Agentic Publication Protocol: An Attempt to Modernize Scientific Publication
Pith reviewed 2026-06-29 01:54 UTC · model grok-4.3
The pith
A protocol packages scientific papers as version-controlled repositories so AI agents can explain results, reproduce experiments, and guide follow-up research.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Agentic Publication Protocol treats a version-controlled repository as the publication object and uses an AGENTS.md file together with optional skills to define a paper agent that can explain the work, reproduce key results when possible, and support follow-up research.
What carries the argument
The AGENTS.md file that defines the paper agent and its interaction skills for explanation and reproduction.
If this is right
- Published work becomes executable by agents without requiring readers to reconstruct missing details from the text alone.
- Tacit decisions about code, data handling, and edge cases get recorded in a form agents can use directly.
- Follow-up experiments can start from the same agent instructions rather than from a fresh reading of the manuscript.
- Reproducibility checks can be run by agents against the same repository format used for publication.
- Evaluation of a paper can include measuring how well its defined agent performs the listed tasks.
Where Pith is reading between the lines
- Preprint servers could automatically generate or validate AGENTS.md files for new submissions.
- Citation practices might shift toward crediting both the original repository and successful agent reproductions.
- Training data for future agents could be drawn from successful interactions recorded under this protocol.
- Review processes could incorporate automated checks of whether an agent's reproduction matches the claimed results.
Load-bearing premise
Current large language model agents can interpret AGENTS.md files and associated artifacts well enough to perform explanation, reproduction, and research-support tasks with little extra human help.
What would settle it
A test in which independent agents given only an APP-formatted repository are asked to reproduce the paper's main results and either succeed at rates comparable to human readers or fail systematically on the same steps.
Figures


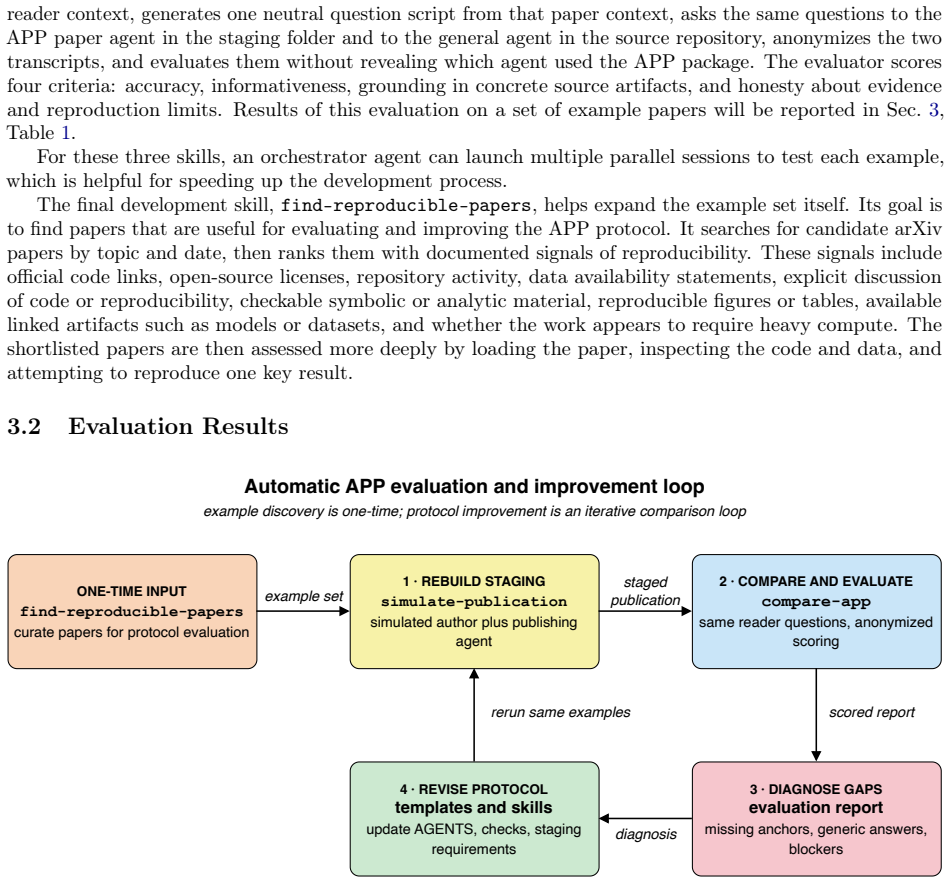
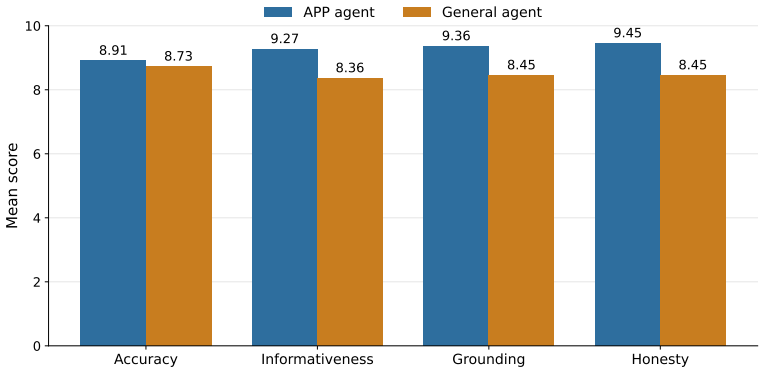

read the original abstract
Scientific publication is still organized primarily around static manuscripts, even though much of scientific progress depends on tacit know-how: how to run code, reproduce figures, interpret edge cases, choose useful follow-up directions, and avoid failed paths. Large language model agents create an opportunity to publish not only knowledge, but also operational know-how in a form that future readers and researchers can directly use. This paper outlines the Agentic Publication Protocol (APP), a lightweight repository format for packaging a paper together with code, data, environment information, reproducibility instructions, and an agent-facing instruction file. APP treats a version-controlled repository as the publication object and uses \texttt{AGENTS.md} and optional skills to define a paper agent that can explain the work, reproduce key results when possible, and support follow-up research. We describe the design principles and details of the protocol, as well as the agent skills useful for publishing papers under the protocol. We also describe development tools for evaluating and improving the protocol and associated agent skills. Finally, we provide a broader discussion of the future of scientific research in the agent era.