MKG-RAG-Bench: Benchmarking Retrieval in Multimodal Knowledge Graph-Augmented Generation
Pith reviewed 2026-06-26 01:09 UTC · model grok-4.3
The pith
Retrieval quality from multimodal knowledge graphs strongly determines the accuracy of answers generated by large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experiments on MKG-RAG-Bench establish that effective multimodal retrieval remains challenging yet crucial for end-to-end MKG-RAG performance, and that retrieval quality strongly determines generation outcomes.
What carries the argument
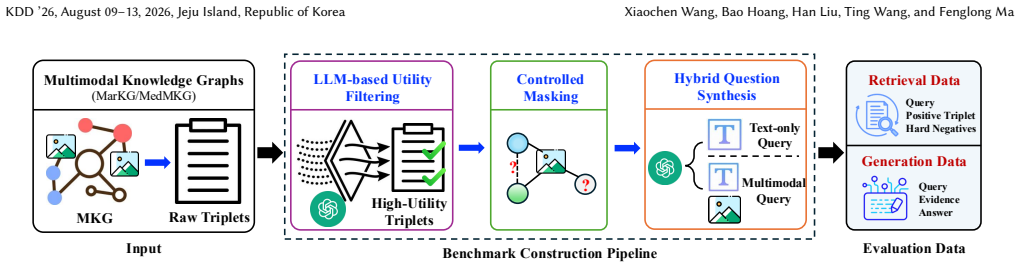
MKG-RAG-Bench, a cross-domain benchmark built from multimodal knowledge graphs that supplies aligned QA datasets and supports isolated measurement of retrieval quality before generation.
If this is right
- Higher-performing multimodal retrievers will raise the accuracy of answers produced by MKG-RAG systems.
- Retrievers tuned only on unstructured text will continue to underperform when knowledge is distributed across modalities inside a graph.
- Generation quality tracks retrieval quality across both general and medical domains.
- Developers can now diagnose whether failures originate in retrieval or in the generator by using the benchmark's controlled splits.
Where Pith is reading between the lines
- Medical MKG-RAG applications may require extra safeguards on image-text alignment that the current benchmark only begins to expose.
- The same retrieval-first evaluation approach could be applied to other structured knowledge sources beyond the two graphs tested here.
- System builders should allocate more engineering effort to retrieval modules when sources mix text, images, and relations.
Load-bearing premise
The LLM-based curation pipeline reliably filters low-utility knowledge and generates structurally grounded queries with exact supervision without introducing systematic biases or alignment errors across modalities.
What would settle it
Running the benchmark's test sets through several retrievers and finding no consistent correlation between standard retrieval metrics and downstream answer accuracy would falsify the central claim.
Figures


read the original abstract
Retrieval-augmented generation (RAG) over knowledge graphs has emerged as a promising approach for grounding large language models, yet existing benchmarks largely overlook the challenges of retrieval in multimodal knowledge graph RAG (MKG-RAG). In practice, retrieval is a critical bottleneck: multimodal knowledge is heterogeneous, difficult to align across modalities, and often poorly served by retrievers designed for unstructured corpora. To address this gap, we introduce MKG-RAG-Bench, a cross-domain benchmark explicitly designed to evaluate retrieval in MKG-RAG. MKG-RAG-Bench is constructed from two multimodal knowledge graphs spanning general and medical domains, and includes carefully aligned question-answering datasets that support controlled evaluation of both retrieval and downstream generation. The benchmark is built using an LLM-based curation pipeline that filters low-utility knowledge, generates structurally grounded queries with exact supervision, and systematically covers diverse modality configurations. Through extensive experiments across representative retriever families and modality settings, we show that effective multimodal retrieval remains challenging yet crucial for end-to-end MKG-RAG performance, and that retrieval quality strongly determines generation outcomes. By isolating retrieval as a first-class evaluation target, MKG-RAG-Bench provides a principled foundation for diagnosing current limitations and advancing multimodal knowledge graph RAG systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MKG-RAG-Bench, a cross-domain benchmark for evaluating retrieval in multimodal knowledge graph-augmented generation (MKG-RAG). It is constructed from two multimodal knowledge graphs (general and medical domains) via an LLM-based curation pipeline that filters low-utility triples and generates structurally grounded queries with exact supervision. The benchmark includes aligned QA datasets supporting controlled retrieval and generation evaluation. Experiments across retriever families and modality settings are used to claim that effective multimodal retrieval remains challenging yet crucial for end-to-end MKG-RAG performance and that retrieval quality strongly determines generation outcomes.
