Smaller Models, Unexpected Costs: Trade-offs in LLM Quantization for Automated Program Repair
Pith reviewed 2026-06-26 03:07 UTC · model grok-4.3
The pith
Base and quantized LLMs repair different sets of problems with little overlap while achieving comparable success rates on automated program repair tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
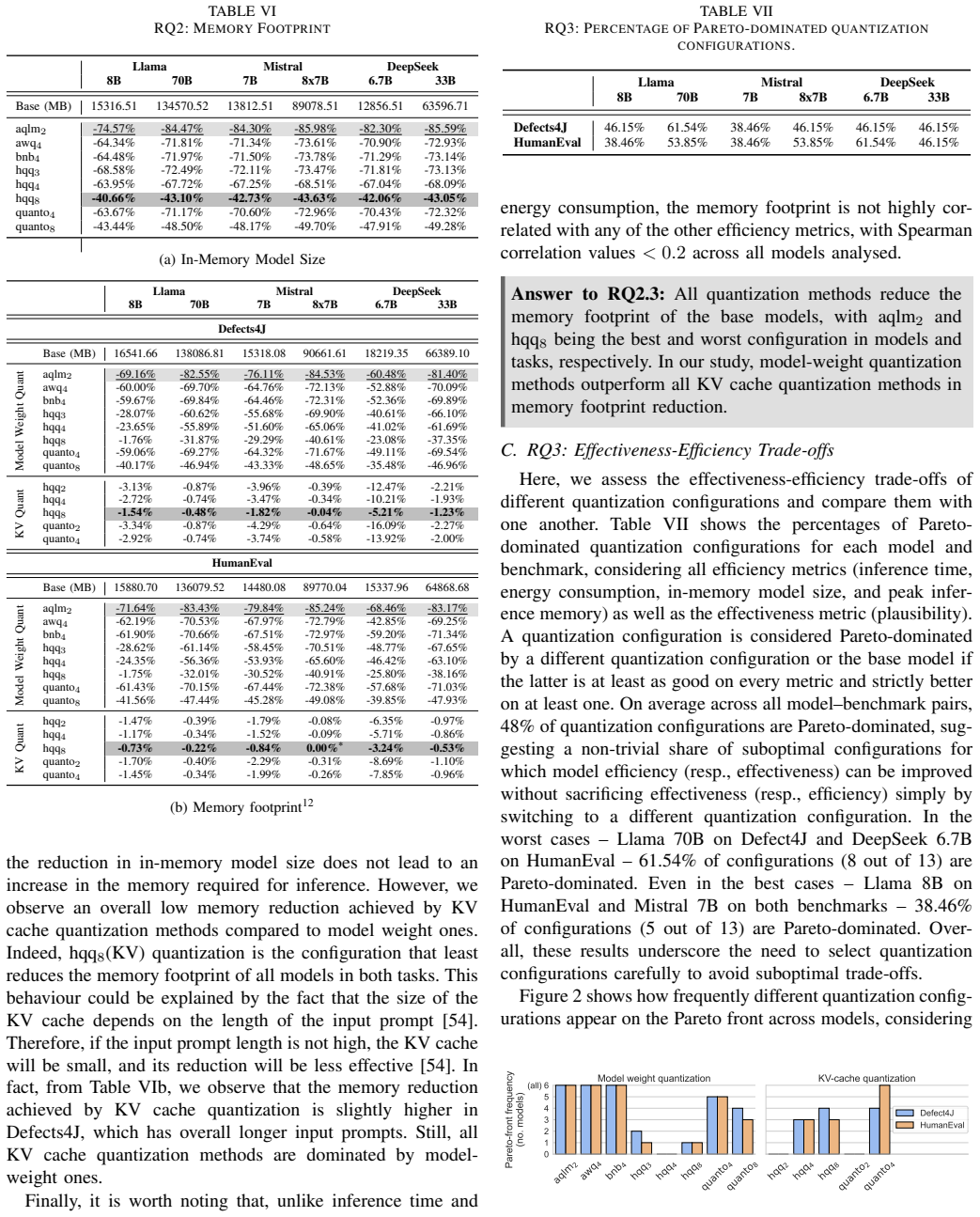
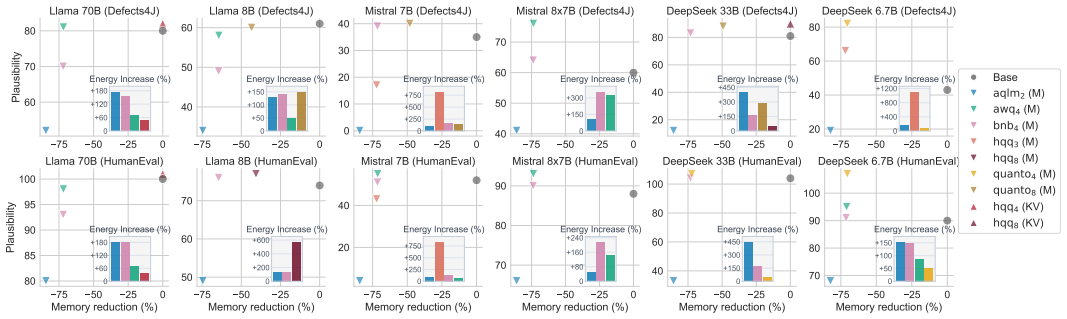
Base and quantized models can provide different sets of repaired problems with little overlap, while retaining a comparable number of repaired problems. Although quantization successfully reduces memory footprints by up to 85%, it increases both inference time and energy consumption, which we attribute to suboptimal hardware utilization. Our Pareto trade-off analysis shows that 48% of the configurations evaluated are strictly dominated by alternatives. Rather than identifying a superior quantization method, our findings highlight that the trade-offs between effectiveness, memory footprint, and energy efficiency are sensitive to the underlying model architecture and the complexity of the task
What carries the argument
Empirical comparison of 13 quantization configurations (varying bit-widths, methods, and weight/KV-cache targets) on six LLMs using HumanEval-Java and Defects4J benchmarks, tracking repair overlap plus memory, time, and energy metrics.
If this is right
- Low overlap in repaired problems means different quantization choices can cover distinct issues even when total counts are similar.
- Memory savings are consistent, but any deployment decision must account for the measured increases in time and energy.
- 48 percent of configurations being strictly dominated implies that many quantization choices can be eliminated without loss on the three-way trade-off surface.
- Sensitivity to model architecture and task complexity means no universal best quantization method exists; selection must be done per model and per domain.
Where Pith is reading between the lines
- Combining outputs from multiple lightly quantized models could increase overall repair coverage beyond what a single full-precision model achieves.
- The observed time and energy penalties might shrink on hardware with native low-precision support, suggesting a hardware-software co-design opportunity.
- If benchmarks under-represent very large or multi-file repairs, the reported overlap and cost patterns could shift for industrial-scale tasks.
Load-bearing premise
The increase in inference time and energy stems from suboptimal hardware utilization across the tested setups, and the two chosen benchmarks adequately represent real program repair tasks.
What would settle it
Direct measurement of hardware utilization metrics such as GPU occupancy or kernel efficiency during quantized inference on the same hardware, or evaluation on a third benchmark with substantially different problem sizes or languages.
