Forget, Anticipate and Adapt: Test Time Training for Long Videos
Pith reviewed 2026-06-30 10:19 UTC · model grok-4.3
The pith
A Frame Forgetting Network performs test-time training on hours-long videos by updating on only three frames and adapting the window via a surprise metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
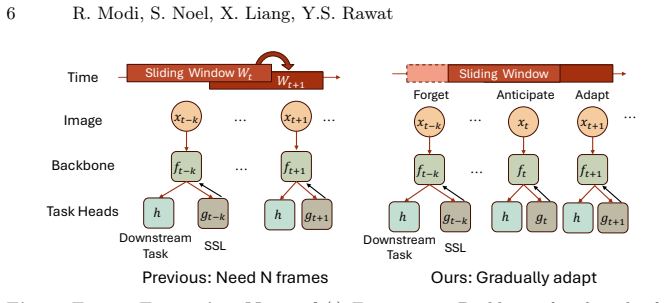
The Frame Forgetting Network retains temporal context for long videos by operating solely on the exiting frame, current frame, and next frame within the sliding window, while a mathematically defined surprise metric enables adaptive modification of the effective window size during self-supervised updates.
What carries the argument
The Frame Forgetting Network, which processes only the exiting, current, and next frames while using a surprise metric to adapt the effective window size.
If this is right
- Test-time updates become tractable for videos lasting hours instead of minutes.
- Compute is saved by skipping or shrinking updates when incoming frames carry little new information.
- The same three-frame mechanism supports dense segmentation, video classification, and depth estimation on long sequences.
- A new dataset of multi-hour walking tours becomes usable for evaluating long-video adaptation.
Where Pith is reading between the lines
- The adaptive window could be applied to live video streams where total length is unknown in advance.
- Energy use on mobile or embedded devices might decrease when the surprise metric frequently reduces the update rate.
- Similar forgetting-plus-surprise logic could transfer to other ordered data such as audio or time-series sensor readings.
Load-bearing premise
Three frames (exiting, current, next) contain enough temporal context to support effective self-supervised weight updates across multi-hour videos.
What would settle it
A drop in downstream task accuracy when the same method is run on videos whose critical temporal dependencies span more than three consecutive frames.
Figures

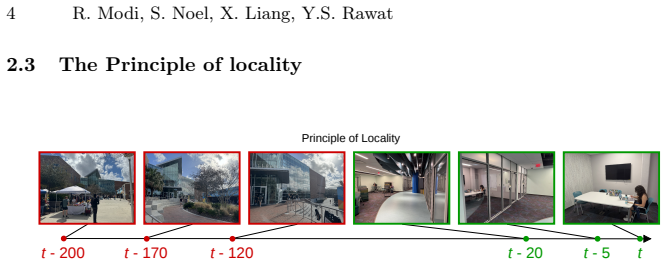

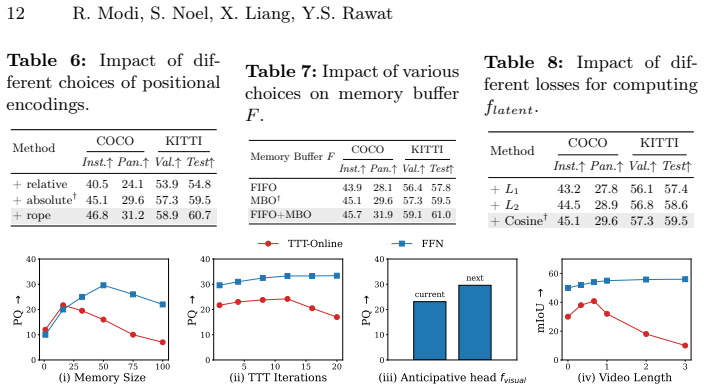






read the original abstract
Test Time Training (TTT) is a mechanism in which a model adapts to an incoming test-sample by performing some self-supervised (SSL) task and updating its weights even during inference. This procedure does not require labels at test-time. This paper focuses on TTT for long-videos. A major concern with existing approaches is: 1) they perform TTT updates using a sliding window containing frames in the past, whose compute increases linearly with the size of window. This becomes computationally intractable when the videos are hours long. 2) TTT is performed even when temporally close frames look similar, thereby consuming a lot of compute. We present the Frame Forgetting Network (FFN) that: 1) operates on only three frames within the sliding window, namely the frame that exits, the current frame and the frame after that. The model still manages to retain temporal context and work for hours long-videos; 2) mathematically define a surprise metric: how much new information the incoming frame contains with respect to the past seen frame. This facilitates determining how to modify the effective window size during TTT and constitutes the core mechanism of an adaptive windowing algorithm. Additionally, we curate a dataset EpicTours containing up to 3 hour long videos of walking city-tours, whereas earlier datasets on this problem were only 5 min long. We demonstrate FFNs empirical effectiveness on dense-segmentation, video classification tasks, generalization to depth-estimation, and multi-hour long videos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Frame