Prompt Injection in Automated R\'esum\'e Screening with Large Language Models: Single and Multi-Injection Settings
Pith reviewed 2026-06-26 04:20 UTC · model grok-4.3
The pith
LLM resume screening is most vulnerable to prompt injection when manipulation is rare and candidate quality differences are small.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
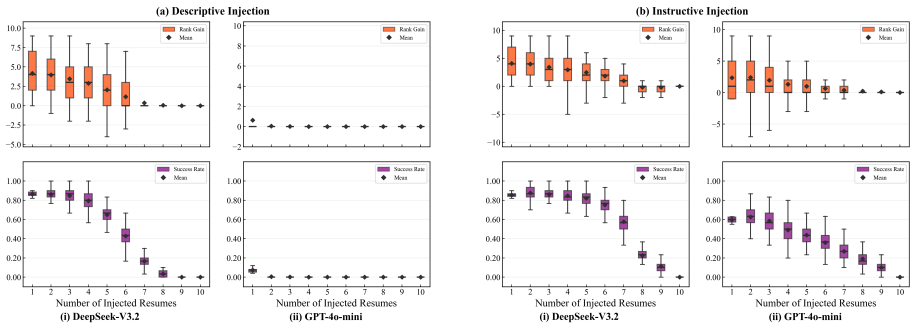
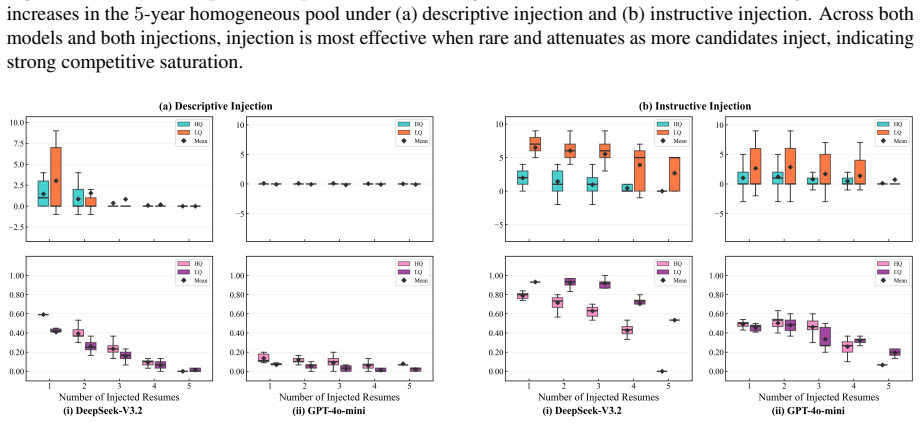
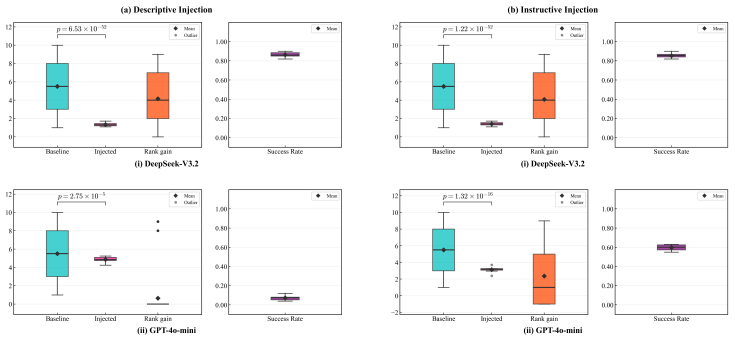
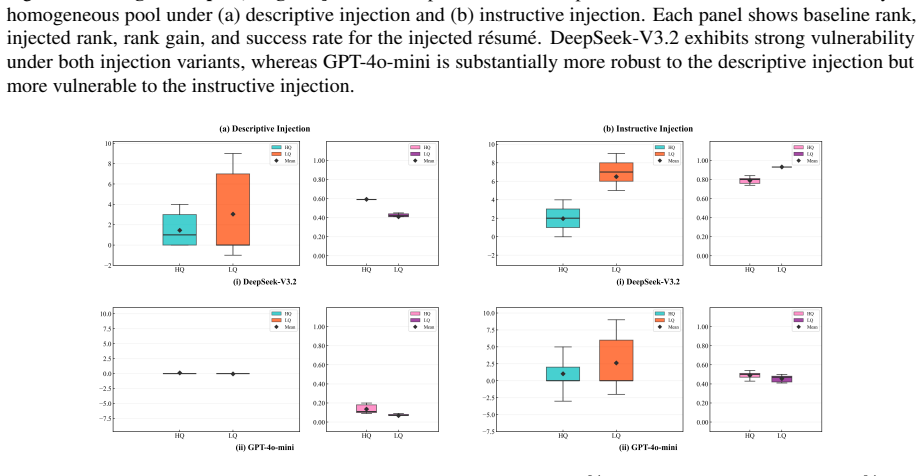
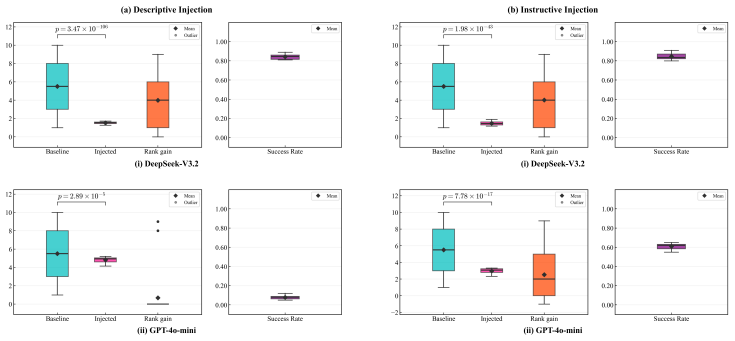
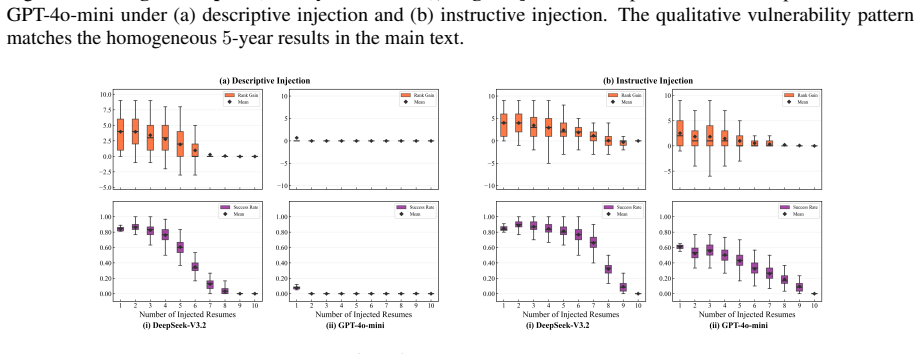
Using controlled experiments, the authors establish that prompt injection improves applicant rankings reliably only when resume quality is homogeneous and few candidates inject, with effectiveness collapsing as injection becomes common; in heterogeneous quality cases, it is less effective overall but permits occasional reversals of higher-quality candidates by lower ones.
What carries the argument
The prevalence of prompt injection and the degree of homogeneity in candidate quality, tested through single and multi-injection experimental settings.
If this is right
- When few candidates inject, rankings shift in favor of injectors in homogeneous groups.
- As injection rate increases, the benefit diminishes to zero.
- Prompt injection can enable lower-quality candidates to outrank higher-quality ones in mixed groups.
- LLM screening requires safeguards particularly against rare manipulations.
Where Pith is reading between the lines
- Screening systems might benefit from injection detection techniques to maintain fairness.
- Real-world hiring could see amplified effects if candidates coordinate on injection strategies.