Figures
read the original abstract
Language Models (LLMs) are powerful toolsand have been increasingly adopted for complex software engineering tasks. As the number of parameters increases, results can often be improved, but this also imposes substantialmemory requirements. While quantization effectively reduces thememory footprint, its overall impact is often summarized onlyby benchmark scores, which mask changes in model behaviorand non-functional overheads. In this work, we conduct anempirical evaluation of LLM quantization using AutomatedProgram Repair (APR), a complex task in software engineering.We analyze 13 quantization configurations spanning differentbit-widths, methods, and target components (weights and KVcache) across six representative LLMs, evaluated on two APRbenchmarks (HumanEval-Java and Defects4J). Our findings reveal that base and quantized models can provide different sets of repaired problems with little overlap, whileretaining a comparable number of repaired problems. Althoughquantization successfully reduces memory footprints by up to85%, it increases both inference time and energy consumption,which we attribute to suboptimal hardware utilization. OurPareto trade-off analysis shows that 48% of the configurationsevaluated are strictly dominated by alternatives. Rather thanidentifying a superior quantization method, our findings highlightthat the trade-offs between effectiveness, memory footprint,and energy efficiency are sensitive to the underlying modelarchitecture and the complexity of the task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study of LLM quantization for automated program repair (APR), evaluating 13 configurations (varying bit-widths, methods, and targets like weights/KV cache) across six LLMs on HumanEval-Java and Defects4J. Key claims include: base and quantized models repair comparable numbers of problems but with little overlap in the specific problems solved; quantization cuts memory by up to 85% but raises inference time and energy (attributed to suboptimal hardware utilization); 48% of configurations are strictly Pareto-dominated; and trade-offs are sensitive to model architecture and task complexity.
Significance. If the measurements hold, the work is significant for demonstrating that quantization in SE tasks like APR produces non-obvious behavioral shifts (different repair sets) and counter-intuitive efficiency costs, beyond simple accuracy-vs-memory summaries. The multi-model, multi-benchmark design and Pareto analysis provide concrete guidance for practitioners choosing quantized models under resource constraints.
major comments (2)
- [Abstract] Abstract and §5 (or wherever the attribution appears): the central claim that increased inference time and energy 'we attribute to suboptimal hardware utilization' is load-bearing for the trade-off and 'no superior method' conclusions, yet the manuscript provides no direct supporting data such as GPU utilization counters, SM occupancy, memory-bandwidth traces, or kernel-level comparisons that would distinguish this from dequantization overhead, slower quantized GEMM kernels, or batch-size/runtime effects.
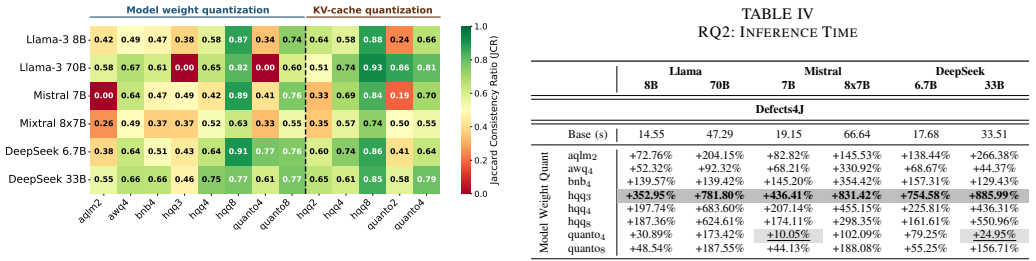
- [§4] §4 (results on repaired problems): the claim of 'different sets of repaired problems with little overlap' while 'retaining a comparable number' is a core empirical finding, but the text should specify the exact overlap metric (e.g., Jaccard index per model pair), whether it is aggregated across all problems or per-benchmark, and include variance or statistical tests to support 'comparable number' given potential run-to-run stochasticity in APR.
minor comments (2)
- [Abstract] Abstract: 'toolsand' and 'substantialmemory' are missing spaces; 'results can often be improved' should be clarified as referring to larger models.
- [§3] The manuscript should explicitly state the exact exclusion rules, number of runs per configuration, and whether error bars or confidence intervals are shown for time/energy/memory measurements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our empirical study of LLM quantization for APR. We address each major comment below, proposing revisions to improve clarity and rigor where the comments identify gaps in the current presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract and §5 (or wherever the attribution appears): the central claim that increased inference time and energy 'we attribute to suboptimal hardware utilization' is load-bearing for the trade-off and 'no superior method' conclusions, yet the manuscript provides no direct supporting data such as GPU utilization counters, SM occupancy, memory-bandwidth traces, or kernel-level comparisons that would distinguish this from dequantization overhead, slower quantized GEMM kernels, or batch-size/runtime effects.
