VIGIL: Runtime Enforcement of Behavioral Specifications in AI Agent Skills
Pith reviewed 2026-06-26 04:40 UTC · model grok-4.3
The pith
VIGIL enforces AI agent behavioral policies by translating natural-language specifications into SMT constraints over finite execution traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
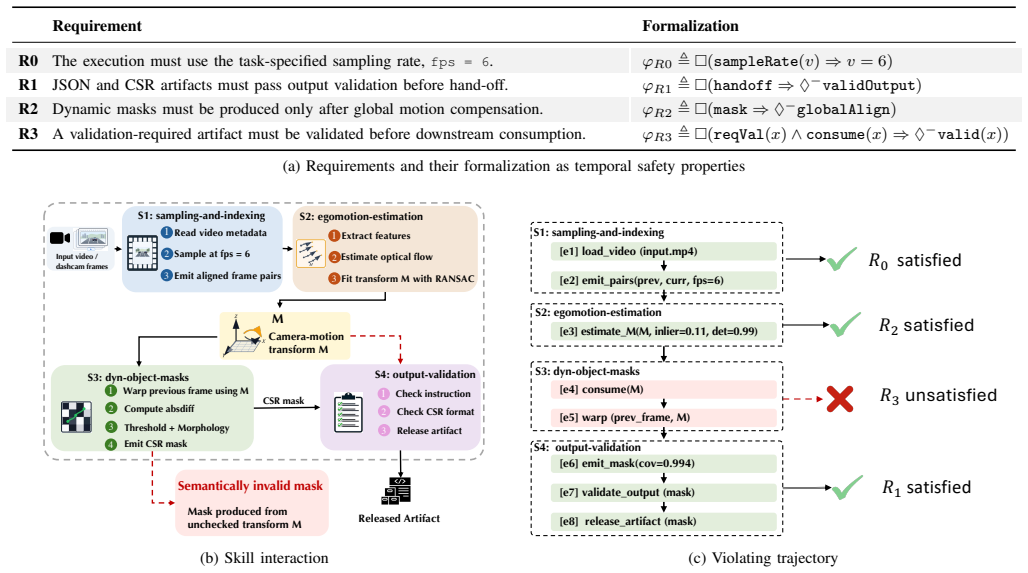
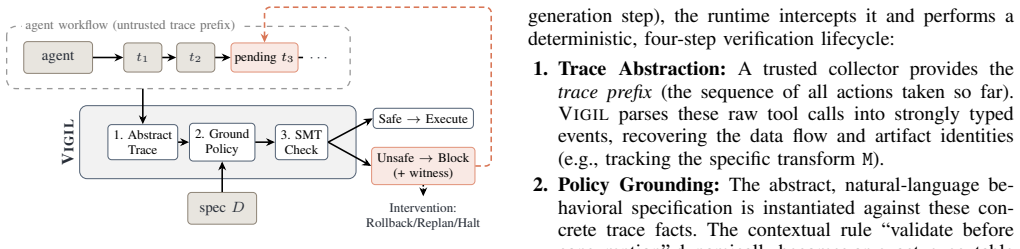
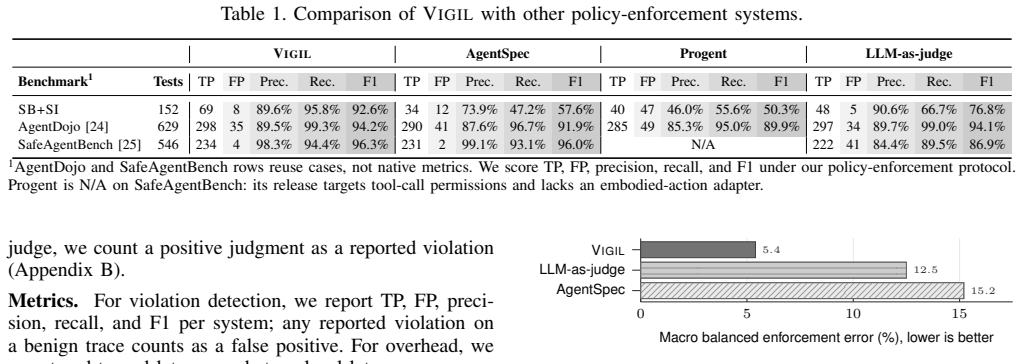
VIGIL checks an agent's actual execution trace against behavioral policies from skill specifications, operator-defined constraints, and global rules spanning multiple skills. To make policies executable, it introduces a policy language that captures context-specific enforcement requirements over agent-tool events, including temporal dependencies, argument constraints, and value-flow conditions. The language is paired with symbolic evaluation rules that translate policies into SMT constraints over finite traces, allowing detection of violations that depend on event order, argument relationships, or cross-call value flow.
