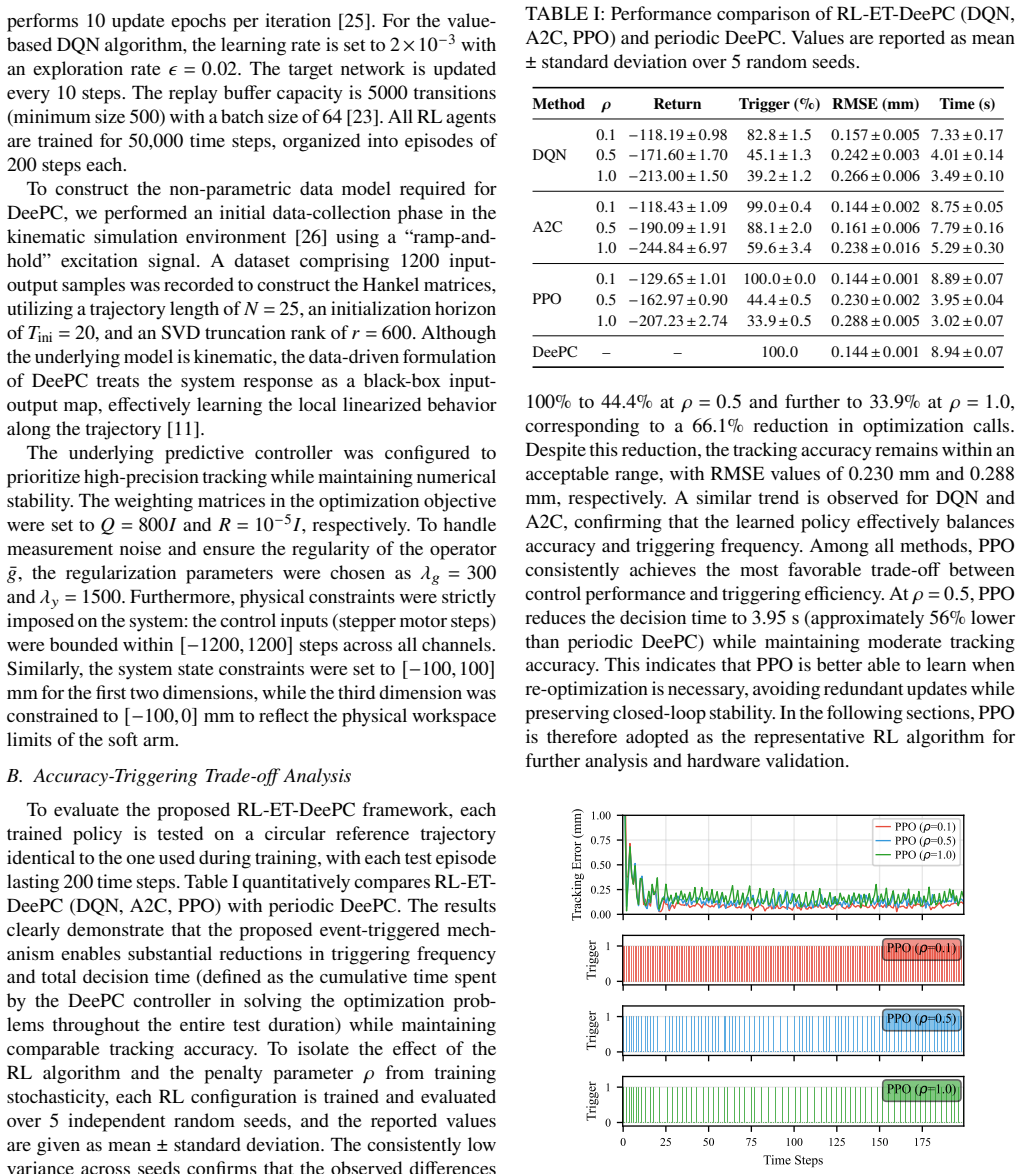
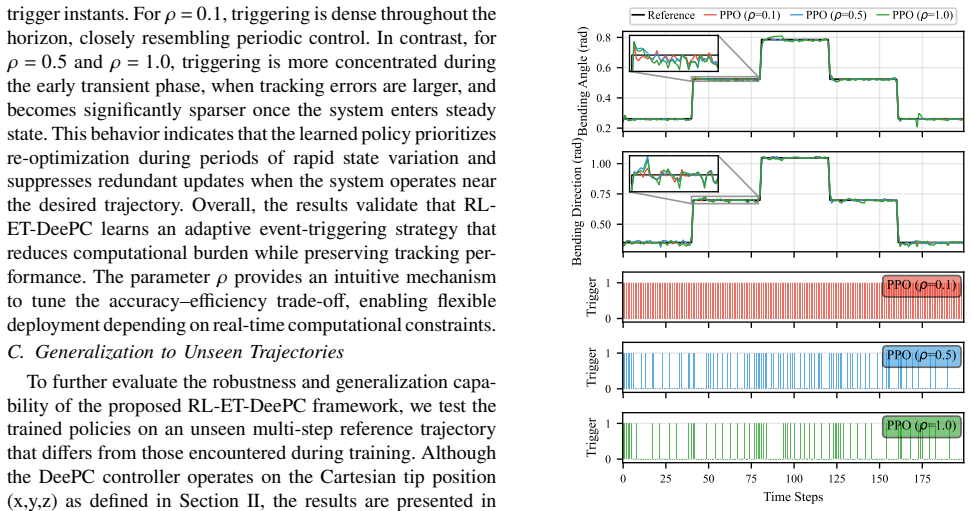
- Optimization frequency drops by up to 66 percent in simulation while tracking accuracy stays comparable to periodic DeePC.
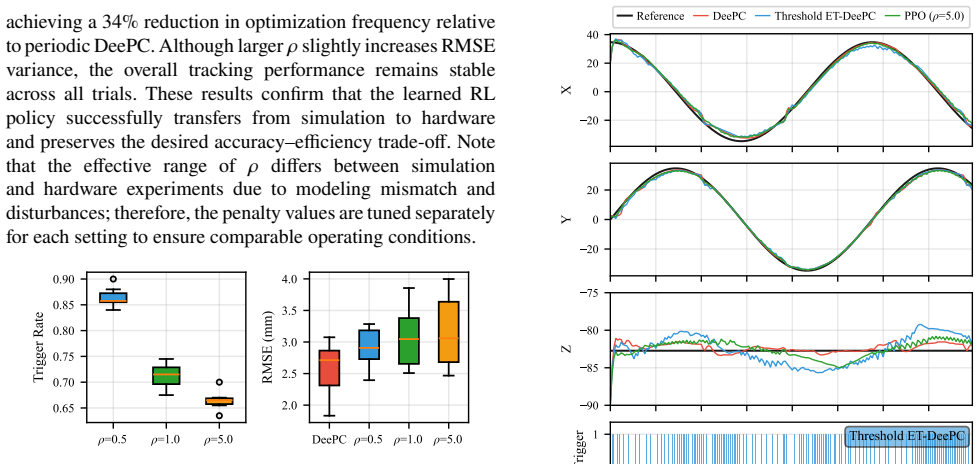
- Hardware tests achieve a 34 percent reduction with direct transfer from simulation training.
- Performance remains more consistent than a static threshold event-triggered baseline.
- The approach supports real-time deployment on resource-limited platforms by lowering the average computational load.
- The same input-output representation used for DeePC also supplies the state for the RL trigger policy.
Where Pith is reading between the lines
- The same RL-trigger idea could be attached to other receding-horizon data-driven controllers that solve optimizations at every step.
- If the policy generalizes across different cable routings or payload changes, it would reduce the need for repeated hardware data collection.
- Lower average optimization rate may translate into reduced power draw and thermal load on embedded processors.
- Testing the policy under larger external disturbances would reveal whether the learned triggers remain safe.
Load-bearing premise
A reinforcement learning policy trained only in simulation on input-output trajectory data will produce reliable triggering decisions when transferred directly to the physical soft robotic arm.
What would settle it
Hardware experiments in which tracking accuracy falls noticeably below periodic DeePC levels or in which the reduction in optimization frequency disappears would falsify the zero-shot transfer claim.