Authors: We agree that the specific attribution to suboptimal hardware utilization lacks direct supporting measurements in the manuscript. This claim is not essential to the core empirical findings on memory reduction, increased time/energy, and Pareto dominance. In the revised version we will remove the attribution from the abstract and §5, replacing it with a neutral statement that the observed increases may stem from implementation factors including dequantization overhead or kernel efficiency, without asserting a particular cause. This revision preserves the reported measurements while avoiding an unsupported causal claim. revision: yes
-
Referee: [§4] §4 (results on repaired problems): the claim of 'different sets of repaired problems with little overlap' while 'retaining a comparable number' is a core empirical finding, but the text should specify the exact overlap metric (e.g., Jaccard index per model pair), whether it is aggregated across all problems or per-benchmark, and include variance or statistical tests to support 'comparable number' given potential run-to-run stochasticity in APR.
Authors: We accept that the overlap claim would benefit from explicit metrics and consideration of stochasticity. The revised manuscript will report the Jaccard index computed on the sets of repaired problems for each model pair (both per-benchmark and aggregated), and will include standard deviations across the three independent runs we performed for each configuration to quantify variability in the number of repaired problems. We will also add a brief note on the implications of any observed variance for the comparability claim. revision: yes
Circularity Check
No circularity: purely empirical measurements
full rationale
The paper reports direct experimental results from running 13 quantization configurations on six LLMs across two APR benchmarks. All reported outcomes (memory reduction up to 85%, changes in repaired problems, inference time, energy) are measured quantities, not derived via equations or predictions that reduce to fitted parameters. The attribution sentence is an interpretive remark on observed data, not a load-bearing derivation or self-referential definition. No equations, fitted inputs called predictions, or self-citation chains appear in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Large language models for software engineering: A systematic literature review
X. Hou et al. “Large language models for software engineering: A systematic literature review.” In:ACM Transactions on Software Engineering and Methodology33.8 (2024), pp. 1–79
2024
-
[2]
Large language models for software engineering: Survey and open problems
A. Fan et al. “Large language models for software engineering: Survey and open problems.” In:2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE). IEEE. 2023, pp. 31–53
2023
-
[3]
A Survey on Efficient Inference for Large Language Models
Z. Zhou et al. “A survey on efficient inference for large language models.” In:arXiv preprint arXiv:2404.14294(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
A survey of quantization methods for efficient neural network inference
A. Gholami et al. “A survey of quantization methods for efficient neural network inference.” In:Low-power computer vision. Chapman and Hall/CRC, 2022, pp. 291–326
2022
-
[5]
E. L. Melin, A. J. Torek, N. U. Eisty, and C. Kennington.Precision or Peril: Evaluating Code Quality from Quantized Large Language Models. 2024. arXiv: 2411.10656[cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Is Quantization a Deal-Breaker? Empirical Insights from Large Code Models
S. Afrin, B. Xu, and A. Mastropaolo. “Is Quantization a Deal-Breaker? Empirical Insights from Large Code Models.” In:2025 IEEE Interna- tional Conference on Software Maintenance and Evolution (ICSME). IEEE Computer Society, 2025, pp. 1–13
