Knowledge-augmented Agentic AI for Mental Health Medication Information Seeking
Pith reviewed 2026-06-26 01:44 UTC · model grok-4.3
The pith
A provenance-aware knowledge graph integrates FDA adverse-event records with patient reports on antidepressants while preserving source distinctions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
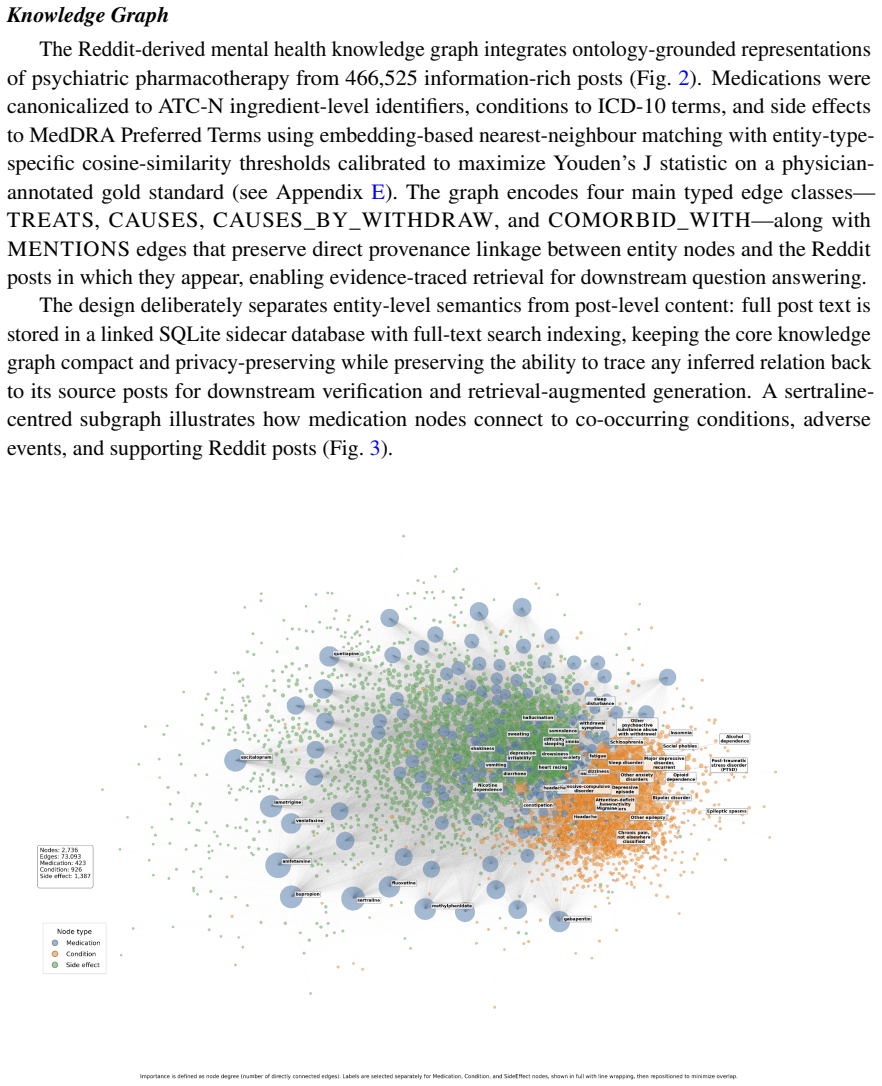
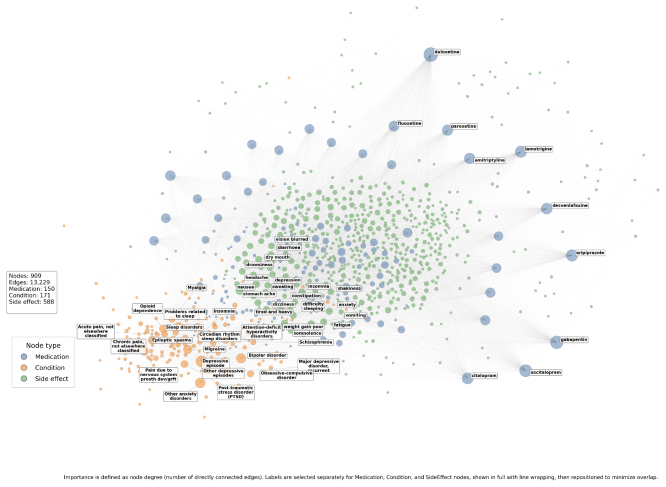
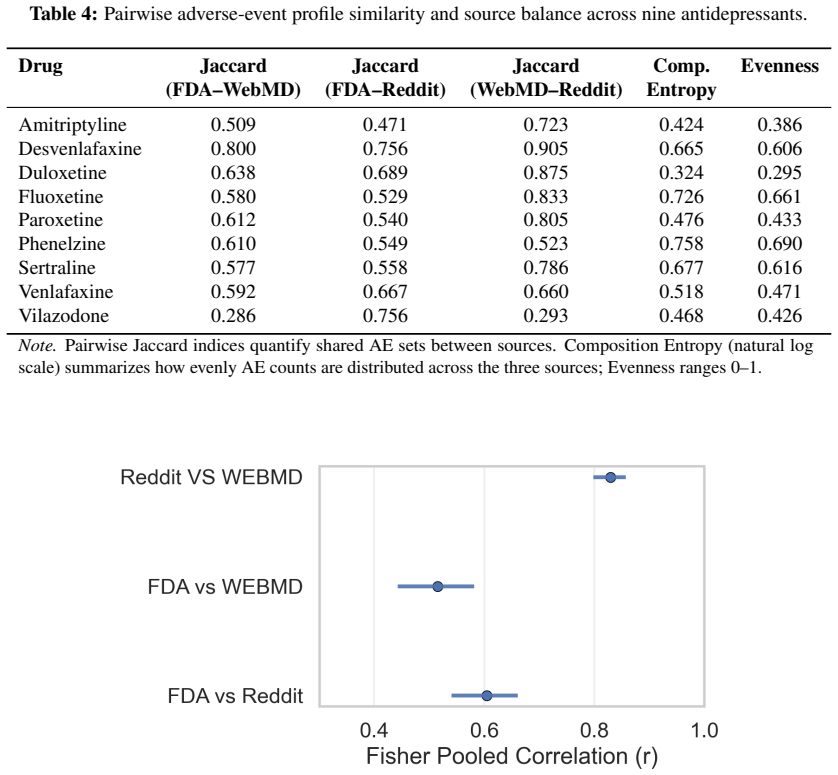
The central discovery is that a Neo4j knowledge graph grounded in standard vocabularies, combined with