SocialPersona: Benchmarking Personalized Profiling and Response with Multimodal Social-Media Context
Pith reviewed 2026-06-26 05:16 UTC · model grok-4.3
The pith
Multimodal models recover broad user interests from social-media timelines but lose accuracy on fine-grained and recent preferences when generating personalized responses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SocialPersona shows that current MLLMs identify broad interest domains from multimodal longitudinal timelines yet suffer measurable drops in accuracy on fine-grained and recent interests, with additional degradation when the resulting profiles are required to produce aligned dialogue responses; text and images supply complementary preference signals.
What carries the argument
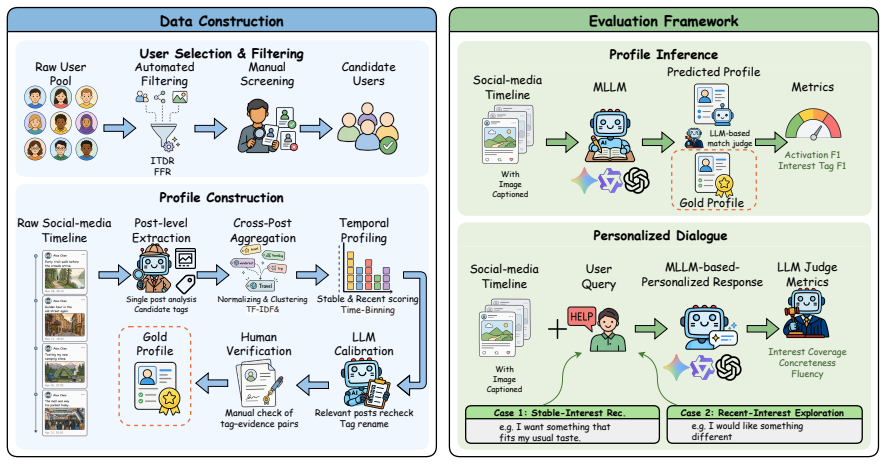
SocialPersona benchmark built from 171 users' multimodal timelines annotated with 2,597 human-verified preference tags across seven domains, supporting two tasks of structured profile construction from context and generation of profile-aligned responses.
If this is right
- Models achieve higher accuracy on broad interest domains than on fine-grained or recent ones.
- Performance declines further when inferred profiles must drive response generation rather than profile construction alone.
- Text and images supply distinct preference signals that together improve recovery.
- Robust cross-modal modeling over long time horizons remains difficult for current systems.
Where Pith is reading between the lines
- The benchmark could be reused to measure whether new architectures improve temporal tracking of preference shifts.
- It highlights a possible need for explicit mechanisms that separate stable traits from transient signals when building user models.
- Similar evaluation setups might apply to other public multimodal traces such as photo streams or forum histories.
Load-bearing premise
The 2,597 human-verified preference tags accurately and comprehensively capture the stable and recent interests shown in the 171 users' social-media timelines.
What would settle it
A model that matches or exceeds human accuracy on fine-grained and recent-interest tags while preserving that accuracy when its inferred profiles are used to generate dialogue responses would refute the reported performance gaps.
Figures

read the original abstract
Personalized language-model assistants are often evaluated through a memory lens: can a model recall preferences users have explicitly stated in dialogue? More comprehensive personalization demands a harder capability -- inferring what users care about from the multimodal traces they naturally leave behind. We introduce SocialPersona, a benchmark for evaluating whether multimodal large language models (MLLMs) can recover revealed preferences from longitudinal social-media timelines and use them in dialogue. Built from longitudinal timelines of 171 everyday, non-promotional social-media users, SocialPersona contains text, images, timestamps, and 2,597 human-verified preference tags across seven interest domains, separating stable interests from recent interests. It supports two tasks: constructing structured user profiles from multimodal context and generating responses aligned with inferred profiles. Experiments with proprietary and open-weight MLLMs show that models can identify broad interest domains, yet their performance drops on fine-grained and recent interests and degrades further when inferred profiles must be used to personalize dialogue. Together with evidence that text and images provide complementary preference signals, these results indicate that robust cross-modal, long-horizon user modeling remains a key challenge, and that SocialPersona can help measure and advance progress toward assistants that infer and act on revealed preferences.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SocialPersona, a benchmark built from longitudinal multimodal timelines of 171 everyday social-media users containing text, images, timestamps, and 2,597 human-verified preference tags across seven domains (separating stable from recent interests). It defines two tasks—constructing structured user profiles from multimodal context and generating dialogue responses aligned with inferred profiles—and reports that MLLMs identify broad domains reasonably well but show clear drops on fine-grained/recent interests, with further degradation when inferred profiles are used for personalization; text and images are shown to provide complementary signals.