2025
-
[7]
Evaluating Quantized Large Language Models for Code Generation on Low-Resource Language Benchmarks
E. Nyamsuren. “Evaluating Quantized Large Language Models for Code Generation on Low-Resource Language Benchmarks.” In:Jour- nal of Computer Languages84 (2025), p. 101351
2025
-
[8]
R. Gong et al.LLMC: Benchmarking Large Language Model Quanti- zation with a Versatile Compression Toolkit. 2024. arXiv: 2405.06001 [cs]
-
[9]
Shi and Y
T. Shi and Y . Ding.Systematic Characterization of LLM Quantization: A Performance, Energy, and Quality Perspective. 2025. arXiv: 2508. 16712[cs]
2025
-
[10]
Towards Greener yet Powerful Code Generation via Quantization: An Empirical Study
X. Wei et al. “Towards Greener yet Powerful Code Generation via Quantization: An Empirical Study.” In:Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, 2023, pp. 224–236
2023
-
[11]
A. Giagnorio, A. Mastropaolo, S. Afrin, M. D. Penta, and G. Bavota. Quantizing Large Language Models for Code Generation: A Differen- tiated Replication. 2025. arXiv: 2503.07103[cs]
- [12]
-
[13]
N. Alizadeh, B. Belchev, N. Saurabh, P. Kelbert, and F. Castor. Language Models in Software Development Tasks: An Experimental Analysis of Energy and Accuracy. 2025. arXiv: 2412.00329[cs]
-
[14]
Wang et al.Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview
Y . Wang et al.Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview. 2024. arXiv: 2409.11650[cs]
-
[15]
On the Com- pression of Language Models for Code: An Empirical Study on CodeBERT
G. d’Aloisio, L. Traini, F. Sarro, and A. Di Marco. “On the Com- pression of Language Models for Code: An Empirical Study on CodeBERT.” In:2025 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). 2025, pp. 12–23
2025
-
[16]
Liu et al.Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models
R. Liu et al.Quantization Hurts Reasoning? An Empirical Study on Quantized Reasoning Models. 2025. arXiv: 2504.04823[cs]
-
[17]
A Comprehensive Study on Quanti- zation Techniques for Large Language Models
J. Lang, Z. Guo, and S. Huang. “A Comprehensive Study on Quanti- zation Techniques for Large Language Models.” In:2024 4th Interna- tional Conference on Artificial Intelligence, Robotics, and Communi- cation (ICAIRC). 2024, pp. 224–231
2024
-
[18]
SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
G. Xiao et al. “SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models.” In:Proceedings of the 40th International Conference on Machine Learning. PMLR, 2023, pp. 38087–38099
2023
-
[19]
Egiazarian et al.Extreme Compression of Large Language Models via Additive Quantization
V . Egiazarian et al.Extreme Compression of Large Language Models via Additive Quantization. 2024. arXiv: 2401.06118[cs]
-
[20]
Fp4-quantization: Lossless 4bit quantization for large language models
J. Wang, H. Liu, D. Feng, J. Ding, and B. Ding. “Fp4-quantization: Lossless 4bit quantization for large language models.” In:2024 IEEE International Conference on Joint Cloud Computing (JCC). IEEE. 2024, pp. 61–67
2024
-
[21]
Lossless and near-lossless compression for foundation models
M. Hershcovitch et al. “Lossless and near-lossless compression for foundation models.” In:arXiv preprint arXiv:2404.15198(2024)
-
[22]
Kamal and D
M. Kamal and D. A. Talbert.Downsized and Compromised?: Assessing the Faithfulness of Model Compression. 2025. arXiv: 2510 . 06125 [cs]
2025
-
[23]
J. Lin, C. Gan, and S. Han.Defensive Quantization: When Efficiency Meets Robustness. 2019. arXiv: 1904.08444[cs]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[24]
S. Fang, W. Ding, A. Mastropaolo, and B. Xu.Smaller = Weaker? Benchmarking Robustness of Quantized LLMs in Code Generation
- [25]
-
[26]
Lossless AI: Toward Guaranteeing Consistency between Inferences Before and After Quantization via Knowledge Distillation