a multi-agent framework, unifies large volumes of regulatory and community data on nine antidepressants while maintaining full provenance, revealing that patient-generated sources form a partly independent safety signal as evidenced by their mutual concordance and earlier event detection compared to FDA records.
What carries the argument
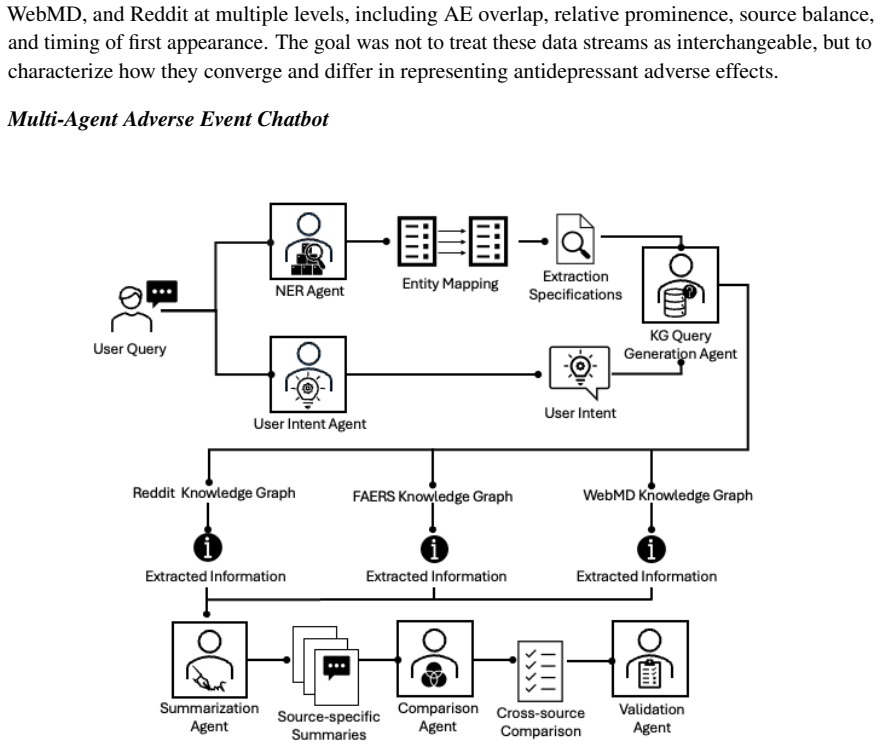
The provenance-aware, knowledge-graph-based multi-agent framework that preserves distinctions between regulatory facts and patient experiences using ATC-N, ICD-10, and MedDRA vocabularies.
