Do Image Editing Models Understand Lighting?
Pith reviewed 2026-06-26 05:27 UTC · model grok-4.3
The pith
Image editing models largely reproduce real lighting physics but err more in low-light regions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
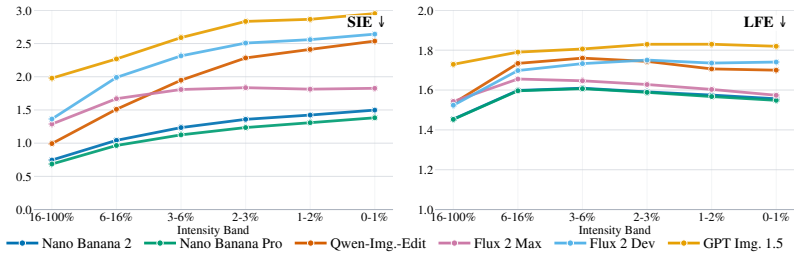
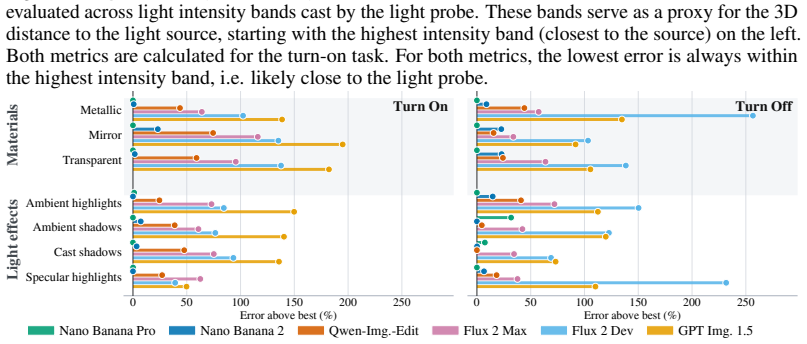
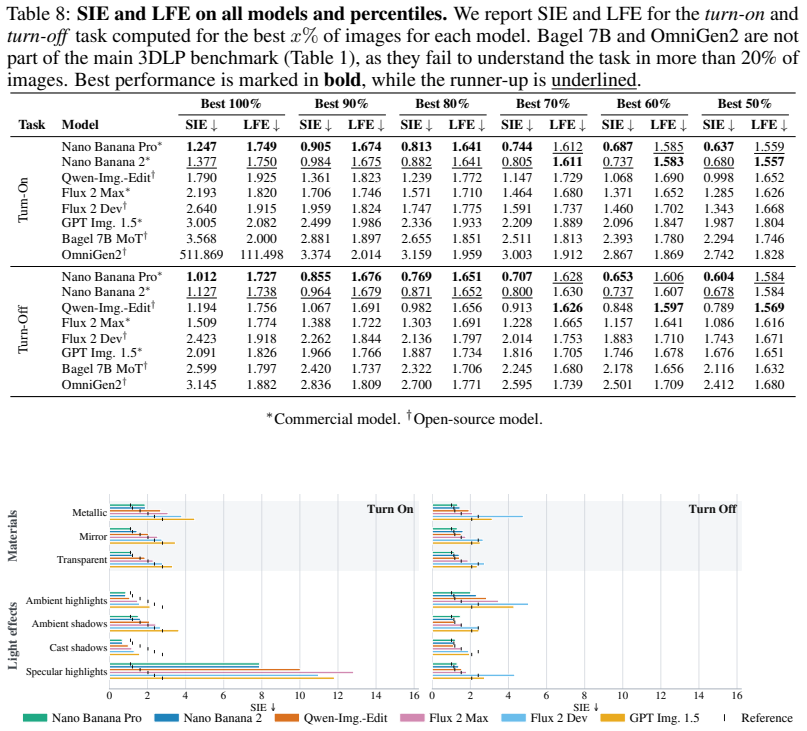
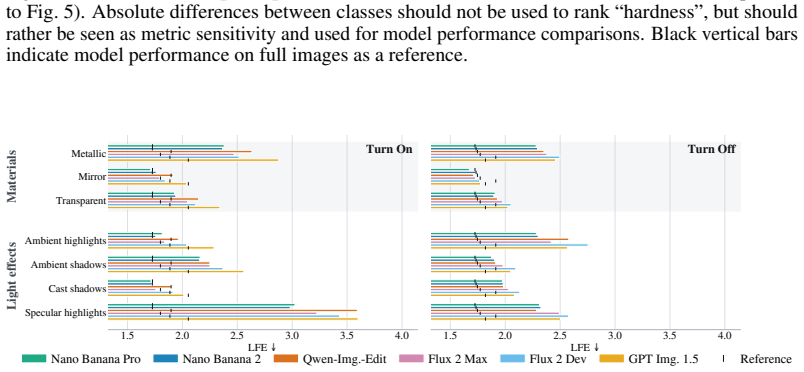
Using the 3D-anchored Light Probe benchmark built from 1K real-world HDR pairs with annotated regions, the evaluation demonstrates that the strongest image editing models produce edits that align closely with measured real-world light transport, although performance varies across models and remains weaker in regions receiving less light from the probe; vision-language models prove unsuitable for this pixel-level task.
What carries the argument
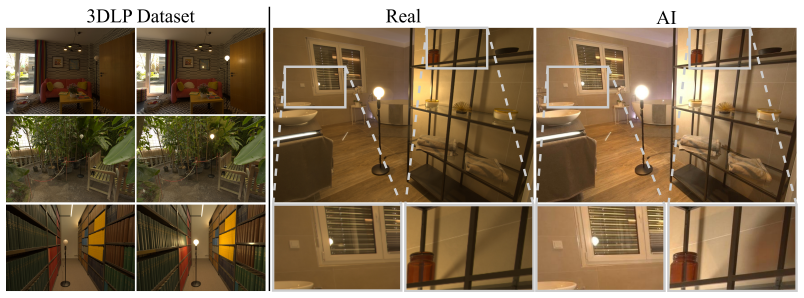
The 3D-anchored Light Probe (3DLP) benchmark, consisting of physically captured on/off light-probe image pairs and region annotations, together with two new scores that isolate lighting transport accuracy from other generative effects.
If this is right
- Best-performing models exhibit high consistency with physical light transport on specular highlights.
- All tested models produce more errors in image regions that receive less light from the probe.
- Model performance differences are slightly smaller on specular surfaces than on other annotated regions.
- Vision-language models cannot substitute for pixel-level light-transport evaluation on this task.
Where Pith is reading between the lines
- The benchmark could be extended to test editing models on outdoor scenes or multiple simultaneous light sources.
- Training pipelines might incorporate explicit supervision from similar on/off probe pairs to reduce low-light errors.
- The observed low-light bias suggests current models rely on learned appearance priors rather than explicit transport simulation.
Load-bearing premise
The two new scores successfully separate lighting transport accuracy from confounding effects such as white-balance shifts, and the captured pairs contain no uncontrolled variables besides the light-probe state.
What would settle it
Independent re-measurement of the released image pairs with calibrated light meters that finds no systematic increase in error for low-light regions after applying the two scores.