What carries the argument
Policy language paired with symbolic evaluation rules that translate policies into SMT constraints over finite traces.
Load-bearing premise
Natural-language skill specifications and operator constraints can be faithfully captured in the proposed policy language and translated to SMT constraints over finite traces without significant loss of intended meaning or introduction of spurious violations.
What would settle it
Finding a realistic multi-action agent trace where a clear policy violation is missed by the SMT encoding or where a compliant trace triggers a false positive violation alert.
Figures





read the original abstract
Agentic systems increasingly act through third-party skills, allowing model-generated decisions to affect files, communication channels, and cyber-physical devices. These skills often include natural-language specifications that define access permissions, disclosure limits, execution privileges, and required preconditions. Although such specifications describe the intended boundaries of skill behavior, they do not by themselves provide executable runtime enforcement. Enforcing them raises a contextual granularity challenge: even when a policy is written for a particular task context, a monitor must still decide which events to observe, what state to retain, how far across the execution to reason, and where to intervene. Choosing the wrong granularity can either block benign executions or miss violations that emerge only across multiple actions. Most existing enforcement mechanisms, however, assume a fixed event model or enforcement point. In this work, we present VIGIL, an end-to-end runtime enforcement framework for agentic systems. VIGIL checks an agent's actual execution trace against behavioral policies from skill specifications, operator-defined constraints, and global rules spanning multiple skills. To make such policies executable, VIGIL introduces a policy language that captures context-specific enforcement requirements over agent-tool events, including temporal dependencies, argument constraints, and value-flow conditions. The language is paired with symbolic evaluation rules that translate policies into SMT constraints over finite traces, allowing VIGIL to detect violations that depend on event order, argument relationships, or cross-call value flow rather than relying on fixed single-call filters. On real LLM-agent runs spanning office-document, operational, and engineering tasks, VIGIL detects policy violations with over 95% recall and a false-positive rate below 10%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
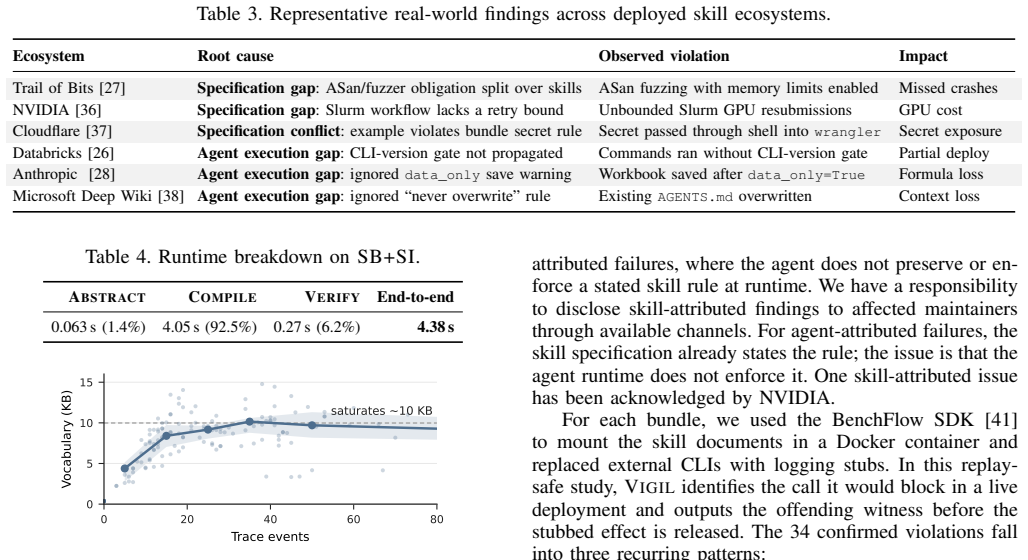
Summary. VIGIL is an end-to-end runtime enforcement framework for AI agent skills that introduces a policy language capturing context-specific requirements (temporal dependencies, argument constraints, value-flow conditions) from natural-language skill specs, operator constraints, and global rules. Policies are translated via symbolic evaluation rules into SMT constraints over finite traces, enabling detection of violations that span multiple actions rather than relying on fixed single-call filters. The central empirical claim is that, on real LLM-agent execution traces from office-document, operational, and engineering tasks, VIGIL achieves >95% recall with <10% false-positive rate.
