TryOnCrafter: Unleashing Camera Trajectories for Realistic Video Virtual Try-on via a Renderable 4D Try-on Proxy
Pith reviewed 2026-06-25 19:18 UTC · model grok-4.3
The pith
A renderable 4D try-on proxy enables photorealistic video virtual try-on under arbitrary camera trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
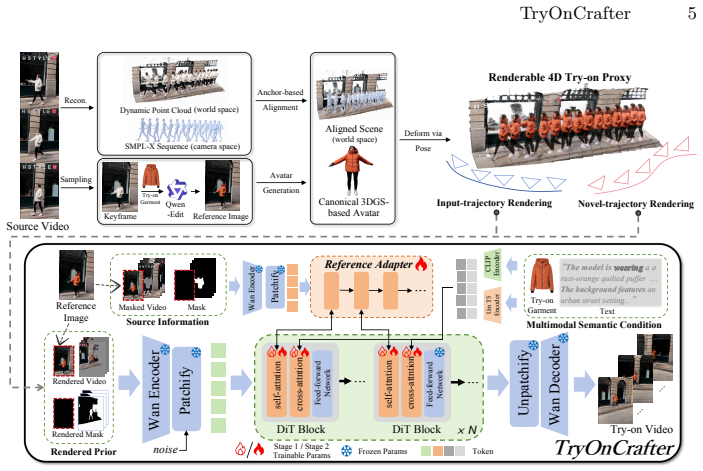
Distilling high-fidelity 2D try-on priors into a clothed 3DGS-based avatar animated via SMPL-X sequences and metric-aligned into a reconstructed background point cloud creates a robust structural foundation with superior texture density and motion integrity; the Proxy-Anchored Video DiT then uses this foundation as a primary geometric anchor to produce photorealistic videos strictly constrained by prescribed trajectories and physically plausible deformations.
What carries the argument
The Renderable 4D Try-on Proxy, which explicitly decouples the clothed human from the environment to serve as the geometric anchor for the diffusion video model.
Load-bearing premise
Distilling high-fidelity 2D try-on priors into a clothed 3DGS-based avatar animated via SMPL-X sequences and metric-aligned into a reconstructed background point cloud will provide a robust structural foundation with superior texture density and motion integrity under arbitrary unconstrained camera movements.
What would settle it
A generated video sequence in which garment texture, body pose, or background alignment visibly breaks when the camera follows a trajectory far from the original source path.
Figures






read the original abstract
While Video Virtual Try-on (VVT) has achieved remarkable progress in synthesizing realistic garment overlays on dynamic subjects, existing paradigms remains fundamentally constrained by a passive dependency on source camera trajectories, failing to accommodate the requisite interactive freedom for omnidirectional viewpoint exploration. To address this limitation, we define a pioneering research frontier: Camera-controllable Video Virtual Try-on (CaM-VVT). Unlike conventional VVT, CaM-VVT not only necessitates viewpoint-agnostic texture hallucination but also strict structural synchronization between non-rigid human dynamics and background contexts under arbitrary, unconstrained camera movements. To tackle these challenges, we present TryOnCrafter, the first unified DiT-based framework specifically architected for the CaM-VVT task. Departing from implicit pixel-space manipulation, we introduce a Renderable 4D Try-on Proxy that explicitly decouples the human subject from the environment. This is achieved by distilling high-fidelity 2D try-on priors into a clothed 3DGS-based avatar, which is subsequently animated via SMPL-X sequences and metric-aligned into a reconstructed background point cloud. This proxy establishes a robust structural foundation with superior texture density and motion integrity. Our Proxy-Anchored Video DiT leverages this robust structural foundation as a primary geometric anchor, ensuring that the synthesized photorealistic videos are strictly constrained by prescribed trajectories and physically plausible deformations. Benefiting from the inherent editability of the 4D proxy, TryOnCrafter facilitates diverse downstream applications, including human relocalization, ``bullet time'' effects, and $360$-degree orbital viewing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines a new task, Camera-controllable Video Virtual Try-on (CaM-VVT), which requires viewpoint-agnostic texture hallucination and structural synchronization under arbitrary camera trajectories. It presents TryOnCrafter, a DiT-based framework that constructs a Renderable 4D Try-on Proxy by distilling 2D try-on priors into a clothed 3DGS avatar animated via SMPL-X and metric-aligned to a background point cloud; this proxy then serves as a geometric anchor for a Proxy-Anchored Video DiT to generate photorealistic output videos, with additional editability enabling applications such as relocalization and 360-degree viewing.