If this is right
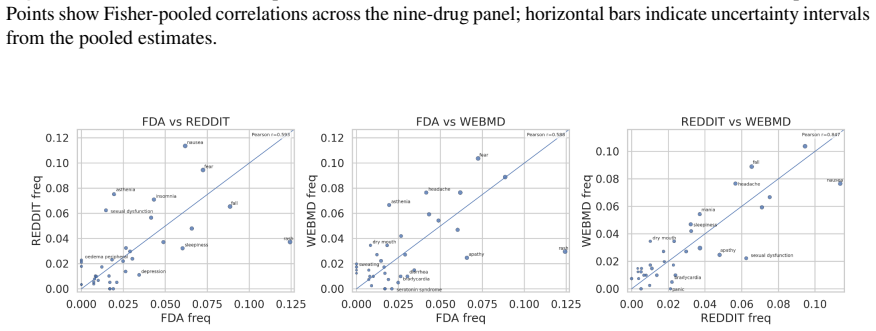
- The two community platforms show Jaccard similarity up to 0.905, far higher than with regulatory reports.
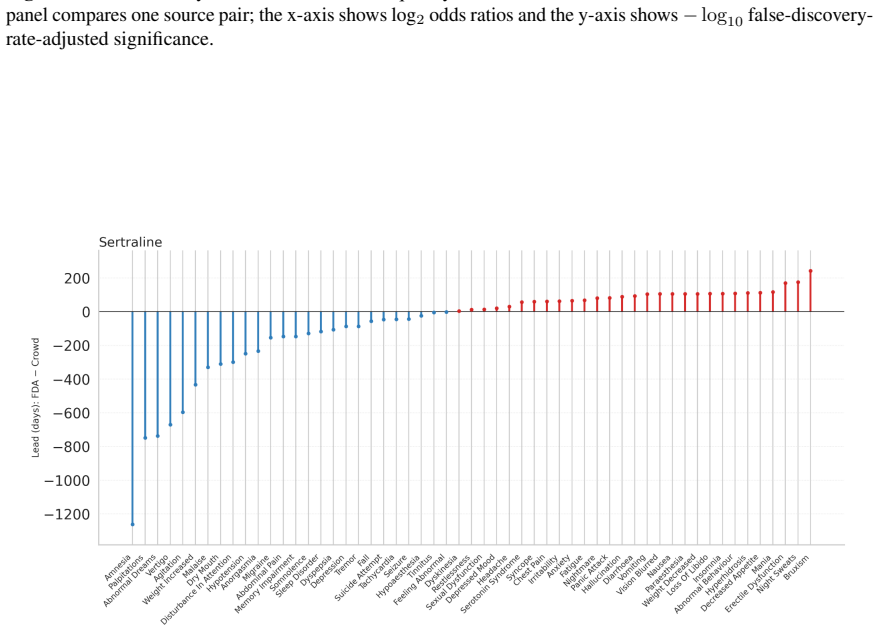
- Adverse events for sertraline appeared in community sources hundreds of days before FDA dates.
- LLM pipeline reaches F1 scores of 0.969 for medications and 0.973 for conditions.
- Over 466,525 Reddit posts and 60,782 WebMD reviews are integrated with 20 years of FDA data for nine antidepressants.
Where Pith is reading between the lines
- This method could support real-time monitoring by highlighting signals that appear first in patient data.
- Extending the framework to other medications might reveal similar patterns of independent signals.
- Traceable information systems may help reduce misinterpretation of anecdotal reports in mental health contexts.