Figures



read the original abstract
Soft robots are challenging to control due to their nonlinear and time-varying dynamics. Data-enabled predictive control (DeePC) offers a model-free alternative by directly leveraging measured input-output trajectories to construct a predictive controller. However, its receding-horizon formulation requires solving a constrained optimization problem at every sampling instant, which can be computationally demanding for real-time deployment on resource-limited robotic platforms. To address this limitation, we propose an adaptive reinforcement-learning-based event-triggered DeePC (RL-ET-DeePC) framework for soft robotic control. A model-free RL policy is trained to determine when to invoke the DeePC optimizer based on the current system state representation, thereby reducing unnecessary optimization calls while preserving closed-loop performance. Simulation results show that RL-ET-DeePC reduces optimization frequency by up to 66% compared to periodic DeePC, while maintaining comparable tracking accuracy. Hardware experiments on a three-dimensional cable-driven soft robotic arm demonstrate zero-shot transfer, achieving a 34% reduction in optimization frequency with tracking accuracy comparable to periodic DeePC and more consistent performance than a static threshold-based event-triggered baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an RL-ET-DeePC framework that augments data-enabled predictive control (DeePC) with a model-free reinforcement learning policy to decide event-triggered invocations of the DeePC optimizer for a 3D cable-driven soft robotic arm. It reports that the approach reduces optimization frequency by up to 66% in simulation while preserving tracking accuracy, and achieves a 34% reduction in hardware experiments via zero-shot sim-to-real transfer, with performance comparable to periodic DeePC and more consistent than a static threshold baseline.
Significance. If the zero-shot transfer result holds under the reported conditions, the work would demonstrate a concrete method for lowering the online computational cost of DeePC on resource-limited soft-robot platforms without degrading closed-loop behavior; the hardware validation on a nonlinear, time-varying 3D system would be a useful data point for event-triggered data-driven control.
major comments (2)
- [Abstract] Abstract: the headline hardware claim of a 34% optimization-frequency reduction with zero-shot transfer and superior consistency rests on the unverified assumption that an RL policy trained on simulation-derived input-output state vectors will produce equivalent triggering decisions on the physical arm; no analysis of state-distribution shift, domain randomization, or trajectory equivalence is referenced, directly affecting both the frequency and consistency assertions.
- [Abstract] Abstract and methods description: quantitative performance claims (66% and 34% reductions, comparable tracking accuracy) are stated without any information on RL reward function, training algorithm and hyperparameters, state-feature construction from trajectories, number of training runs, or statistical variability (e.g., standard deviation across seeds), preventing verification that the reported gains are robust rather than artifacts of a single favorable trial.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive comments on our work. We address the major comments below and will revise the manuscript accordingly where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline hardware claim of a 34% optimization-frequency reduction with zero-shot transfer and superior consistency rests on the unverified assumption that an RL policy trained on simulation-derived input-output state vectors will produce equivalent triggering decisions on the physical arm; no analysis of state-distribution shift, domain randomization, or trajectory equivalence is referenced, directly affecting both the frequency and consistency assertions.
Authors: We acknowledge that the abstract does not explicitly reference an analysis of state-distribution shift or domain randomization. The state representation for the RL policy is constructed from input-output trajectories measured directly from the system in both simulation and hardware. The hardware experiments empirically demonstrate that the policy produces effective triggering decisions on the physical arm, achieving the reported 34% reduction with consistent performance. We will revise the abstract to better clarify the empirical validation of the zero-shot transfer based on the hardware results. revision: yes
-
Referee: [Abstract] Abstract and methods description: quantitative performance claims (66% and 34% reductions, comparable tracking accuracy) are stated without any information on RL reward function, training algorithm and hyperparameters, state-feature construction from trajectories, number of training runs, or statistical variability (e.g., standard deviation across seeds), preventing verification that the reported gains are robust rather than artifacts of a single favorable trial.