Significance. If the ground-truth tags and timeline coverage are reliable, SocialPersona supplies a concrete, falsifiable testbed for cross-modal, long-horizon preference inference that goes beyond explicit memory recall. The separation of stable versus recent interests and the two-stage evaluation (profile construction then response generation) are useful design choices that could help the community quantify progress on revealed-preference modeling.
major comments (2)
- [Dataset Construction] The central empirical claims rest on the claim that the 2,597 human-verified tags accurately and comprehensively reflect the stable and recent interests latent in the 171 multimodal timelines; the manuscript must supply a detailed account of the verification protocol, inter-annotator agreement, coverage statistics, and any filtering criteria (e.g., §3 or Dataset Construction) before the reported performance drops can be interpreted as evidence of model limitations rather than annotation artifacts.
- [Experiments] The experiments section reports performance degradation when moving from broad domains to fine-grained/recent interests and from profile construction to dialogue generation, yet provides no statistical significance tests, confidence intervals, or error analysis that would establish these drops are robust rather than artifacts of prompt sensitivity or small per-user sample sizes.
minor comments (2)
- [Experiments] Clarify the exact split between proprietary and open-weight models evaluated and report per-model numbers rather than aggregated trends only.
- [Discussion] Add a limitations paragraph discussing potential demographic or platform biases in the 171-user sample and the seven interest domains.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive suggestions. We address each of the major comments below, and we plan to incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Dataset Construction] The central empirical claims rest on the claim that the 2,597 human-verified tags accurately and comprehensively reflect the stable and recent interests latent in the 171 multimodal timelines; the manuscript must supply a detailed account of the verification protocol, inter-annotator agreement, coverage statistics, and any filtering criteria (e.g., §3 or Dataset Construction) before the reported performance drops can be interpreted as evidence of model limitations rather than annotation artifacts.
Authors: We agree that additional details on the dataset construction are essential for interpreting the results. The current manuscript provides an overview of the human verification process, but we acknowledge it lacks the requested granularity. In the revised version, we will expand the Dataset Construction section (likely §3) to include: (1) the full verification protocol, including annotator instructions and guidelines for identifying stable vs. recent interests; (2) inter-annotator agreement statistics, such as percentage agreement and Cohen's kappa where applicable; (3) coverage statistics, e.g., average tags per user, distribution across domains, and timeline length coverage; and (4) any filtering criteria applied to select users and tags. This will help demonstrate that the tags reliably capture the latent interests. revision: yes
-
Referee: [Experiments] The experiments section reports performance degradation when moving from broad domains to fine-grained/recent interests and from profile construction to dialogue generation, yet provides no statistical significance tests, confidence intervals, or error analysis that would establish these drops are robust rather than artifacts of prompt sensitivity or small per-user sample sizes.