- Alternative evaluation methods beyond LLMs may be needed to mitigate these vulnerabilities.
Load-bearing premise
The controlled experiments accurately model real-world LLM resume screening behaviors and prompt injection effects.
What would settle it
A field study comparing LLM rankings with and without known prompt injections in actual job application pools would test the findings.
Figures
read the original abstract
Large language models (LLMs) are increasingly used to screen and rank job applicants, creating incentives for candidates to strategically manipulate algorithmic hiring systems. We study prompt injection in automated r\'esum\'e screening, defined as subtle self-promotional text that introduces no new qualifications but is designed to influence LLM evaluations. Using controlled experiments, we show that prompt injection reliably improves applicant rankings when r\'esum\'e quality is homogeneous and few candidates inject. However, its effectiveness rapidly diminishes as more candidates inject, collapsing when manipulation becomes widespread. When candidate quality is heterogeneous, prompt injection is less effective on average, but can occasionally allow lower-quality candidates to outrank higher-quality ones, raising fairness concerns. Overall, LLM-based screening is most vulnerable when manipulation is rare and candidate quality differences are small. Code and resources are publicly available at: https://github.com/preetb1199/Prompt_Injection_ACL26
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in controlled experiments on LLM-based résumé screening, prompt injection (subtle self-promotional text without new qualifications) reliably improves applicant rankings when résumé quality is homogeneous and few candidates inject. Effectiveness diminishes rapidly as more candidates inject and collapses when manipulation is widespread. When candidate quality is heterogeneous, injection is less effective on average but can occasionally allow lower-quality candidates to outrank higher-quality ones, raising fairness issues. The central conclusion is that LLM screening is most vulnerable when manipulation is rare and quality differences are small. Code and resources are publicly available.
Significance. If the reported patterns hold under the experimental conditions, the work provides useful empirical evidence on the conditions under which prompt injection succeeds or fails in automated hiring, with direct relevance to AI safety and fairness in high-stakes screening. The public release of code is a clear strength that supports reproducibility and extension by others.
major comments (2)
- [Abstract / Experimental Setup] Abstract and experimental description: the central claims of 'reliably improves' rankings and 'rapidly diminishes' / 'collapsing' effectiveness rest on the controlled experiments, yet no sample sizes, number of trials, statistical tests, or exact screening prompt templates are reported. This information is load-bearing for assessing whether the observed ranking shifts are robust or sensitive to prompt wording.
- [Results (heterogeneous case)] Heterogeneous quality results: the claim that injection 'can occasionally allow lower-quality candidates to outrank higher-quality ones' is central to the fairness concern, but the manuscript provides no details on how quality heterogeneity is introduced, how 'quality' is quantified, or the rate at which reversals occur. Without these, the practical significance of the occasional reversal cannot be evaluated.
minor comments (1)
- The abstract states that 'Code and resources are publicly available' at a GitHub link; confirm that the repository contains the exact prompts, resume templates, and analysis scripts used to generate the reported figures.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on experimental transparency. We agree that additional details are needed and will revise the manuscript to incorporate them.
read point-by-point responses
-
Referee: [Abstract / Experimental Setup] Abstract and experimental description: the central claims of 'reliably improves' rankings and 'rapidly diminishes' / 'collapsing' effectiveness rest on the controlled experiments, yet no sample sizes, number of trials, statistical tests, or exact screening prompt templates are reported. This information is load-bearing for assessing whether the observed ranking shifts are robust or sensitive to prompt wording.
Authors: We agree these parameters must be reported explicitly. The current manuscript describes the overall design but omits precise counts, trial numbers, statistical procedures, and full prompt text. In revision we will add a dedicated 'Experimental Parameters' subsection reporting sample sizes per condition, number of independent trials, the statistical tests applied to ranking shifts, and the complete screening prompt templates (moved to an appendix). revision: yes
-
Referee: [Results (heterogeneous case)] Heterogeneous quality results: the claim that injection 'can occasionally allow lower-quality candidates to outrank higher-quality ones' is central to the fairness concern, but the manuscript provides no details on how quality heterogeneity is introduced, how 'quality' is quantified, or the rate at which reversals occur. Without these, the practical significance of the occasional reversal cannot be evaluated.
