Towards Explainable Adjudicative Variance: Quantifying Judicial Discretion via Gated Multi-Task Learning
Pith reviewed 2026-06-26 04:46 UTC · model grok-4.3
The pith
A gated multi-task architecture for legal outcome prediction separates merit-based rulings from those driven by judicial discretion, outperforming larger models with far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For identity-conditioned classification of legal outcomes, the choice of conditioning interface dominates scale: differentiable structured composition via a gated multi-task architecture yields more accurate and more parameter-efficient models than prompt-based composition over a substantially larger backbone.
What carries the argument
Judge-Aware Gated Multi-Task Learning architecture whose Gated Fusion mechanism is supervised by a fine-grained outcome taxonomy that disentangles merit pathways from technical disposals.
If this is right
- The gated architecture achieves new state-of-the-art accuracy on the UK tribunal benchmark while using far fewer trainable parameters than generative supervised fine-tuning baselines.
- Performance improvements concentrate on the most ambiguous and rarest outcome classes.
- Learned judge embeddings and calibration profiles make visible the subset of cases in which adjudicative context dominates the prediction.
- The two contextual signals (judge identity and outcome taxonomy) compose weakly when forced through a single autoregressive channel but compose effectively through the gated interface.
Where Pith is reading between the lines
- The same gated separation of identity signals from content signals could be tested on other identity-conditioned classification tasks where rare or ambiguous labels matter most.
- If the taxonomy supervision is the main source of regularization, then substituting other structured label hierarchies might produce comparable efficiency gains in non-legal domains.
- The interpretability of judge embeddings suggests the model could be used to audit systematic differences in how individual decision-makers handle equivalent facts.
Load-bearing premise
The fine-grained outcome taxonomy supplies supervision that forces the encoder to separate distinct semantic pathways for merit-based rulings versus those driven by judicial discretion.
What would settle it
A direct comparison showing that removing the taxonomy supervision eliminates the accuracy gains on the most ambiguous and rarest outcome classes would falsify the claim that the structured regularization is what enables the advantage.
Figures

read the original abstract
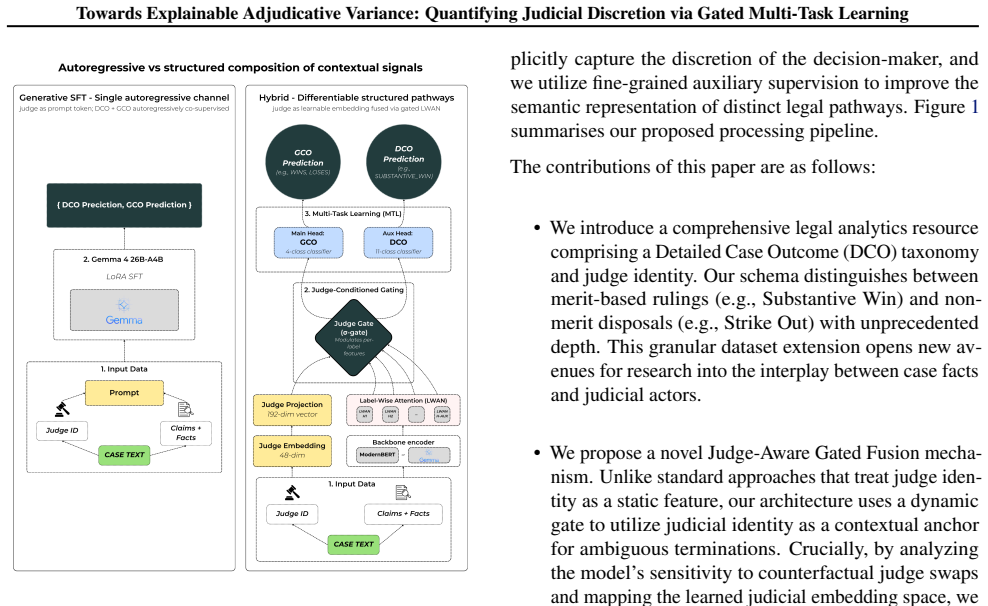
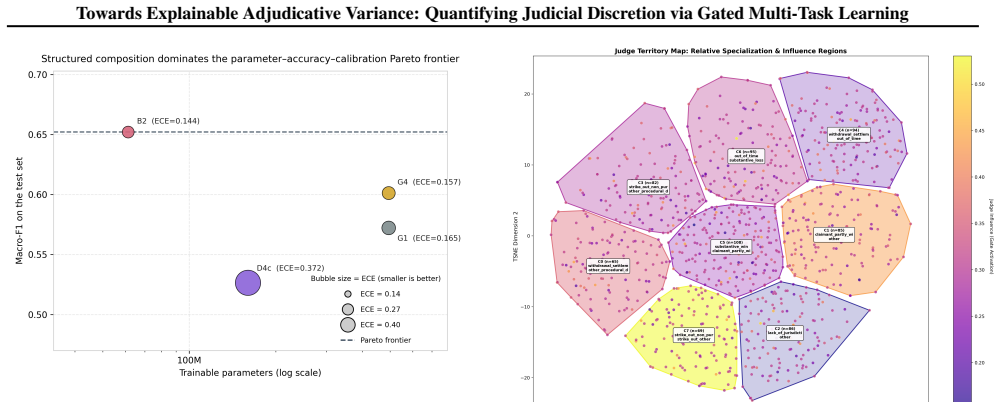