Load-bearing premise
High concordance between community platforms indicates a partly independent safety signal rather than shared biases or artifacts in reporting.
What would settle it
Demonstrating that the observed concordance between Reddit and WebMD data results from common reporting biases, or that integrating the sources does not lead to measurable improvements in patient understanding or outcomes in a controlled study.
Figures
read the original abstract
Patients increasingly seek medication information online, yet safety knowledge for psychiatric drugs is split between regulatory adverse-event records, which are authoritative but abstract, and patient narratives, which are experience-near but unvalidated. Integrating them without conflating evidence and anecdote is especially consequential in psychiatry, where poorly contextualised information can amplify fear, nocebo responses, and non-adherence. Here we develop a provenance-aware, knowledge-graph-based multi-agent framework unifying 466,525 Reddit posts, 60,782 WebMD reviews, and twenty years of U.S. FDA Adverse Event Reporting System records for nine antidepressants. A large-language-model entity-recognition pipeline benchmarked against physician annotations reached highest F1 scores of 0.969 for medications and 0.973 for conditions. The two community platforms were far more concordant with each other (overlap up to a Jaccard similarity of 0.905) than with regulatory reports, indicating that patient-generated data form a partly independent safety signal. For sertraline, many adverse events appeared in community sources hundreds of days before the corresponding FDA date. A Neo4j knowledge graph grounded in ATC-N, ICD-10, and MedDRA vocabularies preserves provenance, keeping every claim traceable and regulatory facts distinct from patient experience. These results establish source-aware integration as a route to more auditable psychiatric medication information, with usefulness and patient benefit to be tested prospectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
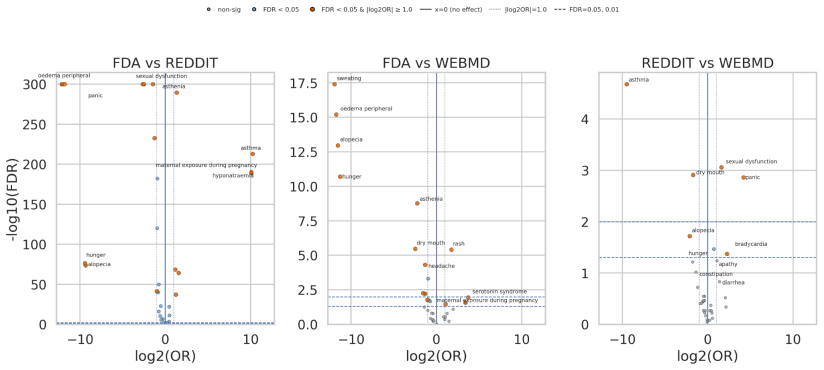
Summary. The manuscript presents a provenance-aware multi-agent framework that integrates 466,525 Reddit posts, 60,782 WebMD reviews, and twenty years of FDA FAERS records for nine antidepressants. An LLM entity-recognition pipeline is benchmarked against physician annotations, a Neo4j knowledge graph is constructed using ATC-N, ICD-10, and MedDRA vocabularies to preserve source provenance, and the analysis reports high concordance between the two community platforms (Jaccard up to 0.905) together with earlier appearance of some adverse events in community data relative to FDA reports, positioning the work as establishing source-aware integration for more auditable psychiatric medication information.
Significance. If the entity-recognition reliability and the claim of an independent safety signal can be substantiated with additional validation, the provenance-preserving knowledge-graph approach could provide a concrete technical route for combining regulatory and patient-generated data while keeping their distinct evidentiary status explicit. The grounding in standard medical vocabularies and the scale of the integrated corpus are constructive elements for future auditable health-information systems.
major comments (3)
- [Abstract] Abstract: The highest F1 scores of 0.969 (medications) and 0.973 (conditions) are stated without any description of the physician-annotation benchmark, inter-annotator agreement, dataset characteristics, or error analysis; because entity recognition underpins the concordance and temporal comparisons, this omission is load-bearing for the central claims.
- [Abstract] Abstract: The conclusion that community platforms supply a 'partly independent safety signal' rests on the Jaccard similarity of 0.905 between Reddit and WebMD plus earlier sertraline dates, yet no supporting analysis is supplied (e.g., overlap with known label side-effects, quantification of unique versus shared events, or controls for shared reporting biases), leaving the independence interpretation untested.