Significance. If the 4D proxy construction and anchoring mechanism can be shown to deliver the claimed structural robustness and photorealism under free camera motion, the work would open a new direction in video virtual try-on by removing the passive dependency on source trajectories. The explicit decoupling of subject and environment via 3DGS and SMPL-X is a concrete architectural choice that could be reusable, but the manuscript supplies no empirical results, ablations, or implementation details with which to evaluate whether these benefits are realized.
major comments (2)
- [Abstract] Abstract: the central claim that the 4D proxy 'establishes a robust structural foundation with superior texture density and motion integrity' and that the Proxy-Anchored Video DiT 'ensures that the synthesized photorealistic videos are strictly constrained by prescribed trajectories and physically plausible deformations' is presented without any equations, algorithmic pseudocode, loss formulations, or experimental validation; this absence is load-bearing because the entire contribution rests on the unverified superiority and anchoring efficacy of the proxy.
- [Abstract] Abstract: no quantitative metrics, user studies, or comparisons against prior VVT methods are reported to substantiate claims of photorealism, structural synchronization, or superiority under unconstrained camera movements, rendering the assertion that TryOnCrafter is 'the first unified DiT-based framework specifically architected for the CaM-VVT task' impossible to assess.
minor comments (2)
- [Abstract] Grammatical error: 'existing paradigms remains fundamentally constrained' should read 'existing paradigms remain fundamentally constrained'.
- [Abstract] The abstract introduces several novel terms (CaM-VVT, Renderable 4D Try-on Proxy, Proxy-Anchored Video DiT) without providing even high-level definitions or distinctions from related concepts such as standard 3DGS or SMPL-X animation pipelines.
Simulated Author's Rebuttal
We thank the referee for the comments highlighting the need for clearer substantiation of claims in the abstract. The full manuscript provides the requested technical details, formulations, and experimental results in dedicated sections; we will revise the abstract to include explicit cross-references while preserving its conciseness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the 4D proxy 'establishes a robust structural foundation with superior texture density and motion integrity' and that the Proxy-Anchored Video DiT 'ensures that the synthesized photorealistic videos are strictly constrained by prescribed trajectories and physically plausible deformations' is presented without any equations, algorithmic pseudocode, loss formulations, or experimental validation; this absence is load-bearing because the entire contribution rests on the unverified superiority and anchoring efficacy of the proxy.
Authors: Abstracts are intentionally high-level and omit equations or pseudocode for brevity. The manuscript details the 4D proxy construction (distillation from 2D priors into 3DGS avatar animated by SMPL-X and aligned to background point cloud) with equations and the distillation algorithm in Section 3, the Proxy-Anchored Video DiT architecture and anchoring losses in Section 4, and empirical validation of texture density, motion integrity, and trajectory constraints via ablations and visualizations in Section 5. We will revise the abstract to reference these sections. revision: partial
-
Referee: [Abstract] Abstract: no quantitative metrics, user studies, or comparisons against prior VVT methods are reported to substantiate claims of photorealism, structural synchronization, or superiority under unconstrained camera movements, rendering the assertion that TryOnCrafter is 'the first unified DiT-based framework specifically architected for the CaM-VVT task' impossible to assess.