Legal outcome prediction must disentangle objective case facts from adjudicative context. Merit-based rulings rely on factual evidence while technical disposals may hinge on judicial discretion. We propose a Judge-Aware Gated Multi-Task Learning architecture that explicitly models this distinction. We introduce a fine-grained outcome taxonomy to supervise the encoder, enforcing a structural regularization that disentangles distinct semantic pathways. This granular legal curriculum enables our Gated Fusion mechanism to dynamically modulate reliance on judge identity. We evaluate our approach on 13,937 UK Employment Tribunal decisions. We benchmark our design against supervised fine-tuning (SFT) of a Gemma-4 26B-A4B backbone, in which judge identity and the taxonomy are injected as prompt tokens or autoregressive output targets. The two contextual signals compose only weakly when forced through a single autoregressive channel. In contrast, coupling a LoRA-adapted Gemma-4 encoder with our gated architecture defines a new state of the art on this benchmark while requiring an order of magnitude fewer trainable parameters than the generative SFT baselines, with gains concentrated on the most ambiguous and rarest outcome classes. Beyond accuracy, the architecture is interpretable; learned judge embeddings and calibration profiles localize the cases where adjudicative context drives the prediction. These results indicate that, for identity-conditioned classification of legal outcomes, the choice of conditioning interface dominates scale: differentiable structured composition yields more accurate, more parameter-efficient models than prompt-based composition over a substantially larger backbone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a Judge-Aware Gated Multi-Task Learning architecture for legal outcome prediction on 13,937 UK Employment Tribunal decisions. A fine-grained outcome taxonomy supervises the encoder to disentangle merit-based rulings from judicial discretion-driven technical disposals. The Gated Fusion mechanism dynamically modulates reliance on judge identity. The approach is benchmarked against prompt-based and autoregressive SFT of a Gemma-4 26B-A4B backbone; the manuscript asserts that a LoRA-adapted Gemma-4 encoder plus the gated MTL design yields SOTA accuracy with an order of magnitude fewer trainable parameters, with gains concentrated on ambiguous and rare outcome classes, plus interpretability via learned judge embeddings and calibration profiles.
Significance. If the empirical claims hold, the work demonstrates that structured differentiable conditioning interfaces can outperform larger generative models using prompt-based composition for identity-conditioned legal classification tasks, while improving parameter efficiency and providing localization of adjudicative variance. The focus on rare/ambiguous classes and explicit disentanglement via taxonomy supervision would strengthen the case for explainable legal AI systems.
major comments (3)
- [Abstract] Abstract: the claim of new state-of-the-art performance and order-of-magnitude parameter reduction is asserted without any numerical results, confidence intervals, ablation tables, or baseline scores; this absence makes the central efficiency and accuracy claims impossible to evaluate from the supplied text.
