How Surprising Is Historical Italian to Language Models? Tokenization Tax, Comprehension Tax, and a Simple Mitigation
Pith reviewed 2026-06-26 04:08 UTC · model grok-4.3
The pith
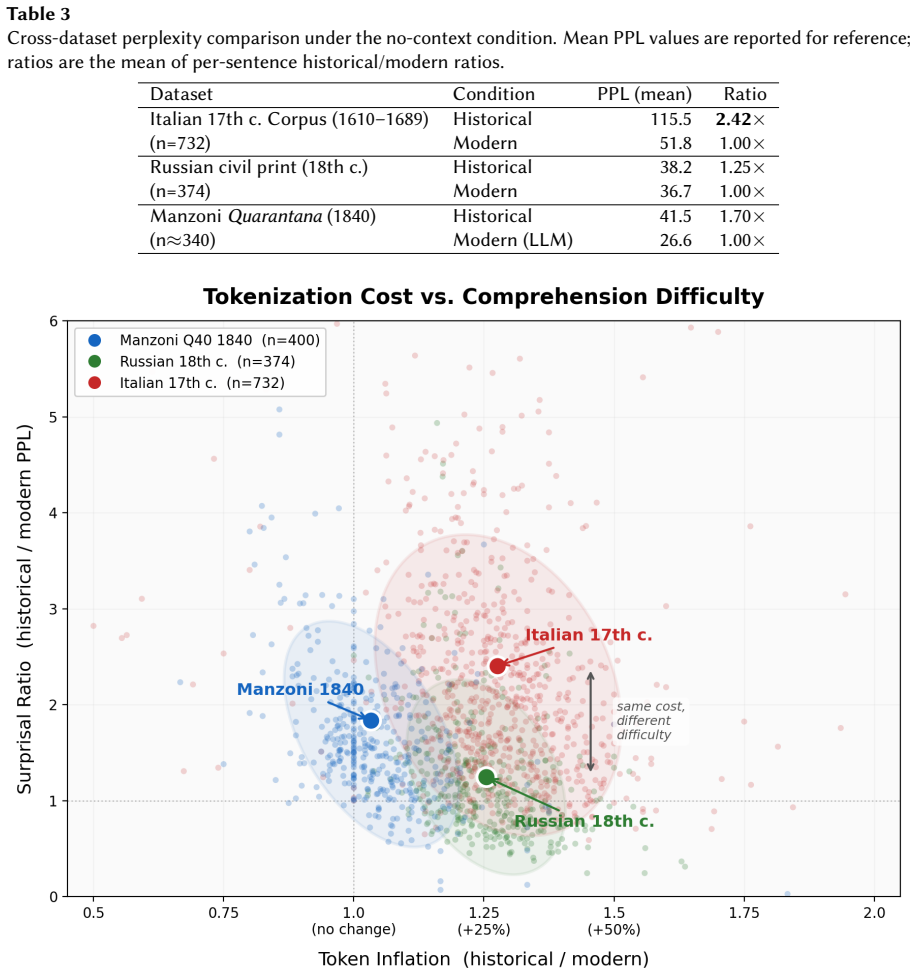
17th-century Italian is 2.4 times more surprising to LLMs than modern Italian, yet embeddings remain robust above 0.85 similarity and a temporal prompt cuts surprisal by 60%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Historical text imposes a consistent encoding tax across languages, but comprehension difficulty varies sharply by era and language, with 17th-century Italian showing 2.4 times higher average surprisal than modern Italian and up to 3.2 times for academic prose, while Russian shows only modest increase; embedding similarity remains robust above 0.85 across all sets, and a simple temporal context prompt reduces historical surprisal by approximately 60%.
What carries the argument
A four-dimensional diagnostic framework that measures tokenization cost, predictive uncertainty (surprisal), semantic robustness via embedding similarity, and context sensitivity.
If this is right
- Tokenization cost is comparable for 17th-century Italian and 18th-century Russian at 25-30% inflation.
- 17th-century Italian shows 2.4 times higher average surprisal than modern Italian, rising to 3.2 times for academic prose.
- Embedding similarity stays above 0.85 across modern, 17th-century Italian, and Russian datasets.
- A minimal temporal context prompt reduces historical surprisal by about 60%.
- Digital libraries can use LLMs for semantic retrieval on historical texts but must adapt generative applications.
Where Pith is reading between the lines
- The same framework could be applied to other historical languages to separate which ones carry mainly tokenization costs versus mainly surprisal costs.
- Libraries might route historical collections to retrieval-first workflows while keeping generative tasks on modern text only.
- Testing whether the 60% surprisal reduction holds when the prompt is translated or when models are fine-tuned on historical data would check the mitigation's generality.
Load-bearing premise
The four-dimensional diagnostic framework cleanly isolates the reported effects without confounding from model-specific tokenizers or from selection bias in the newly curated 17th-century corpus.
What would settle it
Running the same models on the 17th-century Italian corpus but with a different tokenizer family and finding that relative tokenization penalties no longer match the Russian comparison would falsify clean isolation of the encoding tax.
