The Riddle Riddle: Testing Flexible Reasoning in Large Language Models and Humans
Pith reviewed 2026-06-26 04:42 UTC · model grok-4.3
The pith
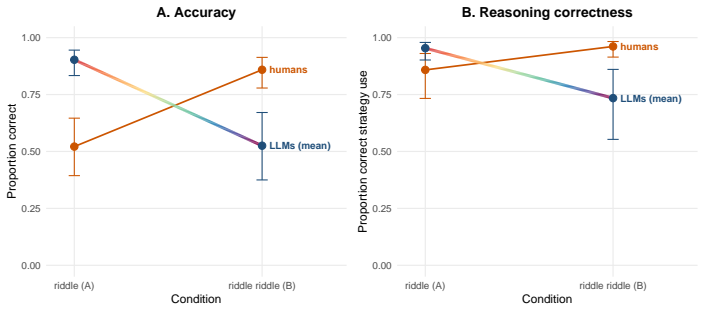
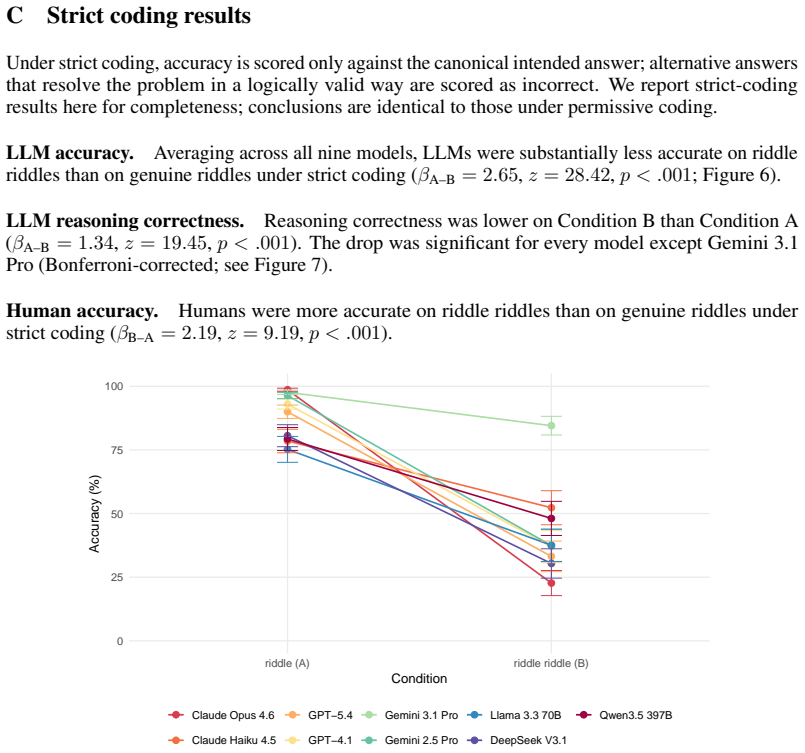
LLMs solve genuine riddles at 85 percent accuracy but drop to 51 percent on versions rewritten to require only literal answers, while humans show the opposite pattern.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
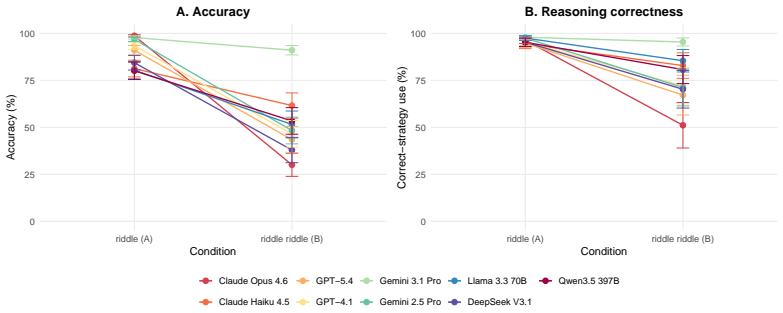
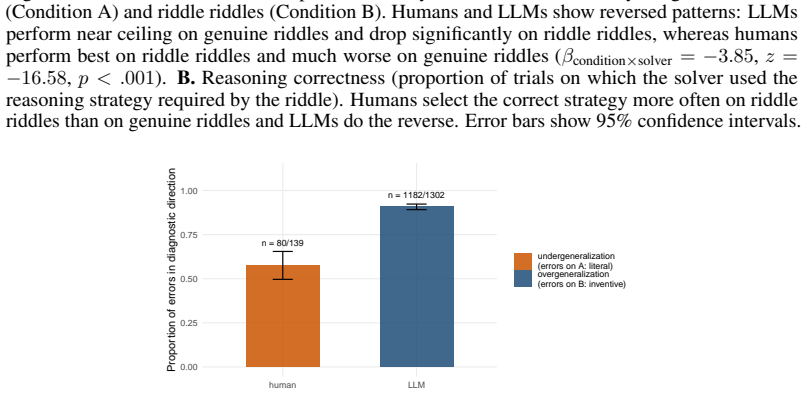
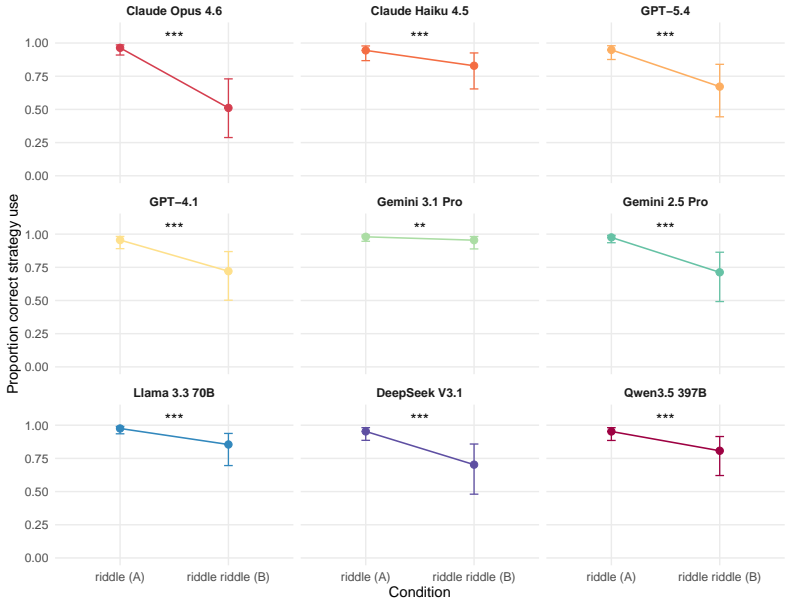
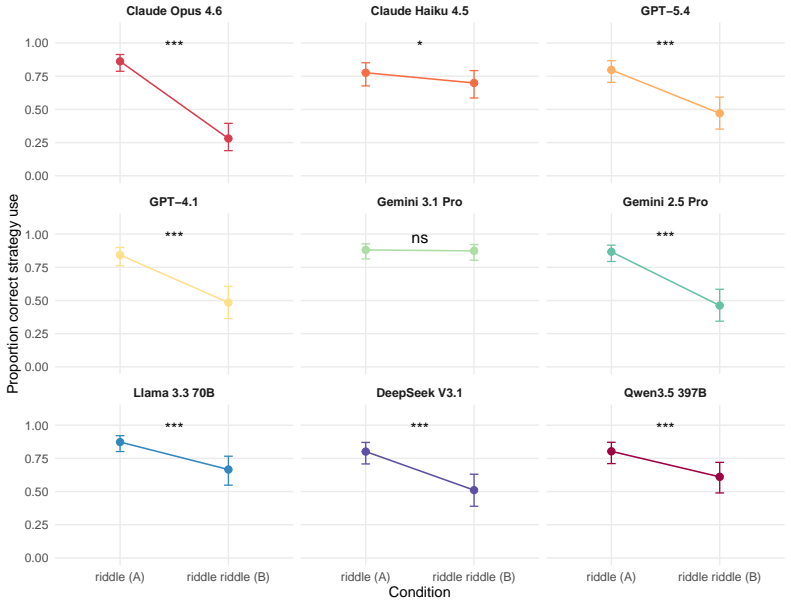
The riddle riddle paradigm reveals that LLMs apply inventive reasoning even when a literal strategy is sufficient, producing lower accuracy on riddle riddles (50.7 percent) than on genuine riddles (84.9 percent), while humans show the reverse accuracy pattern (80.5 percent versus 50.5 percent). Most LLM errors on riddle riddles (90.8 percent) consist of inappropriately using inventive reasoning, compared with 57.6 percent of human errors on genuine riddles being overextension of literal reasoning. This contrast supports the claim that LLM success on genuine riddles reflects memory retrieval of familiar riddle structures rather than content-driven selection of reasoning strategies.
