BetXplain: An Explanation-Annotated Dataset for Detecting Manipulative Betting Advertisements on Social Media
Pith reviewed 2026-06-30 09:34 UTC · model grok-4.3
The pith
A new dataset of social media betting ads provides both manipulative labels and human explanations for each annotation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a dataset of betting-related advertisements from Instagram and Reddit that have been manually annotated for manipulative and deceptive advertising practices, together with human-provided explanations describing the reasoning for each annotation, to enable research into explainable detection approaches while also analyzing persuasive strategies and their potential mental health effects.
What carries the argument
The explanation-annotated dataset, which supplies both classification labels and the reasoning for those labels so that models can be trained to detect and justify findings about manipulative betting ads.
If this is right
- Automated classifiers can be trained directly on the labeled advertisements to identify manipulative content.
- Explainable AI methods can use the provided human explanations to generate justifications for detections.
- Analysis of the ads reveals recurring persuasive tactics used in betting promotions.
- Browser plugins can be built to warn users when they encounter flagged advertisements.
- Web crawlers can be developed to help regulatory authorities monitor and detect such promotions at scale.
Where Pith is reading between the lines
- The same annotation approach with explanations could be applied to manipulative advertising in other product categories beyond betting.
- Patterns in the explanations might be studied to identify which tactics most affect specific user groups.
- The dataset could serve as a starting point for longitudinal tracking of how betting ad strategies evolve over time on the same platforms.
Load-bearing premise
The manual annotations and the explanations given for them are reliable and consistent enough to train and evaluate automated detection systems.
What would settle it
A classifier trained on the dataset that achieves accuracy no higher than random guessing when tested on an independently collected set of new betting advertisements would show the annotations do not support reliable detection.
Figures
read the original abstract
The promotion of betting applications on social media platforms has increased significantly in recent years. Many of these advertisements use persuasive techniques that may mislead users, encourage risky behavior, and potentially influence users' mental well-being. However, research on the automated detection of manipulative and deceptive betting advertisements remains limited due to the lack of publicly available annotated datasets. In this work, we introduce a new dataset of betting-related advertisements collected from two widely used social media platforms, Instagram and Reddit. The advertisements were manually annotated for manipulative and deceptive advertising practices. In addition to classification labels, the dataset includes human-provided explanations that describe the reasoning behind each annotation, enabling research into explainable approaches to detecting manipulative advertising. Furthermore, we analyze the strategies commonly used in betting advertisements and examine how these persuasive tactics may impact users' mental health. The proposed framework can also enable practical applications such as browser plugins that warn users about manipulative betting advertisements and automated web crawlers that help regulatory authorities monitor and detect such promotions online.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BetXplain, a new dataset of betting-related advertisements collected from Instagram and Reddit. Advertisements are manually annotated for manipulative and deceptive practices, with human-provided explanations for each label. The work also analyzes common persuasive strategies in such ads and their potential effects on users' mental health, with the goal of supporting explainable AI research and applications such as warning plugins or regulatory crawlers.
Significance. If the annotations are shown to be reliable, the dataset would address a documented gap in public resources for automated detection of manipulative betting content on social media. The addition of human explanations is a positive feature that directly supports research on explainable detection methods, and the mental-health analysis angle broadens potential impact beyond pure classification.
major comments (2)
- [Data collection and annotation description] The manuscript provides no information on the annotation protocol, number of annotators per item, inter-annotator agreement scores, adjudication procedure, or annotation guidelines. These details are required to evaluate whether the labels constitute stable ground truth suitable for training detection models or for benchmarking explanation methods.
- [Dataset presentation] No dataset statistics (total size, label distribution, platform breakdown, or example annotations with explanations) are reported. Without these, it is impossible to assess scale, balance, or representativeness, which are load-bearing for the claim that the resource enables reproducible research.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence summarizing dataset scale and any reliability metrics.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We agree that the manuscript requires additional information on the annotation methodology and dataset characteristics to support claims about reliability and reproducibility. We will revise the paper to address both major comments.
read point-by-point responses
-
Referee: [Data collection and annotation description] The manuscript provides no information on the annotation protocol, number of annotators per item, inter-annotator agreement scores, adjudication procedure, or annotation guidelines. These details are required to evaluate whether the labels constitute stable ground truth suitable for training detection models or for benchmarking explanation methods.
