Sketched Linear Contrastive Learning: Approximation, Optimization, and Statistical Scaling
Pith reviewed 2026-06-26 05:34 UTC · model grok-4.3
The pith
Sketched linear contrastive learning obeys an explicit scaling law in sketch dimension, sample size, and optimization horizon that accounts for learning interactions between two views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
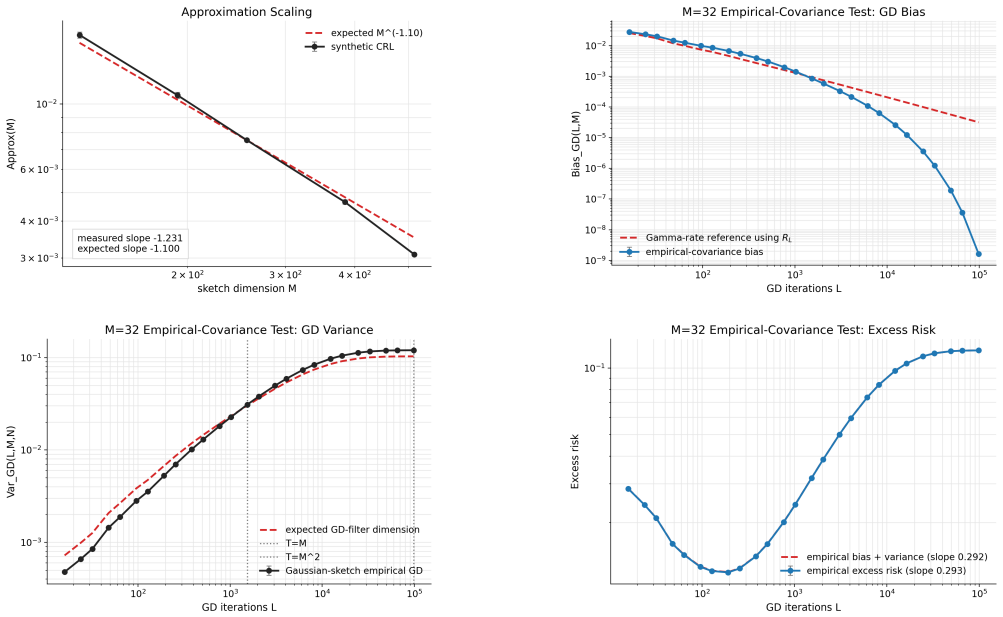
Under a paired Gaussian latent-variable setup with aligned power-law spectra and a contrastive source condition, the risk of the sketched linear contrastive learner decomposes into five components, with the cross term bounded by bias and variance, leading to a scaling law in M, N, and L_eff γ that reflects the bilinear interaction between the two views.
What carries the argument
The risk decomposition into irreducible risk, approximation error, GD bias, GD variance, and cross term for the Gaussian-negative quadratic contrastive surrogate under full-batch empirical gradient descent.
If this is right
- The scaling of optimization error and finite-sample noise differs from linear regression because interactions between views must be learned.
- Balancing sketch dimension M with sample size N and effective horizon L_eff γ becomes necessary to control total risk.
- The upper bound on risk is unaffected by the cross term since it is controlled by bias and variance.
- Guidance is provided for choosing model size, data, and optimization compute in contrastive settings.
Where Pith is reading between the lines
- If the paired Gaussian assumption holds only approximately, the scaling law may still approximate behavior in high-dimensional data with latent structure.
- Similar decompositions could be derived for other self-supervised objectives to compare their scaling behaviors.
- Empirical validation on synthetic paired Gaussian data would confirm the predicted exponents in the scaling law.
Load-bearing premise
The data follows a paired Gaussian latent-variable model with aligned power-law spectra and satisfies the contrastive source condition.
What would settle it
Generate data from non-Gaussian correlated variables or misaligned spectra and measure whether the observed dependence of risk on M, N, and training steps matches the derived scaling law.
Figures
read the original abstract
Scaling laws describe how learning performance varies with model size, data size, and compute. While recent theoretical work has established scaling laws for sketched linear regression, much less is understood for contrastive representation learning. In this paper, we study a sketched linear model for contrastive learning under a paired Gaussian latent-variable setup. The learner observes only sketched views of two correlated variables and trains a bilinear contrastive score by full-batch empirical gradient descent. We analyze a Gaussian-negative quadratic contrastive surrogate under aligned power-law spectra and a contrastive source condition, where we derive a risk decomposition into irreducible risk, approximation error, GD bias, GD variance, and a cross term. The cross term is controlled by the bias and variance and therefore does not affect the upper-bound scaling. Our main theorem gives an explicit scaling law with respect to sketch dimension $M$, sample size $N$, and effective optimization horizon $L_{\mathrm{eff}}\gamma$. Compared with standard linear-regression scaling laws, the contrastive setting must learn interactions between two views, and this changes how optimization and finite-sample noise scale with model size, data, and training time. This provides a first theoretical step toward understanding scaling behavior in contrastive learning and gives guidance for balancing model size, data, and optimization compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies sketched linear contrastive learning under a paired Gaussian latent-variable model with aligned power-law spectra and a contrastive source condition. The learner observes sketched views of two correlated variables and trains a bilinear contrastive score via full-batch empirical gradient descent on a Gaussian-negative quadratic surrogate. The paper derives a risk decomposition into irreducible risk, approximation error, GD bias, GD variance, and cross term (with the cross term controlled by bias and variance so that it does not affect upper-bound scaling), and states a main theorem giving an explicit scaling law for the risk in terms of sketch dimension M, sample size N, and effective optimization horizon L_eff γ. It contrasts the resulting scalings with those of standard linear regression, attributing differences to the need to learn interactions between the two views.