Figures




















read the original abstract
While recent advancements in generative image editing models have achieved stunning visual fidelity, it remains an open question whether these systems possess an intrinsic knowledge of real-world lighting. Existing benchmarks typically evaluate high-level plausibility of perceptual light transport on curated internet imagery, using VLMs or human judgement, or they rely on synthetically generated datasets. In this work, we introduce the 3D-anchored Light Probe (3DLP) benchmark, for which we have captured a new high-fidelity HDR dataset of real-world lighting changes. The dataset consists of 1K image pairs of diverse indoor scenery in which light probes are physically turned on and off. To allow for a granular performance analysis, we annotated specific image regions such as cast shadows or metallic surfaces. With this data, we evaluate a range of state-of-the-art image editing models by measuring how well their light probe edits align with reality. The evaluation uses two new scores to compensate for AI-generated photographic effects, such as adjusted white balance. Our results show that the overall performance of models differs considerably, with differences slightly less pronounced for specular highlights. The best image editing models are remarkably consistent with real-world physics, however, they still leave room for improvement. We observe that image regions that receive less light from the light probe are more prone to errors for all models. Furthermore, building on their success in evaluating macroscopic lighting plausibility, we test VLMs on our task but find that they are unsuitable for pixel-level light transport analysis. We will make the benchmark, together with the real-world dataset, publicly available to encourage future research on this topic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the 3DLP benchmark based on a newly captured high-fidelity HDR dataset of 1K real-world indoor image pairs in which light probes are physically toggled on and off. It evaluates a range of state-of-the-art image editing models by measuring alignment of their light-probe edits with the captured ground truth, using two newly proposed scores intended to compensate for AI-generated photographic effects such as white-balance shifts. The central claims are that the best models are remarkably consistent with real-world physics (with somewhat smaller differences on specular highlights), that errors are more frequent in regions receiving less light from the probe, and that VLMs are unsuitable for pixel-level light-transport analysis. The benchmark and dataset are to be released publicly.
Significance. If the evaluation protocol and new scores are shown to isolate lighting transport, the work supplies a rare real-world, physics-grounded benchmark that moves beyond synthetic data or VLM/human perceptual judgments. The public release of the 1K annotated pairs and the observation of systematic low-light errors would be useful contributions to the field.
major comments (2)
- [Evaluation section] Evaluation section (around the definition of the two new scores): the manuscript provides no ablation, correlation analysis, or controlled experiment demonstrating that the scores successfully remove confounds such as model-induced white-balance or exposure shifts; without this, the reported consistency numbers and the low-light error pattern cannot be attributed solely to lighting transport accuracy.
- [Section 3] Dataset collection protocol (Section 3): the claim that the 1K pairs differ solely in light-probe state is load-bearing for all quantitative results, yet the text does not report explicit controls or measurements for camera stability, ambient light drift, or other capture variables between the on/off pairs.
minor comments (2)
- The exact mathematical definitions of the two new scores should be moved from any appendix into the main text with a short worked example on one image pair.
- Figure captions for the annotated regions (cast shadows, metallic surfaces) should explicitly state the annotation protocol and inter-annotator agreement.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address each of the major comments below.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section (around the definition of the two new scores): the manuscript provides no ablation, correlation analysis, or controlled experiment demonstrating that the scores successfully remove confounds such as model-induced white-balance or exposure shifts; without this, the reported consistency numbers and the low-light error pattern cannot be attributed solely to lighting transport accuracy.
Authors: We agree that explicit validation of the two new scores is needed to confirm they isolate lighting transport. In the revision we will add an ablation study that measures score correlation with ground-truth probe intensity changes, plus controlled experiments that apply synthetic white-balance and exposure shifts to the ground-truth pairs and verify that the scores remain stable. These additions will directly address the concern about confounds. revision: yes
-
Referee: [Section 3] Dataset collection protocol (Section 3): the claim that the 1K pairs differ solely in light-probe state is load-bearing for all quantitative results, yet the text does not report explicit controls or measurements for camera stability, ambient light drift, or other capture variables between the on/off pairs.
Authors: Section 3 already states that a fixed tripod and a single controlled indoor session were used for each scene. We acknowledge that quantitative drift measurements were omitted. The revised manuscript will add a dedicated paragraph reporting (i) repeated camera-position checks with a laser level, (ii) ambient-light readings taken before and after each pair, and (iii) the observed maximum drift values, all of which remained below the noise floor of the HDR capture. revision: yes
Circularity Check
Empirical benchmark with physical ground truth exhibits no circularity
full rationale
The paper captures a new real-world HDR dataset of 1K image pairs differing only by physical light-probe state, annotates regions, and evaluates model edits via direct comparison to this ground truth using two new scores designed to compensate for AI photographic effects. No equations, fitted parameters, self-citations, or ansatzes reduce the reported consistency scores or error patterns to self-referential quantities by construction. The central claim of model consistency with real-world physics rests on independent physical measurements rather than any derivation that collapses to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The captured image pairs accurately isolate lighting changes from other scene variables.
