Multi-modality Image Fusion under Adverse Weather: Mask-Guided Feature Restoration and Interaction
Pith reviewed 2026-06-26 05:49 UTC · model grok-4.3
The pith
A mask-guided mechanism restores features while fusing multi-modal images degraded by adverse weather.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
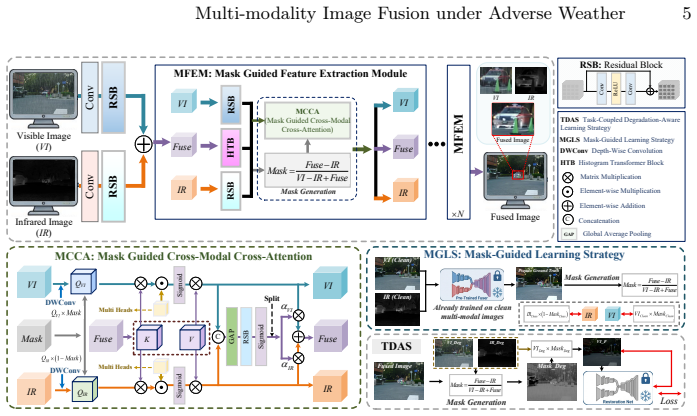
The authors present a mask-guided multi-modality image fusion network that first generates a pseudo ground truth to ease learning, then computes masks from the relationship between the current fused result and the source images; these masks drive a cross-modal cross-attention block and two task-specific learning strategies that jointly restore degraded features and preserve complementary information across modalities.
What carries the argument
The mask generation mechanism that quantifies each modality's relative contribution to the fused image and routes this information into cross-modal cross-attention.
If this is right
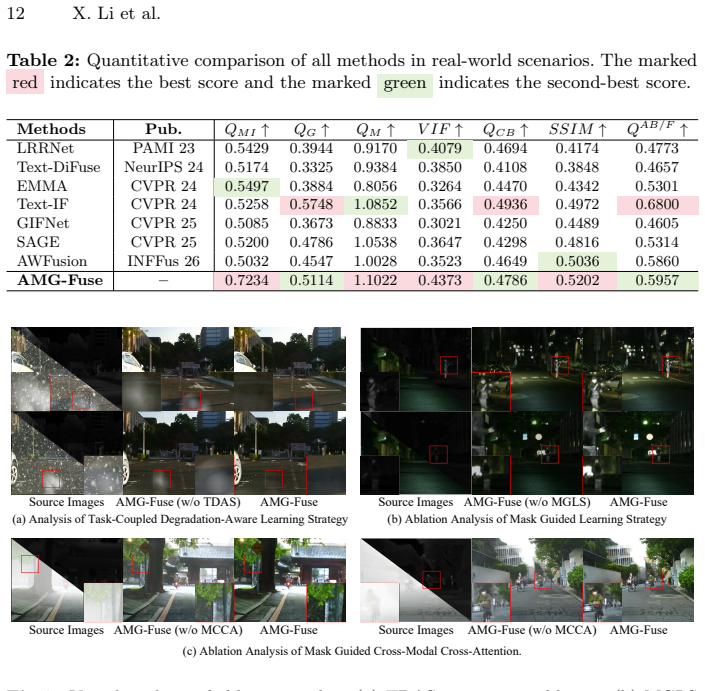
- Fused images exhibit higher visual quality and better quantitative scores on both synthetic and real adverse-weather data.
- Downstream vision tasks such as object detection receive more informative inputs from the fused output.
- The network avoids overfitting to the pseudo ground truth by dynamically weighting modality contributions.
- Feature restoration and cross-modal interaction are balanced within a single training loop rather than treated separately.
Where Pith is reading between the lines
- The same mask-generation logic could be tested on other degradation types such as low-light or motion blur to check whether the contribution-quantification step generalizes.
- If the masks prove stable, they might serve as an interpretability tool that reveals which sensor is trusted at each pixel under different weather conditions.
- Extending the pseudo-ground-truth idea to video sequences could allow temporal consistency constraints to be added without redesigning the mask module.
- The approach leaves open whether a learned mask predictor could replace the explicit mapping rule while preserving the same performance gains.
Load-bearing premise
The pseudo ground truth supplies an unbiased training signal that does not lock the network into a static distribution or introduce artifacts through the mask computation.
What would settle it
A controlled test on real-world adverse-weather pairs in which the proposed method shows no gain in standard fusion metrics or downstream task accuracy over the strongest baseline that lacks the mask guidance.