Authors: We acknowledge that these methodological details were omitted from the submitted manuscript. In the revised version, we will add a new section detailing the full annotation protocol. This will include the number of annotators assigned per item, inter-annotator agreement scores (e.g., Cohen's kappa or Fleiss' kappa), the adjudication procedure for resolving disagreements, and the complete annotation guidelines provided to annotators. These additions will allow evaluation of label stability. revision: yes
-
Referee: [Dataset presentation] No dataset statistics (total size, label distribution, platform breakdown, or example annotations with explanations) are reported. Without these, it is impossible to assess scale, balance, or representativeness, which are load-bearing for the claim that the resource enables reproducible research.
Authors: We agree that quantitative dataset characteristics are essential. The revised manuscript will include a dedicated 'Dataset Statistics' section reporting total size, label distribution across manipulative/deceptive categories, platform breakdown (Instagram vs. Reddit), and several example annotations that include both the classification labels and the accompanying human explanations. These will be presented in a table or figure to demonstrate scale and representativeness. revision: yes
Circularity Check
Dataset release paper contains no derivation chain or fitted predictions
full rationale
This is a dataset paper whose central contribution is the release of manually annotated betting ads from Instagram and Reddit, plus human explanations. No equations, models, or quantitative predictions are claimed. The abstract and described content contain no self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations. Annotation reliability is not quantified in the provided text, but absence of reliability metrics is a reproducibility concern, not a circularity reduction. The paper is self-contained as a resource contribution with no internal derivation that reduces to its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InCompanion Proceedings of the ACM on Web Conference 2025, pages 1885–1889
Mental health and relations: Detection of mental health disorders related to relationship issues through reddit posts. InCompanion Proceedings of the ACM on Web Conference 2025, pages 1885–1889. Government of India. 1867. The public gambling act,
2025
-
[2]
https://www.indiacode.nic.in/handle/ 123456789/2269. Act No. 3 of 1867 regulating gam- bling activities in India. Government of India. 2000. Information technology act, 2000. https://www.meity.gov.in/content/ information-technology-act-2000 . Cyber law addressing digital crimes including online fraud and illegal betting platforms. Government of Kuwait. 19...
2000
-
[3]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Albert: A lite bert for self-supervised learn- ing of language representations.arXiv preprint arXiv:1909.11942. Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. 2020. Bart: Denoising sequence-to-sequence pre-training for nat- ural language generation, translation, and compre...
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[4]
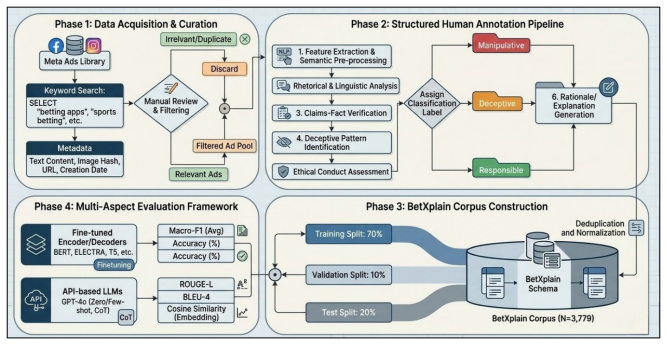
Relevant advertisements asso- ciated with betting applications and services were retrieved using betting-related keywords
Data Collection:Betting-related advertise- ments were collected from public social media platforms, including Instagram and Reddit, us- ing platform search mechanisms and the Meta Ads Library. Relevant advertisements asso- ciated with betting applications and services were retrieved using betting-related keywords
-
[5]
Advertisements con- taining minimal or non-informative text were excluded from the dataset
Data Cleaning:Duplicate advertisements, ir- relevant promotional content, spam entries, and non-betting advertisements were removed during preprocessing. Advertisements con- taining minimal or non-informative text were excluded from the dataset
-
[6]
Text preprocessing was performed while preserv- ing the persuasive and emotional language patterns important for annotation
Data Preprocessing:URLs, usernames, hash- tags, excessive emojis, and formatting arti- facts were normalized where necessary. Text preprocessing was performed while preserv- ing the persuasive and emotional language patterns important for annotation
-
[7]
An- notators also provided concise, human-written explanations of the reasoning behind each as- signed label
Manual Annotation:Each advertisement was independently reviewed and labeled in ac- cordance with the annotation guidelines. An- notators also provided concise, human-written explanations of the reasoning behind each as- signed label
-
[8]
Quality Verification:Annotations were re- viewed for consistency, and disagreements were resolved through collaborative discus- sion before constructing the final dataset
-
[9]
Try your luck,
Dataset Finalization:After quality verifica- tion, duplicate advertisements were removed and the final dataset was partitioned into train, validation, and test splits using stratified sam- pling. F Longformer Ablation Study To justify Longformer’s inclusion despite short me- dian text length, we conducted an ablation study varying the maximum sequence len...