Reference graph
Works this paper leans on
-
[1]
Adobe ushers in a new era of creativity with new creative agent and generative AI innovations in Adobe Firefly, April 2026
Adobe Inc. Adobe ushers in a new era of creativity with new creative agent and generative AI innovations in Adobe Firefly, April 2026. URL https://news.adobe.com/news/2026/04/ adobe-new-creative-agent
2026
-
[2]
Blended latent diffusion.ACM transactions on graphics (TOG), 42(4):1–11, 2023
Omri Avrahami, Ohad Fried, and Dani Lischinski. Blended latent diffusion.ACM transactions on graphics (TOG), 42(4):1–11, 2023
2023
-
[3]
Text2live: Text-driven layered image and video editing
Omer Bar-Tal, Dolev Ofri-Amar, Rafail Fridman, Yoni Kasten, and Tali Dekel. Text2live: Text-driven layered image and video editing. InEuropean conference on computer vision, pages 707–723. Springer, 2022
2022
-
[4]
Switchlight 3.0 is here, November 2025
Beeble AI. Switchlight 3.0 is here, November 2025. URL https://beeble.ai/research/ switchlight-3-0-is-here
2025
-
[5]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
2023
-
[6]
Qi Cai, Jingwen Chen, Yang Chen, Yehao Li, Fuchen Long, Yingwei Pan, Zhaofan Qiu, Yiheng Zhang, Fengbin Gao, Peihan Xu, et al. Hidream-i1: A high-efficient image generative foundation model with sparse diffusion transformer.arXiv preprint arXiv:2505.22705, 2025
Pith/arXiv arXiv 2025
-
[7]
Diffusionlight-turbo: Accelerated light probes for free via single-pass chrome ball inpainting
Worameth Chinchuthakun, Pakkapon Phongthawee, Amit Raj, Varun Jampani, Pramook Khungurn, and Supasorn Suwajanakorn. Diffusionlight-turbo: Accelerated light probes for free via single-pass chrome ball inpainting. InArXiv, 2025
2025
-
[8]
Raghu Vamsi Chittersu, Yuvraj Singh Rathore, Pranav Adlinge, and Kunal Swami. Insert in style: A zero-shot generative framework for harmonious cross-domain object composition.arXiv preprint arXiv:2511.15197, 2025
Pith/arXiv arXiv 2025
-
[9]
Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
Pith/arXiv arXiv 2025
-
[10]
Xingyu Fu, Muyu He, Yujie Lu, William Yang Wang, and Dan Roth. Commonsense-t2i challenge: Can text-to-image generation models understand commonsense?arXiv preprint arXiv:2406.07546, 2024
arXiv 2024
-
[11]
Introducing nano banana pro: Gemini 3 pro’s image generation and editing model
Google. Introducing nano banana pro: Gemini 3 pro’s image generation and editing model. Google Cloud Blog, 11 2025. URL https://blog.google/innovation-and-ai/products/nano-banana-pro/ . Introducing Nano Banana Pro
2025
-
[12]
Build with nano banana 2, our best image generation and editing model
Google. Build with nano banana 2, our best image generation and editing model. Google Blog, 2 2026. URL https://blog.google/innovation-and-ai/technology/developers-tools/ build-with-nano-banana-2/
2026
-
[13]
Mahfuzur Rahman, Fahad Rahman, Mohd Ariful Haque, and Sunzida Siddique
Kishor Datta Gupta, Marufa Kamal, Md. Mahfuzur Rahman, Fahad Rahman, Mohd Ariful Haque, and Sunzida Siddique. Physics-based benchmarking metrics for multimodal synthetic images, 2026. URL https://arxiv.org/abs/2511.15204
Pith/arXiv arXiv 2026
-
[14]
Kai He, Ruofan Liang, Jacob Munkberg, Jon Hasselgren, Nandita Vijaykumar, Alexander Keller, Sanja Fidler, Igor Gilitschenski, Zan Gojcic, and Zian Wang. Unirelight: Learning joint decomposition and synthesis for video relighting.arXiv preprint arXiv:2506.15673, 2025