- [Abstract] Abstract / Evaluation section: the statement that gains are 'concentrated on the most ambiguous and rarest outcome classes' is load-bearing for the taxonomy-supervision argument, yet no per-class metrics, confusion matrices, or frequency-stratified results are referenced to support it.
- [Abstract] Abstract: the description of how the fine-grained outcome taxonomy was constructed, validated, or shown to enforce structural regularization (disentangling merit vs. discretion pathways) is absent; without this, the weakest modeling assumption cannot be assessed.
minor comments (1)
- [Abstract] Clarify the exact model variant referenced as 'Gemma-4 26B-A4B' and whether it is an internal or public checkpoint.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where the abstract could better support the central claims. We address each point below and will revise the abstract accordingly while preserving the manuscript's technical content.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of new state-of-the-art performance and order-of-magnitude parameter reduction is asserted without any numerical results, confidence intervals, ablation tables, or baseline scores; this absence makes the central efficiency and accuracy claims impossible to evaluate from the supplied text.
Authors: We agree the abstract should include key quantitative support. The full manuscript reports these in Section 4 (Table 2 for accuracy and parameter counts, Table 4 for ablations, with 95% CIs from 5 runs). In revision we will add concise numerical highlights (e.g., accuracy delta and parameter ratio) plus explicit references to the tables. revision: yes
-
Referee: [Abstract] Abstract / Evaluation section: the statement that gains are 'concentrated on the most ambiguous and rarest outcome classes' is load-bearing for the taxonomy-supervision argument, yet no per-class metrics, confusion matrices, or frequency-stratified results are referenced to support it.
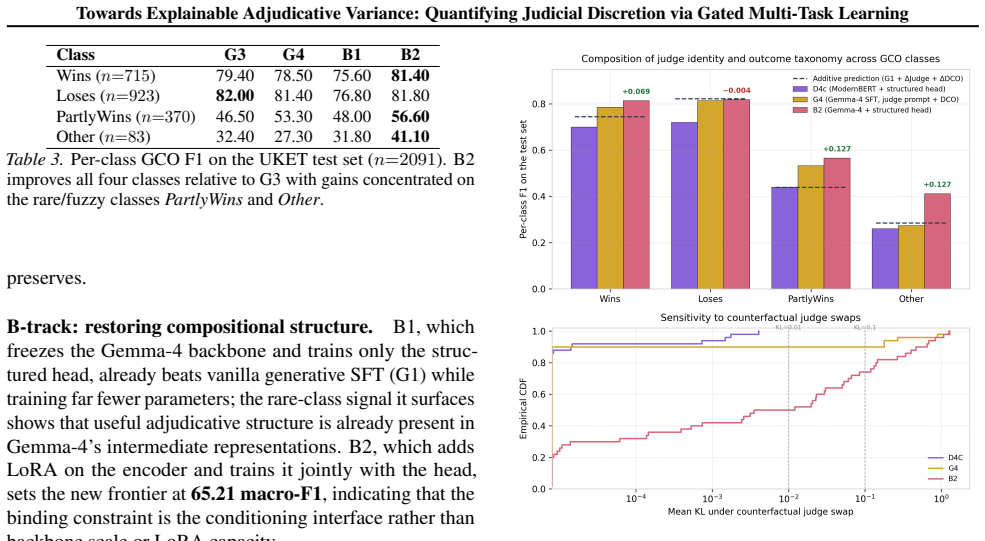
Authors: The supporting evidence appears in the evaluation section (Figure 3 for frequency-stratified F1, Table 3 for per-class breakdown, and confusion matrices in Appendix C). We will revise the abstract to include a brief reference to these results and a one-sentence summary of the observed concentration on rare/ambiguous classes. revision: yes
-
Referee: [Abstract] Abstract: the description of how the fine-grained outcome taxonomy was constructed, validated, or shown to enforce structural regularization (disentangling merit vs. discretion pathways) is absent; without this, the weakest modeling assumption cannot be assessed.