Significance. If the curation pipeline proves reliable, the benchmark would address a clear gap by isolating retrieval as a first-class target in MKG-RAG, where modality heterogeneity and alignment pose documented difficulties. The empirical scope across representative retrievers and domains provides a concrete starting point for diagnosing limitations, which is valuable for a benchmark paper.
major comments (2)
- [Abstract / Benchmark Construction] Abstract / Benchmark Construction: The central claim that retrieval quality strongly determines generation outcomes depends on MKG-RAG-Bench being a faithful testbed. The LLM-based curation pipeline is described as filtering low-utility knowledge and generating structurally grounded queries, yet the manuscript provides no quantitative human validation, inter-annotator agreement, or error analysis of modality alignment or query grounding. This is load-bearing for interpreting all reported performance gaps and correlations.
- [Experiments] Experiments section: The abstract asserts that experiments demonstrate retrieval quality strongly determines outcomes, but without reported quantitative metrics, ablation on the curation pipeline, or analysis of potential LLM-induced biases in the testbed, it is not possible to verify whether the observed gaps reflect intrinsic retrieval hardness or artifacts of the construction process.
minor comments (1)
- [Abstract] Abstract: Consider adding one or two key quantitative results (e.g., retrieval metrics or correlation coefficients) to give readers an immediate sense of effect sizes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which underscores the need for rigorous validation in benchmark construction. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Benchmark Construction] The central claim that retrieval quality strongly determines generation outcomes depends on MKG-RAG-Bench being a faithful testbed. The LLM-based curation pipeline is described as filtering low-utility knowledge and generating structurally grounded queries, yet the manuscript provides no quantitative human validation, inter-annotator agreement, or error analysis of modality alignment or query grounding. This is load-bearing for interpreting all reported performance gaps and correlations.
Authors: We agree that the absence of quantitative human validation limits the strength of claims about the benchmark's fidelity. In the revision we will add a human evaluation on a sampled subset of curated triples and queries, reporting inter-annotator agreement and a detailed error analysis of modality alignment and query grounding. These results will be presented alongside the existing pipeline description. revision: yes
-
Referee: [Experiments] The abstract asserts that experiments demonstrate retrieval quality strongly determines outcomes, but without reported quantitative metrics, ablation on the curation pipeline, or analysis of potential LLM-induced biases in the testbed, it is not possible to verify whether the observed gaps reflect intrinsic retrieval hardness or artifacts of the construction process.
Authors: We concur that additional quantitative support is required to substantiate the reported correlations. The revised manuscript will include ablations isolating components of the curation pipeline together with an analysis of LLM-induced biases, accompanied by the corresponding quantitative metrics. These additions will help distinguish intrinsic retrieval challenges from construction artifacts. revision: yes
Circularity Check
No circularity; benchmark construction and empirical evaluation are self-contained
full rationale