Authors: The full manuscript reports quantitative metrics (PSNR, SSIM, LPIPS for photorealism; trajectory alignment error for structural synchronization), user studies, and comparisons to prior VVT methods under free camera motion in Section 5, along with ablations on the 4D proxy. The 'first' claim follows from the novel CaM-VVT task definition and the explicit 4D proxy + DiT design. We will revise the abstract to briefly note key evaluation outcomes. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript text consists of high-level architectural description with no equations, parameter-fitting steps, uniqueness theorems, or self-citations. The Renderable 4D Try-on Proxy is introduced as a constructed component whose properties are asserted rather than derived from prior fitted quantities within the paper. No load-bearing claim reduces by construction to its own inputs, and the derivation chain is therefore self-contained at the level of a system proposal.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Renderable 4D Try-on Proxy
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Bai,J., Xia, M., Fu, X.,Wang, X.,Mu, L., Cao, J.,Liu, Z., Hu, H.,Bai, X., Wan, P., et al.: Recammaster: Camera-controlled generative rendering from a single video. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14834–14844 (2025)
2025
-
[2]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Cao, C., Zhou, J., Li, S., Liang, J., Yu, C., Wang, F., Xue, X., Fu, Y.: Uni3c: Unifying precisely 3d-enhanced camera and human motion controls for video gen- eration. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–12 (2025)
2025
-
[3]
In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Carreira, J., Zisserman, A.: Quo vadis, action recognition? a new model and the kinetics dataset. In: proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 6299–6308 (2017)
2017
-
[4]
In: European Conference on Computer Vision
Choi, Y., Kwak, S., Lee, K., Choi, H., Shin, J.: Improving diffusion models for authentic virtual try-on in the wild. In: European Conference on Computer Vision. pp. 206–235. Springer (2024)
2024
-
[5]
arXiv preprint arXiv:2501.11325 (2025)
Chong, Z., Zhang, W., Zhang, S., Zheng, J., Dong, X., Li, H., Wu, Y., Jiang, D., Liang, X.: Catv2ton: Taming diffusion transformers for vision-based virtual try-on with temporal concatenation. arXiv preprint arXiv:2501.11325 (2025)
arXiv 2025
-
[6]
arXiv preprint arXiv:2405.11794 (2024)
Fang, Z., Zhai, W., Su, A., Song, H., Zhu, K., Wang, M., Chen, Y., Liu, Z., Cao, Y., Zha, Z.J.: Vivid: Video virtual try-on using diffusion models. arXiv preprint arXiv:2405.11794 (2024)
arXiv 2024
-
[7]
arXiv preprint arXiv:2506.02528 (2025)
Gong, Y., Song, Y., Li, Y., Li, C., Zhang, Y.: Relationadapter: Learning and trans- ferring visual relation with diffusion transformers. arXiv preprint arXiv:2506.02528 (2025)
arXiv 2025
-
[8]
Guo,H.,Zeng,B.,Song,Y.,Zhang,W.,Zhang,C.,Liu,J.:Any2anytryon:Leverag- ingadaptivepositionembeddingsforversatilevirtualclothingtasks.arXivpreprint arXiv:2501.15891 (2025) 16 Sun et al
arXiv 2025
-
[9]
He, H., Xu, Y., Guo, Y., Wetzstein, G., Dai, B., Li, H., Yang, C.: Cameractrl: En- ablingcameracontrolfortext-to-videogeneration.arXivpreprintarXiv:2404.02101 (2024)
Pith/arXiv arXiv 2024
-
[10]
In: European Con- ference on Computer Vision
He, Z., Chen, P., Wang, G., Li, G., Torr, P.H., Lin, L.: Wildvidfit: Video virtual try-on in the wild via image-based controlled diffusion models. In: European Con- ference on Computer Vision. pp. 123–139. Springer (2024)