T. Okuno, Y . Nakata, Y . Ishii, S. Tsukizawa, and K. City. “Lossless AI: Toward Guaranteeing Consistency between Inferences Before and After Quantization via Knowledge Distillation.” In: ()
-
[27]
Towards Understanding Model Quantization for Reliable Deep Neural Network Deployment
Q. Hu et al. “Towards Understanding Model Quantization for Reliable Deep Neural Network Deployment.” In:2023 IEEE/ACM 2nd Inter- national Conference on AI Engineering – Software Engineering for AI (CAIN). IEEE, 2023, pp. 56–67
2023
-
[28]
Li et al.Efficiency Meets Fidelity: A Novel Quantization Framework for Stable Diffusion
S. Li et al.Efficiency Meets Fidelity: A Novel Quantization Framework for Stable Diffusion. 2025. arXiv: 2412.06661[cs]
-
[29]
AWQ: Activation-aware Weight Quantization for On- Device LLM Compression and Acceleration
J. Lin et al. “AWQ: Activation-aware Weight Quantization for On- Device LLM Compression and Acceleration.” In:GetMobile: Mobile Computing and Communications28.4 (2025), pp. 12–17
2025
-
[30]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
T. Dettmers, M. Lewis, Y . Belkada, and L. Zettlemoyer.LLM.Int8(): 8-Bit Matrix Multiplication for Transformers at Scale. 2022. arXiv: 2208.07339[cs]
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
Badri et al.Half-Quadratic Quantization of Large Machine Learn- ing Models
A. Badri et al.Half-Quadratic Quantization of Large Machine Learn- ing Models. 2023
2023
-
[32]
Hugging Face.Optimum Quanto. 2024
2024
-
[33]
Guo et al.DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence
D. Guo et al.DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence. 2024. arXiv: 2401 . 14196[cs]
2024
-
[34]
A. Dubey et al.The Llama 3 Herd of Models. 2024. arXiv: 2407.21783 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
A. Q. Jiang et al.Mistral 7B. 2023. arXiv: 2310.06825[cs]
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
A. Q. Jiang et al.Mixtral of Experts. 2024. arXiv: 2401.04088[cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Impact of Code Language Models on Automated Program Repair
N. Jiang, K. Liu, T. Lutellier, and L. Tan. “Impact of Code Language Models on Automated Program Repair.” In:Proceedings of the 45th International Conference on Software Engineering. IEEE Press, 2023, pp. 1430–1442
2023
-
[38]
Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs
R. Just, D. Jalali, and M. D. Ernst. “Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs.” In: International Symposium on Software Testing and Analysis (ISSTA). ACM, 2014, pp. 437–440
2014
-
[39]
Xiang et al.How Far Can We Go with Practical Function-Level Program Repair?2024
J. Xiang et al.How Far Can We Go with Practical Function-Level Program Repair?2024. arXiv: 2404.12833[cs]
-
[40]
Vallecillos-Ruiz, M
F. Vallecillos-Ruiz, M. Hort, and L. Moonen.Wisdom and Delusion of LLM Ensembles for Code Generation and Repair. 2025. arXiv: 2510. 21513[cs.SE]
2025
-
[41]
RepairLLaMA: Efficient Rep- resentations and Fine-Tuned Adapters for Program Repair
A. Silva, S. Fang, and M. Monperrus. “RepairLLaMA: Efficient Rep- resentations and Fine-Tuned Adapters for Program Repair.” In:IEEE Transactions on Software Engineering51.8 (2025), pp. 2366–2380
2025
-
[42]
The Art of Repair: Optimizing Iterative Program Repair with Instruction-Tuned Models
F. Vallecillos Ruiz, M. Hort, and L. Moonen. “The Art of Repair: Optimizing Iterative Program Repair with Instruction-Tuned Models.” In:Proceedings of the 29th International Conference on Evaluation and Assessment in Software Engineering. Association for Computing Machinery, 2025, pp. 500–511
2025
-
[43]
AI-driven Java Per- formance Testing: Balancing Result Quality with Testing Time
