Computer Vision for MOBA Analytics: A Dataset and Baseline for Visibility Analysis in Dota 2
Pith reviewed 2026-06-26 05:01 UTC · model grok-4.3
The pith
A dataset of 288 Dota 2 match videos enables object detection to produce visibility curves that reveal behavioral patterns missed by structured game data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Releasing the Dota2-Vis dataset of 288 Full HD videos and annotations, then showing that YOLO11l reliably locates player icons on cluttered minimaps, allows construction of visibility timelines that complement conventional MOBA analytics by highlighting behavioral differences difficult to obtain from structured data alone.
What carries the argument
YOLO11l large object detector trained on manually labeled minimap frames to estimate per-team visible player presence and generate visibility curves.
If this is right
- Visibility tracking can be automated from existing match video archives.
- MOBA analytics gains direct measures of information available to each team.
- Hero- and role-specific positioning patterns become measurable from visual data.
- Team-level comparisons of awareness and decision making can draw on visibility timelines.
Where Pith is reading between the lines
- The pipeline could support real-time visibility overlays during live broadcasts.
- Combining the visibility curves with event logs might identify moments when teams act on unseen information.
- The same annotation and detection approach could be applied to other MOBAs that use similar minimap designs.
Load-bearing premise
The manually annotated minimap images accurately represent the true visibility state from each team's perspective during live matches, and detections from the trained model generalize to the full set of 288 videos without significant domain shift or annotation error.
What would settle it
Applying the trained YOLO11l model to a fresh collection of manually verified minimap frames and obtaining precision or recall below the levels reported on the held-out test set would show the baseline does not generalize.
Figures



read the original abstract
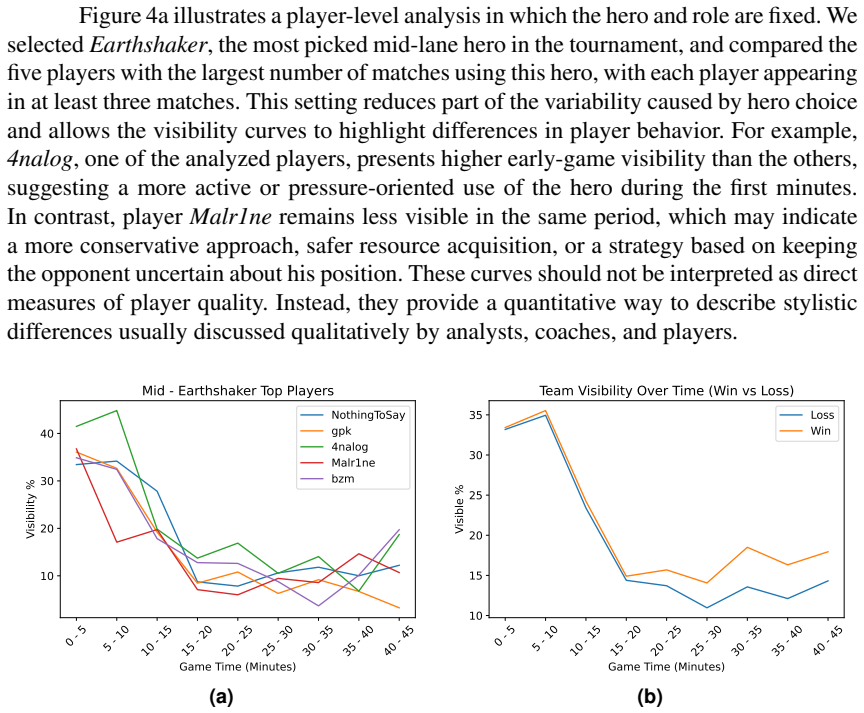
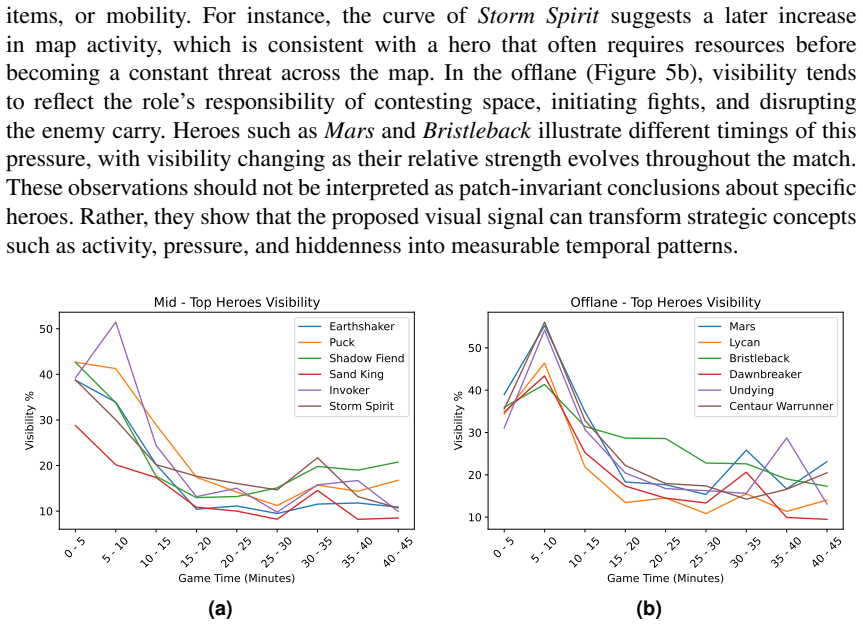
Introduction: Most Multiplayer Online Battle Arena (MOBA) analytics studies rely on structured data, which does not directly capture what each team could actually see during a match. Objective: This work introduces Dota2-Vis, a video-based dataset, and a baseline pipeline for visibility analysis in professional Dota 2 matches. Methodology: The dataset comprises all 144 matches from The International 2025, recorded from both team perspectives, totaling 288 Full HD videos, together with 2,477 manually annotated minimap images. We evaluate multiple variants of a modern object detector for player-icon detection and use the best-performing model to estimate opponent-visible player