arXiv 2025
-
[15]
Prompt-to- prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to- prompt image editing with cross attention control.arXiv preprint arXiv:2208.01626, 2022
Pith/arXiv arXiv 2022
-
[16]
Paralleledits: Efficient multi-object image editing.arXiv preprint arXiv:2406.00985, 2024
Mingzhen Huang, Jialing Cai, Shan Jia, Vishnu Suresh Lokhande, and Siwei Lyu. Paralleledits: Efficient multi-object image editing.arXiv preprint arXiv:2406.00985, 2024
arXiv 2024
-
[17]
Repurposing diffusion-based image generators for monocular depth estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, and Konrad Schindler. Repurposing diffusion-based image generators for monocular depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[18]
Marigold: Affordable adaptation of diffusion-based image generators for image analysis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Bingxin Ke, Kevin Qu, Tianfu Wang, Nando Metzger, Shengyu Huang, Bo Li, Anton Obukhov, and Konrad Schindler. Marigold: Affordable adaptation of diffusion-based image generators for image analysis.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. 11
2025
-
[19]
Intrinsic image fusion for multi-view 3d material reconstruction.ArXiv, 2025
Peter Kocsis, Lukas Höllein, and Matthias Nießner. Intrinsic image fusion for multi-view 3d material reconstruction.ArXiv, 2025
2025
-
[20]
Learning action and reasoning-centric image editing from videos and simulation.Advances in Neural Information Processing Systems, 37:38035–38078, 2024
Benno Krojer, Dheeraj Vattikonda, Luis Lara, Varun Jampani, Eva Portelance, Christopher Pal, and Siva Reddy. Learning action and reasoning-centric image editing from videos and simulation.Advances in Neural Information Processing Systems, 37:38035–38078, 2024
2024
-
[21]
Flux.2 [dev]: 32b parameter rectified flow transformer, 2025
Black Forest Labs. Flux.2 [dev]: 32b parameter rectified flow transformer, 2025. URL https:// huggingface.co/black-forest-labs/FLUX.2-dev
2025
-
[22]
FLUX.2: Frontier Visual Intelligence
Black Forest Labs. FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2, 2025. Technical report for the FLUX.2 family including Max
2025
-
[23]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
Pith/arXiv arXiv 2025
-
[24]
Baiqi Li, Zhiqiu Lin, Deepak Pathak, Jiayao Li, Yixin Fei, Kewen Wu, Tiffany Ling, Xide Xia, Pengchuan Zhang, Graham Neubig, et al. Genai-bench: Evaluating and improving compositional text-to-visual generation.arXiv preprint arXiv:2406.13743, 2024
arXiv 2024
-
[25]
Openrooms: An open framework for photorealistic indoor scene datasets
Zhengqin Li, Ting-Wei Yu, Shen Sang, Sarah Wang, Meng Song, Yuhan Liu, Yu-Ying Yeh, Rui Zhu, Nitesh Gundavarapu, Jia Shi, et al. Openrooms: An open framework for photorealistic indoor scene datasets. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7190–7199, 2021
2021
-
[26]
Ruofan Liang, Norman Müller, Ethan Weber, Duncan Zauss, Nandita Vijaykumar, Peter Kontschieder, and Christian Richardt. Luxremix: Lighting decomposition and remixing for indoor scenes.arXiv preprint arXiv:2601.15283, 2026
Pith/arXiv arXiv 2026
-
[27]