Significance. If the translation from natural-language specifications to the policy language and SMT encoding is faithful and the evaluation methodology is sound, the work would offer a concrete mechanism for contextual runtime enforcement in agentic systems that interact with third-party skills, addressing a gap left by fixed event models. The symbolic approach to handling cross-call value flow and order-dependent constraints is a technical contribution worth noting if the reported metrics are reproducible and not artifacts of the formalization step itself.
major comments (3)
- [Abstract / Evaluation] Abstract and evaluation description: the headline result (>95% recall, <10% FPR) is measured on policies that have already been translated from natural-language specifications into the proposed policy language and SMT constraints. No independent validation (e.g., manual audit of a sample of translated policies against original intent, or comparison against unenforced baseline traces) is described to confirm that the encoding preserves preconditions, value-flow conditions, or temporal dependencies without introducing spurious violations or dropping intended constraints. This is load-bearing for the central claim because any systematic mismatch directly affects the reported recall/FPR figures.
- [Evaluation] Evaluation setup: the abstract reports strong empirical numbers but supplies no information on how ground-truth violations were labeled, what trace collection protocol was used, what baselines (if any) were compared against, or how policy granularity was varied. Without these details it is impossible to assess whether the 95% recall holds under different task distributions or policy formulations.
- [Symbolic evaluation rules] § on symbolic translation rules: the claim that the SMT encoding handles 'cross-call value flow' and 'context-specific enforcement requirements' without loss of meaning is central, yet the manuscript provides no formal argument or empirical check that the finite-trace encoding is semantics-preserving for the multi-action scenarios in the office-document and engineering tasks.
minor comments (2)
- [Policy language definition] Notation for the policy language elements (e.g., how temporal operators and value-flow predicates are written) should be introduced with a small concrete example early in the paper to improve readability.
- [Abstract] The abstract states 'over 95% recall' and 'below 10%' without confidence intervals or per-task breakdowns; adding these would strengthen the presentation even if the underlying data are sound.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments correctly identify gaps in validation and methodological transparency that affect the strength of the central empirical claims. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the headline result (>95% recall, <10% FPR) is measured on policies that have already been translated from natural-language specifications into the proposed policy language and SMT constraints. No independent validation (e.g., manual audit of a sample of translated policies against original intent, or comparison against unenforced baseline traces) is described to confirm that the encoding preserves preconditions, value-flow conditions, or temporal dependencies without introducing spurious violations or dropping intended constraints. This is load-bearing for the central claim because any systematic mismatch directly affects the reported recall/FPR figures.
Authors: We acknowledge that the manuscript does not describe an independent validation of the translation step. The reported metrics reflect end-to-end enforcement on translated policies. In revision we will add a dedicated subsection reporting a manual audit of 50 sampled policies (two reviewers, inter-rater agreement measured) that compares translated SMT constraints against original natural-language intent, plus a baseline comparison of unenforced traces to quantify the effect of enforcement. revision: yes
-
Referee: [Evaluation] Evaluation setup: the abstract reports strong empirical numbers but supplies no information on how ground-truth violations were labeled, what trace collection protocol was used, what baselines (if any) were compared against, or how policy granularity was varied. Without these details it is impossible to assess whether the 95% recall holds under different task distributions or policy formulations.
Authors: The Evaluation section of the full manuscript describes trace collection from LLM-agent executions on the three task domains and ground-truth labeling by expert review against the source specifications. We agree the abstract and high-level summary omit these details. The revision will expand the abstract with a brief protocol summary and insert a new 'Evaluation Methodology' subsection covering trace collection, labeling procedure, inter-rater process, baselines (naive per-action filters and rule-based monitors), and experiments that vary policy granularity. revision: yes
-
Referee: [Symbolic evaluation rules] § on symbolic translation rules: the claim that the SMT encoding handles 'cross-call value flow' and 'context-specific enforcement requirements' without loss of meaning is central, yet the manuscript provides no formal argument or empirical check that the finite-trace encoding is semantics-preserving for the multi-action scenarios in the office-document and engineering tasks.