2024
-
[11]
Hou,C.,Chen,Z.:Training-freecameracontrolforvideogeneration.arXivpreprint arXiv:2406.10126 (2024)
arXiv 2024
-
[12]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Huang, S., Song, Y., Zhang, Y., Guo, H., Wang, X., Liu, J.: Arteditor: Learning customized instructional image editor from few-shot examples. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 17651–17662 (2025)
2025
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[14]
arXiv preprint arXiv:2410.21276 (2024)
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[15]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Jiang, T., Ho, H.I., Kaufmann, M., Song, J.: Prioravatar: Efficient and robust avatar creation from monocular video using learned priors. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–10 (2025)
2025
-
[16]
In: SIG- GRAPH Asia 2024 Conference Papers
Karras, J., Li, Y., Liu, N., Zhu, L., Yoo, I., Lugmayr, A., Lee, C., Kemelmacher- Shlizerman, I.: Fashion-vdm: Video diffusion model for virtual try-on. In: SIG- GRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[17]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kim, J., Gu, G., Park, M., Park, S., Choo, J.: Stableviton: Learning semantic correspondence with latent diffusion model for virtual try-on. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8176– 8185 (2024)
2024
-
[19]
arXiv preprint arXiv:2412.09262 (2024)
Li, C., Zhang, C., Xu, W., Lin, J., Xie, J., Feng, W., Peng, B., Chen, C., Xing, W.: Latentsync: Taming audio-conditioned latent diffusion models for lip sync with syncnet supervision. arXiv preprint arXiv:2412.09262 (2024)
arXiv 2024
-
[20]
arXiv preprint arXiv:2505.21325 (2025)
Li, G., Zheng, S., Zhang, H., Chen, J., Luan, J., Ou, B., Zhao, L., Li, B., Jiang, P.T.: Magictryon: Harnessing diffusion transformer for garment-preserving video virtual try-on. arXiv preprint arXiv:2505.21325 (2025)
arXiv 2025
-
[21]
Advances in neural information processing systems37, 75125–75151 (2024)
Li, X., Lai, Z., Xu, L., Qu, Y., Cao, L., Zhang, S., Dai, B., Ji, R.: Director3d: Real- world camera trajectory and 3d scene generation from text. Advances in neural information processing systems37, 75125–75151 (2024)
2024
-
[22]
IEEE Signal Processing Letters (2024)
Lin, J., Wu, Y., Wang, Z., Liu, X., Guo, Y.: Pair-id: A dual modal framework for identity preserving image generation. IEEE Signal Processing Letters (2024)
2024
-
[23]
arXiv preprint arXiv:2411.14208 (2024)
Liu, K., Shao, L., Lu, S.: Novel view extrapolation with video diffusion priors. arXiv preprint arXiv:2411.14208 (2024)
arXiv 2024
-
[24]
In: The Thirteenth International Conference on Learning Representations (2024)
Meng, Y., Zhu, Z., Hui, L., Hou, J.: Nvs-solver: Video diffusion model as zero-shot novel view synthesizer. In: The Thirteenth International Conference on Learning Representations (2024)
2024
-
[25]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Nguyen, H., Nguyen, Q.Q.V., Nguyen, K., Nguyen, R.: Swifttry: Fast and con- sistent video virtual try-on with diffusion models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 6200–6208 (2025) TryOnCrafter 17
2025
-
[26]
arXiv preprint arXiv:2503.10625 (2025)
Qiu, L., Gu, X., Li, P., Zuo, Q., Shen, W., Zhang, J., Qiu, K., Yuan, W., Chen, G., Dong, Z., et al.: Lhm: Large animatable human reconstruction model from a single image in seconds. arXiv preprint arXiv:2503.10625 (2025)
arXiv 2025
-