Authors: We concur that statistical rigor would bolster the experimental claims. We will revise the Experiments section to include: bootstrap-derived confidence intervals for all reported metrics; statistical significance tests (e.g., paired t-tests or McNemar's test) for the performance differences between broad vs. fine-grained, stable vs. recent, and profile vs. response generation tasks; and an expanded error analysis categorizing model failures by interest granularity, recency, and input modality. To address prompt sensitivity, we will report results from at least two distinct prompt templates. While the per-user sample size is constrained by the 171 timelines, we will clarify that metrics are aggregated across users with appropriate variance estimates. revision: yes
Circularity Check
No significant circularity
full rationale
This is a benchmark construction paper whose central claims consist of empirical observations on MLLM performance across two tasks (profile construction and personalized response generation). No equations, fitted parameters, predictions, or derivations appear in the provided text; the 2,597 human-verified tags function as external ground truth rather than quantities derived from the models or from prior self-citations. The reported performance drops on fine-grained/recent interests and cross-modal complementarity are direct measurements, not reductions to the paper's own inputs. No load-bearing self-citation chains or ansatzes are present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2505.23065
SNS-Bench-VL: Benchmarking multimodal large language models in social networking services. arXiv preprint arXiv:2505.23065. Withdrawn. Zhicheng He, Weiwen Liu, Wei Guo, Jiarui Qin, Yingxue Zhang, Yaochen Hu, and Ruiming Tang
-
[2]
A survey on user behavior modeling in rec- ommender systems. InProceedings of the Thirty- Second International Joint Conference on Artificial Intelligence, pages 6656–6664. Zhaopei Huang, Qifeng Dai, Guozheng Wu, Xiaopeng Wu, Xubin Li, Tiezheng Ge, Wenxuan Wang, and Qin Jin. 2026. Mem-pal: Towards memory-based personalized dialogue assistants for long-ter...
-
[3]
Fakeddit: A new multimodal benchmark dataset for fine-grained fake news detection. InPro- ceedings of the Twelfth Language Resources and Evaluation Conference, pages 6149–6157, Marseille, France. European Language Resources Association. Dan Saattrup Nielsen and Ryan McConville. 2022. Mu- MiN: A large-scale multilingual multimodal fact- checked misinformat...
-
[4]
Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani
ALPBench: A benchmark for attribution-level long-term personal behavior understanding.Preprint, arXiv:2602.03056. Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2023. LaMP: When large lan- guage models meet personalization.arXiv preprint arXiv:2304.11406. Chhavi Sharma, Deepesh Bhageria, William Scott, Srinivas PYKL, Amitava Das, Ta...
-
[5]
sports_outdoor: sports participation, exercise, fitness routines, hiking, running , cycling, camping, outdoor recreation, and active-use sports gear
-
[6]
Exclude gaming unless explicitly about games
entertainment: movies, TV, music, concerts, books/comics/anime, celebrities, and media consumption. Exclude gaming unless explicitly about games
-
[7]
gaming: video games, gaming hardware/ platforms, esports, game fandom, game streaming, and playing/watching games
-
[8]
food_drink: cooking, meals, restaurants, cafes, recipes, coffee, tea, cocktails, and other food/drink consumption or creation
-
[9]
travel_city_exploration: trips, flights, hotels, cities, neighborhoods, sightseeing, landmarks, museums, and city walks/ exploration
-
[10]
Do not assign this domain for a scenic image alone unless the post clearly signals photographing, editing , or creating
photography_creation: taking photos, cameras, lenses, editing, visual creation, making images/videos/artworks. Do not assign this domain for a scenic image alone unless the post clearly signals photographing, editing , or creating
-
[11]
schema_version
pets: pets, pet ownership, pet care, dogs, cats, training, grooming, adoption, veterinary care, pet products, and spending time with companion animals. Exclude wildlife or general nature content unless the post is clearly about personal pets or pet care. General rules: - Use only explicit evidence from the provided post package and any attached image inpu...
-
[12]
Return true only when both labels express the same core interest theme
-
[13]
A wording rewrite, synonym, parent-child phrasing, or broad-vs-specific phrasing can be true when both labels clearly point to the same underlying user-interest cluster in this domain
-
[14]
hiking " vs
Examples that should usually be true: "hiking " vs "outdoor recreation", "coffee" vs " coffee culture", "anime" vs "anime fandom"
-
[15]
basketball
Examples that should usually be false: sibling interests that share only the same domain, such as "basketball" vs "camping", or labels with clearly different focus
-
[16]
Return strict JSON only
Be conservative. Return strict JSON only. Profile Matching Judge — User Prompt Task ID: {task_id} Domain: {domain} Domain definition: {domain_definition} Gold anchor label: {gold_label} Predicted anchor label: {pred_label} Question: Do these two labels describe the same core user interest in this domain? Return strict JSON only. A.4 Dialogue Generation Pr...