Significance. If the central derivation holds, the work supplies the first explicit scaling law for contrastive representation learning. The risk decomposition and the explicit dependence on M, N, and L_eff γ, together with the demonstration that view interactions alter optimization and noise scaling relative to linear regression, constitute a concrete theoretical advance. The result is stated under clearly articulated modeling assumptions and supplies falsifiable predictions inside that regime; these features make the contribution useful for guiding resource allocation between sketch size, data volume, and optimization compute in contrastive pipelines.
minor comments (3)
- [Abstract / Main Theorem] The notation L_eff γ appears in the abstract and main theorem without an explicit forward reference to its definition; a single sentence introducing the effective horizon before the theorem statement would improve readability.
- [Risk Decomposition] The risk decomposition lists five terms; a short table or displayed equation summarizing the scaling order of each term with respect to M, N, and L_eff γ would make the comparison to linear-regression scaling laws easier to follow.
- [Discussion / Conclusion] A few sentences in the conclusion or discussion section clarifying the regime in which the aligned power-law spectra assumption is expected to be approximately satisfied would help readers assess practical relevance.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the positive recommendation to accept. We appreciate the recognition that the work provides the first explicit scaling law for contrastive representation learning under the stated modeling assumptions, along with the risk decomposition and the comparison to linear regression scalings.
Circularity Check
No significant circularity; derivation is self-contained under stated assumptions
full rationale
The paper explicitly states its modeling assumptions (paired Gaussian latent-variable setup, aligned power-law spectra, contrastive source condition) upfront in the abstract and derives the risk decomposition (irreducible risk, approximation error, GD bias, GD variance, cross term) and scaling law with respect to M, N, and L_eff γ from those assumptions via standard analysis of the sketched linear contrastive model. No step reduces a claimed prediction to a fitted quantity defined by the result itself, nor relies on load-bearing self-citations or ansatzes smuggled via prior work. The central claim is an explicit bound derived inside the stated regime rather than by construction from its own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Paired Gaussian latent-variable setup
- domain assumption Aligned power-law spectra and contrastive source condition
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:1712.00409 , year =
Deep Learning Scaling is Predictable, Empirically , author =. arXiv preprint arXiv:1712.00409 , year =
-
[2]
arXiv preprint arXiv:2001.08361 , year =
Scaling Laws for Neural Language Models , author =. arXiv preprint arXiv:2001.08361 , year =
Pith/arXiv arXiv 2001
-
[3]
arXiv preprint arXiv:2010.14701 , year =
Scaling Laws for Autoregressive Generative Modeling , author =. arXiv preprint arXiv:2010.14701 , year =
Pith/arXiv arXiv 2010
-
[4]
Advances in Neural Information Processing Systems , volume =
Training Compute-Optimal Large Language Models , author =. Advances in Neural Information Processing Systems , volume =
-
[5]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Scaling Vision Transformers , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[6]
Advances in Neural Information Processing Systems , volume =
Scaling Data-Constrained Language Models , author =. Advances in Neural Information Processing Systems , volume =
-
[7]
arXiv preprint arXiv:2102.04074 , year =
Learning Curve Theory , author =. arXiv preprint arXiv:2102.04074 , year =
-
[8]
arXiv preprint arXiv:2004.10802 , year =
A Neural Scaling Law from the Dimension of the Data Manifold , author =. arXiv preprint arXiv:2004.10802 , year =
arXiv 2004
-
[9]
arXiv preprint arXiv:2210.16859 , year =
A Solvable Model of Neural Scaling Laws , author =. arXiv preprint arXiv:2210.16859 , year =
-
[10]
Proceedings of the National Academy of Sciences , volume =
Explaining Neural Scaling Laws , author =. Proceedings of the National Academy of Sciences , volume =
-
[11]
Proceedings of the 41st International Conference on Machine Learning , year =
A Dynamical Model of Neural Scaling Laws , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[12]
Journal of Statistical Mechanics: Theory and Experiment , volume =
Scaling and Renormalization in High-Dimensional Regression , author =. Journal of Statistical Mechanics: Theory and Experiment , volume =. doi:10.1088/1742-5468/ae4bba , year =
-
[13]
Advances in Neural Information Processing Systems , volume =
4+3 Phases of Compute-Optimal Neural Scaling Laws , author =. Advances in Neural Information Processing Systems , volume =
-
[14]
Proceedings of the 41st International Conference on Machine Learning , series =
A Tale of Tails: Model Collapse as a Change of Scaling Laws , author =. Proceedings of the 41st International Conference on Machine Learning , series =
-
[15]
Advances in Neural Information Processing Systems , volume =