Forgetting Network (FFN) for test-time training (TTT) on long videos. FFN operates on only three frames in the sliding window (exiting frame, current frame, next frame) while claiming to retain temporal context for hours-long videos. It introduces a mathematically defined surprise metric to adapt the effective window size and avoid unnecessary TTT updates on similar frames. The work also curates the EpicTours dataset containing videos up to 3 hours long and reports empirical results on dense segmentation, video classification, generalization to depth estimation, and multi-hour videos.
Significance. If the central claims hold with proper validation, this could meaningfully advance scalable TTT for long-form video by replacing linear-in-window compute with a constant three-frame mechanism plus adaptive control. The curation of EpicTours is a concrete positive contribution, as prior datasets were limited to ~5 minutes. No machine-checked proofs or parameter-free derivations are present, but the adaptive-window idea is a clear attempt to address a practical bottleneck.
major comments (3)
- [Abstract] Abstract: the central claim that three frames (exiting/current/next) suffice to retain adequate temporal context for multi-hour videos is load-bearing for the entire contribution, yet the abstract supplies no derivation, mechanism, or ablation to support it; the reader's weakest assumption correctly identifies this empirical gap.
- [Abstract] Abstract: the surprise metric is described as 'mathematically defined' and core to the adaptive windowing algorithm, but no equation or definition is provided, making it impossible to verify whether the metric is free of hidden parameters, circular, or actually controls window size as claimed.
- [Abstract] Abstract: the new EpicTours dataset is invoked to demonstrate multi-hour capability, but its statistics, length distribution, and annotation details are not reported, undermining the claim that the method scales to 3-hour videos.
minor comments (1)
- [Abstract] The abstract would benefit from a single sentence clarifying how the three-frame restriction still propagates temporal information across hours without explicit recurrence or memory state.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback focused on the abstract. We agree that the abstract can be strengthened to better convey the core mechanisms and contributions without expanding its length excessively. We address each comment below and will revise the abstract in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that three frames (exiting/current/next) suffice to retain adequate temporal context for multi-hour videos is load-bearing for the entire contribution, yet the abstract supplies no derivation, mechanism, or ablation to support it; the reader's weakest assumption correctly identifies this empirical gap.
Authors: The abstract is necessarily concise, but we agree it should briefly indicate the mechanism. The full manuscript (Section 3) explains that the exiting frame is forgotten while the next frame is anticipated, allowing the model to maintain effective temporal context via the adaptive updates rather than explicit long-term storage. This is validated empirically across multi-hour videos in the experiments. We will revise the abstract to include a short clause summarizing this three-frame retention approach. revision: yes
-
Referee: [Abstract] Abstract: the surprise metric is described as 'mathematically defined' and core to the adaptive windowing algorithm, but no equation or definition is provided, making it impossible to verify whether the metric is free of hidden parameters, circular, or actually controls window size as claimed.