-
[10]
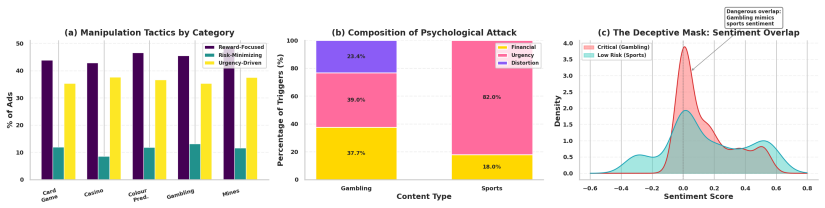
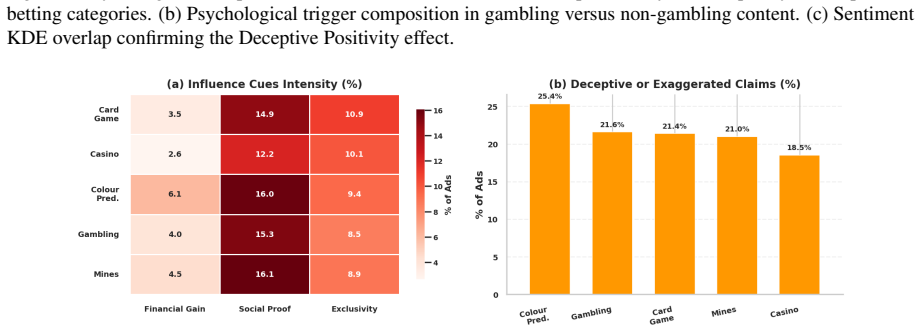
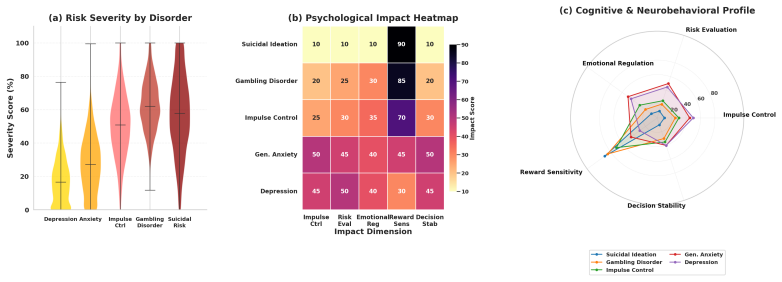
The Chase Phase.Content encourages users to “recover” losses by making further deposits, sustaining engagement through loss-aversion psychology
-
[11]
The Crash.When mathematically inevitable losses occur, the user experiences a rapid de- pletion of both dopamine and serotonin
-
[12]
Jackpot,
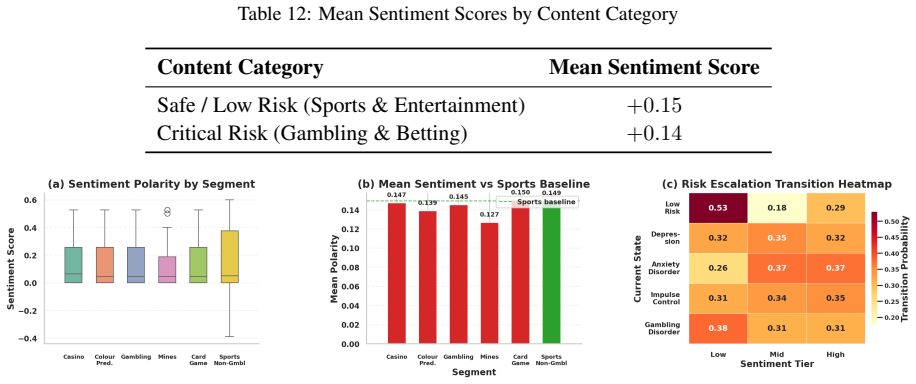
The Danger Zone.This neurochemical crash, combined with the tangible reality of debt or bankruptcy, creates a window of acute sui- cidality. Research indicates that individuals with Gambling Disorder have the highest sui- cide attempt rates among all addiction de- mographics, with estimates reaching up to 20% (Blaszczynski and Nower, 2002). L Visual Evide...
2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.