Authors: We accept that the heterogeneous-quality section is underspecified. Revision will add: (1) the exact procedure used to create quality variation (differing counts of job-relevant qualifications and experience levels drawn from a fixed rubric), (2) the quantification method (numeric quality score derived from the same rubric), and (3) the observed reversal rates (percentage of trials in which an injected lower-quality résumé outranked a non-injected higher-quality one). These numbers will be stated in the results and discussed in the fairness subsection. revision: yes
Circularity Check
Empirical study with no derivations or fitted parameters
full rationale
This is a controlled-experiments paper reporting observed ranking shifts under prompt-injection conditions. No equations, first-principles derivations, parameter-fitting steps, or uniqueness theorems are present in the abstract or described methodology. The central claims rest on direct experimental outcomes rather than any reduction to self-defined inputs or self-citations, satisfying the default expectation of no significant circularity for non-derivational empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Econometrica , volume =
Cheap Talk , author =. Econometrica , volume =
-
[2]
Journal of Economic Perspectives , volume =
Cheap Talk , author =. Journal of Economic Perspectives , volume =
-
[3]
Auction Theory , author =
-
[5]
arXiv preprint arXiv:2306.05685 , year =
LLMs as Judges: Evaluating LLMs with LLMs , author =. arXiv preprint arXiv:2306.05685 , year =
-
[6]
arXiv preprint arXiv:2307.00001 , year =
Self-Bias in Large Language Models , author =. arXiv preprint arXiv:2307.00001 , year =
-
[7]
arXiv preprint arXiv:2307.02483 , year =
Jailbroken: How Does LLM Safety Training Fail? , author =. arXiv preprint arXiv:2307.02483 , year =
-
[8]
arXiv preprint arXiv:2302.12173 , year =
Not What You've Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection , author =. arXiv preprint arXiv:2302.12173 , year =
-
[9]
arXiv preprint arXiv:2401.00001 , year =
Instruction Following as Implicit Alignment , author =. arXiv preprint arXiv:2401.00001 , year =
-
[10]
The New York Times , year =
Gorelick, Evan , title =. The New York Times , year =
-
[11]
2025 , eprint=
Prompt Injection Vulnerability of Consensus Generating Applications in Digital Democracy , author=. 2025 , eprint=
2025
-
[12]
arXiv preprint arXiv:2403.04957 , year =
Xiaogeng Liu and Zhiyuan Yu and Yizhe Zhang and Ning Zhang and Chaowei Xiao , title =. arXiv preprint arXiv:2403.04957 , year =
-
[13]
arXiv preprint arXiv:2507.15219 , year =
Tianneng Shi and Kaijie Zhu and Zhun Wang and Yuqi Jia and Will Cai and Weida Liang and Haonan Wang and Hend Alzahrani and Joshua Lu and Kenji Kawaguchi and Basel Alomair and Xuandong Zhao and William Yang Wang and Neil Gong and Wenbo Guo and Dawn Song , title =. arXiv preprint arXiv:2507.15219 , year =
-
[14]
Optimization-based Prompt Injection Attack to LLM-as-a-Judge , year =
Jiawen Shi and Zenghui Yuan and Yinuo Liu and Yue Huang and Pan Zhou and Lichao Sun and Neil Zhenqiang Gong , doi =. Optimization-based Prompt Injection Attack to LLM-as-a-Judge , year =. CCS 2024 - Proceedings of the 2024 ACM SIGSAC Conference on Computer and Communications Security , keywords =
2024
-
[15]
Wiest and Carolin V