Authors: We acknowledge the abstract lacks the explicit definition. The manuscript (Section 3.2) provides the mathematical formulation of the surprise metric as the KL divergence between the model's predictive distribution on the incoming frame and the distribution conditioned on the prior frame, with no additional tunable parameters. This directly modulates the effective window size in the adaptive algorithm. We will add a brief parenthetical reference or one-sentence description in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the new EpicTours dataset is invoked to demonstrate multi-hour capability, but its statistics, length distribution, and annotation details are not reported, undermining the claim that the method scales to 3-hour videos.
Authors: This is a fair observation about the abstract's brevity. The manuscript contains a full section describing EpicTours, including video lengths up to 3 hours, frame counts, and annotation protocol for dense segmentation. We will incorporate concise statistics (e.g., 'videos of 30 min to 3 h duration') into the revised abstract to support the scaling claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description contain no equations, fitted parameters, or derivation steps that can be inspected. The surprise metric is asserted to be mathematically defined and the three-frame operation is presented as an architectural choice enabling long-video TTT, without any reduction to inputs by construction, self-citation chains, or renamed empirical patterns. The central claims rest on design decisions and empirical results on a new dataset rather than a closed self-referential loop. This is the common honest outcome of a self-contained method description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El- Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Emerging Properties in Self-Supervised Vision Transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging Properties in Self-Supervised Vision Transformers. InICCV, 2021
2021
-
[3]
Online model distillation for efficient video inference.arXiv preprint arXiv:1812.02699, 2018
Ravi Teja Mullapudi, Steven Chen, Keyi Zhang, Deva Ramanan, and Kayvon Fa- tahalian. Online model distillation for efficient video inference.arXiv preprint arXiv:1812.02699, 2018
-
[4]
Test-time training on video streams.Journal of Ma- chine Learning Research, 26(9):1–29, 2025
Renhao Wang, Yu Sun, Arnuv Tandon, Yossi Gandelsman, Xinlei Chen, Alexei A Efros, and Xiaolong Wang. Test-time training on video streams.Journal of Ma- chine Learning Research, 26(9):1–29, 2025
2025
-
[5]
Programming pearls: algorithm design techniques.Communications of the ACM, 27(9):865–873, 1984
Jon Bentley. Programming pearls: algorithm design techniques.Communications of the ACM, 27(9):865–873, 1984
1984
-
[6]
Learningdistributedrepresentationsofconcepts
GeoffreyEHinton. Learningdistributedrepresentationsofconcepts. InProceedings of the Annual Meeting of the Cognitive Science Society, volume 8, 1986
1986
-
[7]
Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
-
[8]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017. 7 Recently, a form of analog bits for generative models was proposed. That might be an interesting idea to try next 16 R. Modi, S. Noel, X. Lian...
2017
-
[9]
Lookahead op- timizer: k steps forward, 1 step back.Advances in neural information processing systems, 32, 2019
Michael Zhang, James Lucas, Jimmy Ba, and Geoffrey E Hinton. Lookahead op- timizer: k steps forward, 1 step back.Advances in neural information processing systems, 32, 2019
2019
-
[10]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Learning and using the arrow of time
Donglai Wei, Joseph J Lim, Andrew Zisserman, and William T Freeman. Learning and using the arrow of time. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8052–8060, 2018
2018
-
[12]
The arrow of time.Scientific American, 233(6):56–69, 1975
David Layzer. The arrow of time.Scientific American, 233(6):56–69, 1975
1975
-
[13]
Collaborative filter- ing and deep learning based recommendation system for cold start items.Expert systems with applications, 69:29–39, 2017
Jian Wei, Jianhua He, Kai Chen, Yi Zhou, and Zuoyin Tang. Collaborative filter- ing and deep learning based recommendation system for cold start items.Expert systems with applications, 69:29–39, 2017
2017
-
[14]
Step: Segmenting and tracking every pixel.arXiv preprint arXiv:2102.11859, 2021
Mark Weber, Jun Xie, Maxwell Collins, Yukun Zhu, Paul Voigtlaender, Hartwig Adam, Bradley Green, Andreas Geiger, Bastian Leibe, Daniel Cremers, et al. Step: Segmenting and tracking every pixel.arXiv preprint arXiv:2102.11859, 2021
-
[16]
something something
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzyn- ska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learn- ing and evaluating visual common sense. InProceedings of the IEEE international conference on computer vision, pages 5842...