Figures
read the original abstract
Large language models (LLMs) are increasingly critical to digital library workflows, yet their ability to process historical language remains poorly understood. Historical difficulty is typically treated as a monolithic barrier, conflating orthographic variation, linguistic distance, and pretraining exposure. In this paper, we propose a diagnostic framework that decomposes this difficulty into four distinct dimensions: tokenization cost, predictive uncertainty (surprisal), semantic robustness, and context sensitivity. We evaluate this framework on three datasets spanning three centuries: (1) a newly curated corpus of 17th-century Italian texts (1610-1689) digitized from original page images; (2) canonical 19th-century Italian "I Promessi Sposi" serving as a high-exposure control; and (3) 18th-century Russian civil print books as a contrastive orthographic stress test. Our results reveal a distinct dissociation between encoding cost and comprehension. While Russian and early modern Italian incur comparable tokenization penalties (25-30% inflation), their predictive difficulty diverges sharply. 17th-century Italian is on average 2.4 times more surprising than its modern equivalent - with academic prose reaching 3.2 times - whereas Russian shows only a modest increase. But predictive uncertainty does not imply representational degradation: embedding similarity remains robust (> 0.85) across all datasets, confirming that models can represent historical meaning even when generation is unstable. Finally, we demonstrate that a minimal temporal context prompt reduces historical surprisal by approximately 60%, offering a simple, model-agnostic mitigation. These findings suggest that while historical text imposes a consistent encoding tax, digital libraries can safely deploy LLMs for semantic retrieval tasks, provided that generative applications are carefully adapted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a four-dimensional diagnostic framework (tokenization cost, predictive uncertainty/surprisal, semantic robustness via embeddings, context sensitivity) to decompose LLM difficulty with historical language. It evaluates the framework on a newly curated 17th-century Italian corpus (1610-1689), 19th-century Italian control text, and 18th-century Russian texts, reporting comparable tokenization inflation (25-30%) across the non-modern datasets but sharply higher surprisal only for Italian (2.4x overall, 3.2x for academic prose), robust embedding similarity (>0.85), and a simple temporal-context prompt that reduces historical surprisal by ~60%. The central claim is that historical text imposes an encoding tax but not representational degradation, so LLMs can be deployed safely for semantic retrieval tasks in digital libraries while generative uses require adaptation.
Significance. If the reported dissociation holds, the work supplies a practical, model-agnostic framework and mitigation that directly informs digital-library workflows; the curation of the 17th-century corpus and the explicit contrast with Russian orthographic stress provide useful empirical grounding. The finding of preserved embedding similarity despite elevated surprisal is a falsifiable prediction that could guide future retrieval-system design.
major comments (2)
- [Abstract and evaluation description] Abstract and evaluation description: the reported numerical dissociation (25-30% tokenization inflation vs. 2.4x surprisal differential) is computed from the same unspecified modern tokenizer for both metrics; because BPE merges learned on contemporary Italian will systematically affect both token counts and per-token probabilities for 1610-1689 orthography, the claimed clean separation of encoding tax from comprehension tax may be tokenizer-dependent rather than a general linguistic property. This directly weakens the warrant for the deployment recommendation.
- [Abstract and methods] Abstract and methods: no error bars, statistical tests, model versions, or exact computation details are supplied for the four dimensions or the 60% mitigation reduction, leaving the central ratios and the robustness claim (>0.85 embedding similarity) without quantifiable uncertainty; this is load-bearing because the recommendation for safe semantic retrieval rests on the reliability of these point estimates.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and evaluation description] Abstract and evaluation description: the reported numerical dissociation (25-30% tokenization inflation vs. 2.4x surprisal differential) is computed from the same unspecified modern tokenizer for both metrics; because BPE merges learned on contemporary Italian will systematically affect both token counts and per-token probabilities for 1610-1689 orthography, the claimed clean separation of encoding tax from comprehension tax may be tokenizer-dependent rather than a general linguistic property. This directly weakens the warrant for the deployment recommendation.
Authors: We agree that the observed dissociation is measured with a single contemporary tokenizer and is therefore specific to the tokenization behavior of current LLMs. This is the intended and practically relevant setting for the deployment recommendation, as digital-library applications would use exactly such models. The framework is explicitly model-agnostic in its diagnostic structure but evaluated under realistic tokenizer conditions. To address the concern, we will revise the abstract and methods to explicitly state that the separation is tokenizer-conditioned, add a limitations paragraph discussing sensitivity to alternative tokenizers, and note that the Russian contrast still isolates orthographic effects under the same tokenizer. We do not claim the separation is a tokenizer-independent linguistic universal. revision: partial
-
Referee: [Abstract and methods] Abstract and methods: no error bars, statistical tests, model versions, or exact computation details are supplied for the four dimensions or the 60% mitigation reduction, leaving the central ratios and the robustness claim (>0.85 embedding similarity) without quantifiable uncertainty; this is load-bearing because the recommendation for safe semantic retrieval rests on the reliability of these point estimates.