Pi-light: Physics-inspired diffusion for full-image relighting.arXiv preprint arXiv:2601.22135, 2026
Zhexin Liang, Zhaoxi Chen, Yongwei Chen, Tianyi Wei, Tengfei Wang, and Xingang Pan. Pi-light: Physics-inspired diffusion for full-image relighting.arXiv preprint arXiv:2601.22135, 2026
arXiv 2026
-
[28]
I2ebench: A comprehensive benchmark for instruction-based image editing.Advances in Neural Information Processing Systems, 37:41494–41516, 2024
Yiwei Ma, Jiayi Ji, Ke Ye, Weihuang Lin, Zhibin Wang, Yonghan Zheng, Qiang Zhou, Xiaoshuai Sun, and Rongrong Ji. I2ebench: A comprehensive benchmark for instruction-based image editing.Advances in Neural Information Processing Systems, 37:41494–41516, 2024
2024
-
[29]
Lightlab: Controlling light sources in images with diffusion models
Nadav Magar, Amir Hertz, Eric Tabellion, Yael Pritch, Alex Rav-Acha, Ariel Shamir, and Yedid Hoshen. Lightlab: Controlling light sources in images with diffusion models. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–11, 2025
2025
-
[30]
Shweta Mahajan, Shreya Kadambi, Hoang Le, Munawar Hayat, and Fatih Porikli. Do-undo: Generating and reversing physical actions in vision-language models.arXiv preprint arXiv:2512.13609, 2025
Pith/arXiv arXiv 2025
-
[31]
Fanqing Meng, Wenqi Shao, Lixin Luo, Yahong Wang, Yiran Chen, Quanfeng Lu, Yue Yang, Tianshuo Yang, Kaipeng Zhang, Yu Qiao, et al. Phybench: A physical commonsense benchmark for evaluating text-to-image models.arXiv preprint arXiv:2406.11802, 2024
arXiv 2024
-
[32]
Yuwei Niu, Munan Ning, Mengren Zheng, Weiyang Jin, Bin Lin, Peng Jin, Jiaqi Liao, Chaoran Feng, Kunpeng Ning, Bin Zhu, et al. Wise: A world knowledge-informed semantic evaluation for text-to-image generation.arXiv preprint arXiv:2503.07265, 2025
Pith/arXiv arXiv 2025
-
[33]
Addendum to gpt-4o system card: Native image generation
OpenAI. Addendum to gpt-4o system card: Native image generation. Technical report, OpenAI, 2025. URLhttps://openai.com/index/gpt-4o-system-card-addendum. Introducing GPT Image 1
2025
-
[34]
The new chatgpt images is here
OpenAI. The new chatgpt images is here. OpenAI News, 12 2025. URL https://openai.com/index/ new-chatgpt-images-is-here/. Introducing GPT Image 1.5
2025
-
[35]
Diffusionlight: Light probes for free by painting a chrome ball
Pakkapon Phongthawee, Worameth Chinchuthakun, Nontaphat Sinsunthithet, Varun Jampani, Amit Raj, Pramook Khungurn, and Supasorn Suwajanakorn. Diffusionlight: Light probes for free by painting a chrome ball. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 98–108, 2024
2024
-
[36]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 12
Pith/arXiv arXiv 2023
-
[37]
Yuandong Pu, Le Zhuo, Songhao Han, Jinbo Xing, Kaiwen Zhu, Shuo Cao, Bin Fu, Si Liu, Hongsheng Li, Yu Qiao, Wenlong Zhang, Xi Chen, and Yihao Liu. Picabench: How far are we from physically realistic image editing?arXiv preprint arXiv:2510.17681, 2025
arXiv 2025
-
[38]
Infinigen indoors: Photorealistic indoor scenes using procedural generation
Alexander Raistrick, Lingjie Mei, Karhan Kayan, David Yan, Yiming Zuo, Beining Han, Hongyu Wen, Meenal Parakh, Stamatis Alexandropoulos, Lahav Lipson, Zeyu Ma, and Jia Deng. Infinigen indoors: Photorealistic indoor scenes using procedural generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21783–21...
