Mask to Concept: Auto-Promptable SAM3 via Efficient Test-Time Concept Embedding Search for Few-Shot Annotation
Pith reviewed 2026-07-01 06:33 UTC · model grok-4.3
The pith
A learnable concept embedding optimized inside frozen SAM3 enables auto-prompted medical image segmentation from few labeled examples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
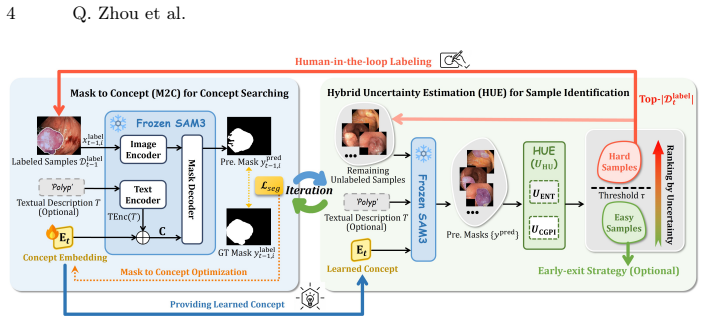
Mask to Concept (M2C) adapts SAM3 for few-shot medical annotation by initializing a learnable concept embedding that prompts the frozen model, then updates the embedding through backpropagation of the segmentation loss computed against the provided masks. A Hybrid Uncertainty Estimation module computes prediction entropy and inconsistency with box prompts to select samples for human correction, feeding the refined masks back to further optimize the embedding.
What carries the argument
The learnable concept embedding updated at test time by minimizing segmentation error gradients to generate prompts for the frozen SAM3 model.
If this is right
- The method reaches state-of-the-art accuracy on medical few-shot segmentation tasks.
- Annotation requires fewer human interventions due to the active learning loop with uncertainty estimates.
- No external feature matchers or auxiliary networks are needed, keeping the approach lightweight.
- The framework supports continuous improvement as more corrected masks become available.
Where Pith is reading between the lines
- Similar test-time embedding search could adapt other frozen foundation models to new domains without retraining.
- The approach might scale to video or 3D medical data if the embedding optimization generalizes across dimensions.
- Reducing the number of initial labeled examples below current few-shot levels could be tested by strengthening the uncertainty feedback loop.
Load-bearing premise
The gradients from segmentation errors on a small set of medical images are sufficient to discover visual concepts that transfer across different images in the same domain.
What would settle it
If optimizing the concept embedding on five labeled CT scans fails to produce accurate segmentations on a held-out set of similar scans from the same hospital, the claim would be falsified.
Figures
read the original abstract
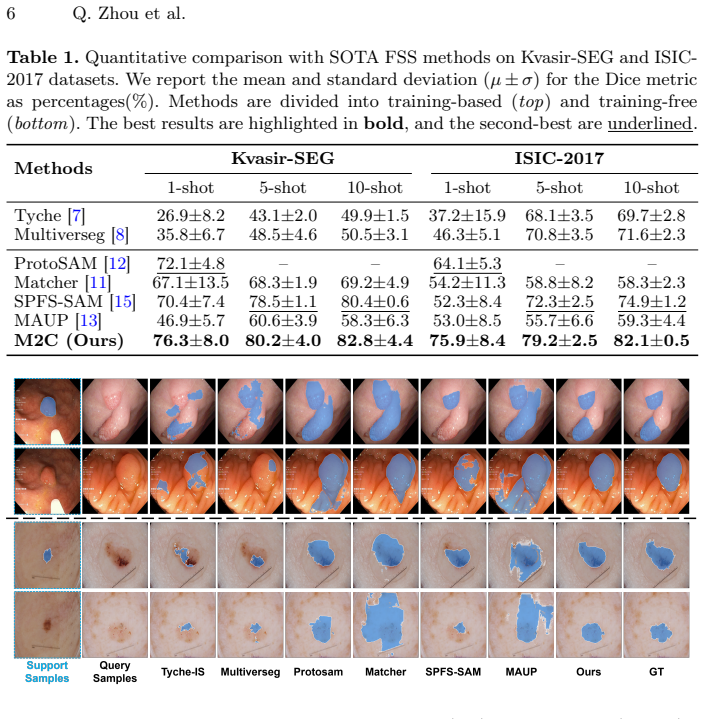
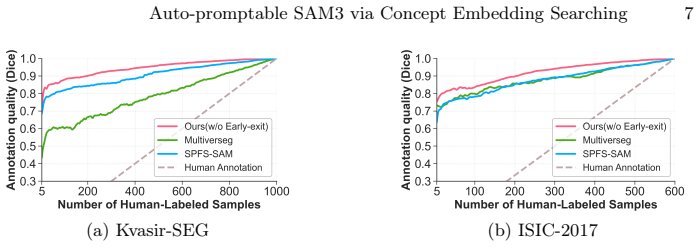
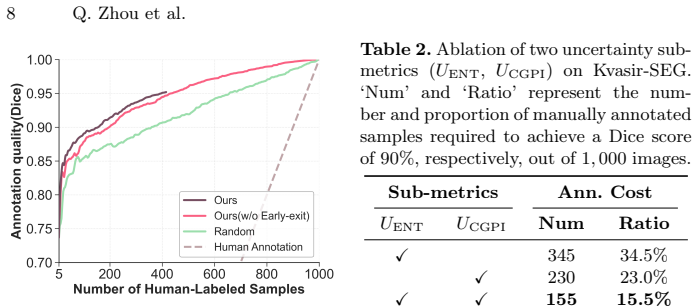
Transforming foundation segmentation models from human-prompted tools into auto-promptable annotators is critical for scalable medical data annotation. Current methods commonly depend on external feature matchers or auxiliary networks to automate geometric prompting, but introducing architectural overhead and limiting performance scalability. Although SAM3 natively supports concept segmentation via reusable text prompts, its direct