Authors: The manuscript presents the symbolic rules and applies them to multi-action traces but supplies neither a standalone formal semantics argument nor an isolated empirical check of preservation. We will add an appendix containing a formal argument that the finite-trace SMT encoding is semantics-preserving for the supported policy constructs (temporal, argument, and value-flow) and an empirical validation on a curated set of synthetic multi-action traces that isolate cross-call value flow and ordering constraints. revision: yes
Circularity Check
No significant circularity; evaluation on external real runs is independent of internal definitions.
full rationale
The paper's central empirical claims (>95% recall, <10% FPR) are presented as measured on real LLM-agent executions across tasks. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citation chains are identifiable from the provided text. The policy language and SMT translation are introduced as a new mechanism, but performance is not shown to be forced by construction from those mechanisms alone. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Equipping agents for the real world with Agent Skills,
Anthropic, “Equipping agents for the real world with Agent Skills,” https://www.anthropic.com/engineering/equipping-agents-for-the-rea l-world-with-agent-skills, 2025
2025
-
[2]
GitHub Copilot now supports Agent Skills,
GitHub, “GitHub Copilot now supports Agent Skills,” https://github .blog/changelog/2025-12-18-github-copilot-now-supports-agent-ski lls/, 2025
2025
-
[3]
Level up your agents: Announcing Google’s official skills repository,
Google Cloud, “Level up your agents: Announcing Google’s official skills repository,” https://cloud.google.com/blog/topics/developers-p ractitioners/level-up-your-agents-announcing-googles-official-skill s-repository, 2026
2026
-
[4]
AWS Agent Toolkit: Skills,
Amazon Web Services, “AWS Agent Toolkit: Skills,” https://docs.a ws.amazon.com/agent-toolkit/latest/userguide/skills.html, 2026
2026
-
[5]
NVIDIA verified agent skills provide capability gover- nance for AI agents,
NVIDIA, “NVIDIA verified agent skills provide capability gover- nance for AI agents,” https://developer.nvidia.com/blog/nvidia-verif ied-agent-skills-provide-capability-governance-for-ai-agents/, 2026
2026
-
[6]
Echoleak: The first real-world zero-click prompt injection exploit in a production llm system,
P. Reddy and A. S. Gujral, “Echoleak: The first real-world zero-click prompt injection exploit in a production llm system,” inProceedings of the AAAI Symposium Series, vol. 7, no. 1, 2025, pp. 303–311
2025
-
[7]
ForcedLeak: AI agent risks exposed in Salesforce Agentforce,
Noma Security, “ForcedLeak: AI agent risks exposed in Salesforce Agentforce,” https://noma.security/blog/forcedleak-agent-risks-expos ed-in-salesforce-agentforce/, 2025
2025
-
[8]
A Meta AI security researcher said an OpenClaw agent ran amok on her inbox,
J. Bort, “A Meta AI security researcher said an OpenClaw agent ran amok on her inbox,” https://techcrunch.com/2026/02/23/a-meta-ai-s ecurity-researcher-said-an-openclaw-agent-ran-amok-on-her-inbox/, 2026
2026
-
[9]
No attack required: Semantic fuzzing for specification violations in agent skills,
Y . Li, H. Wen, Y . Chen, H. Liu, Y . Tian, and Y . Feng, “No attack required: Semantic fuzzing for specification violations in agent skills,” arXiv preprint arXiv:2605.13044, 2026
Pith/arXiv arXiv 2026
-
[10]