Authors: The referee correctly notes that the abstract and methods description do not include the requested details on the RL reward function, training algorithm, hyperparameters, state-feature construction, number of training runs, or statistical variability. We will revise the manuscript to incorporate these elements, adding descriptions of the reward function, the specific training algorithm and hyperparameters, how state features are constructed from trajectories, the number of training runs, and statistical measures such as standard deviations across multiple seeds. revision: yes
Circularity Check
No circularity: empirical performance claims rest on experiments, not self-referential derivations
full rationale
The paper applies established DeePC and RL methods to a soft-robot platform and reports empirical gains (66% sim, 34% hardware optimization-frequency reduction) from simulation and hardware trials. No load-bearing equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described claims; the central results are falsifiable experimental outcomes rather than quantities defined by construction from the same paper's inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Soft robotics in minimally invasive surgery,
M. Runciman, A. Darzi, and G. P. Mylonas, “Soft robotics in minimally invasive surgery,”Soft Robotics, vol. 6, no. 4, pp. 423–443, 2019
2019
-
[2]
Soft robotic grippers for biological sampling on deep reefs,
K. C. Galloway, K. P. Becker, B. Phillips, J. Kirby, S. Licht, D. Tchernov, R. J. Wood, and D. F. Gruber, “Soft robotic grippers for biological sampling on deep reefs,”Soft Robotics, vol. 3, no. 1, pp. 23–33, 2016
2016
-
[3]
Soft robotics: Review of fluid-driven intrinsically soft devices; manufac- turing, sensing, control, and applications in human-robot interaction,
P. Polygerinos, N. Correll, S. A. Morin, B. Mosadegh, C. D. Onal, K. Petersen, M. Cianchetti, M. T. Tolley, and R. F. Shepherd, “Soft robotics: Review of fluid-driven intrinsically soft devices; manufac- turing, sensing, control, and applications in human-robot interaction,” Advanced Engineering Materials, vol. 19, no. 12, p. 1700016, 2017
2017
-
[4]
Design, fabrication and control of soft robots,
D. Rus and M. T. Tolley, “Design, fabrication and control of soft robots,” Nature, vol. 521, no. 7553, pp. 467–475, 2015
2015
-
[5]
Control design for soft robots based on reduced-order model,
M. Thieffry, A. Kruszewski, C. Duriez, and T.-M. Guerra, “Control design for soft robots based on reduced-order model,”IEEE Robotics and Automation Letters, vol. 4, no. 1, pp. 25–32, 2018
2018
-
[6]
Soft robotics: Biological inspiration, state of the art, and future research,
D. Trivedi, C. D. Rahn, W. M. Kier, and I. D. Walker, “Soft robotics: Biological inspiration, state of the art, and future research,”Applied Bionics and Biomechanics, vol. 5, no. 3, pp. 99–117, 2008
2008
-
[7]
Real-time dynamics of soft and continuum robots based on cosserat rod models,
J. Till, V. Aloi, and C. Rucker, “Real-time dynamics of soft and continuum robots based on cosserat rod models,”The International Journal of Robotics Research, vol. 38, no. 6, pp. 723–746, 2019
2019
-
[8]
Modeling and simulation of dynamics in soft robotics: A review of numerical approaches,
L. Qin, H. Peng, X. Huang, M. Liu, and W. Huang, “Modeling and simulation of dynamics in soft robotics: A review of numerical approaches,”Current Robotics Reports, vol. 5, no. 1, pp. 1–13, 2024
2024
-
[9]
Dynamics of continuum and soft robots: A strain parameterization based approach,
F. Boyer, V. Lebastard, F. Candelier, and F. Renda, “Dynamics of continuum and soft robots: A strain parameterization based approach,” IEEE Transactions on Robotics, vol. 37, no. 3, pp. 847–863, 2020
2020
-
[10]
Model-based control of soft robots: A survey of the state of the art and open challenges,
C. Della Santina, C. Duriez, and D. Rus, “Model-based control of soft robots: A survey of the state of the art and open challenges,”IEEE Control Systems Magazine, vol. 43, no. 3, pp. 30–65, 2023
2023
-
[11]
Data-enabled predictive control: In the shallows of the DeePC,
J. Coulson, J. Lygeros, and F. D¨orfler, “Data-enabled predictive control: In the shallows of the DeePC,” in2019 18th European Control Conference, 2019, pp. 307–312