presence over time. Results: YOLO11l (large) achieved the best overall performance, reliably identifying player icons even in dense and visually cluttered minimap scenes. The resulting visibility curves reveal player, hero, role, and team-level patterns that complement conventional MOBA analytics, highlighting behavioral differences that are difficult to obtain from structured data alone. The dataset and code are publicly available at https://github.com/RicardoRCarvalho/dota2-vis/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Dota2-Vis dataset comprising 288 Full HD videos (144 matches from The International 2025 recorded from both team perspectives) and 2,477 manually annotated minimap images. It benchmarks YOLO11 model variants for player-icon detection on minimaps, reports YOLO11l as the top performer for reliable detection in cluttered scenes, and applies the model to generate visibility curves that expose player-, hero-, role-, and team-level patterns. These are positioned as complementary to conventional structured-data MOBA analytics. The dataset and code are released publicly.
Significance. If the annotations faithfully capture team-specific visibility states and detections generalize, the work fills a gap in esports analytics by enabling direct measurement of in-game visibility, which structured data cannot provide. The public release of the full dataset and code is a clear strength that supports reproducibility and community extension. This represents a useful application of modern object detection to a domain-specific problem.
major comments (3)
- [Dataset creation] Dataset creation section: The manuscript supplies no annotation protocol, inter-annotator agreement statistics, or description of how team-specific visibility (fog-of-war, wards, perspective differences) was encoded in the 2,477 frames across the 288 videos. This directly undermines verification of the ground-truth labels that support the central visibility-curve claim.
- [Experimental evaluation] Experimental evaluation section: No train/test split details, cross-match validation, statistical significance tests, or error analysis on the full unannotated videos are reported. Without these, the assertion that YOLO11l 'reliably' detects icons and generalizes to the 288-video corpus remains unverified and load-bearing for the results.
- [Visibility analysis] Visibility analysis subsection: The pipeline that converts detections into player/hero/role/team visibility curves does not quantify or mitigate the impact of false positives/negatives, leaving open whether the reported behavioral patterns could arise from detection artifacts rather than true visibility differences.
minor comments (2)
- [Results] Results tables should report parameter counts, inference speeds, and confidence intervals or standard deviations across multiple runs to strengthen the model comparison.