2017
-
[17]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875–21911, 2024
2024
-
[18]
Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The International Journal of Robotics Research, 32(11):1231–1237, 2013
2013
-
[19]
Scannet: Richly-annotated 3d reconstructions of indoor scenes
Angela Dai, Angel X Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, and Matthias Nießner. Scannet: Richly-annotated 3d reconstructions of indoor scenes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 5828–5839, 2017
2017
-
[20]
Palazzolo, J
E. Palazzolo, J. Behley, P. Lottes, P. Giguère, and C. Stachniss. ReFusion: 3D Re- construction in Dynamic Environments for RGB-D Cameras Exploiting Residuals. 2019
2019
-
[21]
Indoor segmen- tation and support inference from rgbd images
Pushmeet Kohli Nathan Silberman, Derek Hoiem and Rob Fergus. Indoor segmen- tation and support inference from rgbd images. InECCV, 2012
2012
-
[22]
Butler, Jonas Wulff, Garrett B
Daniel J. Butler, Jonas Wulff, Garrett B. Stanley, and Michael J. Black.A Natu- ralistic Open Source Movie for Optical Flow Evaluation, page 611–625. Jan 2012
2012
-
[23]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus En- zweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In2016 IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR), pages 3213–3223, 2016
2016
-
[25]
Perazzi, J
F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine- Hornung. A benchmark dataset and evaluation methodology for video object seg- mentation. InComputer Vision and Pattern Recognition, 2016. Forget, Anticipate and Adapt: Test Time Training for Long Videos 17
2016
-
[26]
Youtube-vos: Sequence-to-sequence video object segmentation
Ning Xu, Linjie Yang, Yuchen Fan, Jianchao Yang, Dingcheng Yue, Yuchen Liang, Brian Price, Scott Cohen, and Thomas Huang. Youtube-vos: Sequence-to-sequence video object segmentation. InProceedings of the European conference on computer vision (ECCV), pages 585–601, 2018
2018
-
[27]
Robodepth: Robust out-of-distribution depth estimation under corruptions.Advances in Neural Information Processing Systems, 36:21298–21342, 2023
Lingdong Kong, Shaoyuan Xie, Hanjiang Hu, Lai Xing Ng, Benoit Cottereau, and Wei Tsang Ooi. Robodepth: Robust out-of-distribution depth estimation under corruptions.Advances in Neural Information Processing Systems, 36:21298–21342, 2023
2023
-
[28]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Rama- monjisoa, et al. Dinov3.arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Masked Autoencoders Are Scalable Vision Learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross B. Girshick. Maskedautoencodersarescalablevisionlearners.CoRR,abs/2111.06377, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Tent: Fully Test-time Adaptation by Entropy Minimization
Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Dar- rell. Tent: Fully test-time adaptation by entropy minimization.arXiv preprint arXiv:2006.10726, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[31]
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.arXiv:2406.09414, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Neural video depth stabilizer
Yiran Wang, Min Shi, Jiaqi Li, Zihao Huang, Zhiguo Cao, Jianming Zhang, Ke Xian, and Guosheng Lin. Neural video depth stabilizer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9466–9476, 2023
2023
-
[33]
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Matteo Poggi, and Yiyi Liao. Learning temporally consistent video depth from video diffusion priors.arXiv preprint arXiv:2406.01493, 2024
-
[34]