Scaling Laws in Linear Regression: Compute, Parameters, and Data , author =. Advances in Neural Information Processing Systems , volume =. doi:10.52202/079017-1937 , year =
-
[16]
Advances in Neural Information Processing Systems , volume =
Improved Scaling Laws in Linear Regression via Data Reuse , author =. Advances in Neural Information Processing Systems , volume =
-
[17]
arXiv preprint arXiv:2605.24316 , url =
From One-Pass SGD to Data Reuse: Mini-Batch Scaling Laws in Sketched Linear Regression , author =. arXiv preprint arXiv:2605.24316 , url =
-
[18]
Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science , pages =
Improved Approximation Algorithms for Large Matrices via Random Projections , author =. Proceedings of the 47th Annual IEEE Symposium on Foundations of Computer Science , pages =
-
[19]
SIAM Review , volume =
Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions , author =. SIAM Review , volume =
-
[20]
Foundations and Trends in Theoretical Computer Science , volume =
Sketching as a Tool for Numerical Linear Algebra , author =. Foundations and Trends in Theoretical Computer Science , volume =
-
[21]
Foundations of Computational Mathematics , volume =
Optimal Rates for the Regularized Least-Squares Algorithm , author =. Foundations of Computational Mathematics , volume =
-
[22]
Bernoulli , volume =
Concentration Inequalities and Moment Bounds for Sample Covariance Operators , author =. Bernoulli , volume =
-
[23]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Dimensionality Reduction by Learning an Invariant Mapping , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
-
[24]
arXiv preprint arXiv:1807.03748 , year =
Representation Learning with Contrastive Predictive Coding , author =. arXiv preprint arXiv:1807.03748 , year =
-
[25]
Proceedings of the 37th International Conference on Machine Learning , pages =
A Simple Framework for Contrastive Learning of Visual Representations , author =. Proceedings of the 37th International Conference on Machine Learning , pages =
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Momentum Contrast for Unsupervised Visual Representation Learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[27]
Advances in Neural Information Processing Systems , volume =
Supervised Contrastive Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[28]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models from Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =
-
[29]
Proceedings of the 38th International Conference on Machine Learning , pages =
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =
-
[30]
Zhai, Xiaohua and Wang, Xiao and Mustafa, Basil and Steiner, Andreas and Keysers, Daniel and Kolesnikov, Alexander and Beyer, Lucas , booktitle =
-
[31]
Proceedings of the 36th International Conference on Machine Learning , pages =
A Theoretical Analysis of Contrastive Unsupervised Representation Learning , author =. Proceedings of the 36th International Conference on Machine Learning , pages =
-
[32]
Proceedings of the 37th International Conference on Machine Learning , pages =
Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere , author =. Proceedings of the 37th International Conference on Machine Learning , pages =
-
[33]
Proceedings of the 32nd International Conference on Algorithmic Learning Theory , pages =
Contrastive Learning, Multi-view Redundancy, and Linear Models , author =. Proceedings of the 32nd International Conference on Algorithmic Learning Theory , pages =
-
[34]
Proceedings of the 38th International Conference on Machine Learning , pages =
Contrastive Learning Inverts the Data Generating Process , author =. Proceedings of the 38th International Conference on Machine Learning , pages =
-
[35]
Advances in Neural Information Processing Systems , volume =
Provable Guarantees for Self-Supervised Deep Learning with Spectral Contrastive Loss , author =. Advances in Neural Information Processing Systems , volume =
-
[36]
arXiv preprint arXiv:2110.02473 , year =
The Power of Contrast for Feature Learning: A Theoretical Analysis , author =. arXiv preprint arXiv:2110.02473 , year =
-
[37]
arXiv preprint arXiv:2605.02116 , year =
Statistical Consistency and Generalization of Contrastive Representation Learning , author =. arXiv preprint arXiv:2605.02116 , year =
-
[38]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Reproducible Scaling Laws for Contrastive Language-Image Learning , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[39]
An Inverse Scaling Law for
Li, Xianhang and Wang, Zeyu and Xie, Cihang , booktitle =. An Inverse Scaling Law for
-
[40]
Advances in Neural Information Processing Systems , volume =
Scaling Laws for Robust Comparison of Open Foundation Language-Vision Models and Datasets , author =. Advances in Neural Information Processing Systems , volume =
-
[41]
Gadre, Samir Yitzhak and Ilharco, Gabriel and Fang, Alex and Hayase, Jonathan and Smyrnis, Georgios and Nguyen, Thao and Marten, Ronen Eldan and Wortsman, Mitchell and Ghosh, Dhruba and Zhang, Jieyu and others , booktitle =
-
[42]
Proceedings of the National Academy of Sciences , volume =
Benign Overfitting in Linear Regression , author =. Proceedings of the National Academy of Sciences , volume =
-
[43]
High-Dimensional Statistics: A Non-Asymptotic Viewpoint , author =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.