CascadeOcc: Rethinking 3D Occupancy World Models with Cascaded VQ Representations
Pith reviewed 2026-06-29 00:29 UTC · model grok-4.3
The pith
CascadeOcc uses cascaded vector quantization to create more effective 3D occupancy world models for driving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By integrating a cascaded Vector Quantized mechanism into an autoregressive framework and following a coarse-to-fine principle with a multi-scale architecture, along with a TimeMixer for multi-scale temporal dependencies, CascadeOcc establishes a dual-hierarchy mechanism in space and time that achieves superior performance among vision-centric approaches on 4D occupancy forecasting and motion planning benchmarks.
What carries the argument
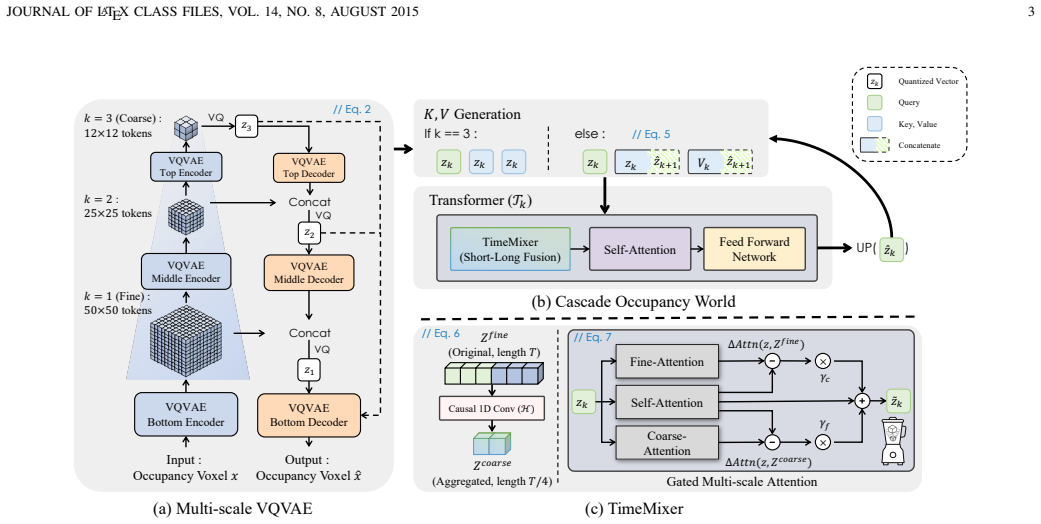
The cascaded Vector Quantized (VQ) mechanism that refines occupancy representations from global structures to fine-grained details in a multi-scale architecture.
If this is right
- Optimizing the inherent structural hierarchy of occupancy representations serves as a strong alternative to external foundation models.
- The dual-hierarchy mechanism improves modeling of complex 3D scenes in both space and time.
- Performance gains are demonstrated on standard 4D occupancy forecasting benchmarks.
- Improvements are also shown on motion planning benchmarks for autonomous driving.
Where Pith is reading between the lines
- If the cascaded approach succeeds, it may extend to other autoregressive modeling tasks in 3D vision.
- Reducing dependence on external models could simplify system design for real-time applications.
- Further work might explore how the multi-scale architecture handles dynamic elements like moving objects.
Load-bearing premise
That the cascaded VQ mechanism can progressively refine fine-grained details from global structures without relying on external modalities.
What would settle it
Running the model on the benchmarks with the cascaded VQ disabled and observing whether performance drops below the reported levels or matches external-model methods.