[27]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Qiu, L., Zhu, S., Zuo, Q., Gu, X., Dong, Y., Zhang, J., Xu, C., Li, Z., Yuan, W., Bo, L., et al.: Anigs: Animatable gaussian avatar from a single image with inconsistent gaussian reconstruction. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 21148–21158 (2025)
2025
-
[28]
arXiv preprint arXiv:2408.00714 (2024)
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
Pith/arXiv arXiv 2024
-
[29]
In: SIGGRAPH Asia 2024 Conference Papers
Shen,Z.,Pi,H.,Xia,Y.,Cen,Z.,Peng,S.,Hu,Z.,Bao,H.,Hu,R.,Zhou,X.:World- grounded human motion recovery via gravity-view coordinates. In: SIGGRAPH Asia 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[30]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Song, Q., Lin, M., Zhan, W., Yan, S., Cao, L., Ji, R.: Univst: A unified frame- work for training-free localized video style transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[31]
arXiv preprint arXiv:2503.06508 (2025)
Song, Q., Lin, Z., Zeng, Z., Zhang, Z., Cao, L., Ji, R.: Lightmotion: A light and tuning-free method for simulating camera motion in video generation. arXiv preprint arXiv:2503.06508 (2025)
arXiv 2025
-
[32]
arXiv preprint arXiv:2605.15824 (2026)
Song, Q., Shen, Y., Chen, M., Sun, H., Lan, J., Zhu, X., Zheng, B., Cao, L.: Fashionchameleon: Towards real-time and interactive human-garment video cus- tomization. arXiv preprint arXiv:2605.15824 (2026)
Pith/arXiv arXiv 2026
-
[33]
arXiv preprint arXiv:2511.22098 (2025)
Song, Q., Song, Y., Peng, K., Gao, Y., Shou, M.Z.: Worldwander: Bridging ego- centric and exocentric worlds in video generation. arXiv preprint arXiv:2511.22098 (2025)
arXiv 2025
-
[34]
arXiv preprint arXiv:2510.22994 (2025)
Song, Q., Zhou, D., Lin, J., Shen, F., Wang, J., Hu, X., Chen, C., Heng, P.A.: Scenedecorator: Towards scene-oriented story generation with scene planning and scene consistency. arXiv preprint arXiv:2510.22994 (2025)
arXiv 2025
-
[35]
arXiv preprint arXiv:2502.01572 (2025)
Song, Y., Liu, C., Shou, M.Z.: Makeanything: Harnessing diffusion transformers for multi-domain procedural sequence generation. arXiv preprint arXiv:2502.01572 (2025)
arXiv 2025
-
[36]
arXiv preprint arXiv:2503.20314 (2025)
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
Pith/arXiv arXiv 2025
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, J., Chen, M., Karaev, N., Vedaldi, A., Rupprecht, C., Novotny, D.: Vggt: Visual geometry grounded transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5294–5306 (2025)
2025
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, S., Leroy, V., Cabon, Y., Chidlovskii, B., Revaud, J.: Dust3r: Geometric 3d vision made easy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20697–20709 (2024)
2024
-
[39]
arXiv preprint arXiv:2507.13347 (2025)
Wang, Y., Zhou, J., Zhu, H., Chang, W., Zhou, Y., Li, Z., Chen, J., Pang, J., Shen, C., He, T.:π 3: Permutation-equivariant visual geometry learning. arXiv preprint arXiv:2507.13347 (2025)
Pith/arXiv arXiv 2025
-
[40]
In: Proceedings of the 32nd ACM Interna- tional Conference on Multimedia
Wang, Y., Dai, W., Chan, L., Zhou, H., Zhang, A., Liu, S.: Gpd-vvto: Preserving garment details in video virtual try-on. In: Proceedings of the 32nd ACM Interna- tional Conference on Multimedia. pp. 7133–7142 (2024)
2024
-
[41]
In: ACM SIGGRAPH 2024 Conference Papers
Wang, Z., Yuan, Z., Wang, X., Li, Y., Chen, T., Xia, M., Luo, P., Shan, Y.: Mo- tionctrl: A unified and flexible motion controller for video generation. In: ACM SIGGRAPH 2024 Conference Papers. pp. 1–11 (2024)