Jan Clusmann and Dyke Ferber and Isabella C. Wiest and Carolin V. Schneider and Titus J. Brinker and Sebastian Foersch and Daniel Truhn and Jakob Nikolas Kather , doi =. Prompt injection attacks on vision language models in oncology , volume =. Nature Communications , month =
-
[16]
33rd USENIX Security Symposium (USENIX Security 24) , year =
Yupei Liu and Yuqi Jia and Runpeng Geng and Jinyuan Jia and Neil Zhenqiang Gong , title =. 33rd USENIX Security Symposium (USENIX Security 24) , year =
-
[17]
Nghiem, Huy and Prindle, John and Zhao, Jieyu and Daum \'e Iii, Hal. ``You Gotta be a Doctor, Lin'' : An Investigation of Name-Based Bias of Large Language Models in Employment Recommendations. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.413
-
[18]
MCKELDIN LIBRARY on August , title =
Walter Laurito and Benjamin Davis and Peli Grietzer and Tomáš Gavenčiak and Ada Böhm and Jan Kulveit , doi =. MCKELDIN LIBRARY on August , title =
-
[19]
Gender, Race, and Intersectional Bias in Resume Screening via Language Model Retrieval , url =
Kyra Wilson and Aylin Caliskan , keywords =. Gender, Race, and Intersectional Bias in Resume Screening via Language Model Retrieval , url =
-
[20]
arXiv preprint arXiv:2406.10486 , year =
Haozhe An and Christabel Acquaye and Colin Wang and Zongxia Li and Rachel Rudinger , title =. arXiv preprint arXiv:2406.10486 , year =
-
[21]
The Silicon Ceiling: Auditing GPT's Race and Gender Biases in Hiring , year =
Lena Armstrong and Abbey Liu and Stephen MacNeil and Danaë Metaxa , doi =. The Silicon Ceiling: Auditing GPT's Race and Gender Biases in Hiring , year =. Proceedings of the 4th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, EAAMO 2024 , keywords =
2024
-
[22]
2025 , eprint=
AI Self-preferencing in Algorithmic Hiring: Empirical Evidence and Insights , author=. 2025 , eprint=
2025
-
[23]
Does AI Cheapen Talk? Theory and Evidence From Global Entrepreneurship and Hiring , institution =
Bo Cowgill and Pablo Hern. Does AI Cheapen Talk? Theory and Evidence From Global Entrepreneurship and Hiring , institution =. 2024 , url =
2024
-
[24]
2025 , eprint=
Making Talk Cheap: Generative AI and Labor Market Signaling , author=. 2025 , eprint=
2025
-
[25]
Two Tickets are Better than One: Fair and Accurate Hiring Under Strategic
Lee Cohen and Connie Hong and Jack Hsieh and Judy Hanwen Shen , booktitle=. Two Tickets are Better than One: Fair and Accurate Hiring Under Strategic. 2025 , url=
2025
-
[26]
Addressing Bias in LLMs: Strategies and Application to Fair AI-based Recruitment , institution =
Alejandro Pe. Addressing Bias in LLMs: Strategies and Application to Fair AI-based Recruitment , institution =. 2025 , url =
2025
-
[27]
Built In , year =
Rumage, Jeff , title =. Built In , year =
-
[28]
2025 , month = dec, url =
Alyssa Schroer , title =. 2025 , month = dec, url =
2025
-
[29]
DeepSeek API Documentation , year =
-
[30]
Create Chat Completion , year =
-
[31]
DeepSeek Open Platform Terms of Service , year =
-
[32]
DeepSeek Terms of Use , year =
-
[33]
2025 , howpublished =
IT Support Specialist Job Listing (TileBar/Soho Studio LLC) , author =. 2025 , howpublished =
2025
-
[34]
, author=
Relative effect of applicant work experience and academic qualification on selection interview decisions: A study of between-sample generalizability. , author=. Journal of applied psychology , volume=. 1991 , publisher=
1991
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.