Authors: Section 3.1 details the taxonomy construction (expert annotation protocol, inter-annotator agreement of 0.87, and the structural regularization objective). We will add a short clause in the abstract summarizing the construction process and directing readers to Section 3.1 for validation details. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical ML architecture for legal outcome prediction, trained and evaluated on an external labeled dataset of 13,937 UK tribunal decisions. Performance claims (SOTA accuracy, parameter efficiency, gains on rare classes) rest on standard supervised training against held-out test data and comparison to prompt-based SFT baselines; no equations, derivations, or first-principles results are presented that reduce any claimed quantity to quantities defined by the model's own fitted parameters or by self-citation chains. The gated MTL design and taxonomy supervision are presented as modeling choices whose validity is assessed externally via benchmark metrics, rendering the argument self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The chosen outcome taxonomy provides independent supervision that structurally regularizes the encoder to separate merit-based and discretionary semantic pathways.
invented entities (1)
-
Judge-Aware Gated Fusion mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gated Multimodal Units for Information Fusion
URL https://api.semanticscholar. org/CorpusID:7630289. Arevalo, J., Solorio, T., y Gmez, M. M., and Gonzlez, F. A. Gated multimodal units for information fusion, 2017. URLhttps://arxiv.org/abs/1702.01992. Baxter, J. A model of inductive bias learning.Journal of Artificial Intelligence Research, 12:149–198, 03 2000. doi: 10.1613/jair.731. BehnamGhader, P.,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1613/jair.731 2017
-
[2]
L ex GLUE : A Benchmark Dataset for Legal Language Understanding in E nglish
URL https://aclanthology.org/2020. emnlp-main.607/. Chalkidis, I., Jana, A., Hartung, D., Bommarito, M., An- droutsopoulos, I., Katz, D., and Aletras, N. LexGLUE: A benchmark dataset for legal language understanding in English. In Muresan, S., Nakov, P., and Villavicen- cio, A. (eds.),Proceedings of the 60th Annual Meet- ing of the Association for Computa...
-
[3]
URL https://api.semanticscholar. org/CorpusID:16119010. Deng, L., Wang, M., Yang, C., and Wang, Y . LegiLM: A fine-tuned legal language model for data compli- ance, 2024. URL https://arxiv.org/abs/ 2409.13721. Dominguez-Olmedo, R., Nanda, V ., Abebe, R., Bech- told, S., Engel, C., Gummadi, K. P., Hardt, M., Hil- gard, S., and Schmude, M. Lawma: The power ...
-
[4]
URL https://api.semanticscholar. org/CorpusID:52985426. Engel, C. and Weinshall, K. Manna from heaven for judges: Judges reaction to a quasi-random reduction in caseload.Journal of Empirical Legal Studies, 17 (4):722–751, 2020. doi: https://doi.org/10.1111/jels. 12265. URL https://onlinelibrary.wiley. com/doi/abs/10.1111/jels.12265. Gan, L., Li, B., Kuang...
-
[5]
URL https://aclanthology.org/2023. findings-emnlp.814/. Gemma Team, Google DeepMind. Gemma 4: Multimodal open-weights models. Technical report, Google Deep- Mind, April 2026. URL https://huggingface. co/google/gemma-4-26B-A4B-it. Hu, E. J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., and Chen, W. LoRA: Low-rank adaptation of large l...
Pith/arXiv arXiv 2023
-
[6]
Curran Associates Inc. ISBN 9781713871088. Katz, D. M., Bommarito, M. J., and Blackman, J. A general approach for predicting the behavior of the supreme court of the united states.PloS one, 12(4):e0174698, 2017. Kovaleva, O., Romanov, A., Rogers, A., and Rumshisky, A. Revealing the dark secrets of BERT. In Inui, K., Jiang, J., Ng, V ., and Wan, X. (eds.),...