2024
-
[42]
arXiv preprint arXiv:2508.02324 (2025) 18 Sun et al
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., Yin, S.m., Bai, S., Xu, X., Chen, Y., et al.: Qwen-image technical report. arXiv preprint arXiv:2508.02324 (2025) 18 Sun et al
Pith/arXiv arXiv 2025
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, J.Z., Zhang, Y., Turki, H., Ren, X., Gao, J., Shou, M.Z., Fidler, S., Gojcic, Z., Ling, H.: Difix3d+: Improving 3d reconstructions with single-step diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26024–26035 (2025)
2025
-
[44]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, R., Gao, R., Poole, B., Trevithick, A., Zheng, C., Barron, J.T., Holynski, A.: Cat4d: Create anything in 4d with multi-view video diffusion models. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26057–26068 (2025)
2025
-
[45]
arXiv preprint arXiv:2411.19324 (2024)
Xiao, Z., Ouyang, W., Zhou, Y., Yang, S., Yang, L., Si, J., Pan, X.: Trajectory attention for fine-grained video motion control. arXiv preprint arXiv:2411.19324 (2024)
arXiv 2024
-
[46]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Xie,S.,Girshick,R.,Dollár,P.,Tu,Z.,He,K.:Aggregatedresidualtransformations for deep neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1492–1500 (2017)
2017
-
[47]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Xu, Y., Gu, T., Chen, W., Chen, A.: Ootdiffusion: Outfitting fusion based latent diffusion for controllable virtual try-on. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 8996–9004 (2025)
2025
-
[48]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Xu, Z., Chen, M., Wang, Z., Xing, L., Zhai, Z., Sang, N., Lan, J., Xiao, S., Gao, C.: Tunnel try-on: Excavating spatial-temporal tunnels for high-quality virtual try-on in videos. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 3199–3208 (2024)
2024
-
[49]
In: Proceedings of the IEEE/CVF international conference on computer vision
Yu, M., Hu, W., Xing, J., Shan, Y.: Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 100–111 (2025)
2025
-
[50]
arXiv preprint arXiv:2409.02048 (2024)
Yu, W., Xing, J., Yuan, L., Hu, W., Li, X., Huang, Z., Gao, X., Wong, T.T., Shan, Y., Tian, Y.: Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis. arXiv preprint arXiv:2409.02048 (2024)
Pith/arXiv arXiv 2024
-
[51]
arXiv preprint arXiv:2410.03825 (2024)
Zhang, J., Herrmann, C., Hur, J., Jampani, V., Darrell, T., Cole, F., Sun, D., Yang, M.H.: Monst3r: A simple approach for estimating geometry in the presence of motion. arXiv preprint arXiv:2410.03825 (2024)
Pith/arXiv arXiv 2024
-
[52]
arXiv preprint arXiv:2503.07027 (2025)
Zhang, Y., Yuan, Y., Song, Y., Wang, H., Liu, J.: Easycontrol: Adding efficient and flexible control for diffusion transformer. arXiv preprint arXiv:2503.07027 (2025)
arXiv 2025
-
[53]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, Y., Zhang, Q., Song, Y., Zhang, J., Tang, H., Liu, J.: Stable-hair: Real- world hair transfer via diffusion model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 10348–10356 (2025)
2025
-
[54]
Zuo, T., Huang, Z., Ning, S., Lin, E., Liang, C., Zheng, Z., Jiang, J., Zhang, Y., Gao, M., Dong, X.: Dreamvvt: Mastering realistic video virtual try-on in the wild via a stage-wise diffusion transformer framework. arXiv preprint arXiv:2508.02807 (2025) TryOnCrafter 19 Supplementary Materials S1 Overview In the supplementary materials, we provide addition...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.