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the Agentic Publication Protocol (APP), a lightweight repository-based publication format that packages a paper with code, data, environment specifications, reproducibility instructions, and an AGENTS.md file (plus optional skills) so that LLM-based paper agents can explain the work, reproduce key results when feasible, and support follow-up research. It outlines design principles, protocol details, relevant agent skills, development tools for evaluating and improving the protocol, and a broader discussion of scientific research in the agent era.
Significance. If the protocol can be shown to work reliably, it would offer a concrete mechanism for publishing operational scientific know-how alongside static manuscripts, potentially improving reproducibility and enabling automated agents to build directly on published artifacts. The design is timely and provides a structured approach to agent-paper interaction that could influence future standards in digital libraries and reproducible research.
major comments (2)
- [Abstract] Abstract: The central claim that APP enables a paper agent to 'explain the work, reproduce key results when possible, and support follow-up research' with the AGENTS.md format rests on the untested assumption that current or near-future LLM agents can interpret these artifacts and execute the tasks with minimal additional human effort; no implementation, benchmark, or error analysis is supplied to support this.
- [Section describing development tools] Section describing development tools: Although the manuscript states that it describes 'development tools for evaluating and improving the protocol and associated agent skills,' no actual evaluation results, benchmarks, or demonstrations of agent performance on APP-formatted repositories are reported, leaving the feasibility of the protocol unverified.
minor comments (1)
- Including a concrete example of an AGENTS.md file (perhaps in an appendix) would make the protocol specification more actionable for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript proposing the Agentic Publication Protocol. The report correctly identifies that the work is a conceptual proposal without accompanying empirical evaluations. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] The central claim that APP enables a paper agent to 'explain the work, reproduce key results when possible, and support follow-up research' with the AGENTS.md format rests on the untested assumption that current or near-future LLM agents can interpret these artifacts and execute the tasks with minimal additional human effort; no implementation, benchmark, or error analysis is supplied to support this.