use in medical imaging is hindered by a lack of fine-grained clinical knowledge and the ambiguity of human-written descriptions. In this work, we propose Mask to Concept (M2C), an efficient framework that adapts SAM3 for medical few-shot annotation without external modules, parameter retraining, or manual text engineering. Using only a few labeled images, M2C enables SAM3 to automatically search for transferable visual concepts entirely within its frozen architecture: it initializes a learnable concept embedding, uses it to prompt segmentation, and updates the embedding by gradients of minimizing the concept segmentation error. We further introduce a Hybrid Uncertainty Estimation (HUE) module that calculates the prediction entropy and maps concept predictions back to the box prompts, measuring concept-geometry prompting inconsistency. Highly uncertain samples are flagged actively for human correction, and the corrected masks are then fed back to M2C to continuously search for more precise concept embeddings, forming a self-enhancing annotation loop with minimal expert effort. Experiments on medical segmentation benchmarks show that our method achieves SOTA few-shot segmentation performance and outstanding annotation efficiency, offering a practical and efficient pathway toward scalable medical image labeling. Codes are at https://github.com/Huster-Hq/M2C.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Mask to Concept (M2C), a framework that adapts the frozen SAM3 model for few-shot medical image annotation by initializing a learnable concept embedding, prompting segmentation with it, and updating the embedding solely via gradients of segmentation error on a small number of labeled images. No external modules, retraining, or manual text prompts are used. A Hybrid Uncertainty Estimation (HUE) module computes prediction entropy and maps concept outputs back to box prompts to detect inconsistency; high-uncertainty cases are flagged for human correction whose masks are fed back into the embedding search, forming an iterative loop. The authors claim this yields SOTA few-shot segmentation performance and high annotation efficiency on medical benchmarks.
Significance. If the empirical results hold, the approach could enable practical, low-effort adaptation of foundation segmentation models to medical domains without architectural changes or large-scale retraining, supporting scalable annotation pipelines. The public code release at https://github.com/Huster-Hq/M2C is a clear strength that aids reproducibility.
major comments (2)
- [Abstract] Abstract: the central claim of 'SOTA few-shot segmentation performance' is asserted without any metrics, baselines, dataset names, ablation tables, or quantitative results, so the soundness of the empirical contribution cannot be assessed from the provided text.