Authors: We accept this criticism. The current manuscript reports point estimates without uncertainty quantification or full computational specifications. In the revision we will (1) specify the exact model versions and tokenizer checkpoints used, (2) report bootstrapped 95% confidence intervals and paired statistical tests for all key ratios (tokenization inflation, surprisal multipliers, embedding cosine similarities, and the 60% mitigation effect), and (3) include a methods subsection with explicit formulas and pseudocode for each metric. These additions will be placed in both the abstract and the main text. revision: yes
Circularity Check
No circularity: direct empirical measurements on held-out corpora
full rationale
The paper reports tokenization inflation, surprisal ratios, embedding cosine similarities, and prompt-based mitigation via direct model evaluations on three fixed datasets (newly curated 17th-c. Italian, 19th-c. control, 18th-c. Russian). No equations, fitted parameters, or self-citations appear in the provided text; the four-dimensional framework is presented as a descriptive decomposition rather than a derived result. Central claims rest on observed numerical dissociations (e.g., comparable tokenization penalties but divergent surprisal) computed from model outputs on held-out text, with no reduction of any reported quantity to a parameter defined by the same data or prior self-work. This matches the default expectation of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Levchenko, Building historical corpora with multimodal LLMs: Epistemic gaps and misreadings in 18th-century russian books, ACH Anthology 3 (2025). doi:10.63744/SKoZVUHQbtE7
-
[2]
M. Levchenko, Evaluating LLMs for historical document OCR: A methodological framework for digital humanities, 2025. doi:10.48550/arXiv.2510.06743.arXiv:2510.06743
work page doi:10.48550/arxiv.2510.06743.arxiv:2510.06743 2025
-
[3]
Smith, An overview of the Tesseract OCR engine, Proceedings of ICDAR (2007)
R. Smith, An overview of the Tesseract OCR engine, Proceedings of ICDAR (2007). doi: 10.1109/ ICDAR.2007.4376991
arXiv 2007
-
[4]
R. Sennrich, B. Haddow, A. Birch, Neural machine translation of rare words with subword units, in: Proceedings of ACL, 2016. doi:10.18653/v1/P16-1162
-
[5]
T. Kudo, J. Richardson, Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing, in: Proceedings of EMNLP (System Demonstrations),
-
[6]
doi:10.18653/v1/D18-2012
work page internal anchor Pith review doi:10.18653/v1/d18-2012 2012
-
[7]
Wegmann, D
A. Wegmann, D. Nguyen, D. Jurgens, Tokenization is sensitive to language variation, in: Findings of the Association for Computational Linguistics: ACL 2025, Association for Computational Linguistics, 2025. URL: https://aclanthology.org/2025.findings-acl.572/
2025
-
[8]
D. Maksymenko, O. Turuta, Tokenization efficiency of current foundational large language models for the ukrainian language, Frontiers in Artificial Intelligence 8 (2025) 1538165. URL: https://doi.org/10.3389/frai.2025.1538165. doi:10.3389/frai.2025.1538165
-
[9]
Hale, A probabilistic earley parser as a psycholinguistic model, in: Proceedings of NAACL, 2001
J. Hale, A probabilistic earley parser as a psycholinguistic model, in: Proceedings of NAACL, 2001
2001
-
[10]
Levy, Expectation-based syntactic comprehension, Cognition 106 (2008) 1126–1177
R. Levy, Expectation-based syntactic comprehension, Cognition 106 (2008) 1126–1177. doi: 10. 1016/j.cognition.2007.05.006
2008
-
[11]
Carlini, F
N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-Voss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson, J. Pope, H. B. McMahan, Extracting training data from large language models, in: USENIX Security Symposium, 2021
2021
-
[12]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, et al., Language models are few-shot learners, in: Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[13]
S. Wu, H. Bao, S. Li, A. Holtzman, J. A. Evans, Mapping overlaps in benchmarks through perplexity in the wild, 2025. URL: https://arxiv.org/abs/2509.23488.arXiv:2509.23488
arXiv 2025
-
[14]
W. L. Hamilton, J. Leskovec, D. Jurafsky, Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change, in: Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Berlin, Germany, 2016, pp. 1489–1501. URL: https://aclanthology.org/P16-1141. doi:10...
-
[15]
Kutuzov, L
A. Kutuzov, L. Øvrelid, T. Szymanski, E. Velldal, Diachronic word embeddings and semantic shifts: a survey, in: Proceedings of the 27th International Conference on Computational Linguistics, Association for Computational Linguistics, Santa Fe, New Mexico, USA, 2018, pp. 1384–1397. URL: https://aclanthology.org/C18-1117
2018
-
[16]
B. Zhao, Z. Brumbaugh, Y. Wang, H. Hajishirzi, N. A. Smith, Set the clock: Temporal alignment of pretrained language models, in: Findings of the Association for Computational Linguistics: ACL 2024, Association for Computational Linguistics, 2024. URL: https://aclanthology.org/2024. findings-acl.892
2024
-
[17]
Levchenko, B
M. Levchenko, B. Nava, E. Russo, Tei encoding as a unified structure for multilingual digital editions: The leggomanzoni case study, Proceedings AIUCD 2025 (2025) 264
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.