Authors: We agree that the manuscript advances a proposed format whose practical effectiveness with LLM agents remains untested. The abstract describes intended capabilities rather than demonstrated performance. We will revise the abstract to state explicitly that APP is a proposed protocol and that validation through implementations and benchmarks is left for future work. revision: yes
-
Referee: [Section describing development tools] Although the manuscript states that it describes 'development tools for evaluating and improving the protocol and associated agent skills,' no actual evaluation results, benchmarks, or demonstrations of agent performance on APP-formatted repositories are reported, leaving the feasibility of the protocol unverified.
Authors: The section outlines the intended design of evaluation tools but does not report results, as the paper's scope is the definition of the protocol rather than its empirical assessment. We will revise the section to clarify that the tools are proposed for subsequent evaluation efforts and that no performance data or demonstrations are included in the current manuscript. revision: yes
Circularity Check
No circularity: standalone design proposal with no derivations or self-referential claims
full rationale
The manuscript is a design document proposing the Agentic Publication Protocol (APP) as a repository format using AGENTS.md and skills. It contains no equations, fitted parameters, predictions, or load-bearing self-citations. The central claim is a definitional proposal whose utility depends on external assumptions about future LLM agents, but this is not circularity within the paper's own chain. No steps reduce to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can be effectively instructed via structured files to perform scientific tasks such as result explanation and reproduction.
invented entities (2)
-
AGENTS.md file
no independent evidence
-
Agentic Publication Protocol (APP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nature Publishing Group UK London (2016)
Monya Baker. 1,500 scientists lift the lid on reproducibility.Nature, 533(7604):452–454, 2016. doi: 10.1038/533452a
-
[2]
Roger D. Peng. Reproducible research in computational science.Science, 334(6060):1226–1227, 2011. doi: 10.1126/science.1213847
-
[3]
An empirical analysis of journal policy effectiveness for computational reproducibility.Proceedings of the National Academy of Sciences, 115(11):2584–2589,
Victoria Stodden, Jennifer Seiler, and Zhaokun Ma. An empirical analysis of journal policy effectiveness for computational reproducibility.Proceedings of the National Academy of Sciences, 115(11):2584–2589,
-
[4]
doi: 10.1073/pnas.1708290115
-
[5]
University of Chicago Press, Chicago, 2009
Michael Polanyi.The Tacit Dimension. University of Chicago Press, Chicago, 2009. ISBN 9780226672984. First published 1966; reissued with a new foreword by Amartya Sen
2009
-
[6]
Hanchen Wang, Tianfan Fu, Yuanqi Du, Wenhao Gao, Kexin Huang, Ziming Liu, Payal Chandak, Shengchao Liu, Peter Van Katwyk, Andreea Deac, Anima Anandkumar, Karianne Bergen, Carla P. Gomes, Shirley Ho, Pushmeet Kohli, Joan Lasenby, Jure Leskovec, Tie-Yan Liu, Arjun Manrai, Debora Marks, Bharath Ramsundar, Le Song, Jimeng Sun, Jian Tang, Petar Veličković, Max...
-
[7]
The agentification of scientific research: A physicist’s perspective, 2026
Xiao-Liang Qi. The agentification of scientific research: A physicist’s perspective, 2026. URLhttps: //arxiv.org/abs/2604.14718. arXiv:2604.14718
Pith/arXiv arXiv 2026
-
[8]
Early science acceleration experiments with GPT-5, 2025
Sébastien Bubeck, Christian Coester, Ronen Eldan, et al. Early science acceleration experiments with GPT-5, 2025. URLhttps://arxiv.org/abs/2511.16072. arXiv:2511.16072
arXiv 2025
-
[9]
Can theoretical physics research benefit from language agents?, 2025
Sirui Lu, Zhijing Jin, Terry Jingchen Zhang, et al. Can theoretical physics research benefit from language agents?, 2025. URLhttps://arxiv.org/abs/2506.06214. arXiv:2506.06214
arXiv 2025
-
[10]
Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes
Daniil A. Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023. doi: 10.1038/s41586-023-06792-0
-
[11]
Bran, Sam Cox, Oliver Schilter, et al
Andres M. Bran, Sam Cox, Oliver Schilter, et al. Augmenting large language models with chemistry tools.Nature Machine Intelligence, 6(5):525–535, 2024. doi: 10.1038/s42256-024-00832-8. URL https://doi.org/10.1038/s42256-024-00832-8
-
[12]
VASPilot: MCP-facilitated multi-agent intelligence for autonomous VASP simulations, 2025
Jiaxuan Liu, Tiannian Zhu, Caiyuan Ye, et al. VASPilot: MCP-facilitated multi-agent intelligence for autonomous VASP simulations, 2025. URLhttps://arxiv.org/abs/2508.07035. arXiv:2508.07035
arXiv 2025
-
[13]
Juraj Gottweis, Wei-Hung Weng, Alexander Daryin, Tao Tu, Anil Palepu, Petar Sirkovic, Artiom Myaskovsky, Felix Weissenberger, Keran Rong, Ryutaro Tanno, Khaled Saab, Dan Popovici, Jacob Blum, Fan Zhang, Katherine Chou, Avinatan Hassidim, Burak Gokturk, Amin Vahdat, Pushmeet Kohli, Yossi Matias, Andrew Carroll, Kavita Kulkarni, Nenad Tomasev, Yuan Guan, Vi...