- [Abstract] Method description (abstract): the single learnable concept embedding is optimized exclusively by back-propagating segmentation loss on the support-set masks; nothing in the described procedure (gradient search or HUE inconsistency check) supplies an independent mechanism to ensure the embedding encodes clinically meaningful, transferable structures rather than support-set-specific textures or artifacts, which is load-bearing for generalization claims given the natural-to-medical domain gap.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript where appropriate to strengthen clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'SOTA few-shot segmentation performance' is asserted without any metrics, baselines, dataset names, ablation tables, or quantitative results, so the soundness of the empirical contribution cannot be assessed from the provided text.
Authors: We agree that the abstract would benefit from quantitative anchors to support the SOTA claim. The full manuscript reports detailed results including Dice/IoU metrics, multiple baselines, dataset names, and ablations. We will revise the abstract to incorporate key numerical highlights and dataset references while remaining within length limits. revision: yes
-
Referee: [Abstract] Method description (abstract): the single learnable concept embedding is optimized exclusively by back-propagating segmentation loss on the support-set masks; nothing in the described procedure (gradient search or HUE inconsistency check) supplies an independent mechanism to ensure the embedding encodes clinically meaningful, transferable structures rather than support-set-specific textures or artifacts, which is load-bearing for generalization claims given the natural-to-medical domain gap.
Authors: The optimization occurs directly on target-domain support masks, and the HUE module supplies an auxiliary consistency signal by mapping concept outputs back to box prompts and quantifying entropy-based disagreement; this loop is iterated with human-corrected masks. Transferability is validated empirically on held-out test images from the same medical benchmarks rather than through an external supervisory signal. We will expand the abstract's method summary to better emphasize the role of HUE-driven refinement in promoting robustness, while the full paper contains supporting ablations. revision: partial
Circularity Check
No circularity; method is explicit test-time optimization on external labels
full rationale
The paper presents a standard gradient-based optimization loop that fits a single concept embedding to minimize segmentation loss on a small set of provided labeled masks, then applies the resulting embedding to new images. This is a direct fitting procedure with no equations that reduce the claimed output to the input by construction. The HUE module derives uncertainty directly from model entropy and prompt inconsistency without reference to fitted targets. No self-citations serve as load-bearing uniqueness theorems, no ansatzes are smuggled, and no predictions are statistically forced from the same data used for fitting. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Embracing imperfect datasets: A review of deep learning solutions for medical image segmentation.Medical image analysis, 63:101693, 2020
Nima Tajbakhsh, Laura Jeyaseelan, Qian Li, Jeffrey N Chiang, Zhihao Wu, and Xiaowei Ding. Embracing imperfect datasets: A review of deep learning solutions for medical image segmentation.Medical image analysis, 63:101693, 2020
2020
-
[2]
Sali:Short-termalignmentandlong-terminteractionnetworkforcolonoscopyvideo polyp segmentation
Qiang Hu, Zhenyu Yi, Ying Zhou, Fang Peng, Mei Liu, Qiang Li, and Zhiwei Wang. Sali:Short-termalignmentandlong-terminteractionnetworkforcolonoscopyvideo polyp segmentation. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 531–541. Springer, 2024
2024
-
[3]
Segment anything
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C Berg, Wan-Yen Lo, et al. Segment anything. InProceedings of the IEEE/CVF international conference on computer vision, pages 4015–4026, 2023
2023
-
[4]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Segment anything in medical images.Nature Communications, 15(1):654, 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature Communications, 15(1):654, 2024
2024
-
[6]
Universeg: Universal medical image segmentation
Victor Ion Butoi, Jose Javier Gonzalez Ortiz, Tianyu Ma, Mert R Sabuncu, John Guttag, and Adrian V Dalca. Universeg: Universal medical image segmentation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 21438–21451, 2023