WenboHu,XiangjunGao,XiaoyuLi,SijieZhao,XiaodongCun,YongZhang,Long Quan, and Ying Shan. Depthcrafter: Generating consistent long depth sequences for open-world videos.arXiv preprint arXiv:2409.02095, 2024
-
[35]
Depth any video with scalable synthetic data
Honghui Yang, Di Huang, Wei Yin, Chunhua Shen, Haifeng Liu, Xiaofei He, Binbin Lin, Wanli Ouyang, and Tong He. Depth any video with scalable synthetic data. arXiv preprint arXiv:2410.10815, 2024
-
[36]
Video depth anything: Consistent depth estimation for super- long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super- long videos. InProceedings of the Computer Vision and Pattern Recognition Con- ference, pages 22831–22840, 2025
2025
-
[37]
Ma-lmm: Memory-augmented large mul- timodalmodelforlong-termvideounderstanding
Bo He, Hengduo Li, Young Kyun Jang, Menglin Jia, Xuefei Cao, Ashish Shah, Abhinav Shrivastava, and Ser-Nam Lim. Ma-lmm: Memory-augmented large mul- timodalmodelforlong-termvideounderstanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13504–13514, 2024
2024
-
[38]
Gammerman, V
A. Gammerman, V. Vovk, and V. Vapnik. Learning by transduction. InIn Un- certainty in Artificial Intelligence, pages 148–155. Morgan Kaufmann, 1998
1998
-
[39]
Kotz.Estimation of Dependences Based on Empirical Data: Empirical Inference Science (Information Science and Statistics)
Vladimir Vapnik and S. Kotz.Estimation of Dependences Based on Empirical Data: Empirical Inference Science (Information Science and Statistics). Springer- Verlag, Berlin, Heidelberg, 2006
2006
-
[40]
Local learning algorithms.Neural computation, 4(6):888–900, 1992
Léon Bottou and Vladimir Vapnik. Local learning algorithms.Neural computation, 4(6):888–900, 1992
1992
-
[41]
Svm-knn: Dis- criminative nearest neighbor classification for visual category recognition
Hao Zhang, Alexander C Berg, Michael Maire, and Jitendra Malik. Svm-knn: Dis- criminative nearest neighbor classification for visual category recognition. In2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’06), volume 2, pages 2126–2136. IEEE, 2006. 18 R. Modi, S. Noel, X. Liang, Y.S. Rawat
2006
-
[42]
Moritz Hardt and Yu Sun. Test-time training on nearest neighbors for large lan- guage models.arXiv preprint arXiv:2305.18466, 2023
-
[43]
InFind- ings of the Association for Computational Linguis- tics: NAACL 2025, pages 2358–2372
Xiangyu Qi, Ashwinee Panda, Kaifeng Lyu, Xiao Ma, Subhrajit Roy, Ahmad Beirami, Prateek Mittal, and Peter Henderson. Safety alignment should be made more than just a few tokens deep.arXiv preprint arXiv:2406.05946, 2024
-
[44]
Online domain adaptation of a pre-trained cascade of classifiers
Vidit Jain and Erik Learned-Miller. Online domain adaptation of a pre-trained cascade of classifiers. InCVPR 2011, pages 577–584. IEEE, 2011
2011
-
[45]
zero-shot
Assaf Shocher, Nadav Cohen, and Michal Irani. “zero-shot” super-resolution using deep internal learning. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3118–3126, 2018
2018
-
[46]
Mystyle: A personalized generative prior.arXiv preprint arXiv:2203.17272, 2022
Yotam Nitzan, Kfir Aberman, Qiurui He, Orly Liba, Michal Yarom, Yossi Gandels- man, Inbar Mosseri, Yael Pritch, and Daniel Cohen-Or. Mystyle: A personalized generative prior.arXiv preprint arXiv:2203.17272, 2022
-
[47]
Sepico:Semantic-guidedpixelcontrastfordomainadaptivesemanticsegmentation
Binhui Xie, Shuang Li, Mingjia Li, Chi Harold Liu, Gao Huang, and Guoren Wang. Sepico:Semantic-guidedpixelcontrastfordomainadaptivesemanticsegmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023
2023
-
[48]
Learning to adapt for stereo