Figures






read the original abstract
Multi-modality image fusion (MMIF) enhances scene representation by exploiting complementary cues from different modalities. Adverse weather, however, causes significant image degradation, disrupting feature representation and requiring simultaneous feature restoration and cross-modal complementarity. Existing methods often struggle with effective representation learning under such conditions, limiting their practical performance. To address these challenges, we propose a mask-guided MMIF method that integrates feature restoration and interaction. We first introduce "Pseudo Ground Truth" to simplify training, promoting faster and more effective feature learning. Then, we design a mask generation mechanism based on the mapping relationship between the fused result and the source images, quantifying the relative contribution of each modality during the fusion process. By incorporating the proposed mask-guided cross-modal cross-attention mechanism, the network is encouraged to selectively attend to informative features during modality interaction, mitigating the risk of overfitting to the static distribution of the "Pseudo Ground Truth". Additionally, we propose a mask-guided learning strategy and a task-coupled degradation-aware learning strategy to balance feature restoration and interaction. Extensive experiments on synthetic and real-world datasets demonstrate that our method surpasses state-of-the-art approaches in visual quality, quantitative metrics, and downstream tasks. The source code is available at https://github.com/ixilai/AMG-Fuse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a mask-guided multi-modality image fusion method for adverse weather that combines feature restoration and cross-modal interaction. It introduces Pseudo Ground Truth to simplify training, a mask generation mechanism that maps the fused output back to source images to quantify relative modality contributions, a mask-guided cross-modal cross-attention module, and mask-guided plus task-coupled degradation-aware learning strategies. The central claim is that the approach outperforms prior SOTA methods on synthetic and real-world datasets in visual quality, quantitative metrics, and downstream tasks.
Significance. If the empirical claims hold after addressing the validation gaps, the work would provide a practical route to robust MMIF under degradation by using masks to balance restoration and selective interaction, with direct relevance to vision systems in autonomous driving or surveillance. Open-sourcing the code is a clear strength for reproducibility.
major comments (3)
- [Abstract] Abstract: the superiority claim on quantitative metrics and downstream tasks is asserted without any numerical values, ablation tables, or error bars, so the magnitude and consistency of gains cannot be assessed from the provided text.
- [Pseudo Ground Truth] Pseudo Ground Truth section: the construction is presented as an unbiased target that the mask mechanism prevents from causing static-distribution overfitting, yet no comparison to real ground truth, bias quantification, or ablation removing the pseudo-GT is supplied to support this.
- [Mask generation mechanism] Mask generation mechanism: the mapping from fused result to source images is assumed to yield artifact-free relative-contribution weights that safely drive cross-attention, but no independent check (human-annotated modality weights, mask-noise ablation, or correlation analysis with pseudo-GT artifacts) is reported.
minor comments (2)
- [Figures] Figure captions and method diagrams should explicitly label the mask generation and cross-attention blocks for clarity.
- [Experiments] The real-world dataset description lacks details on weather severity distribution and sensor calibration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, indicating the revisions we will implement.
read point-by-point responses
-
Referee: [Abstract] Abstract: the superiority claim on quantitative metrics and downstream tasks is asserted without any numerical values, ablation tables, or error bars, so the magnitude and consistency of gains cannot be assessed from the provided text.
Authors: We agree that the abstract would be strengthened by including concrete numerical evidence. In the revised version, we will incorporate key quantitative results from the experimental sections, such as average PSNR/SSIM gains on synthetic data and mAP improvements on downstream tasks, along with standard deviations where reported. revision: yes
-
Referee: [Pseudo Ground Truth] Pseudo Ground Truth section: the construction is presented as an unbiased target that the mask mechanism prevents from causing static-distribution overfitting, yet no comparison to real ground truth, bias quantification, or ablation removing the pseudo-GT is supplied to support this.
Authors: The Pseudo Ground Truth is introduced because real ground truth is unavailable under adverse weather. We will add an ablation study that removes the Pseudo-GT component to demonstrate its contribution. We will also expand the text to discuss potential biases in its construction and the role of the mask mechanism in mitigating overfitting risks. revision: yes
-
Referee: [Mask generation mechanism] Mask generation mechanism: the mapping from fused result to source images is assumed to yield artifact-free relative-contribution weights that safely drive cross-attention, but no independent check (human-annotated modality weights, mask-noise ablation, or correlation analysis with pseudo-GT artifacts) is reported.