What carries the argument
The riddle riddle paradigm, which generates word problems that preserve riddle-like phrasing and structure but alter the required solution to a literal interpretation instead of an inventive one.
If this is right
- LLM outputs that appear to demonstrate reasoning on tasks with familiar surface forms may instead result from pattern retrieval.
- Cognitive benchmarks for LLMs require controls that force a contrast between surface-form strategies and content-based strategy switching.
- Human performance advantages on literal versions of riddle-like problems point to a difference in how the two systems select reasoning modes.
- Error analysis separating inappropriate inventive responses from other mistakes provides a diagnostic for distinguishing retrieval from flexible reasoning.
Where Pith is reading between the lines
- Similar surface-form controls could be applied to other reasoning benchmarks that use story problems or lateral-thinking items.
- If training corpora contain many riddle examples, targeted removal or rewriting of such examples might reduce the performance gap between genuine and altered versions.
- The paradigm could be extended to test whether the same retrieval-versus-flexibility split appears in non-riddle tasks that have both figurative and literal solution paths.
Load-bearing premise
Riddle riddles match genuine riddles in every respect except the shift from inventive to literal reasoning, with no unintended differences in difficulty, wording familiarity, or other surface features.
What would settle it
LLMs would achieve statistically equivalent accuracy on genuine riddles and riddle riddles after the two sets are matched for length, vocabulary frequency, and participant ratings of familiarity and difficulty.
Figures

read the original abstract
Humans flexibly adapt their reasoning strategies to the requirements of a given problem. Large language models (LLMs) have performed well on many cognitive tasks, however, it is unclear whether this accuracy is a result of pattern matching from training data or flexible reasoning. Here, we introduce a novel paradigm to test this question: the riddle riddle paradigm. Riddle riddles are word problems written to mimic popular riddles, but altered so their answers only require literal interpretations. Identifying correct answers requires looking past the structure of each question and flexibly apply different reasoning strategies based on the content. If LLMs respond to surface features, such as form, a riddle-like structure should cause models to use an inventive reasoning strategy even when a literal interpretation suffices. Alternatively, if LLMs reason based on content, they should flexibly switch strategies when appropriate. Across two experiments with nine state-of-the-art LLMs and 100 human participants, we show humans and LLMs fail on this paradigm in opposite directions. LLMs were far more accurate on genuine riddles than on riddle riddles (84.9% vs. 50.7%); whereas humans showed the reverse effect (50.5% vs. 80.5%). Error analysis shows that 90.8% of LLM errors on riddle riddles (the condition where they show diminished performance) were due to inappropriate use of inventive reasoning while only 57.6% of human errors on genuine riddles were due to overextending literal reasoning. Thus, while both groups make mistakes, reasoning mistakes are made more often by LLMs than by humans. Overall, LLMs' strong performance on genuine riddles may reflect memory retrieval rather than flexible strategy selection, and without stimuli designed to elicit this contrast, it becomes easy to conflate LLM-generated outputs that look like reasoning with genuine reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the 'riddle riddle' paradigm: word problems that mimic the surface form of popular riddles but require only literal interpretations for correct answers. Across nine LLMs and 100 humans, LLMs achieve 84.9% on genuine riddles but only 50.7% on riddle riddles, while humans show the reverse (50.5% vs. 80.5%). Error analysis attributes 90.8% of LLM riddle-riddle errors to inappropriate inventive reasoning (vs. 57.6% of human genuine-riddle errors from over-literal responses), supporting the claim that LLM riddle performance reflects memory retrieval rather than flexible strategy selection.
Significance. If the riddle-riddle stimuli are shown to be matched to genuine riddles on difficulty, familiarity, and surface features, the opposite performance patterns would provide direct evidence that current LLMs lack the flexible strategy switching humans exhibit, with implications for interpreting 'reasoning' benchmarks. The work is a clean empirical contrast with no fitted parameters or circular derivations.
major comments (3)
- [Methods / Stimulus construction] Methods (stimulus construction): no quantitative matching is reported between genuine riddles and riddle riddles on dimensions such as word frequency, perplexity under a language model, sentence length, or pre-tested human difficulty ratings. The central claim that the 34-point LLM accuracy drop reflects inappropriate inventive reasoning rather than general task difficulty therefore rests on an untested equivalence assumption.
- [Results / Error analysis] Results (error analysis): the classification that 90.8% of LLM riddle-riddle errors are 'inappropriate inventive reasoning' inherits the same confound; without independent validation that riddle riddles do not differ in surface features that might elicit inventive responses, the error percentages cannot be unambiguously attributed to strategy selection.