- [Figures] Figure captions for the visibility curves could explicitly note the temporal resolution and any smoothing applied.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to incorporate the requested information and analyses.
read point-by-point responses
-
Referee: [Dataset creation] Dataset creation section: The manuscript supplies no annotation protocol, inter-annotator agreement statistics, or description of how team-specific visibility (fog-of-war, wards, perspective differences) was encoded in the 2,477 frames across the 288 videos. This directly undermines verification of the ground-truth labels that support the central visibility-curve claim.
Authors: We agree that the annotation protocol and related statistics were insufficiently documented. In the revised manuscript we will add a dedicated subsection detailing the annotation guidelines, the procedure used to encode team-specific visibility (including handling of fog-of-war, wards, and perspective), and inter-annotator agreement measured on a 200-frame overlap subset annotated independently by two annotators. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation section: No train/test split details, cross-match validation, statistical significance tests, or error analysis on the full unannotated videos are reported. Without these, the assertion that YOLO11l 'reliably' detects icons and generalizes to the 288-video corpus remains unverified and load-bearing for the results.
Authors: We acknowledge the need for these experimental details. The revision will specify the train/test split (by match to prevent leakage), report results under cross-match validation, include statistical significance tests on the detection metrics, and provide a quantitative error analysis on a sampled subset of the unannotated videos to support the generalization claim. revision: yes
-
Referee: [Visibility analysis] Visibility analysis subsection: The pipeline that converts detections into player/hero/role/team visibility curves does not quantify or mitigate the impact of false positives/negatives, leaving open whether the reported behavioral patterns could arise from detection artifacts rather than true visibility differences.
Authors: We agree that the impact of detection errors on the derived curves should be quantified. The revised visibility analysis will include an error-propagation study that simulates false-positive and false-negative rates (drawn from the validation performance) on the visibility curves, together with a discussion of mitigation steps such as temporal filtering and confidence thresholding. revision: yes
Circularity Check
No circularity: empirical dataset creation and standard model evaluation
full rationale
The paper creates a new video dataset of 288 Dota 2 matches with 2,477 manual annotations and evaluates off-the-shelf YOLO11 variants on held-out frames. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. Results are direct performance metrics (e.g., detection accuracy) on the authors' own annotations; the central claims do not reduce to quantities defined by the paper's own prior parameters or unverified self-references. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MoBA-VP: Segmentation-Guided Motion-Biased Attention for Long-Term Video Prediction , year=
Kim, Yuseon and Park, Kyongseok , journal=. MoBA-VP: Segmentation-Guided Motion-Biased Attention for Long-Term Video Prediction , year=
-
[2]
ADVANCES IN COMPUTER VISION: NEW HORIZONS AND ONGOING CHALLENGES , volume =
Majhi, Rahul and Waoo, Akhilesh , year =. ADVANCES IN COMPUTER VISION: NEW HORIZONS AND ONGOING CHALLENGES , volume =. ShodhKosh: Journal of Visual and Performing Arts , doi =
-
[3]
Artificial Intelligence in