2024
-
[39]
Susskind
Mike Roberts, Jason Ramapuram, Anurag Ranjan, Atulit Kumar, Miguel Angel Bautista, Nathan Paczan, Russ Webb, and Joshua M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InInternational Conference on Computer Vision (ICCV) 2021, 2021
2021
-
[40]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[41]
Shadows don’t lie and lines can’t bend! generative models don’t know projective geometry
Ayush Sarkar, Hanlin Mai, Amitabh Mahapatra, Svetlana Lazebnik, David A Forsyth, and Anand Bhattad. Shadows don’t lie and lines can’t bend! generative models don’t know projective geometry... for now. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 28140–28149, 2024
2024
-
[42]
Synclight: Controllable and consistent multi-view relighting.arXiv preprint arXiv:2601.16981, 2026
David Serrano-Lozano, Anand Bhattad, Luis Herranz, Jean-François Lalonde, and Javier Vazquez-Corral. Synclight: Controllable and consistent multi-view relighting.arXiv preprint arXiv:2601.16981, 2026
Pith/arXiv arXiv 2026
-
[43]
Kaiyue Sun, Rongyao Fang, Chengqi Duan, Xian Liu, and Xihui Liu. T2i-reasonbench: Benchmarking reasoning-informed text-to-image generation.arXiv preprint arXiv:2508.17472, 2025
arXiv 2025
-
[44]
Spatiotemporally consistent indoor lighting estimation with diffusion priors
Mutian Tong, Rundi Wu, and Changxi Zheng. Spatiotemporally consistent indoor lighting estimation with diffusion priors. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–11, 2025
2025
-
[45]
Relight my nerf: A dataset for novel view synthesis and relighting of real world objects
Marco Toschi, Riccardo De Matteo, Riccardo Spezialetti, Daniele De Gregorio, Luigi Di Stefano, and Samuele Salti. Relight my nerf: A dataset for novel view synthesis and relighting of real world objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20762–20772, 2023
2023
-
[46]
Lmm4lmm: Benchmarking and evaluating large-multimodal image generation with lmms
Jiarui Wang, Huiyu Duan, Yu Zhao, Juntong Wang, Guangtao Zhai, and Xiongkuo Min. Lmm4lmm: Benchmarking and evaluating large-multimodal image generation with lmms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17312–17323, 2025
2025
-
[47]
Imagen editor and editbench: Advancing and evaluating text-guided image inpainting
Su Wang, Chitwan Saharia, Ceslee Montgomery, Jordi Pont-Tuset, Shai Noy, Stefano Pellegrini, Yasumasa Onoe, Sarah Laszlo, David J Fleet, Radu Soricut, et al. Imagen editor and editbench: Advancing and evaluating text-guided image inpainting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18359–18369, 2023
2023
-
[48]
Genspace: Benchmarking spatially-aware image generation.arXiv preprint arXiv:2505.24870, 2025
Zehan Wang, Jiayang Xu, Ziang Zhang, Tianyu Pang, Chao Du, Hengshuang Zhao, and Zhou Zhao. Genspace: Benchmarking spatially-aware image generation.arXiv preprint arXiv:2505.24870, 2025
arXiv 2025
-
[49]
Zengbin Wang, Xuecai Hu, Yong Wang, Feng Xiong, Man Zhang, and Xiangxiang Chu. Everything in its place: Benchmarking spatial intelligence of text-to-image models.arXiv preprint arXiv:2601.20354, 2026
arXiv 2026
-
[50]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
2004
-
[51]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
Pith/arXiv arXiv 2025
-
[52]
Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, Ze Liu, Ziyi Xia, Chaofan Li, Haoge Deng, Jiahao Wang, Kun Luo, Bo Zhang, Defu Lian, Xinlong Wang, Zhongyuan Wang, Tiejun Huang, and Zheng Liu. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 13