- [Abstract] Abstract: The temporal claim that 'many adverse events appeared in community sources hundreds of days before the corresponding FDA date' for sertraline is presented without the alignment procedure, handling of multiple reports per event, or any statistical test, so the reported lead time cannot be evaluated for robustness.
minor comments (1)
- [Abstract] The abstract would be clearer if it briefly indicated how many of the nine antidepressants are covered by the sertraline temporal example and whether the Jaccard figure is an aggregate or per-drug maximum.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight the need for the abstract to be more self-contained regarding key methodological details and analytical support. We will revise the abstract to incorporate brief descriptions addressing these points while maintaining its conciseness. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: The highest F1 scores of 0.969 (medications) and 0.973 (conditions) are stated without any description of the physician-annotation benchmark, inter-annotator agreement, dataset characteristics, or error analysis; because entity recognition underpins the concordance and temporal comparisons, this omission is load-bearing for the central claims.
Authors: We agree that additional context in the abstract would improve clarity. The full manuscript provides a detailed description of the physician-annotation benchmark, including inter-annotator agreement, dataset characteristics, and error analysis in the Methods section. We will revise the abstract to include a concise reference to the benchmark methodology and its validation. revision: yes
-
Referee: [Abstract] Abstract: The conclusion that community platforms supply a 'partly independent safety signal' rests on the Jaccard similarity of 0.905 between Reddit and WebMD plus earlier sertraline dates, yet no supporting analysis is supplied (e.g., overlap with known label side-effects, quantification of unique versus shared events, or controls for shared reporting biases), leaving the independence interpretation untested.
Authors: The manuscript contains supporting analyses for the independence claim, including comparisons to known label side-effects and quantification of unique events. However, the abstract does not summarize these. We will revise the abstract to briefly outline the supporting evidence for the 'partly independent safety signal' interpretation. revision: yes
-
Referee: [Abstract] Abstract: The temporal claim that 'many adverse events appeared in community sources hundreds of days before the corresponding FDA date' for sertraline is presented without the alignment procedure, handling of multiple reports per event, or any statistical test, so the reported lead time cannot be evaluated for robustness.
Authors: Details on the alignment procedure, handling of multiple reports, and statistical tests are provided in the full manuscript's temporal analysis. To enhance the abstract, we will add a short description of the temporal comparison methodology. revision: yes
Circularity Check
No significant circularity; derivation is observational data integration
full rationale
The paper describes an LLM-based entity recognition pipeline benchmarked on physician annotations, computes direct overlap metrics (Jaccard similarity) between community sources, and reports observed temporal precedence of events in patient data versus FDA records. No equations, fitted parameters, predictions derived from subsets, or self-citations are invoked as load-bearing steps in the provided text. All reported quantities are computed outputs from external datasets rather than reductions to inputs by construction, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Physician annotations serve as reliable ground truth for benchmarking LLM entity recognition.
- domain assumption Jaccard similarity and temporal precedence between sources indicate independent safety signals.
Reference graph
Works this paper leans on
-
[1]
One in two EU citizens look for health information online.Eurostat News, 2021
Eurostat. One in two EU citizens look for health information online.Eurostat News, 2021. https://ec.europa.eu/eurostat/web/products-eurostat-news/-/ edn-20210406-1
2021
-
[2]
Finney Rutten, L. J. et al. Online health information seeking among US adults: Measuring progress toward a Healthy People 2020 objective.Public Health Rep.134, 617–625 (2019)
2020
-
[3]
Wong, D. K.-K. & Cheung, M.-K. Online health information seeking and eHealth literacy among patients attending a primary care clinic in Hong Kong.J. Med. Internet Res.21, e10831 (2019)