Costa, Lincoln Magalhães and Drachen, Anders and Souza, Francisco Carlos Monteiro and Xexéo, Geraldo , journal=. Artificial Intelligence in. 2024 , volume=
2024
-
[4]
Joo, Ho-Taek and Lee, Sung-Ha and Chung, Insik and Kim, Kyung-Joong , title=. Scientific Reports , year=. doi:10.1038/s41598-025-93692-0 , url=
-
[5]
, booktitle=
Su, Norman Makoto and Crandall, David J. , booktitle=. The Affective Growth of Computer Vision , year=
-
[6]
Predicting Events in
Yang, Zelong and Wang, Yan and Li, Piji and Lin, Shaobin and Shi, Shuming and Huang, Shao-Lun and Bi, Wei , journal=. Predicting Events in. 2023 , volume=
2023
-
[7]
Machine Learning with Applications , volume =
Time to Die 2: Improved in-game death prediction in. Machine Learning with Applications , volume =. 2023 , issn =. doi:10.1016/j.mlwa.2023.100466 , author =
-
[8]
and Demediuk, Simon and Block, Florian and Drachen, Anders and Walker, James Alfred , booktitle=
Katona, Adam and Spick, Ryan and Hodge, Victoria J. and Demediuk, Simon and Block, Florian and Drachen, Anders and Walker, James Alfred , booktitle=. Time to Die: Death Prediction in. 2019 , volume=
2019
-
[9]
WARDS : Modelling the Worth of Vision in MOBA 's
Chitayat, Alan Pedrassoli and Kokkinakis, Athanasios and Patra, Sagarika and Demediuk, Simon and Robertson, Justus and Olarewaju, Oluseji and Ursu, Marian and Kirmann, Ben and Hook, Jonathan and Block, Florian and Drachen, Anders. WARDS : Modelling the Worth of Vision in MOBA 's. Science and Information Conference. 2020
2020
-
[10]
Wang, Nanzhi and Li, Lin and Xiao, Linlong and Yang, Guocai and Zhou, Yue , title =. 2018 , isbn =. doi:10.1145/3208788.3208800 , booktitle =
-
[11]
Predicting Winning Team and Probabilistic Ratings in ``Dota 2'' and ``Counter-Strike: Global Offensive'' Video Games
Makarov, Ilya and Savostyanov, Dmitry and Litvyakov, Boris and Ignatov, Dmitry I. Predicting Winning Team and Probabilistic Ratings in ``Dota 2'' and ``Counter-Strike: Global Offensive'' Video Games. Analysis of Images, Social Networks and Texts. 2018
2018
-
[12]
Draft-analysis of the ancients: predicting draft picks in
Summerville, Adam and Cook, Michael and Steenhuisen, Ben , booktitle=. Draft-analysis of the ancients: predicting draft picks in
-
[13]
Real-time eSports match result prediction
Yang, Yifan and Qin, Tian and Lei, Yu-Heng. Real-time eSports match result prediction. arXiv:1701.03162
-
[14]
Dota 2 with large scale deep reinforcement learning
OpenAI and Berner, Christopher and Brockman, Greg and Chan, Brooke and Cheung, Vicki and D e biak, Przemys aw and Dennison, Christy and Farhi, David and Fischer, Quirin and Hashme, Shariq and Hesse, Chris and J \'o zefowicz, Rafal and Gray, Scott and Olsson, Catherine and Pachocki, Jakub and Petrov, Michael and Pinto, Henrique Pond \'e de Oliveira and Rai...
Pith/arXiv arXiv 1912
-
[15]
What Are You Looking At?
Tot, Marko and Conserva, Michelangelo and Chitayat, Alan Pedrassoli and Kokkinakis, Athanasios and Patra, Sagarika and Demediuk, Simon and Munoz, Alvaro Caceres and Olarewaju, Oluseji and Ursu, Marian and Kirmann, Ben and Hook, Jonathan and Block, Florian and Drachen, Anders and Perez-Liebana, Diego , booktitle=. What Are You Looking At?. 2021 , volume=
2021
-
[16]
Real-Time Player Tracking Framework on
Kim, Dae-Wook and Park, Sung-Yun and Yang, Seong-Il and Lee, Sang-Kwang , journal=. Real-Time Player Tracking Framework on. 2025 , volume=
2025
-
[17]
and Demediuk, Simon and Drachen, Anders and Hook, Jonathan and Nolle, Isabelle and Olarewaju, Oluseyi and Slawson, Daniel and Ursu, Marian and Block, Florian Oliver , title=
Kokkinakis, Athanasios and York, Peter and Patra, Moni Sagarika and Robertson, Justus and Kirman, Ben and Coates, Alistair and Chitayat, Alan P. and Demediuk, Simon and Drachen, Anders and Hook, Jonathan and Nolle, Isabelle and Olarewaju, Oluseyi and Slawson, Daniel and Ursu, Marian and Block, Florian Oliver , title=. International Journal of Esports , year=