2019
-
[12]
Behavioral systems theory in data-driven analysis, signal processing, and control,
I. Markovsky and F. D ¨orfler, “Behavioral systems theory in data-driven analysis, signal processing, and control,”Annual Reviews in Control, vol. 52, pp. 42–64, 2021
2021
-
[13]
Mechanical design and data-enabled predictive control of a planar soft robot,
H. Wang, K. Zhang, K. Lee, Y. Mei, K. Zhu, V. Srivastava, J. Sheng, and Z. Li, “Mechanical design and data-enabled predictive control of a planar soft robot,”IEEE Robotics and Automation Letters, vol. 9, no. 9, pp. 7923–7930, 2024
2024
-
[14]
Velocity-form data-enabled predictive control of soft robots under unknown external payloads,
H. Wang, K. Zhang, K. Lee, Y. Mei, V. Srivastava, J. Sheng, Z. Song, and Z. Li, “Velocity-form data-enabled predictive control of soft robots under unknown external payloads,”arXiv preprint arXiv:2510.04509, 2025
-
[15]
Direct data-driven predictive control for a three-dimensional cable-driven soft robotic arm,
C. Ouyang, M. U. Islam, D. Chen, K. Zhang, Z. Li, and X. Tan, “Direct data-driven predictive control for a three-dimensional cable-driven soft robotic arm,”arXiv preprint arXiv:2510.08953, 2025
-
[16]
Event-triggered model predictive control with deep reinforcement learning for autonomous driving,
F. Dang, D. Chen, J. Chen, and Z. Li, “Event-triggered model predictive control with deep reinforcement learning for autonomous driving,”IEEE Transactions on Intelligent Vehicles, vol. 9, no. 1, pp. 459–468, 2023
2023
-
[17]
Koopman-based event-triggered control from data,
Z. M. Manaa, A. M. Abdallah, M. Ismail, and S. E. Ferik, “Koopman-based event-triggered control from data,”arXiv preprint arXiv:2504.14334, 2025
-
[18]
Aperiodic data-driven model predictive control with feasibility and stability guarantees,
P. Wang, X. Ren, and D. Zheng, “Aperiodic data-driven model predictive control with feasibility and stability guarantees,”IEEE Transactions on Automation Science and Engineering, vol. 22, pp. 14 461–14 473, 2025
2025
-
[19]
Event-triggered data-driven predic- tive control for multirate systems: Theoretic analysis and experimental results,
Y. Yang, D. Shi, H. Yu, and L. Shi, “Event-triggered data-driven predic- tive control for multirate systems: Theoretic analysis and experimental results,”IEEE/ASME Transactions on Mechatronics, vol. 30, no. 4, pp. 2450–2460, 2025
2025
-
[20]
A note on persistency of excitation,
J. C. Willems, P. Rapisarda, I. Markovsky, and B. L. De Moor, “A note on persistency of excitation,”Systems & Control Letters, vol. 54, no. 4, pp. 325–329, 2005
2005
-
[21]
Dimension reduction for efficient data-enabled predictive control,
K. Zhang, Y. Zheng, C. Shang, and Z. Li, “Dimension reduction for efficient data-enabled predictive control,”IEEE Control Systems Letters, vol. 7, pp. 3277–3282, 2023
2023
-
[22]
A two- step event-triggered-based data-driven predictive control for power converters,
X. Liu, L. Qiu, Y. Fang, K. Wang, Y. Li, and J. Rodr ´ıguez, “A two- step event-triggered-based data-driven predictive control for power converters,”IEEE Transactions on Industrial Electronics, vol. 71, no. 11, pp. 13 545–13 555, 2024
2024
-
[23]
Human-level control through deep reinforcement learning,
V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529–533, 2015
2015
-
[24]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proxi- mal policy optimization algorithms,”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
Asynchronous methods for deep rein- forcement learning,
V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep rein- forcement learning,” inInternational Conference on Machine Learning. PmLR, 2016, pp. 1928–1937
2016
-
[26]
Design and nonlinear modeling of a modular cable-driven soft robotic arm,
X. Qi, Y. Mei, D. Chen, Z. Li, and X. Tan, “Design and nonlinear modeling of a modular cable-driven soft robotic arm,”IEEE/ASME Transactions on Mechatronics, vol. 29, no. 4, pp. 3083–3091, 2024
2024
-
[27]
G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schul- man, J. Tang, and W. Zaremba, “Openai gym,”arXiv preprint arXiv:1606.01540, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.