2019
-
[4]
Wang, X. & Cohen, R. A. Health Information Technology Use among Adults: United States, July–December 2022. CDC (2023).https://doi.org/10.15620/cdc:133700
-
[5]
Lim, H. M. et al. Association between online health information-seeking and medication adherence.Digit. Health8, 20552076221097784 (2022)
2022
-
[6]
Sieling, C. et al. What do patients know about their newly prescribed medication?Patient Educ. Couns.133, 108645 (2025). 15
2025
-
[7]
Lobban, F. et al. Impacts of using peer online forums in mental health.J. Med. Internet Res.27, e79289 (2025)
2025
-
[8]
& Petrie, K
Faasse, K. & Petrie, K. J. The nocebo effect: patient expectations and medication side effects. Postgrad. Med. J.89, 540–546 (2013)
2013
-
[9]
Nestoriuc, Y . et al. Informing about the nocebo effect affects patients’ need for information about antidepressants.Front. Psychiatry12, 587122 (2021)
2021
-
[10]
FDA Adverse Event Reporting System (FAERS) Database
Center for Drug Evaluation & Research. FDA Adverse Event Reporting System (FAERS) Database. U.S. Food and Drug Administration (2024)
2024
-
[11]
Golder, S. et al. The value of social media analysis for adverse events detection and pharma- covigilance: Scoping review.JMIR Public Health Surveill.10, e59167 (2024)
2024
-
[12]
Busch, F. et al. Current applications and challenges in large language models for patient care. Commun. Med. (Lond.)5, 26 (2025)
2025
-
[13]
Huo, B. et al. Large language models for chatbot health advice studies: A systematic review. JAMA Netw. Open8, e2457879 (2025)
2025
-
[14]
Yu, H. et al. Large language models in biomedical and health informatics: A review with bibliometric analysis.J. Healthc. Inform. Res.8, 658–711 (2024)
2024
-
[15]
Hager, P. et al. Evaluation and mitigation of the limitations of large language models in clinical decision-making.Nat. Med.30, 2613–2622 (2024)
2024
-
[16]
Niu, J. et al. AIPatient Arena: EHR-grounded evaluation of large language models in end-to-end clinical consultation workflows.arXiv preprint arXiv:2606.17474(2026)
Pith/arXiv arXiv 2026
-
[17]
Asgari, E. et al. A framework to assess clinical safety and hallucination rates of LLMs for medical text summarisation.NPJ Digit. Med.8, 274 (2025)
2025
-
[18]
Lin, X. et al. Evaluating an evidence-guided reinforcement learning framework in aligning light-parameter large language models with decision-making cognition in psychiatric clinical reasoning.arXiv preprint arXiv:2602.06449(2026)
arXiv 2026
-
[19]
Stade, E. C. et al. Large language models could change the future of behavioral healthcare.Npj Ment. Health Res.3, 12 (2024)
2024
-
[20]
& Etminani, K
Rajabi, E. & Etminani, K. Knowledge-graph-based explainable AI: A systematic review.J. Inf. Sci.50, 1019–1029 (2024)
2024
-
[21]
Miao, Y . et al. Improving large language model applications in medical and nursing domains with retrieval-augmented generation.J. Med. Internet Res.27, e80557 (2025)
2025
-
[22]
Zhu, L. et al. Artificial Intelligence Agents in Mental Health: A Systematic Review and Meta Analysis.medRxiv2026.04.21.26351365 (2026)
2026
-
[23]
Li, X. et al. DispatchMAS: Fusing taxonomy and artificial intelligence agents for emergency medical services.BMC Emerg. Med.26, 78 (2026)
2026
-
[24]
intended for nervous system related illnesses
Yu, H. et al. Simulated patient systems powered by large language model-based AI agents offer potential for transforming medical education.Commun. Med.6, 27 (2026). 16 Appendices Table of Contents ALLM Prompt for Expanding Generic Names to Brand Synonymy . . . . . . . . . . . . . . . . . . . . . . . . 18 Table S1 LLM prompt for expanding generic drug name...
2026
-
[25]
The post is about a Nervous System drug (e.g., antidepressants, antipsychotics, mood stabilizers, anxiolytics)
-
[26]
Aside effectis a common or expected reaction (e.g., fatigue, weight gain); anadverse eventis a severe or unexpected reaction (e.g., seizures, suicidal thoughts)
The post mentions a side effect or adverse event related to the drug. Aside effectis a common or expected reaction (e.g., fatigue, weight gain); anadverse eventis a severe or unexpected reaction (e.g., seizures, suicidal thoughts)
-
[27]
all missing fieldsMUSTbe null
The post isinformation-rich, meaning it includes at least one of the following: specific symptom(s) or effect(s); details about timing, duration, dosage, or sequence of events; or how the reaction impacted daily life or required medical attention. Approximately 23.3% of posts were labeled as information-rich. Using these labeled data, we then fine-tuned a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.