Authors: We will add validation experiments for the mask generation mechanism, specifically mask-noise ablation studies and correlation analysis between the generated masks and Pseudo-GT artifacts. These will be included in the revised manuscript to provide independent empirical checks on the reliability of the derived weights. revision: yes
Circularity Check
No circularity: empirical method with independent experimental validation
full rationale
The paper introduces a mask-guided fusion architecture that employs pseudo ground truth for training simplification and a mask-generation step derived from fused-to-source mapping to guide cross-attention. These components are presented as engineering choices to mitigate overfitting and balance restoration versus interaction; the central performance claims rest on reported experiments across synthetic and real datasets plus downstream tasks rather than any equation that reduces the output metric to a fitted parameter or self-citation chain. No load-bearing derivation, uniqueness theorem, or ansatz is shown to collapse into its own inputs by construction. The pipeline therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Pseudo Ground Truth
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Bai, H., Zhang, J., Zhao, Z., Wu, Y., Deng, L., Cui, Y., Feng, T., Xu, S.: Task- driven image fusion with learnable fusion loss. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7457–7468 (2025)
2025
-
[2]
In: 2024 IEEE International Conference on Image Processing (ICIP)
Chen, J., Yu, W., Tian, X., Huang, J., Ma, J.: Mdbfusion: A visible and infrared image fusion framework capable for motion deblurring. In: 2024 IEEE International Conference on Image Processing (ICIP). pp. 1019–1025. IEEE (2024)
2024
-
[3]
Pattern Recognition159, 111098 (2025)
Chen, X., Xu, S., Hu, S., Ma, X.: Acfnet: An adaptive cross-fusion network for infrared and visible image fusion. Pattern Recognition159, 111098 (2025)
2025
-
[4]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Cheng, C., Xu, T., Feng, Z., Wu, X., Tang, Z., Li, H., Zhang, Z., Atito, S., Awais, M., Kittler, J.: One model for all: Low-level task interaction is a key to task- agnostic image fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28102–28112 (2025) 16 X. Li et al
2025
-
[5]
In: The Thirteenth International Conference on Learning Representations (2025)
Cui, Y., Zamir, S.W., Khan, S., Knoll, A., Shah, M., Khan, F.S.: AdaIR: Adap- tive all-in-one image restoration via frequency mining and modulation. In: The Thirteenth International Conference on Learning Representations (2025)
2025
-
[6]
Measurement p
Huang, J., Li, X., Tan, H., Yang, L., Wang, G., Yi, P.: Dednet: Infrared and visible image fusion with noise removal by decomposition-driven network. Measurement p. 115092 (2024)
2024
-
[7]
In: Proceedings of the IEEE/CVF international con- ference on computer vision
Jia, X., Zhu, C., Li, M., Tang, W., Zhou, W.: Llvip: A visible-infrared paired dataset for low-light vision. In: Proceedings of the IEEE/CVF international con- ference on computer vision. pp. 3496–3504 (2021)
2021
-
[8]
Expert Systems with Appli- cations227, 120301 (2023)
Jie, Y., Li, X., Zhou, F., Tan, H., et al.: Medical image fusion based on ex- tended difference-of-gaussians and edge-preserving. Expert Systems with Appli- cations227, 120301 (2023)
2023
-
[9]
Infor- mation Fusion121, 103146 (2025)
Jie, Y., Xu, Y., Li, X., Zhou, F., Lv, J., Li, H.: Fs-diff: Semantic guidance and clarity-aware simultaneous multimodal image fusion and super-resolution. Infor- mation Fusion121, 103146 (2025)
2025
-
[10]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
Li, H., Yang, Z., Zhang, Y., Jia, W., Yu, Z., Liu, Y.: Mulfs-cap: Multimodal fusion- supervised cross-modality alignment perception for unregistered infrared-visible image fusion. IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[11]
Li, H., Xu, T., Wu, X.J., Lu, J., Kittler, J.: Lrrnet: A novel representation learning guidedfusionnetworkforinfraredandvisibleimages.IEEEtransactionsonpattern analysis and machine intelligence (2023)
2023
-
[12]
In: Proceedings of the 31st ACM International Conference on Multimedia
Li, J., Chen, J., Liu, J., Ma, H.: Learning a graph neural network with cross modal- ity interaction for image fusion. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 4471–4479 (2023)
2023
-
[13]
IEEE Transactions on Image Processing (2025)
Li, J., Jiang, J., Liang, P., Ma, J., Nie, L.: Maefuse: Transferring omni features with pretrained masked autoencoders for infrared and visible image fusion via guided training. IEEE Transactions on Image Processing (2025)
2025
-
[14]