-
[7]
KMMLU: Measuring massive multitask language understanding in Korean
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025.naacl-long
-
[8]
URL https://aclanthology.org/2025. naacl-long.355/. Li, e. a. Unilaw-R1: A large language model for legal reasoning with reinforcement learning and iterative in- ference. InFindings of the Association for Compu- tational Linguistics: EMNLP, 2025. URL https: //arxiv.org/abs/2510.10072. Li, S., Zhang, H., Ye, L., Guo, X., and Fang, B. Mann: A multichannel a...
arXiv 2025
-
[9]
URL https://api.semanticscholar. org/CorpusID:204939518. Li, Z. and Zhou, T. Your mixture-of-experts LLM is secretly an embedding model for free. InInternational Confer- ence on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2410.10814. Oral presentation. Lim, B., Ark, S. ., Loeff, N., and Pfister, T. Tempo- ral fusion transformers for i...
arXiv 2025
-
[10]
Available: https://doi.org/10.1016/j.ijforecast.2021.03
doi: https://doi.org/10.1016/j.ijforecast.2021.03. 11 Towards Explainable Adjudicative Variance: Quantifying Judicial Discretion via Gated Multi-Task Learning
-
[11]
Luo, B., Feng, Y ., Xu, J., Zhang, X., and Zhao, D
URL https://www.sciencedirect.com/ science/article/pii/S0169207021000637. Luo, B., Feng, Y ., Xu, J., Zhang, X., and Zhao, D. Learning to predict charges for criminal cases with legal basis. In Palmer, M., Hwa, R., and Riedel, S. (eds.),Proceedings of the 2017 Conference on Empirical Methods in Natu- ral Language Processing, pp. 2727–2736, Copenhagen, Den...
-
[12]
cc/paper_files/paper/2023/file/ 819b8452be7d6af1351d4c4f9cbdbd9b-Paper-Datasets_ and_Benchmarks.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ 819b8452be7d6af1351d4c4f9cbdbd9b-Paper-Datasets_ and_Benchmarks.pdf. Sanh, V ., Wolf, T., and Ruder, S. A hierarchical multi- task approach for learning embeddings from semantic tasks. InAAAI Conference on Artificial Intelligence,
2023
-
[13]
org/CorpusID:53436546
URL https://api.semanticscholar. org/CorpusID:53436546. Sargeant, H., ¨Ostling, A., and Magnusson, M. Detect- ing legal citations in United Kingdom court judgments. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of the 2025 Confer- ence on Empirical Methods in Natural Language Pro- cessing, pp. 26798–26824, Suzhou, ...
2025
-
[14]
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/v1/2025.emnlp-main
-
[15]
URL https://aclanthology.org/2025. emnlp-main.1361/. Segal, J. A. and Cover, A. D. Ideological values and the votes of u.s. supreme court justices.The American Political Science Review, 83(2):557–565, 1989. ISSN 00030554, 15375943. URL http://www.jstor. org/stable/1962405. Shihata, Y . Gated recursive fusion: A stateful approach to scalable multimodal tra...
-
[16]
URL https://aclanthology.org/2023. findings-eacl.44/. T.y.s.s, S., Perez San Blas, M., Kemper, P., and Grab- mair, M. Leveraging task dependency and contrastive learning for case outcome classification on European court of human rights cases. In Vlachos, A. and Au- genstein, I. (eds.),Proceedings of the 17th Conference of the European Chapter of the Assoc...
-
[17]
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
URL https://aclanthology.org/2024. findings-emnlp.214/. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need. InNeural Informa- tion Processing Systems, 2017. URL https://api. semanticscholar.org/CorpusID:13756489. V oita, E., Talbot, D., Moiseev, F., Sennrich, R., and Titov...