2023
-
[7]
Tyche: Stochastic in-context learning for medical image segmentation
Marianne Rakic, Hallee E Wong, Jose Javier Gonzalez Ortiz, Beth A Cimini, John V Guttag, and Adrian V Dalca. Tyche: Stochastic in-context learning for medical image segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11159–11173, 2024. 10 Q. Zhou et al
2024
-
[8]
Multiverseg: scalable interactive segmentation of biomedical imaging datasets with in-context guidance
Hallee E Wong, Jose Javier Gonzalez Ortiz, John Guttag, and Adrian V Dalca. Multiverseg: scalable interactive segmentation of biomedical imaging datasets with in-context guidance. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20966–20980, 2025
2025
-
[9]
Few-shot medical image segmentation via generating multiple representative descriptors.IEEE Transactions on Medical Imaging, 43(6):2202–2214, 2024
Ziming Cheng, Shidong Wang, Tong Xin, Tao Zhou, Haofeng Zhang, and Ling Shao. Few-shot medical image segmentation via generating multiple representative descriptors.IEEE Transactions on Medical Imaging, 43(6):2202–2214, 2024
2024
-
[10]
Samix: Reinforcing sam2 with semantic adapter and reference selecting policy for mix-supervised segmentation
QiangHu,JiajieWei,ZhenyuYi,ZhifenYan,YingjieGuo,HongkuanShi,Ge-Peng Ji, Qiang Li, and Zhiwei Wang. Samix: Reinforcing sam2 with semantic adapter and reference selecting policy for mix-supervised segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17948–17958, 2026
2026
-
[11]
arXiv preprint arXiv:2305.13310 (2023)
Yang Liu, Muzhi Zhu, Hengtao Li, Hao Chen, Xinlong Wang, and Chunhua Shen. Matcher: Segment anything with one shot using all-purpose feature matching. arXiv preprint arXiv:2305.13310, 2023
-
[12]
Lev Ayzenberg, Raja Giryes, and Hayit Greenspan. Protosam: One-shot medical image segmentation with foundational models.arXiv preprint arXiv:2407.07042, 2024
-
[13]
Maup: Training-free multi-center adaptive uncertainty-aware prompting for cross-domain few-shot medical image segmen- tation
Yazhou Zhu and Haofeng Zhang. Maup: Training-free multi-center adaptive uncertainty-aware prompting for cross-domain few-shot medical image segmen- tation. InInternational Conference on Medical Image Computing and Computer- Assisted Intervention, pages 326–336. Springer, 2025
2025
-
[14]
arXiv preprint arXiv:2305.03048 (2023)
Renrui Zhang, Zhengkai Jiang, Ziyu Guo, Shilin Yan, Junting Pan, Xianzheng Ma, Hao Dong, Peng Gao, and Hongsheng Li. Personalize segment anything model with one shot.arXiv preprint arXiv:2305.03048, 2023
-
[15]
Self-prompting large vision models for few-shot medical image segmentation
Qi Wu, Yuyao Zhang, and Marawan Elbatel. Self-prompting large vision models for few-shot medical image segmentation. InMICCAI workshop on domain adaptation and representation transfer, pages 156–167. Springer, 2023
2023
-
[16]
Synpo: Boosting training-free few-shot medical segmentation via high-quality negative prompts
Yufei Liu, Haoke Xiao, Jiaxing Chai, Yongcun Zhang, Rong Wang, Zijie Meng, and Zhiming Luo. Synpo: Boosting training-free few-shot medical segmentation via high-quality negative prompts. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 594–603. Springer, 2025
2025
-
[17]
First-framesupervisedvideopolyp segmentation via propagative and semantic dual-teacher network
QiangHu,MeiLiu,QiangLi,andZhiweiWang. First-framesupervisedvideopolyp segmentation via propagative and semantic dual-teacher network. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[18]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, An- drew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision, 130(9):2337–2348, 2022
2022
-
[20]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Kvasir-seg: A segmented polyp dataset
Debesh Jha, Pia H Smedsrud, Michael A Riegler, Pål Halvorsen, Thomas de Lange, Dag Johansen, and Håvard D Johansen. Kvasir-seg: A segmented polyp dataset. In MultiMedia Modeling: 26th International Conference, MMM 2020, Daejeon, South Korea, January 5–8, 2020, Proceedings, Part II 26, pages 451–462. Springer, 2020. Auto-promptable SAM3 via Concept Embeddi...
2020
-
[22]
Noel CF Codella, David Gutman, M Emre Celebi, Brian Helba, Michael A Marchetti, Stephen W Dusza, Aadi Kalloo, Konstantinos Liopyris, Nabin Mishra, Harald Kittler, et al. Skin lesion analysis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic)...
2017
-
[23]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.