A survey of autonomous driving: Common practices and emerging technologies,
E. Yurtsever, J. Lambert, A. Carballo, and K. Takeda, “A survey of autonomous driving: Common practices and emerging technologies,” IEEE access, vol. 8, pp. 58 443–58 469, 2020
2020
-
[11]
Skillsbench: Benchmarking how well agent skills work across diverse tasks,
X. Li, W. Chen, Y . Liu, S. Zheng, X. Chen, Y . He, Y . Li, B. You, H. Shen, J. Sunet al., “Skillsbench: Benchmarking how well agent skills work across diverse tasks,”arXiv preprint arXiv:2602.12670, 2026
Pith/arXiv arXiv 2026
-
[12]
Build agents you can trust across any framework with open evals and a control standard,
Microsoft, “Build agents you can trust across any framework with open evals and a control standard,” https://devblogs.microsoft.com/f oundry/build-2026-open-trust-stack-ai-agents/, 2026
2026
-
[13]
Overview of NVIDIA OpenShell,
NVIDIA, “Overview of NVIDIA OpenShell,” https://docs.nvidia.co m/openshell/about/overview, 2026
2026
-
[14]
Agentspec: Customizable runtime enforcement for safe and reliable llm agents,
H. Wang, C. M. Poskitt, and J. Sun, “Agentspec: Customizable runtime enforcement for safe and reliable llm agents,”arXiv preprint arXiv:2503.18666, 2025
Pith/arXiv arXiv 2025
-
[15]
Pro- gent: Programmable privilege control for llm agents,
T. Shi, J. He, Z. Wang, H. Li, L. Wu, W. Guo, and D. Song, “Pro- gent: Programmable privilege control for llm agents,”arXiv preprint arXiv:2504.11703, 2025
Pith/arXiv arXiv 2025
-
[16]
Contextual agent security: A policy for every purpose,
L. Tsai and E. Bagdasarian, “Contextual agent security: A policy for every purpose,” inProceedings of the 2025 Workshop on Hot Topics in Operating Systems, 2025, pp. 8–17
2025
-
[17]
Policy compiler for secure agentic systems,
N. Palumbo, S. Choudhary, J. Choi, P. Chalasani, and S. Jha, “Policy compiler for secure agentic systems,”arXiv e-prints, pp. arXiv–2602, 2026
2026
-
[18]
Defeating prompt injec- tions by design,
E. Debenedetti, I. Shumailov, T. Fan, J. Hayes, N. Carlini, D. Fabian, C. Kern, C. Shi, A. Terzis, and F. Tramèr, “Defeating prompt injec- tions by design,”arXiv preprint arXiv:2503.18813, 2025
Pith/arXiv arXiv 2025
-
[19]
Securing ai agents with information-flow control,
M. Costa, B. Köpf, A. Kolluri, A. Paverd, M. Russinovich, A. Salem, S. Tople, L. Wutschitz, and S. Zanella-Béguelin, “Securing ai agents with information-flow control,”arXiv preprint arXiv:2505.23643, 2025
Pith/arXiv arXiv 2025
-
[20]
Identifying the risks of lm agents with an lm-emulated sandbox,
Y . Ruan, H. Dong, A. Wang, S. Pitis, Y . Zhou, J. Ba, Y . Dubois, C. Maddison, and T. Hashimoto, “Identifying the risks of lm agents with an lm-emulated sandbox,” inInternational Conference on Learn- ing Representations, vol. 2024, 2024, pp. 27 031–27 098
2024
-
[21]
Policy-invisible violations in llm-based agents,
J. Wu and M. Gong, “Policy-invisible violations in llm-based agents,” arXiv preprint arXiv:2604.12177, 2026
Pith/arXiv arXiv 2026
-
[22]
Satisfiability modulo theories,
C. Barrett and C. Tinelli, “Satisfiability modulo theories,” inHand- book of model checking. Springer, 2018, pp. 305–343
2018
-
[23]
Skill-inject: Measuring agent vulnerability to skill file attacks,
D. Schmotz, L. Beurer-Kellner, S. Abdelnabi, and M. An- driushchenko, “Skill-inject: Measuring agent vulnerability to skill file attacks,”arXiv preprint arXiv:2602.20156, 2026
Pith/arXiv arXiv 2026
-
[24]
Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,