Alessio Tonioni, Oscar Rahnama, Thomas Joy, Luigi Di Stefano, Thalaiyasingam Ajanthan, and Philip HS Torr. Learning to adapt for stereo. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9661–9670, 2019
2019
-
[49]
Real-time self-adaptive deep stereo
Alessio Tonioni, Fabio Tosi, Matteo Poggi, Stefano Mattoccia, and Luigi Di Ste- fano. Real-time self-adaptive deep stereo. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 195–204, 2019
2019
-
[50]
Online depth learning against forgetting in monocular videos
Zhenyu Zhang, Stephane Lathuiliere, Elisa Ricci, Nicu Sebe, Yan Yan, and Jian Yang. Online depth learning against forgetting in monocular videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4494–4503, 2020
2020
-
[51]
Open-world stereo video matching with deep rnn
Yiran Zhong, Hongdong Li, and Yuchao Dai. Open-world stereo video matching with deep rnn. InProceedings of the European Conference on Computer Vision (ECCV), pages 101–116, 2018
2018
-
[52]
Consistent video depth estimation.ACM Transactions on Graphics (ToG), 39(4):71–1, 2020
Xuan Luo, Jia-Bin Huang, Richard Szeliski, Kevin Matzen, and Johannes Kopf. Consistent video depth estimation.ACM Transactions on Graphics (ToG), 39(4):71–1, 2020
2020
-
[53]
Self-supervised policy adaptation during deployment.arXiv preprint arXiv:2007.04309, 2020
Nicklas Hansen, Rishabh Jangir, Yu Sun, Guillem Alenyà, Pieter Abbeel, Alexei A Efros, Lerrel Pinto, and Xiaolong Wang. Self-supervised policy adaptation during deployment.arXiv preprint arXiv:2007.04309, 2020
-
[54]
Online learning of unknown dynamics for model-based controllers in legged locomotion.IEEE Robotics and Automation Letters, 6(4):8442–8449, 2021
Yu Sun, Wyatt L Ubellacker, Wen-Loong Ma, Xiang Zhang, Changhao Wang, Noel V Csomay-Shanklin, Masayoshi Tomizuka, Koushil Sreenath, and Aaron D Ames. Online learning of unknown dynamics for model-based controllers in legged locomotion.IEEE Robotics and Automation Letters, 6(4):8442–8449, 2021
2021
-
[55]
Ttt++: When does self-supervised test-time train- ing fail or thrive?Advances in Neural Information Processing Systems, 34, 2021
Yuejiang Liu, Parth Kothari, Bastien van Delft, Baptiste Bellot-Gurlet, Taylor Mordan, and Alexandre Alahi. Ttt++: When does self-supervised test-time train- ing fail or thrive?Advances in Neural Information Processing Systems, 34, 2021
2021
-
[56]
Robust test-time adaptation in dynamic scenarios
Longhui Yuan, Binhui Xie, and Shuang Li. Robust test-time adaptation in dynamic scenarios. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15922–15932, 2023
2023
-
[57]
On the road to online adaptation for semantic image segmentation
Riccardo Volpi, Pau De Jorge, Diane Larlus, and Gabriela Csurka. On the road to online adaptation for semantic image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19184–19195, 2022. Forget, Anticipate and Adapt: Test Time Training for Long Videos 19
2022
-
[58]
Overview of the h
Thomas Wiegand, Gary J Sullivan, Gisle Bjontegaard, and Ajay Luthra. Overview of the h. 264/avc video coding standard.IEEE Transactions on circuits and sys- tems for video technology, 13(7):560–576, 2003
2003
-
[59]
Generalization in reinforcement learning: Successful examples using sparse coarse coding.Advances in neural information processing systems, 8, 1995
Richard S Sutton. Generalization in reinforcement learning: Successful examples using sparse coarse coding.Advances in neural information processing systems, 8, 1995
1995
-
[60]
Geoffrey Hinton. The forward-forward algorithm: Some preliminary investigations. arXiv preprint arXiv:2212.13345, 2(3):5, 2022
-
[61]