Pith/arXiv arXiv 2025
-
[14]
Michael Y. Li, Emily B. Fox, and Noah D. Goodman. Automated statistical model discovery with language models, 2024. URLhttps://arxiv.org/abs/2402.17879. arXiv:2402.17879
arXiv 2024
-
[15]
Brenner, Vincent Cohen-Addad, and David Woodruff
Michael P. Brenner, Vincent Cohen-Addad, and David Woodruff. Solving an open problem in theoretical physics using AI-assisted discovery, 2026. URLhttps://arxiv.org/abs/2603.04735. arXiv:2603.04735
arXiv 2026
-
[16]
Single-minus graviton tree amplitudes are nonzero, 2026
Alfredo Guevara, Alexandru Lupsasca, David Skinner, et al. Single-minus graviton tree amplitudes are nonzero, 2026. URLhttps://cdn.openai.com/pdf/graviton.pdf. OpenAI preprint PDF. 13
2026
-
[17]
Tony Feng, Trieu H. Trinh, Garrett Bingham, et al. Towards autonomous mathematics research, 2026. URLhttps://arxiv.org/abs/2602.10177. arXiv:2602.10177
arXiv 2026
-
[18]
AI co-mathematician: Accelerating mathematicians with agentic AI, 2026
Daniel Zheng, Ingrid von Glehn, Yori Zwols, et al. AI co-mathematician: Accelerating mathematicians with agentic AI, 2026. URLhttps://arxiv.org/abs/2605.06651. arXiv:2605.06651
Pith/arXiv arXiv 2026
-
[19]
Advancing mathematics research with AI-driven formal proof search, 2026
George Tsoukalas, Anton Kovsharov, Sergey Shirobokov, et al. Advancing mathematics research with AI-driven formal proof search, 2026. URLhttps://arxiv.org/abs/2605.22763. arXiv:2605.22763
Pith/arXiv arXiv 2026
-
[20]
An OpenAI model has disproved a central conjecture in discrete geometry, May 2026
OpenAI. An OpenAI model has disproved a central conjecture in discrete geometry, May 2026. URL https://openai.com/index/model-disproves-discrete-geometry-conjecture/. Research announcement, with links to proof and companion remarks
2026
-
[21]
Bloom, W
Noga Alon, Thomas F. Bloom, W. T. Gowers, Daniel Litt, Will Sawin, Arul Shankar, Jacob Tsimer- man, Victor Wang, and Melanie Matchett Wood. Remarks on the disproof of the unit distance conjecture, 2026. URL https://cdn.openai.com/pdf/74c24085-19b0-4534-9c90-465b8e29ad73/ unit-distance-remarks.pdf. Companion remarks on the OpenAI unit-distance result
2026
-
[22]
The AI scientist: Towards fully automated open-ended scientific discovery, 2024
Chris Lu, Cong Lu, Robert Tjarko Lange, et al. The AI scientist: Towards fully automated open-ended scientific discovery, 2024. URLhttps://arxiv.org/abs/2408.06292. arXiv:2408.06292
Pith/arXiv arXiv 2024
-
[23]
The AI Scientist-v2: Workshop-level automated scientific discovery via agentic tree search,
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The AI Scientist-v2: Workshop-level automated scientific discovery via agentic tree search,
- [24]
-
[25]
Agent laboratory: Using LLM agents as research assistants
Samuel Schmidgall, Yusheng Su, Ze Wang, et al. Agent laboratory: Using LLM agents as research assistants. InFindings of the Association for Computational Linguistics: EMNLP 2025, 2025. URL https://aclanthology.org/2025.findings-emnlp.320/
2025
-
[26]