Knowledge-Based Systems224, 107087 (2021)
Li, X., Zhou, F., Tan, H.: Joint image fusion and denoising via three-layer decom- position and sparse representation. Knowledge-Based Systems224, 107087 (2021)
2021
-
[15]
IEEE Transactions on Image Process- ing34, 6231–6245 (2025)
Li, X., Li, X., Tan, T., Li, H., Ye, T.: Umcfuse: A unified multiple complex scenes infrared and visible image fusion framework. IEEE Transactions on Image Process- ing34, 6231–6245 (2025)
2025
-
[16]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Li, X., Li, X., Ye, T., Cheng, X., Liu, W., Tan, H.: Bridging the gap between multi- focus and multi-modal: a focused integration framework for multi-modal image fusion. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 1628–1637 (2024)
2024
-
[17]
IEEE Transactions on Image Processing35, 5151–5164 (2026)
Li, X., Liu, H., Li, X., Ye, T., Kuang, Z., Li, H.: Awm-fuse: multi-modality image fusion for adverse weather via global and local text perception. IEEE Transactions on Image Processing35, 5151–5164 (2026)
2026
-
[18]
Information Fusion p
Li, X., Liu, W., Li, X., Zhou, F., Li, H., Nie, F.: All-weather multi-modality im- age fusion: Unified framework and 100k benchmark. Information Fusion p. 104130 (2026)
2026
-
[19]
In: European Conference on Computer Vision
Liang, P., Jiang, J., Liu, X., Ma, J.: Fusion from decomposition: A self-supervised decomposition approach for image fusion. In: European Conference on Computer Vision. pp. 719–735. Springer (2022)
2022
-
[20]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Liu, J., Fan, X., Huang, Z., Wu, G., Liu, R., Zhong, W., Luo, Z.: Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 5802–5811 (2022) Multi-modality Image Fusion under Adverse Weather 17
2022
-
[21]
International Journal of Computer Vision132(5), 1748–1775 (2024)
Liu, J., Lin, R., Wu, G., Liu, R., Luo, Z., Fan, X.: Coconet: Coupled contrastive learningnetworkwithmulti-levelfeatureensembleformulti-modalityimagefusion. International Journal of Computer Vision132(5), 1748–1775 (2024)
2024
-
[22]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
Liu, J., Wu, G., Liu, Z., Wang, D., Jiang, Z., Ma, L., Zhong, W., Fan, X.: In- frared and visible image fusion: From data compatibility to task adaption. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024)
2024
-
[23]
IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (2024)
Liu, R., Liu, Z., Liu, J., Fan, X., Luo, Z.: A task-guided, implicitly-searched and metainitialized deep model for image fusion. IEEE Transactions on Pattern Anal- ysis and Machine Intelligence (2024)
2024
-
[24]
IEEE transactions on pattern analysis and machine intelligence34(1), 94–109 (2011)
Liu, Z., Blasch, E., Xue, Z., Zhao, J., Laganiere, R., Wu, W.: Objective assess- ment of multiresolution image fusion algorithms for context enhancement in night vision: a comparative study. IEEE transactions on pattern analysis and machine intelligence34(1), 94–109 (2011)
2011
-
[25]
In: Proceedings of the 31st ACM International Conference on Multimedia
Liu, Z., Liu, J., Zhang, B., Ma, L., Fan, X., Liu, R.: Paif: Perception-aware infrared- visible image fusion for attack-tolerant semantic segmentation. In: Proceedings of the 31st ACM International Conference on Multimedia. pp. 3706–3714 (2023)
2023
-
[26]
Multimedia tools and applications82(26), 41241–41251 (2023)
Rajasekaran, G., Abitha, V., Vaishnavi, S.: Image dehazing algorithm based on artificial multi-exposure image fusion. Multimedia tools and applications82(26), 41241–41251 (2023)
2023
-
[27]
IEEE transactions on pattern analysis and machine intelligence44(3), 1623–1637 (2020)
Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., Koltun, V.: Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE transactions on pattern analysis and machine intelligence44(3), 1623–1637 (2020)
2020
-
[28]
IEEE Transactions on Circuits and Systems for Video Technology (2025)
Shi, Y., Shi, C., Weng, Z., Tian, Y., Xian, X., Lin, L.: Crossfuse: Learning infrared and visible image fusion by cross-sensor top-k vision alignment and beyond. IEEE Transactions on Circuits and Systems for Video Technology (2025)
2025
-
[29]
In: European Conference on Computer Vi- sion
Sun, S., Ren, W., Gao, X., Wang, R., Cao, X.: Restoring images in adverse weather conditions via histogram transformer. In: European Conference on Computer Vi- sion. pp. 111–129. Springer (2024)
2024
-
[30]
Advances in Neural Information Processing Systems35, 4461–4474 (2022)
Sun, S., Ren, W., Wang, T., Cao, X.: Rethinking image restoration for object de- tection. Advances in Neural Information Processing Systems35, 4461–4474 (2022)
2022
-