-
[18]
Interpretable Real-Time Win Prediction for
Yang, Zelong and Pan, Zhufeng and Wang, Yan and Cai, Deng and Shi, Shuming and Huang, Shao-Lun and Bi, Wei and Liu, Xiaojiang , journal=. Interpretable Real-Time Win Prediction for. 2022 , volume=
2022
-
[19]
Liquipedia , title =
-
[20]
Profiling Successful Team Behaviors in League of Legends , doi =
Felix, Fernando and Melo, Allan and Costa, Igor and Marinho, Leandro , year =. Profiling Successful Team Behaviors in League of Legends , doi =
-
[21]
2013 , doi =
Game Analytics: Maximizing the Value of Player Data , publisher =. 2013 , doi =
2013
-
[22]
International Conf
Semenov, Aleksandr and Romov, Peter and Korolev, Sergey and Yashkov, Daniil and Neklyudov, Kirill , title =. International Conf. on Analysis of Images, Social Networks and Texts , pages =. 2017 , doi =
2017
-
[23]
2021 , journal =
Win Prediction in Multiplayer Esports: Live Professional Match Prediction , author =. 2021 , journal =
2021
-
[24]
and Drachen, Anders and Cowling, Peter I
Block, Florian and Hodge, Victoria and Hobson, Stephen and Sephton, Nick and Devlin, Sam and Ursu, Marian F. and Drachen, Anders and Cowling, Peter I. , title =. Proceedings of the 2018 ACM International Conference on Interactive Experiences for TV and Online Video , pages =. 2018 , isbn =. doi:10.1145/3210825.3210833 , abstract =
-
[25]
International Joint Conference on Neural Networks (IJCNN) , pages =
R. International Joint Conference on Neural Networks (IJCNN) , pages =. 2025 , title =
2025
-
[26]
A comprehensive review of
Terven, Juan and C. A comprehensive review of. Machine Learning and Knowledge Extraction , volume=
-
[27]
Object detection using YOLO: challenges, architectural successors, datasets and applications,
Diwan, Tausif and Anirudh, G. and Tembhurne, Jitendra V. , year =. Object detection using. Multimedia Tools and Applications , volume =. doi:10.1007/s11042-022-13644-y , issn =
-
[28]
Ultralytics , year =
-
[29]
Bj\". Do We Train on Test Data?. 2020 , journal =. doi:10.3390/jimaging6060041 , issn =
-
[30]
Everingham, Mark and Van Gool, Luc and Williams, Christopher K. I. and Winn, John and Zisserman, Andrew , day =. The Pascal Visual Object Classes (. International Journal of Computer Vision , month =. doi:10.1007/s11263-009-0275-4 , issn =
-
[31]
Microsoft
Lin, Tsung-Yi and Maire, Michael and Belongie, Serge and Hays, James and Perona, Pietro and Ramanan, Deva and Doll. Microsoft. European Conference on Computer Vision (ECCV) , doi =
-
[32]
Mahlmann, Tobias and Schubert, Matthias and Drachen, Anders , year =
-
[33]
A Visual Analytics Approach for Understanding Reasons behind Snowballing and Comeback in
Li, Quan and Xu, Peng and Chan, Yeuk Yin and Wang, Yun and Wang, Zhipeng and Qu, Huamin and Ma, Xiaojuan , year =. A Visual Analytics Approach for Understanding Reasons behind Snowballing and Comeback in. IEEE Transactions on Visualization and Computer Graphics , volume =. doi:10.1109/TVCG.2016.2598415 , keywords =
-
[34]
and Bennett, Kyle J
Novak, Andrew R. and Bennett, Kyle J. M. and Pluss, Matthew A. and Fransen, Job , journal =. Performance Analysis in Esports: Part 1 -- The Validity and Reliability of Match Statistics and Notational Analysis in. 2019 , doi =
2019
-
[35]
Esports Training, Periodization, and Software—A Scoping Review , author =. 2024 , journal =. doi:10.3390/app142210354 , issn =
-
[36]
Do We Train on Test Data?
R. Do We Train on Test Data?. International Joint Conference on Neural Networks (IJCNN) , volume =. 2023 , month =
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.