Yi Zhou. From paper to program: Accelerating quantum many-body algorithm development via a multi- stage LLM-assisted workflow, 2026. URLhttps://arxiv.org/abs/2604.04089. arXiv:2604.04089
Pith/arXiv arXiv 2026
-
[27]
Towards verifiable and self-correcting AI physicists for quantum many-body simulations, 2026
Ken Deng, Xiangfei Wang, Guijing Duan, et al. Towards verifiable and self-correcting AI physicists for quantum many-body simulations, 2026. URLhttps://arxiv.org/abs/2604.00149. arXiv:2604.00149
Pith/arXiv arXiv 2026
-
[28]
Peter Cha, Paul Ginsparg, Felix Wu, Juan Carrasquilla, Peter L. McMahon, and Eun-Ah Kim. Attention- based quantum tomography.Machine Learning: Science and Technology, 3(1):01LT01, 2022. doi: 10.1088/2632-2153/ac362b. URLhttps://arxiv.org/abs/2006.12469. arXiv:2006.12469
-
[29]
Free-space model for a balloon-based quantum network, 2024
Ilektra Karakosta-Amarantidou, Raja Yehia, and Matteo Schiavon. Free-space model for a balloon-based quantum network, 2024. URLhttps://arxiv.org/abs/2412.03356. arXiv:2412.03356
arXiv 2024
-
[30]
Michael A. Perlin, Zain H. Saleem, Martin Suchara, and James C. Osborn. Quantum circuit cutting with maximum likelihood tomography.npj Quantum Information, 7:64, 2021. doi: 10.1038/s41534-021-00390-6. URLhttps://arxiv.org/abs/2005.12702. arXiv:2005.12702
-
[31]
Particle partition entanglement of one dimensional spinless fermions.Journal of Statistical Mechanics: Theory and Experiment, 2017(8):083109,
Hatem Barghathi, Emanuel Casiano-Diaz, and Adrian Del Maestro. Particle partition entanglement of one dimensional spinless fermions.Journal of Statistical Mechanics: Theory and Experiment, 2017(8):083109,
2017
-
[32]
Particle partition entanglement of one dimensional spinless fermions
doi: 10.1088/1742-5468/aa819a. URLhttps://arxiv.org/abs/1703.10587. arXiv:1703.10587
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1088/1742-5468/aa819a
-
[33]
Multiple-basis representation of quantum states, 2024
Adrián Pérez-Salinas, Patrick Emonts, Jordi Tura, and Vedran Dunjko. Multiple-basis representation of quantum states, 2024. URLhttps://arxiv.org/abs/2411.03110. arXiv:2411.03110
arXiv 2024
-
[34]
Qiushi Liu, Zihao Hu, Haidong Yuan, and Yuxiang Yang. Optimal strategies of quantum metrology with a strict hierarchy.Physical Review Letters, 130:070803, 2023. doi: 10.1103/PhysRevLett.130.070803. URLhttps://arxiv.org/abs/2203.09758. arXiv:2203.09758
-
[35]
Simanshu Kumar and Nandan S Bisht. OAM-induced lattice rotation reveals a fractional optimum in fault- tolerant GKP quantum sensing, 2026. URLhttps://arxiv.org/abs/2605.13271. arXiv:2605.13271. 14
Pith/arXiv arXiv 2026
-
[36]
Guillem Müller-Rigat, Anubhav Kumar Srivastava, Stanisław Kurdziałek, Grzegorz Rajchel-Mieldzioć, Maciej Lewenstein, and Irénée Frérot. Certifying the quantum fisher information from a given set of mean values: a semidefinite programming approach.Quantum, 7:1152, 2023. doi: 10.22331/q-2023-10-24-1152. URLhttps://arxiv.org/abs/2306.12711. arXiv:2306.12711
-
[37]
Learning quantum processes with quantum statistical queries