E. Debenedetti, J. Zhang, M. Balunovic, L. Beurer-Kellner, M. Fis- cher, and F. Tramèr, “Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents,”Advances in Neural Information Processing Systems, vol. 37, pp. 82 895–82 920, 2024
2024
-
[25]
Safeagentbench: A benchmark for safe task planning of embodied llm agents,
S. Yin, X. Pang, Y . Ding, M. Chen, Y . Bi, Y . Xiong, W. Huang, Z. Xiang, J. Shao, and S. Chen, “Safeagentbench: A benchmark for safe task planning of embodied llm agents,”arXiv preprint arXiv:2412.13178, 2024
arXiv 2024
-
[26]
Databricks Agent Skills,
Databricks, “Databricks Agent Skills,” https://github.com/databricks/ databricks-agent-skills, 2025, accessed: 2026-06-11
2025
-
[27]
Testing handbook skills for Claude Code,
Trail of Bits, “Testing handbook skills for Claude Code,” https://gith ub.com/trailofbits/skills/tree/main/plugins/testing-handbook-skills, 2025, accessed: 2026-06-10
2025
-
[28]
Anthropic skills,
Anthropic, “Anthropic skills,” https://github.com/anthropics/skills/tre e/main/skills, 2026
2026
-
[29]
Model context protocol specification,
Model Context Protocol, “Model context protocol specification,” http s://modelcontextprotocol.io, 2024, accessed: June 26, 2026
2024
-
[30]
Enforceable security policies,
F. B. Schneider, “Enforceable security policies,”ACM Transactions on Information and System Security (TISSEC), vol. 3, no. 1, pp. 30– 50, 2000
2000
-
[31]
Edit automata: Enforcement mechanisms for run-time security policies,
J. Ligatti, L. Bauer, and D. Walker, “Edit automata: Enforcement mechanisms for run-time security policies,”International Journal of Information Security, vol. 4, no. 1, pp. 2–16, 2005
2005
-
[32]
Patterns in property specifications for finite-state verification,
M. B. Dwyer, G. S. Avrunin, and J. C. Corbett, “Patterns in property specifications for finite-state verification,” inProceedings of the 21st international conference on Software engineering, 1999, pp. 411–420
1999
-
[33]
Linear temporal logic and linear dynamic logic on finite traces,
G. De Giacomo and M. Y . Vardi, “Linear temporal logic and linear dynamic logic on finite traces,” inProceedings of the Twenty-Third In- ternational Joint Conference on Artificial Intelligence (IJCAI). AAAI Press, 2013, pp. 854–860
2013
-
[34]
Z3: An efficient smt solver,
L. De Moura and N. Bjørner, “Z3: An efficient smt solver,” inIn- ternational conference on Tools and Algorithms for the Construction and Analysis of Systems. Springer, 2008, pp. 337–340
2008
-
[35]
Foray: Towards effective attack synthesis against deep logical vulnerabilities in DeFi protocols,
H. Wen, H. Liu, J. Song, Y . Chen, W. Guo, and Y . Feng, “Foray: Towards effective attack synthesis against deep logical vulnerabilities in DeFi protocols,” inProceedings of the 2024 ACM SIGSAC Con- ference on Computer and Communications Security (CCS), 2024
2024
-
[36]
Nemo-evaluator-launcher skills,
NVIDIA, “Nemo-evaluator-launcher skills,” https://github.com/NVI DIA/skills/tree/8c40eff71464e661df027f547c4a7d0f69fe3693/skills/ NeMo-Evaluator-Launcher, 2026
2026
-
[37]
Cloudflare skills,
Cloudflare, “Cloudflare skills,” https://github.com/cloudflare/skills, 2026
2026
-
[38]
Microsoft skill bundle,
Microsoft, “Microsoft skill bundle,” https://github.com/microsoft/ski lls/, 2026
2026
-
[39]
Agentc- group: Understanding and controlling OS resources of AI agents,
Y . Zheng, J. Fan, Q. Fu, Y . Yang, W. Zhang, and A. Quinn, “Agentc- group: Understanding and controlling OS resources of AI agents,” arXiv preprint arXiv:2602.09345, 2026