The paper constructs MKG-RAG-Bench from existing multimodal KGs using an LLM curation pipeline, then runs controlled experiments on retriever families. No equations, fitted parameters, or predictions are present. Central claims rest on direct empirical measurements of retrieval and generation performance rather than any self-referential derivation or self-citation chain. The LLM pipeline is an input construction step, not a load-bearing derivation that reduces to its own outputs by definition. This matches the default case of a non-circular empirical benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based curation produces reliable, unbiased queries with exact supervision from the knowledge graph
Reference graph
Works this paper leans on
-
[1]
Olivier Bodenreider. 2004. The Unified Medical Language System (UMLS): inte- grating biomedical terminology.Nucleic Acids Res.32, Database issue (Jan. 2004), D267–70
2004
-
[2]
Jiangjie Chen, Rui Xu, Ziquan Fu, Wei Shi, Zhongqiao Li, Xinbo Zhang, Changzhi Sun, Lei Li, Yanghua Xiao, and Hao Zhou. 2022. E-KAR: A benchmark for ratio- nalizing natural language analogical reasoning.arXiv preprint arXiv:2203.08480 (2022)
arXiv 2022
-
[3]
Wenhu Chen, Hexiang Hu, Xi Chen, Pat Verga, and William Cohen. 2022. Murag: Multimodal retrieval-augmented generator for open question answering over images and text. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 5558–5570
2022
-
[4]
Zhanpeng Chen, Chengjin Xu, Yiyan Qi, Xuhui Jiang, and Jian Guo. 2025. VLM Is a Strong Reranker: Advancing Multimodal Retrieval-augmented Generation via Knowledge-enhanced Reranking and Noise-injected Training. InFindings of the Association for Computational Linguistics: EMNLP 2025. 8140–8158
2025
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multi- modality, Long Context, and Next Generation Agentic Capabilities.arXiv preprint arXiv:2507.06261(2025)
Pith/arXiv arXiv 2025
-
[6]
Kuicai Dong, Yujing Chang, Shijie Huang, Yasheng Wang, Ruiming Tang, and Yong Liu. 2025. Benchmarking Retrieval-Augmented Multimodal Generation for Document Question Answering.arXiv preprint arXiv:2505.16470(2025)
arXiv 2025
-
[7]
Aleksandr Drozd, Anna Gladkova, and Satoshi Matsuoka. 2016. Word embed- dings, analogies, and machine learning: Beyond king-man+ woman= queen. In Proceedings of coling 2016. 3519–3530
2016
-
[8]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
Pith/arXiv arXiv 2024
-
[9]
Feng Gao, Qing Ping, Govind Thattai, Aishwarya Reganti, Ying Nian Wu, and Prem Natarajan. 2022. Transform-Retrieve-Generate: Natural Language-Centric KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Xiaochen Wang, Bao Hoang, Han Liu, Ting Wang, and Fenglong Ma Outside-Knowledge Visual Question Answering. InCVPR 2022. IEEE, 5057–5067
2022
-
[10]
Yu Gu, Sue Kase, Michelle Vanni, Brian Sadler, Percy Liang, Xifeng Yan, and Yu Su. 2021. Beyond iid: three levels of generalization for question answering on knowledge bases. InProceedings of the web conference 2021. 3477–3488
2021
-
[11]
Xiaoxin He, Yijun Tian, Yifei Sun, Nitesh Chawla, Thomas Laurent, Yann LeCun, Xavier Bresson, and Bryan Hooi. 2024. G-retriever: Retrieval-augmented gen- eration for textual graph understanding and question answering.Advances in Neural Information Processing Systems37 (2024), 132876–132907
2024
-
[12]
Yuntong Hu, Zhihan Lei, Zheng Zhang, Bo Pan, Chen Ling, and Liang Zhao
-
[13]
arXiv:2405.16506 [cs.LG] https://arxiv.org/abs/2405.16506
GRAG: Graph Retrieval-Augmented Generation. arXiv:2405.16506 [cs.LG] https://arxiv.org/abs/2405.16506
-
[14]
Alistair E W Johnson, Tom J Pollard, Seth J Berkowitz, Nathaniel R Greenbaum, Matthew P Lungren, Chih-Ying Deng, Roger G Mark, and Steven Horng. 2019. MIMIC-CXR, a de-identified publicly available database of chest radiographs with free-text reports.Sci. Data6, 1 (Dec. 2019), 317