Chirag Wadhwa and Mina Doosti. Learning quantum processes with quantum statistical queries. Quantum, 9:1739, 2025. doi: 10.22331/q-2025-05-12-1739. URLhttps://arxiv.org/abs/2310.02075. arXiv:2310.02075
-
[38]
Boris Sokolov, Matteo A. C. Rossi, Guillermo García-Pérez, and Sabrina Maniscalco. Emergent entanglement structures and self-similarity in quantum spin chains.Philosophical Transactions of the Royal Society A, 380(2227):20200421, 2022. doi: 10.1098/rsta.2020.0421. URLhttps://arxiv.org/ abs/2007.06989. arXiv:2007.06989
-
[39]
Daniel Malz and Adam Smith. Topological two-dimensional floquet lattice on a single superconducting qubit.Physical Review Letters, 126:163602, 2021. doi: 10.1103/PhysRevLett.126.163602. URLhttps: //arxiv.org/abs/2012.01459. arXiv:2012.01459
-
[40]
Why linked data is not enough for scientists
Sean Bechhofer, Iain Buchan, David De Roure, et al. Why linked data is not enough for scientists. Future Generation Computer Systems, 29(2):599–611, 2013. doi: 10.1016/j.future.2011.08.004
-
[41]
Mark D. Wilkinson, Michel Dumontier, IJsbrand Jan Aalbersberg, et al. The FAIR guiding principles for scientific data management and stewardship.Scientific Data, 3:160018, 2016. doi: 10.1038/sdata.2016.18
-
[42]
Binder 2.0 – reproducible, interactive, sharable environments for science at scale
Project Jupyter, Matthias Bussonnier, Jessica Forde, Jeremy Freeman, Brian Granger, Tim Head, Chris Holdgraf, Kyle Kelley, Gladys Nalvarte, Andrew Osheroff, M Pacer, Yuvi Panda, Fernando Pérez, Benjamin Ragan-Kelley, and Carol Willing. Binder 2.0 – reproducible, interactive, sharable environments for science at scale. InProceedings of the 17th Python in S...
-
[43]
Improving reproducibility in machine learning research (a report from the NeurIPS 2019 reproducibility program).Journal of Machine Learning Research, 22 (164):1–20, 2021
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. Improving reproducibility in machine learning research (a report from the NeurIPS 2019 reproducibility program).Journal of Machine Learning Research, 22 (164):1–20, 2021. URLhttp://jmlr.org/papers/v22/20-303.html
2019
-
[44]
Artifact review and badging – current (version 1.1)
Association for Computing Machinery. Artifact review and badging – current (version 1.1). ACM publications policy, August 2020. URL https://www.acm.org/publications/policies/ artifact-review-and-badging-current. Accessed 2026-06-10
2020
-
[45]
Hugging Face Papers
Hugging Face. Hugging Face Papers. Website, 2026. URLhttps://huggingface.co/papers. Hosts the paper–code index formerly maintained by Papers with Code;https://huggingface.co/papers; accessed 2026-06-10
2026
-
[46]
The last human-written paper: Agent-native research artifacts, 2026
Jiachen Liu, Jiaxin Pei, Jintao Huang, Chenglei Si, Ao Qu, Xiangru Tang, Runyu Lu, Lichang Chen, Xiaoyan Bai, Haizhong Zheng, Carl Chen, Zhiyang Chen, Haojie Ye, Yujuan Fu, Zexue He, Zijian Jin, Zhenyu Zhang, Shangquan Sun, Maestro Harmon, John Dianzhuo Wang, Jianqiao Zeng, Jiachen Sun, Mingyuan Wu, Baoyu Zhou, Yuchen You, Shijian Lu, Yiming Qiu, Fan Lai,...