- [Abstract / Results] Abstract and Results: prompt wording and exact model instructions are not provided, leaving open the possibility that differences in how the two conditions were framed (rather than the literal vs. inventive requirement) contribute to the observed reversal.
minor comments (2)
- [Results] The paper should report statistical tests (e.g., mixed-effects models) for the condition-by-group interaction rather than relying solely on raw accuracy percentages.
- [Methods] Clarify the exact number and selection criteria for the nine LLMs and the 100 human participants (e.g., recruitment platform, exclusion criteria).
Simulated Author's Rebuttal
We thank the referee for their constructive comments on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Methods / Stimulus construction] Methods (stimulus construction): no quantitative matching is reported between genuine riddles and riddle riddles on dimensions such as word frequency, perplexity under a language model, sentence length, or pre-tested human difficulty ratings. The central claim that the 34-point LLM accuracy drop reflects inappropriate inventive reasoning rather than general task difficulty therefore rests on an untested equivalence assumption.
Authors: We agree that reporting quantitative matching on these dimensions would provide stronger evidence for the equivalence of the stimuli. In the revised manuscript, we will include analyses comparing word frequency, sentence length, and perplexity between the genuine riddles and riddle riddles. Additionally, we will report any available pre-tested difficulty ratings or conduct a small validation if feasible. This will allow us to statistically test for differences and address the equivalence assumption directly. revision: yes
-
Referee: [Results / Error analysis] Results (error analysis): the classification that 90.8% of LLM riddle-riddle errors are 'inappropriate inventive reasoning' inherits the same confound; without independent validation that riddle riddles do not differ in surface features that might elicit inventive responses, the error percentages cannot be unambiguously attributed to strategy selection.
Authors: The error analysis is based on post-hoc classification of responses, and we acknowledge the potential for surface features to influence the type of errors. To address this, we will add a section in the revision where we provide independent ratings of the 'riddle-likeness' or surface similarity of the stimuli, and correlate these with error types if possible. However, the core design ensures that the correct response for riddle riddles is literal by construction, as the questions were altered specifically for that purpose. revision: partial
-
Referee: [Abstract / Results] Abstract and Results: prompt wording and exact model instructions are not provided, leaving open the possibility that differences in how the two conditions were framed (rather than the literal vs. inventive requirement) contribute to the observed reversal.
Authors: We recognize the importance of providing the exact prompts for reproducibility. In the revised version, we will include the full prompt templates used for both genuine riddles and riddle riddles across all models in the Methods section or as supplementary material. This will clarify that the instructions were consistent in framing the task as answering the question, without biasing towards inventive or literal responses. revision: yes
Circularity Check
No circularity: direct empirical comparison with measured outcomes
full rationale
The paper reports an experimental comparison of LLM and human accuracy on genuine riddles versus constructed riddle riddles, along with error coding. No equations, derivations, fitted parameters, or predictions appear anywhere in the abstract or described results. Performance metrics (84.9% vs 50.7% for LLMs; 50.5% vs 80.5% for humans) and error percentages are direct observational outcomes rather than quantities defined in terms of themselves or reduced to prior self-citations. The central claim rests on the observed performance gap and error patterns, which are independent of any self-referential construction. No load-bearing steps match any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Riddle riddles can be written so that they match genuine riddles in surface structure while requiring only literal interpretation, without introducing other confounds
Reference graph
Works this paper leans on
-
[1]
Thompson
Rakefet Ackerman and Valerie A. Thompson. Meta-reasoning: Monitoring and control of thinking and reasoning.Trends in Cognitive Sciences, 21(8):607–617, 2017
2017
-
[2]
Stumpers: An annotated compendium.Thinking & Reasoning, 27(4):536–566, 2021
Maya Bar-Hillel. Stumpers: An annotated compendium.Thinking & Reasoning, 27(4):536–566, 2021
2021
-
[3]
A is B” fail to learn “B is A
Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. The reversal curse: LLMs trained on “A is B” fail to learn “B is A”. InInternational Conference on Learning Representations, 2024