-
[18]
org/CorpusID:278108241
URL https://api.semanticscholar. org/CorpusID:278108241. Warner, B., Chaffin, A., Clavi´e, B., Weller, O., Hallstr¨om, O., Taghadouini, S., Gallagher, A., Biswas, R., Lad- hak, F., Aarsen, T., Adams, G. T., Howard, J., and Poli, I. Smarter, better, faster, longer: A modern bidi- rectional encoder for fast, memory efficient, and long context finetuning and...
2025
-
[19]
doi: 10.18653/v1/2025.acl-long.127. URL https: //aclanthology.org/2025.acl-long.127/. Wu, Y ., Zhou, S., Liu, Y ., Lu, W., Liu, X., Zhang, Y ., Sun, C., Wu, F., and Kuang, K. Precedent-enhanced legal judgment prediction with LLM and domain-model col- laboration. In Bouamor, H., Pino, J., and Bali, K. (eds.), Proceedings of the 2023 Conference on Empirical...
-
[20]
URL https://aclanthology.org/2023. emnlp-main.740/. Xie, H., Steffek, F., de Faria, J. R., Carter, C., and Ruther- ford, J. The clc-uket dataset: Benchmarking case outcome prediction for the uk employment tribunal, 2024. URL https://arxiv.org/abs/2409.08098. Yue, S., Chen, W., Wang, S., Li, B., Shen, C., Liu, S., Zhou, Y ., Xiao, Y ., Yun, S., Lin, W., Hu...
arXiv 2023
-
[21]
The facts do not point cleanly to a complete win or complete loss
Legal evaluation.The dispute combines adminis- trative process, security vetting, race discrimination, disability discrimination, and reasonable adjustments. The facts do not point cleanly to a complete win or complete loss. This is the type of mixed legal eval- uation that is naturally represented by claimant - partly wins
-
[22]
The generative model predicts both LOSES and substantive loss
G4 collapses the mixed evaluation to a full loss. The generative model predicts both LOSES and substantive loss. That error is plausible if the model focuses on the contested security-clearance dis- pute as an unsuccessful discrimination claim, but it misses the multiple remedy structure of the case
-
[23]
This is consistent with the aggregate result that B2’s largest gains are on PARTLY WINS
B2 recovers the partial-outcome structure.B2 pre- dicts PARTLY WINS, aligning with the gold GCO. This is consistent with the aggregate result that B2’s largest gains are on PARTLY WINS. The composite head can preserve a fine-grained partial-success path- way that is easy to lose in a single autoregressive label channel
-
[24]
Implication for the conditioning interface.Since both models use the Gemma backbone, the relevant difference is the conditioning interface. The rescue suggests that LW AN plus multi-task fine-grained super- vision helps the model retain mixed remedial structure even when the surface narrative contains strong loss- like elements. E.2. Rescuing an atypical ...
-
[25]
This combination is not well captured by a simple merits-based win/loss framing
Legal evaluation.The case lies at the boundary be- tween ordinary dismissal litigation, victimisation for a protected act, safeguarding concerns, data governance, and investigation conduct. This combination is not well captured by a simple merits-based win/loss framing
-
[26]
Given the misconduct narrative and the employer’s loss-of-trust account, a generative model can plausibly map the case to LOSES
G4 follows the dominant substantive-loss pathway. Given the misconduct narrative and the employer’s loss-of-trust account, a generative model can plausibly map the case to LOSES. But the gold label is OTHER, reflecting the atypical procedural and legal evaluation. In particular, further evidence might be necessary in this case
-
[27]
This matches the aggregate pattern: B2 improves Other F1 to 0.411, compared with G4’s 0.273
B2 preserves the minority-class boundary.B2 pre- dicts OTHER, the rarest and most difficult GCO class. This matches the aggregate pattern: B2 improves Other F1 to 0.411, compared with G4’s 0.273
-
[28]
Implication for the composite head.The case il- lustrates a central advantage of the composite head: label-wise attention and fine-grained supervision can maintain an alternative procedural/outcome pathway even when the surface text contains strong majority- class cues. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.