Putting an end to end-to- end: Gradient-isolated learning of representations.Advances in neural information processing systems, 32, 2019
Sindy Löwe, Peter O’Connor, and Bastiaan Veeling. Putting an end to end-to- end: Gradient-isolated learning of representations.Advances in neural information processing systems, 32, 2019
2019
-
[62]
Difference tar- get propagation
Dong-Hyun Lee, Saizheng Zhang, Asja Fischer, and Yoshua Bengio. Difference tar- get propagation. InJoint european conference on machine learning and knowledge discovery in databases, pages 498–515. Springer, 2015
2015
-
[63]
Qinyu Li, Yee Whye Teh, and Razvan Pascanu. Noprop: Training neural net- works without full back-propagation or full forward-propagation.arXiv preprint arXiv:2503.24322, 2025
-
[64]
Geoffrey hinton—the ‘godfather’ of ai and neural networks.MIT Technology Review, 2021
Cade Metz. Geoffrey hinton—the ‘godfather’ of ai and neural networks.MIT Technology Review, 2021
2021
-
[65]
wake- sleep
Geoffrey E Hinton, Peter Dayan, Brendan J Frey, and Radford M Neal. The" wake- sleep" algorithm for unsupervised neural networks.Science, 268(5214):1158–1161, 1995
1995
-
[66]
Carnegie-Mellon University, Department of Computer Science Pittsburgh, PA, 1984
Geoffrey E Hinton, Terrence J Sejnowski, and David H Ackley.Boltzmann ma- chines: Constraint satisfaction networks that learn. Carnegie-Mellon University, Department of Computer Science Pittsburgh, PA, 1984
1984
-
[67]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic dif- ferential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[68]
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
Yu Sun, Xinhao Li, Karan Dalal, Jiarui Xu, Arjun Vikram, Genghan Zhang, Yann Dubois, Xinlei Chen, Xiaolong Wang, Sanmi Koyejo, et al. Learning to (learn at test time): Rnns with expressive hidden states.arXiv preprint arXiv:2407.04620, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[69]
One-minute video generation with test-time training.arXiv preprint arXiv:2504.05298, 2025
Karan Dalal, Daniel Koceja, Gashon Hussein, Jiarui Xu, Yue Zhao, Youjin Song, Shihao Han, Ka Chun Cheung, Jan Kautz, Carlos Guestrin, et al. One-minute video generation with test-time training.arXiv preprint arXiv:2504.05298, 2025
-
[70]
Masked-attention Mask Transformer for Universal Image Segmentation
Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention Mask Transformer for Universal Image Segmentation. InCVPR, 2022
2022
-
[71]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Khurram Soomro, Amir Roshan Zamir, and Mubarak Shah. Ucf101: A dataset of 101 human actions classes from videos in the wild.arXiv preprint arXiv:1212.0402, 2012
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[72]
The cityscapes dataset for semantic urban scene understanding
Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus En- zweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016
2016
-
[73]
Masked autoencoders are scalable vision learners
KaimingHe,XinleiChen,SainingXie,YanghaoLi,PiotrDollár,andRossGirshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022. 20 R. Modi, S. Noel, X. Liang, Y.S. Rawat
2022
-
[74]
" " Computes s i n u s o i d a l p o s i t i o n a l encoding for a time step
Yossi Gandelsman, Yu Sun, Xinlei Chen, and Alexei Efros. Test-time training with masked autoencoders.Advances in Neural Information Processing Systems, 35:29374–29385, 2022. Forget, Anticipate and Adapt: Test Time Training for Long Videos 21 Table of Contents A Broader Impact................................................22 B Reproducibility Statement......
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.