[31]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Tang, L., Deng, Y., Yi, X., Yan, Q., Yuan, Y., Ma, J.: Drmf: Degradation-robust multi-modal image fusion via composable diffusion prior. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 8546–8555 (2024)
2024
-
[32]
Information Fusion82, 28–42 (2022)
Tang, L., Yuan, J., Ma, J.: Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Information Fusion82, 28–42 (2022)
2022
-
[33]
Information Fusion 83, 79–92 (2022)
Tang, L., Yuan, J., Zhang, H., Jiang, X., Ma, J.: Piafusion: A progressive infrared and visible image fusion network based on illumination aware. Information Fusion 83, 79–92 (2022)
2022
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, C.Y., Bochkovskiy, A., Liao, H.Y.M.: Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7464–7475 (2023)
2023
-
[35]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, G., Liu, H., Fu, H., Peng, Y., Liu, J., Fan, X., Liu, R.: Every sam drop counts: Embracing semantic priors for multi-modality image fusion and beyond. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 17882–17891 (2025)
2025
-
[36]
arXiv preprint arXiv:2606.12303 (2026) 18 X
Xian, Y., Xu, Y., He, Y., Yang, Y.: From 2d grids to 1d tokens: Reforming shared representations for multimodal image fusion. arXiv preprint arXiv:2606.12303 (2026) 18 X. Li et al
Pith/arXiv arXiv 2026
-
[37]
IEEE Transactions on Pattern Analysis and Machine Intelligence 44(1), 502–518 (2020)
Xu, H., Ma, J., Jiang, J., Guo, X., Ling, H.: U2fusion: A unified unsupervised image fusion network. IEEE Transactions on Pattern Analysis and Machine Intelligence 44(1), 502–518 (2020)
2020
-
[38]
In: International Conference on Medical Image Computing and Computer-Assisted Intervention
Xu, Y., Li, X., Jie, Y., Tan, H.: Simultaneous tri-modal medical image fusion and super-resolution using conditional diffusion model. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. pp. 635–645. Springer (2024)
2024
-
[39]
Information Fusion121, 103148 (2025)
Yang, Z., Zhang, Y., Li, H., Liu, Y.: Instruction-driven fusion of infrared–visible images: Tailoring for diverse downstream tasks. Information Fusion121, 103148 (2025)
2025
-
[40]
Information Fusion110, 102450 (2024)
Yi, X., Tang, L., Zhang, H., Xu, H., Ma, J.: Diff-if: Multi-modality image fusion via diffusion model with fusion knowledge prior. Information Fusion110, 102450 (2024)
2024
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yi, X., Xu, H., Zhang, H., Tang, L., Ma, J.: Text-if: Leveraging semantic text guidance for degradation-aware and interactive image fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 27026– 27035 (2024)
2024
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: Efficient transformer for high-resolution image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5728–5739 (2022)
2022
-
[43]
Advances in Neural Informa- tion Processing Systems37, 39552–39572 (2024)
Zhang, H., Cao, L., Ma, J.: Text-difuse: An interactive multi-modal image fusion framework based on text-modulated diffusion model. Advances in Neural Informa- tion Processing Systems37, 39552–39572 (2024)
2024
-
[44]
Information Fusion76, 323–336 (2021)
Zhang, H., Xu, H., Tian, X., Jiang, J., Ma, J.: Image fusion meets deep learning: A survey and perspective. Information Fusion76, 323–336 (2021)
2021
-
[45]
IEEE Transactions on Pattern Analysis and Machine Intelligence (2023)
Zhang, X., Demiris, Y.: Visible and infrared image fusion using deep learning. IEEE Transactions on Pattern Analysis and Machine Intelligence (2023)
2023
-
[46]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, Z., Bai, H., Zhang, J., Zhang, Y., Xu, S., Lin, Z., Timofte, R., Van Gool, L.: Cddfuse: Correlation-driven dual-branch feature decomposition for multi-modality image fusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5906–5916 (2023)
2023
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhao, Z., Bai, H., Zhang, J., Zhang, Y., Zhang, K., Xu, S., Chen, D., Timofte, R., Van Gool, L.: Equivariant multi-modality image fusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 25912– 25921 (2024)
2024
-
[48]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhao, Z., Bai, H., Zhu, Y., Zhang, J., Xu, S., Zhang, Y., Zhang, K., Meng, D., Tim- ofte, R., Van Gool, L.: Ddfm: denoising diffusion model for multi-modality image fusion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8082–8093 (2023)
2023
-
[49]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhu, P., Sun, Y., Cao, B., Hu, Q.: Task-customized mixture of adapters for general image fusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7099–7108 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.