Pith/arXiv arXiv 2026
-
[47]
Davis, Yaohui Zhang, Jonathan K
Jiacheng Miao, Joe R. Davis, Yaohui Zhang, Jonathan K. Pritchard, and James Zou. Paper2Agent: Reimagining research papers as interactive and reliable AI agents, 2025. URLhttps://arxiv.org/ abs/2509.06917. arXiv:2509.06917
arXiv 2025
-
[48]
Introducing the Model Context Protocol
Anthropic. Introducing the Model Context Protocol. https://www.anthropic.com/news/ model-context-protocol, November 2024. Open standard for connecting AI assistants to data sources and tools; accessed 2026-06-10. 15
2024
-
[49]
Paper2Code: Automating code generation from scientific papers in machine learning
Minju Seo, Jinheon Baek, Seongyun Lee, and Sung Ju Hwang. Paper2Code: Automating code generation from scientific papers in machine learning. InInternational Conference on Learning Representations (ICLR), 2026. URLhttps://openreview.net/forum?id=3DcaUTjdKc. arXiv:2504.17192
arXiv 2026
-
[50]
Exploring the use of AI authors and reviewers at Agents4Science.Nature Biotechnology, 44:11–14, 2026
Federico Bianchi, Owen Queen, Nitya Thakkar, Eric Sun, James Zou, et al. Exploring the use of AI authors and reviewers at Agents4Science.Nature Biotechnology, 44:11–14, 2026. doi: 10.1038/s41587-025-02963-8. URLhttps://doi.org/10.1038/s41587-025-02963-8
-
[51]
Weixin Liang, Yuhui Zhang, Hancheng Cao, Binglu Wang, Daisy Yi Ding, Xinyu Yang, Kailas Vodrahalli, Siyu He, Daniel Scott Smith, Yian Yin, Daniel A. McFarland, and James Zou. Can large language models provide useful feedback on research papers? A large-scale empirical analysis.NEJM AI, 1(8): AIoa2400196, 2024. doi: 10.1056/AIoa2400196
-
[52]
Davidson, Veniamin Veselovsky, and Robert West
Giuseppe Russo Latona, Manoel Horta Ribeiro, Tim R. Davidson, Veniamin Veselovsky, and Robert West. The AI review lottery: Widespread AI-assisted peer reviews boost paper scores and acceptance rates, 2024. URLhttps://arxiv.org/abs/2405.02150. arXiv:2405.02150
arXiv 2024
-
[53]
Weixin Liang, Yaohui Zhang, Zhengxuan Wu, et al. Quantifying large language model usage in scientific papers.Nature Human Behaviour, 9:2599–2609, 2025. doi: 10.1038/s41562-025-02273-8. URL https://doi.org/10.1038/s41562-025-02273-8
-
[54]
Scientific production in the era of large language models.Science, 390(6779):1240–1243, 2025
Keigo Kusumegi, Xinyu Yang, Paul Ginsparg, et al. Scientific production in the era of large language models.Science, 390(6779):1240–1243, 2025. doi: 10.1126/science.adw3000. URLhttps://doi.org/10. 1126/science.adw3000
-
[55]
Riccardo Bertolo and Alessandro Antonelli. Generative AI in scientific publishing: Disruptive or destructive?Nature Reviews Urology, 21:1–2, 2024. doi: 10.1038/s41585-023-00836-w. URLhttps: //doi.org/10.1038/s41585-023-00836-w
-
[56]
ICML 2023 clarification on large language model policy.https://icml.cc/Conferences/2023/ llm-policy, 2023
ICML. ICML 2023 clarification on large language model policy.https://icml.cc/Conferences/2023/ llm-policy, 2023. Accessed 2026-06-10
2023
-
[57]
Tools such as ChatGPT threaten transparent science; here are our ground rules for their use
Editorial. Tools such as ChatGPT threaten transparent science; here are our ground rules for their use. Nature, 613:612, 2023. doi: 10.1038/d41586-023-00191-1. Editorial
-
[58]
Holden Thorp
H. Holden Thorp. ChatGPT is fun, but not an author.Science, 379(6630):313, 2023. doi: 10.1126/ science.adg7879
2023
-
[59]
NeurIPS 2025 policy on the use of large language models.https://neurips.cc/Conferences/ 2025/LLM, 2025
NeurIPS. NeurIPS 2025 policy on the use of large language models.https://neurips.cc/Conferences/ 2025/LLM, 2025. Accessed 2026-06-10
2025
-
[60]
Policies on large language model usage at ICLR 2026
ICLR 2026 Program Chairs. Policies on large language model usage at ICLR 2026. https: //blog.iclr.cc/2025/08/26/policies-on-large-language-model-usage-at-iclr-2026/ , August
2026
-
[61]
Accessed 2026-06-10. 16
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.