2019
-
[15]
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. doi:10.48550/ARXIV.2004.04906
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2004.04906 2020
-
[16]
Jason J Lau, Soumya Gayen, Asma Ben Abacha, and Dina Demner-Fushman. 2018. A dataset of clinically generated visual questions and answers about radiology images.Scientific data5, 1 (2018), 1–10
2018
-
[17]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[18]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. 2022. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning. PMLR, 12888–12900
2022
-
[19]
Mufei Li, Siqi Miao, and Pan Li. 2024. Simple is effective: The roles of graphs and large language models in knowledge-graph-based retrieval-augmented genera- tion.arXiv preprint arXiv:2410.20724(2024)
arXiv 2024
-
[20]
Shiyang Li, Yifan Gao, Haoming Jiang, Qingyu Yin, Zheng Li, Xifeng Yan, Chao Zhang, and Bing Yin. 2023. Graph Reasoning for Question Answering with Triplet Retrieval. InACL (Findings)
2023
-
[21]
Yangning Li, Yinghui Li, Xinyu Wang, Yong Jiang, Zhen Zhang, Xinran Zheng, Hui Wang, Hai-Tao Zheng, Fei Huang, Jingren Zhou, et al. [n. d.]. Benchmarking Multimodal Retrieval Augmented Generation with Dynamic VQA Dataset and Self-adaptive Planning Agent. InThe Thirteenth ICLR
-
[22]
Bo Liu, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu. 2021. SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical Visual Ques- tion Answering. arXiv:2102.09542 [cs.CV] https://arxiv.org/abs/2102.09542
arXiv 2021
-
[23]
Ye Liu, Hui Li, Alberto Garcia-Duran, Mathias Niepert, Daniel Onoro-Rubio, and David S Rosenblum. 2019. MMKG: multi-modal knowledge graphs. InEuropean Semantic Web Conference. Springer, 459–474
2019
-
[24]
Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. 2023. Reasoning on graphs: Faithful and interpretable large language model reasoning.arXiv preprint arXiv:2310.01061(2023)
arXiv 2023
-
[25]
Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyuan Lu, Ziyu Liu, Yan Ma, Xiaoyi Dong, et al. 2024. Mmlongbench-doc: Benchmarking long-context document understanding with visualizations.Advances in Neural Information Processing Systems37 (2024), 95963–96010
2024
-
[26]
Zi-Ao Ma, Tian Lan, Rong-Cheng Tu, Yong Hu, Yu-Shi Zhu, Tong Zhang, Heyan Huang, Zhijing Wu, and Xian-Ling Mao. 2024. Multi-modal Retrieval Augmented Multi-modal Generation: Datasets, Evaluation Metrics and Strong Baselines. arXiv preprint arXiv:2411.16365(2024)
arXiv 2024
-
[27]
Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. 2019. Ok-vqa: A visual question answering benchmark requiring external knowledge. InProceedings of CVPR. 3195–3204
2019
-
[28]
Lang Mei, Siyu Mo, Zhihan Yang, and Chong Chen. 2025. A Survey of Multimodal Retrieval-Augmented Generation. doi:10.48550/ARXIV.2504.08748
-
[29]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. InInternational conference on machine learning. PmLR, 8748–8763
2021
-
[30]
Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. doi:10.48550/ARXIV.1908.10084
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1908.10084 2019
-
[31]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Foundations and Trends®in Information Retrieval3, 4 (2009), 333–389. doi:10.1561/1500000019
-
[32]
Naganand Yadati Sanket Shah, Anand Mishra and Partha Pratim Talukdar. 2019. KVQA: Knowledge-Aware Visual Question Answering. InAAAI
2019
-
[33]
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, Patrick Schramowski, Srivatsa Kundurthy, Katherine Crowson, Ludwig Schmidt, Robert Kaczmarczyk, and Jenia Jitsev. 2022. LAION-5B: An open large-scale dataset for training next generation image-text m...