L. Traini, F. Di Menna, and V . Cortellessa. “AI-driven Java Per- formance Testing: Balancing Result Quality with Testing Time.” In: Proceedings of the 39th IEEE/ACM International Conference on Au- tomated Software Engineering. Association for Computing Machinery, 2024, pp. 443–454
2024
-
[44]
Automated Generation and Evaluation of JMH Microbenchmark Suites From Unit Tests
M. Jangali, Y . Tang, N. Alexandersson, et al. “Automated Generation and Evaluation of JMH Microbenchmark Suites From Unit Tests.” In: IEEE Transactions on Software Engineering49.4 (2023), pp. 1704– 1725
2023
-
[45]
Faster or Slower? Performance Mystery of Python Idioms Unveiled with Empirical Evidence
Z. Zhang, Z. Xing, X. Xia, et al. “Faster or Slower? Performance Mystery of Python Idioms Unveiled with Empirical Evidence.” In: Proceedings of the 45th International Conference on Software Engi- neering. IEEE Press, 2023, pp. 1495–1507
2023
-
[46]
Dynamically Reconfiguring Software Microbenchmarks: Reducing Execution Time without Sacri- ficing Result Quality
C. Laaber, S. W ¨ursten, H. C. Gall, et al. “Dynamically Reconfiguring Software Microbenchmarks: Reducing Execution Time without Sacri- ficing Result Quality.” In:Proceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. Association for Computing Machinery, 2020, pp. 989–1001
2020
-
[47]
Rigorous Benchmarking in Reasonable Time
T. Kalibera and R. Jones. “Rigorous Benchmarking in Reasonable Time.” In:Proceedings of the 2013 International Symposium on Memory Management. Association for Computing Machinery, 2013, pp. 63–74
2013
-
[48]
Kalibera and R
T. Kalibera and R. Jones.Quantifying Performance Changes with Effect Size Confidence Intervals. Technical Report 4–12. University of Kent, 2012, p. 55
2012
-
[49]
Wilcoxon signed-rank test
R. F. Woolson. “Wilcoxon signed-rank test.” In:Encyclopedia of Biostatistics8 (2005)
2005
-
[50]
How Software Refactoring Impacts Execution Time
L. Traini, D. Di Pompeo, M. Tucci, et al. “How Software Refactoring Impacts Execution Time.” In:ACM Trans. Softw. Eng. Methodol.31.2 (2021)
2021
-
[51]
Search based software engineering: Techniques, taxonomy, tutorial
M. Harman, P. McMinn, J. T. De Souza, and S. Yoo. “Search based software engineering: Techniques, taxonomy, tutorial.” In:LASER Summer School on Software Engineering. Springer, 2008, pp. 1–59
2008
-
[52]
Compressing large-scale transformer-based models: A case study on bert
P. Ganesh, Y . Chen, X. Lou, et al. “Compressing large-scale transformer-based models: A case study on bert.” In:Transactions of the Association for Computational Linguistics9 (2021), pp. 1061– 1080
2021
-
[53]
An efficient quantized GEMV implementation for large language models inference with matrix core: Y . Zhang et al
Y . Zhang, L. Lu, R. Zhao, Y . Guo, and Z. Yang. “An efficient quantized GEMV implementation for large language models inference with matrix core: Y . Zhang et al.” In:The Journal of Supercomputing 81.3 (2025), p. 496
2025
-
[54]
The proof and measurement of association between two things
C. Spearman. “The proof and measurement of association between two things.” In: (1961)
1961
-
[55]
Kvquant: Towards 10 million context length llm inference with kv cache quantization
C. Hooper et al. “Kvquant: Towards 10 million context length llm inference with kv cache quantization.” In:Advances in Neural Infor- mation Processing Systems37 (2024), pp. 1270–1303
2024
-
[56]
Automated Patch Correctness Assessment: How Far Are We?
S. Wang et al. “Automated Patch Correctness Assessment: How Far Are We?” In:35th IEEE/ACM International Conference on Automated Software Engineering. ACM, 2020, pp. 968–980
2020
-
[57]
Explainable Automated Debugging via Large Language Model-Driven Scientific Debugging
S. Kang, B. Chen, S. Yoo, and J.-G. Lou. “Explainable Automated Debugging via Large Language Model-Driven Scientific Debugging.” In:Empirical Software Engineering30.2 (2024), p. 45
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.