arXiv 2026
-
[40]
Clawhub,
ClawHub, “Clawhub,” https://clawhub.ai/, 2026, accessed: 2026-06- 12
2026
-
[41]
Benchflow,
BenchFlow, “Benchflow,” https://github.com/benchflow-ai/benchflo w, 2026, accessed: 2026-06-11
2026
-
[42]
{AddressSanitizer}: A fast address sanity checker,
K. Serebryany, D. Bruening, A. Potapenko, and D. Vyukov, “{AddressSanitizer}: A fast address sanity checker,” in2012 USENIX annual technical conference (USENIX ATC 12), 2012, pp. 309–318
2012
-
[43]
AddressSanitizer — Clang documentation,
LLVM Project, “AddressSanitizer — Clang documentation,” https: //clang.llvm.org/docs/AddressSanitizer.html, accessed: 2026-06-11
2026
-
[44]
The attack and defense landscape of agentic ai: A comprehensive survey,
J. Kim, X. Liu, Z. Wang, S. Qiu, B. Li, W. Guo, and D. Song, “The attack and defense landscape of agentic ai: A comprehensive survey,” arXiv preprint arXiv:2603.11088, 2026
arXiv 2026
-
[45]
Sok: Attack and defense landscape of agentic ai systems,
J. Kim, W. Guo, and D. Song, “Sok: Attack and defense landscape of agentic ai systems,” in35th USENIX Security Symposium (USENIX Security 26), 2026
2026
-
[46]
Ghost in the agent: Re- defining information flow tracking for llm agents,
Y . Cai, W. Tang, C. Wen, and S. Qin, “Ghost in the agent: Re- defining information flow tracking for llm agents,”arXiv preprint arXiv:2604.23374, 2026
Pith/arXiv arXiv 2026
-
[47]
Agentarmor: Enforcing program analysis on agent runtime trace to defend against prompt injection,
P. Wang, Y . Liu, Y . Lu, Y . Cai, H. Chen, Q. Yang, J. Zhang, J. Hong, and Y . Wu, “Agentarmor: Enforcing program analysis on agent runtime trace to defend against prompt injection,”arXiv preprint arXiv:2508.01249, 2025
arXiv 2025
-
[48]
T. Zhang, Y . Xu, J. Wang, K. Guo, X. Xu, B. Xiao, Q. Guan, J. Fan, J. Liu, Z. Liuet al., “Agentsentry: Mitigating indirect prompt injection in llm agents via temporal causal diagnostics and context purification,”arXiv preprint arXiv:2602.22724, 2026
arXiv 2026
-
[49]
H. M. Pysklo, A. Zhuravel, and P. D. Watson, “Agent-diff: Bench- marking llm agents on enterprise api tasks via code execution with state-diff-based evaluation,”arXiv preprint arXiv:2602.11224, 2026
Pith/arXiv arXiv 2026
-
[50]
The keynote trust-management system version 2,
M. Blaze, J. Feigenbaum, J. Ioannidis, and A. Keromytis, “The keynote trust-management system version 2,” RFC Editor, Tech. Rep. RFC 2704, September 1999
1999
-
[51]
The ponder policy specification language,
N. Damianou, N. Dulay, E. Lupu, and M. Sloman, “The ponder policy specification language,” inInternational Workshop on Policies for Distributed Systems and Networks. Springer, 2001, pp. 18–38
2001
-
[52]
Cedar: A new language for expressive, fast, safe, and analyzable authorization,
J. W. Cutler, C. Disselkoen, A. Eline, S. He, K. Headley, M. Hicks, K. Hietala, E. Ioannidis, J. Kastner, A. Mamatet al., “Cedar: A new language for expressive, fast, safe, and analyzable authorization,” Proceedings of the ACM on Programming Languages, vol. 8, no. OOPSLA1, pp. 670–697, 2024
2024
-
[53]
Policies and permissions in aws identity and access management,
Amazon Web Services, “Policies and permissions in aws identity and access management,” https://docs.aws.amazon.com/IAM/latest/Use rGuide/access_policies.html, 2026, accessed: 2026-06-06
2026
-
[54]
What is azure role-based access control (Azure RBAC)?