-
[17]
Could you recommend one option for me?
I want something that fits my usual taste. Could you recommend one option for me?
-
[18]
Could you suggest one thing I’d probably en- joy based on what I usually like?
-
[19]
What’s one good option?
I’m looking for a recommendation that feels very me. What’s one good option?
-
[20]
Choose one option that fits what I’ve liked for a while
-
[21]
What should I try?
I want a safe choice that matches my usual preferences. What should I try?
-
[22]
Recommend one activity or item that seems close to my regular taste
-
[23]
Based on what I tend to enjoy, what is one practical suggestion?
-
[24]
I’m not trying to branch out today; give me one recommendation that fits my normal style
-
[25]
What’s one personalized option that would likely suit my everyday interests?
-
[26]
Recent-interest exploration requests
Give me one recommendation grounded in what I’ve consistently liked before. Recent-interest exploration requests
-
[27]
Any suggestion?
I want to try something a bit new, but still something that feels like me. Any suggestion?
-
[28]
Could you recommend one fresh option that connects to what I’ve been into lately?
-
[29]
What’s one suggestion that still matches my taste?
I’m open to exploring something new. What’s one suggestion that still matches my taste?
-
[30]
Choose one option that builds on what has caught my attention recently, without feeling random
-
[31]
What should I try?
I’d like a small change from my usual choices. What should I try?
-
[32]
Recommend one new-ish activity or item that fits what I seem to be into right now
-
[33]
What’s one recommendation that reflects what I’ve been paying attention to lately?
-
[34]
Any idea?
I want something slightly outside my routine, but not totally unfamiliar. Any idea?
-
[35]
Suggest one option that feels current for me while still matching my usual taste
-
[36]
A.6 Dialogue Evaluation Judge Prompt Dialogue Evaluation Judge — System Prompt You are an expert judge for social-media- grounded personalized dialogue
Give me one practical recommendation that feels timely for me, not just my old favorites. A.6 Dialogue Evaluation Judge Prompt Dialogue Evaluation Judge — System Prompt You are an expert judge for social-media- grounded personalized dialogue. You will be given two independent recommendation cases, the user’s gold profile, and the model responses. The user...
-
[37]
Reward semantic fit to the correct target interests, not exact wording similarity
-
[38]
For stable_recommendation, reward use of stable interests
-
[39]
For recent_interest_exploration, reward use of recent interests while keeping the suggestion compatible with stable interests
-
[40]
Reward concrete, actionable, natural recommendations
-
[41]
Penalize generic filler, unsupported assumptions, demographic guesses, and benchmark-like language
-
[42]
The two cases are independent; do not require dialogue continuity across them
-
[43]
try something you enjoy
Return strict JSON only. Score each dimension from 0 to 5 using the rubrics below. Dialogue Evaluation Judge — Rubrics RUBRIC: interest_coverage Whether the response engages the correct target interests (stable for stable_recommendation , recent for recent_interest_exploration) in this scenario. - 0: No target interest is engaged; response is generic or i...
-
[44]
Only infer interests that are supported by observable evidence in the posts
-
[45]
Do not infer demographic attributes, personality traits, occupation, gender, age , race, religion, political identity, health status, or other sensitive personal attributes
-
[46]
Distinguish recurring interests from one-off mentions
-
[47]
Use both text and image captions as evidence
-
[48]
Preserve post IDs as evidence anchors
-
[49]
For example, one photo of food does not mean the user is a food enthusiast unless there are repeated signals
Do not over-generalize. For example, one photo of food does not mean the user is a food enthusiast unless there are repeated signals
-
[50]
Return valid JSON only
If the evidence is weak or incidental, mark it as weak. Return valid JSON only. Hierarchical — Global Aggregation — System Prompt You are aggregating chunk-level summaries into a final user interest profile. You will receive summaries from multiple chronological chunks of the same user’s social-media timeline. Your task is to merge redundant interests, id...