Pith/arXiv arXiv 2025
-
[53]
Kris-bench: Benchmarking next-level intelligent image editing models
Yongliang Wu, Zonghui Li, Xinting Hu, Xinyu Ye, Xianfang Zeng, Gang Yu, Wenbo Zhu, Bernt Schiele, Ming-Hsuan Yang, and Xu Yang. Kris-bench: Benchmarking next-level intelligent image editing models. arXiv preprint arXiv:2505.16707, 2025
arXiv 2025
-
[54]
Jing Yang, Krithika Dharanikota, Emily Jia, Haiwei Chen, and Yajie Zhao. Ictpolarreal: A polarized reflection and material dataset of real world objects.arXiv preprint arXiv:2603.24912, 2026
arXiv 2026
-
[55]
Primedepth: Efficient monocular depth estimation with a stable diffusion preimage
Denis Zavadski, Damjan Kalšan, and Carsten Rother. Primedepth: Efficient monocular depth estimation with a stable diffusion preimage. InProceedings of the Asian Conference on Computer Vision, pages 922–940, 2024
2024
-
[56]
RGB↔X: Image decomposition and synthesis using material- and lighting-aware diffusion models
Zheng Zeng, Valentin Deschaintre, Iliyan Georgiev, Yannick Hold-Geoffroy, Yiwei Hu, Fujun Luan, Ling- Qi Yan, and Miloš Hašan. RGB↔X: Image decomposition and synthesis using material- and lighting-aware diffusion models. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH ’24, New York, NY , USA,
2024
-
[57]
Association for Computing Machinery. ISBN 9798400705250. doi: 10.1145/3641519.3657445. URLhttps://doi.org/10.1145/3641519.3657445
-
[58]
Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction-guided image editing.Advances in Neural Information Processing Systems, 36:31428–31449, 2023
2023
-
[59]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[60]
Xiangyu Zhao, Peiyuan Zhang, Kexian Tang, Xiaorong Zhu, Hao Li, Wenhao Chai, Zicheng Zhang, Renqiu Xia, Guangtao Zhai, Junchi Yan, et al. Envisioning beyond the pixels: Benchmarking reasoning-informed visual editing.arXiv preprint arXiv:2504.02826, 2025
arXiv 2025
-
[61]
Xilong Zhou, Jianchun Chen, Pramod Rao, Timo Teufel, Linjie Lyu, Tigran Minasian, Oleksandr Sotny- chenko, Xiao-Xiao Long, Marc Habermann, and Christian Theobalt. Olatverse: A large-scale real-world object dataset with precise lighting control.arXiv preprint arXiv:2511.02483, 2025
arXiv 2025
-
[62]
Jingsen Zhu, Fujun Luan, Yuchi Huo, Zihao Lin, Zhihua Zhong, Dianbing Xi, Rui Wang, Hujun Bao, Jiaxiang Zheng, and Rui Tang. Learning-based inverse rendering of complex indoor scenes with dif- ferentiable monte carlo raytracing. InSIGGRAPH Asia 2022 Conference Papers. ACM, 2022. URL https://doi.org/10.1145/3550469.3555407
-
[63]
Irisformer: Dense vision transformers for single-image inverse rendering in indoor scenes
Rui Zhu, Zhengqin Li, Janarbek Matai, Fatih Porikli, and Manmohan Chandraker. Irisformer: Dense vision transformers for single-image inverse rendering in indoor scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2822–2831, June 2022
2022
-
[64]
Xiaorong Zhu, Ziheng Jia, Jiarui Wang, Xiangyu Zhao, Haodong Duan, Xiongkuo Min, Jia Wang, Zicheng Zhang, and Guangtao Zhai. Gobench: Benchmarking geometric optics generation and understanding of mllms. InProceedings of the 33rd ACM International Conference on Multimedia, pages 12690–12697, 2025. 14 A Proofs and scores A.1 Proof of metric invariance We sh...
arXiv 2025
-
[65]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.