2024
-
[4]
Using cognitive psychology to understand GPT-3.Proceedings of the National Academy of Sciences, 120(6):e2218523120, 2023
Marcel Binz and Eric Schulz. Using cognitive psychology to understand GPT-3.Proceedings of the National Academy of Sciences, 120(6):e2218523120, 2023
2023
-
[5]
Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[6]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with GPT-4.arXiv preprint arXiv:2303.12712, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Liu, Elizabeth Bonawitz, and Tomer D
Junyi Chu, Misha O’Keeffe, Silvia K. Liu, Elizabeth Bonawitz, and Tomer D. Ullman. Stumped! Learning to think outside the box in 3-7 year old children. InProceedings of the Annual Meeting of the Cognitive Science Society, volume 47, 2025. URLhttps://escholarship.org/uc/item/1jd4n5hf
2025
-
[8]
John H. Flavell. Metacognition and cognitive monitoring: A new area of cognitive-developmental inquiry. American Psychologist, 34(10):906–911, 1979
1979
-
[9]
Explaining and Harnessing Adversarial Examples
Ian J. Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples. InInternational Conference on Learning Representations (ICLR), 2015. URL https://arxiv. org/abs/1412.6572
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
Farrar, Straus and Giroux, 2011
Daniel Kahneman.Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011
2011
-
[11]
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks
Brenden Lake and Marco Baroni. Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks. InProceedings of the 35th International Conference on Machine Learning, pages 2873–2882. PMLR, 2018
2018
-
[12]
Richard Landis and Gary G
J. Richard Landis and Gary G. Koch. The measurement of observer agreement for categorical data. Biometrics, 33(1):159–174, 1977
1977
-
[13]
Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857, 2022
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models.Advances in Neural Information Processing Systems, 35:3843–3857, 2022
2022
-
[14]
Rouge: A package for automatic evaluation of summaries
Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. InText Summarization Branches Out, pages 74–81, 2004
2004
-
[15]
Thomas McCoy, Ellie Pavlick, and Tal Linzen
R. Thomas McCoy, Ellie Pavlick, and Tal Linzen. Right for the wrong reasons: Diagnosing syntactic heuristics in natural language inference. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3428–3448, 2019. 10
2019
-
[16]
Thomas McCoy, Shunyu Yao, Dan Friedman, Mathew D
R. Thomas McCoy, Shunyu Yao, Dan Friedman, Mathew D. Hardy, and Thomas L. Griffiths. Embers of autoregression show how large language models are shaped by the problem they are trained to solve. Proceedings of the National Academy of Sciences, 121(41):e2322420121, 2024
2024
-
[17]
Simon.Human Problem Solving
Allen Newell and Herbert A. Simon.Human Problem Solving. Prentice-Hall, Englewood Cliffs, NJ, 1972
1972
-
[18]
Payne, James R
John W. Payne, James R. Bettman, and Eric J. Johnson. Adaptive strategy selection in decision making. Journal of Experimental Psychology: Learning, Memory, and Cognition, 14(3):534–552, 1988
1988
-
[19]
Quantifying language models’ sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting. In International Conference on Learning Representations, 2024
2024
-
[20]
Siegler.Emerging Minds: The Process of Change in Children’s Thinking
Robert S. Siegler.Emerging Minds: The Process of Change in Children’s Thinking. Oxford University Press, 1996
1996
-
[21]
Tomer Ullman. The illusion-illusion: Vision language models see illusions where there are none.arXiv preprint arXiv:2412.18613, 2024
-
[22]
Holyoak, and Hongjing Lu
Taylor Webb, Keith J. Holyoak, and Hongjing Lu. Emergent analogical reasoning in large language models. Nature Human Behaviour, 7(9):1526–1541, 2023
2023
-
[23]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
2022
-
[24]
Reasoning or memorization? unreliable results of reinforcement learning due to data contamination
Mingqi Wu, Zhihao Zhang, Qiaole Dong, Zhiheng Xi, Jun Zhao, Senjie Jin, Xiaoran Fan, Yuhao Zhou, Huijie Lv, Ming Zhang, Yanwei Fu, Qin Liu, Songyang Zhang, and Qi Zhang. Reasoning or memorization? unreliable results of reinforcement learning due to data contamination. InProceedings of the AAAI Conference on Artificial Intelligence, 2026
2026
-
[25]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Advances in Neural Information Processing Systems, 36:11809–11822, 2023
2023
-
[26]
I can be underwater for 10 minutes using no type of equipment or air pockets!
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800, 2019. A Full stimulus set The 30 matched riddle pairs used in Experiments 1 and 2 are shown in Table 1. Condition A items a...
2019
-
[27]
(<strategy>) <canonical answer>
-
[28]
Model response: <model’s response> 20
(<strategy>) <alternative 1> ... Model response: <model’s response> 20
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.