-
[51]
home cooking
Merge semantically equivalent interests. For example, "home cooking", "cooking meals", and "homemade food" should be normalized if they refer to the same core interest
-
[52]
Stable interests should be supported across multiple posts or multiple time periods
-
[53]
Recent interests should be supported by posts concentrated in the most recent part of the timeline, even if they are not stable
-
[54]
Interests should only be included when supported by clear, repeated evidence; sparse or ambiguous signals should not be promoted to interests
-
[56]
Do not create interests that are not supported by the provided chunk summaries
-
[57]
Preserve evidence post IDs whenever possible
-
[58]
A.9 Extractive Profile Construction Prompts The extractive–abstractive method proceeds in two stages
Output valid JSON only. A.9 Extractive Profile Construction Prompts The extractive–abstractive method proceeds in two stages. First, the LLM receives the full user time- line and is prompted to select up to K represen- tative posts per domain. The selection criteria in- clude relevance, specificity (concrete interest sig- nals rather than vague topics), r...
-
[59]
Select posts only when they provide concrete evidence for the domain
-
[60]
Prefer posts that show recurring interests, strong visual/textual evidence, or recent concentrated activity
-
[61]
Avoid selecting posts that only contain incidental, ambiguous, or very weak signals
-
[62]
Use both text and image captions
-
[63]
Do not infer sensitive attributes or demographics
-
[64]
Only select representative posts
Do not summarize the profile yet. Only select representative posts
-
[65]
Each domain can have at most the configured K selected posts
-
[66]
Return valid JSON only
If a domain has insufficient evidence, return an empty list for that domain. Return valid JSON only. Extractive — Abstractive Synthesis — System Prompt You are generating an abstractive user interest profile from selected representative social-media posts. You will receive a small set of representative posts selected for each domain. Each post may contain...
-
[67]
Use only the selected posts as evidence
-
[68]
Do not infer interests that are not supported by selected posts
-
[69]
Separate stable interests from recent interests
-
[70]
Stable interests should be supported by multiple posts or recurring evidence
-
[71]
Recent interests should be supported by posts concentrated in the most recent period
-
[72]
Only include interests that are clearly supported; do not include interests when evidence is limited or ambiguous
-
[73]
Do not infer sensitive attributes or demographic information
-
[74]
Preserve supporting post IDs for every interest
-
[75]
A.10 Calibration and Gold Rewrite Prompts Calibration — Evidence-First Extraction — System Prompt You are performing evidence-first interest summarization for one domain
Output valid JSON only. A.10 Calibration and Gold Rewrite Prompts Calibration — Evidence-First Extraction — System Prompt You are performing evidence-first interest summarization for one domain. Goal: - Produce natural-language interest labels and short descriptions suitable for downstream LLM personalization benchmarking. - Use canonical tags only as evi...
-
[76]
Preserve natural-language candidate interests from pass1 whenever evidence supports them
-
[77]
Use algorithmic statistics only to place interests into stable / recent / weak buckets
-
[78]
Keep canonical_tags as anchors, but do not use raw canonical ids in labels or summaries
-
[79]
Write domain_summary as 2-4 natural sentences suitable for downstream personalization benchmarking. Hard constraints: - Every interest item must contain both label ( natural language) and canonical_tags (from provided clusters only). - domain_summary should mention only labels that appear in structured fields. - Exclude family roles, career identity, and ...
-
[80]
Dialogue setting: 7–8 responses from each of the four settings (Timeline-conditioned,Di- rect,Hierarchical,Extractive–abstractive), ensuring representation of both raw-timeline and profile-conditioned generation paths
-
[81]
User intent: 15 stable-interest recommenda- tion responses and 15 recent-interest explo- ration responses
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.