Pith/arXiv arXiv 2022
-
[34]
Dustin Schwenk, Apoorv Khandelwal, Christopher Clark, Kenneth Marino, and Roozbeh Mottaghi. 2022. A-okvqa: A benchmark for visual question answering using world knowledge. InECCV. Springer, 146–162
2022
-
[35]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al
-
[36]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267(2025)
Pith/arXiv arXiv 2025
-
[37]
Alon Talmor and Jonathan Berant. 2018. The web as a knowledge-base for answering complex questions.arXiv preprint arXiv:1803.06643(2018)
Pith/arXiv arXiv 2018
-
[38]
Qwen Team. 2026. Qwen3.5: Accelerating Productivity with Native Multimodal Agents. https://qwen.ai/blog?id=qwen3.5
2026
-
[39]
Jiaqi Wang, Xiao Yang, Kai Sun, Parth Suresh, Sanat Sharma, Adam Czyzewski, Derek Andersen, Surya Appini, Arkav Banerjee, Sajal Choudhary, et al . 2025. CRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark.arXiv preprint arXiv:2510.26160(2025)
arXiv 2025
-
[40]
Xin Wang, Benyuan Meng, Hong Chen, Yuan Meng, Ke Lv, and Wenwu Zhu
-
[41]
TIVA-KG: A Multimodal Knowledge Graph with Text, Image, Video and Audio. InProceedings of MM’23. Association for Computing Machinery, New York, NY, USA, 2391–2399. doi:10.1145/3581783.3612266
-
[42]
Xiaochen Wang, Zongyu Wu, Yuan Zhong, Xiang Zhang, Suhang Wang, and Fen- glong Ma. 2026. GPR: Empowering Generation with Graph-Pretrained Retriever. InProceedings of the ACM Web Conference 2026. 8349–8352
2026
-
[43]
Xiaochen Wang, Yuan Zhong, Lingwei Zhang, Lisong Dai, Ting Wang, and Fenglong Ma. 2025. MEDMKG: Benchmarking Medical Knowledge Exploitation with Multimodal Knowledge Graph. arXiv:2505.17214 [cs.AI] https://arxiv.org/ abs/2505.17214
arXiv 2025
-
[44]
Navve Wasserman, Roi Pony, Oshri Naparstek, Adi Raz Goldfarb, Eliyahu Schwartz, Udi Barzelay, and Leonid Karlinsky. 2025. REAL-MM-RAG: A Real- World Multi-Modal Retrieval Benchmark. InAnnual Meeting of the Association for Computational Linguistics
2025
-
[45]
Yibin Yan and Weidi Xie. 2024. EchoSight: Advancing Visual-Language Models with Wiki Knowledge. InFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics, 1538–1551
2024
-
[46]
Wen-tau Yih, Matthew Richardson, Christopher Meek, Ming-Wei Chang, and Jina Suh. 2016. The value of semantic parse labeling for knowledge base question answering. InProceedings of the 54th ACL (Volume 2: Short Papers). 201–206
2016
-
[47]
Wenjia Zhai. 2024. Self-adaptive Multimodal Retrieval-Augmented Generation. doi:10.48550/ARXIV.2410.11321
-
[48]
Ningyu Zhang, Lei Li, Xiang Chen, Xiaozhuan Liang, Shumin Deng, and Hua- jun Chen. 2023. Multimodal Analogical Reasoning over Knowledge Graphs. arXiv:2210.00312 [cs.CL] https://arxiv.org/abs/2210.00312
arXiv 2023
-
[49]
Anni Zou, Wenhao Yu, Hongming Zhang, Kaixin Ma, Deng Cai, Zhuosheng Zhang, Hai Zhao, and Dong Yu. 2025. Docbench: A benchmark for evaluating llm-based document reading systems. InProceedings of the 4th International Workshop on Knowledge-Augmented Methods for Natural Language Processing. 359–373. A Source Knowledge Graphs We use the following two knowledg...
2025
-
[50]
keep": bool,
Output MUST be JSON:{"keep": bool, "reason": str}
-
[51]
Return ONLY JSON (no extra keys)
-
[52]
Decide keep based primarily on relation_text and tail examples
-
[53]
Because head_text may be uninformative for images, DO NOT reject just because head_text is generic
-
[54]
Set keep=false only when the tails are mostly placeholders or administrative/meta concepts, e.g., tails like ‘thing/object/entity/space/place/environment/location/category’, or when the relation is too vague. Input: GROUP TYPE: {mask_tail or mask_relation} head_text: {head_text} relation_text: {relation_text} tail_text (if mask_relation): {tail_text} cand...
-
[55]
questions
Output MUST be JSON:{"questions": [..]}
-
[56]
Do NOT copy relation_text (or candidate relation strings) verbatim; paraphrase
-
[57]
6)≤25 words per question
If mask_tail: Questions MUST NOT mention any specific tail candidates. 6)≤25 words per question. Avoid yes/no
-
[58]
Refer to the head as ‘{head_ref}’ (or equivalent if multimodal)
-
[59]
Of which global or intergovernmental bodies is Antigua and Barbuda a member?
If mask_relation: You MAY mention tail_text. Input: GROUP TYPE: {mask_tail or mask_relation} head_text: {head_text} relation_text: {relation_text} tail_text (if mask_relation): {tail_text} candidates_count: {cand_total} examples (random 3): {cand_examples} candidates_sample: {cand_sample} K={k} Figure 3: Two-agent prompting for query construction: filteri...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.