Microsoft Azure, “What is azure role-based access control (Azure RBAC)?” https://learn.microsoft.com/en-us/azure/role-based-acces s-control/overview, 2026, accessed: 2026-06-06
2026
-
[55]
Iam overview,
Google Cloud, “Iam overview,” https://cloud.google.com/iam/docs/ overview, 2026, accessed: 2026-06-06
2026
-
[56]
Semantic-based automated reasoning for aws access policies using smt,
J. Backes, P. Bolignano, B. Cook, C. Dodge, A. Gacek, K. Luckow, N. Rungta, O. Tkachuk, and C. Varming, “Semantic-based automated reasoning for aws access policies using smt,” in2018 Formal Methods in Computer Aided Design (FMCAD). IEEE, 2018, pp. 1–9
2018
-
[57]
Agent skills for large language models: Archi- tecture, acquisition, security, and the path forward,
R. Xu and Y . Yan, “Agent skills for large language models: Archi- tecture, acquisition, security, and the path forward,”arXiv preprint arXiv:2602.12430, 2026
Pith/arXiv arXiv 2026
-
[58]
Sok: Agentic skills–beyond tool use in llm agents,
Y . Jiang, D. Li, H. Deng, B. Ma, X. Wang, Q. Wang, and G. Yu, “Sok: Agentic skills–beyond tool use in llm agents,”arXiv preprint arXiv:2602.20867, 2026
Pith/arXiv arXiv 2026
-
[59]
Towards secure agent skills: Architecture, threat taxonomy, and security analysis,
Z. Li, J. Wu, X. Ling, X. Cui, and T. Luo, “Towards secure agent skills: Architecture, threat taxonomy, and security analysis,”arXiv preprint arXiv:2604.02837, 2026
Pith/arXiv arXiv 2026
-
[60]
Agent skills in the wild: An empirical study of security vulnerabilities at scale,
Y . Liu, W. Wang, R. Feng, Y . Zhang, G. Xu, G. Deng, Y . Li, and L. Zhang, “Agent skills in the wild: An empirical study of security vulnerabilities at scale,”arXiv preprint arXiv:2601.10338, 2026
Pith/arXiv arXiv 2026
-
[61]
Malicious agent skills in the wild: A large-scale security empirical study,
Y . Liu, Z. Chen, Y . Zhang, G. Deng, Y . Li, J. Ning, Y . Zhang, and L. Y . Zhang, “Malicious agent skills in the wild: A large-scale security empirical study,”arXiv preprint arXiv:2602.06547, 2026
Pith/arXiv arXiv 2026
-
[62]
Harmful- skillbench: How do harmful skills weaponize your agents?
Y . Jiang, Y . Zhang, M. Backes, X. Shen, and Y . Zhang, “Harmful- skillbench: How do harmful skills weaponize your agents?”arXiv preprint arXiv:2604.15415, 2026
Pith/arXiv arXiv 2026
-
[63]
Agenttrap: Measuring runtime trust failures in third-party agent skills,
H. Zhuang, H. Xing, Y . Zhou, Y . Ma, Y . Huang, Y . Shen, Y . Han, and X. Zhang, “Agenttrap: Measuring runtime trust failures in third-party agent skills,”arXiv preprint arXiv:2605.13940, 2026
Pith/arXiv arXiv 2026
-
[64]
Skillprobe: Security auditing for emerging agent skill marketplaces via multi- agent collaboration,
Z. Guo, Z. Chen, X. Nie, J. Lin, Y . Zhou, and W. Zhang, “Skillprobe: Security auditing for emerging agent skill marketplaces via multi- agent collaboration,”arXiv preprint arXiv:2603.21019, 2026
arXiv 2026
-
[65]
Semia: Auditing agent skills via constraint-guided representation synthesis,
H. Wen, Y . Li, H. Liu, C. Shou, Y . Chen, Y . Tian, and Y . Feng, “Semia: Auditing agent skills via constraint-guided representation synthesis,”arXiv preprint arXiv:2605.00314, 2026. Table 5. Representative policy categories and formalizations in SB+SI. Category Example policyFormalization Required event property Period search must include flux uncertain...
Pith/arXiv arXiv 2026
-
[66]
SECURITY_PROTOCOL: the skill’s natural−language policy text
-
[67]
observed_vocabulary: actions, argument roles, command options, predicates, scripts, and text samples recovered from the trace
-
[68]
signature: the allowed condition operators and temporal templates
-
[69]
Grounding contract: − Draft policy statements only; do not classify the trace
policy_language: the target schema and declared role set. Grounding contract: − Draft policy statements only; do not classify the trace. − Use only literals and symbols present in the inputs. − Do not emit event ids, witness ids, SMT variables, expected verdicts, violation labels, or other trace−checking artifacts. − Emit Unsupported when a rule cannot be...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.