Figures
read the original abstract
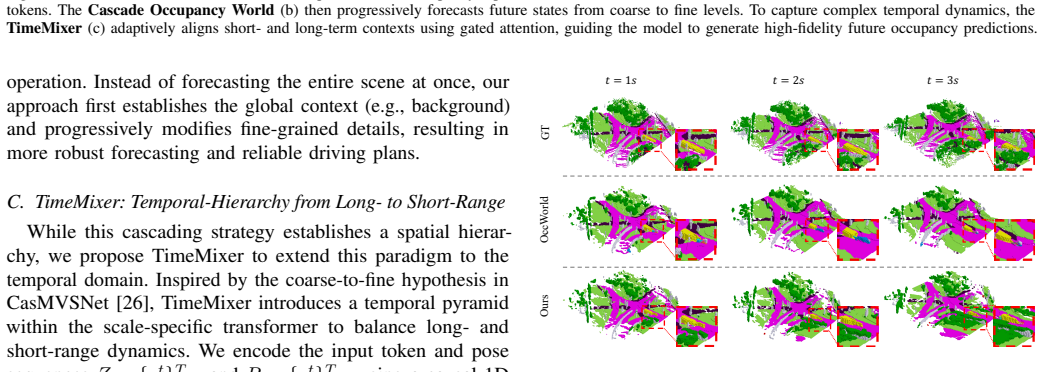
This letter proposes CascadeOcc, a novel occupancy world model that prioritizes intrinsic structural hierarchy over extrinsic auxiliary modalities for autonomous driving. Occupancy world models -- forecasting the future driving environment and planning the driving trajectory -- effectively bridge perception and planning, but current approaches often heavily rely on external modalities or large language models, failing to fully exploit the inherent structural potential of occupancy representations themselves. To enhance representational capacity for complex 3D scenes, we integrate a cascaded Vector Quantized (VQ) mechanism into an autoregressive framework. Following a coarse-to-fine principle, CascadeOcc progressively refines fine-grained details from global structures through a multi-scale architecture. Additionally, we incorporate a TimeMixer to capture multi-scale temporal dependencies, establishing a dual-hierarchy mechanism in both space and time. Experimental results on 4D occupancy forecasting and motion planning benchmarks demonstrate that CascadeOcc achieves superior performance among vision-centric approaches, validating that optimizing inherent representations is a powerful alternative to relying on external foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CascadeOcc, a novel occupancy world model for autonomous driving that integrates a cascaded Vector Quantized (VQ) mechanism into an autoregressive framework. Following a coarse-to-fine principle, it progressively refines fine-grained 3D scene details from global structures via a multi-scale architecture and incorporates a TimeMixer to capture multi-scale temporal dependencies, establishing a dual-hierarchy in space and time. The central claim is that experimental results on 4D occupancy forecasting and motion planning benchmarks show superior performance among vision-centric approaches, validating that optimizing inherent representations is a powerful alternative to relying on external modalities or large language models.
Significance. If the reported benchmark gains hold under rigorous controls, the work would indicate that intrinsic hierarchical VQ representations can deliver competitive or superior results without external foundation models, potentially simplifying architectures and reducing dependency on auxiliary modalities in occupancy-based perception and planning pipelines for autonomous driving.
major comments (1)
- [Abstract] Abstract: the claim that results on vision-centric benchmarks 'validate that optimizing inherent representations is a powerful alternative to relying on external foundation models' does not follow from the stated evidence; the experiments establish only intra-category superiority, and head-to-head metrics against external-modality or LLM-based baselines on the same 4D forecasting and planning tasks are required to support the comparative validation.
minor comments (1)
- [Abstract] Abstract: the assertion of 'superior performance' is made without any quantitative metrics, specific baselines, ablation results, or error analysis, which limits immediate evaluation of the strength of the empirical support.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the specific observation on the abstract. We agree that the current phrasing overreaches the presented evidence and will revise the manuscript to align claims precisely with the experimental scope.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that results on vision-centric benchmarks 'validate that optimizing inherent representations is a powerful alternative to relying on external foundation models' does not follow from the stated evidence; the experiments establish only intra-category superiority, and head-to-head metrics against external-modality or LLM-based baselines on the same 4D forecasting and planning tasks are required to support the comparative validation.
Authors: We accept this critique. The reported experiments compare CascadeOcc only against other vision-centric methods on the 4D occupancy and planning benchmarks. No direct head-to-head results versus external-modality or LLM-augmented baselines appear in the current evaluation. We will revise the abstract (and any similar statements in the introduction and conclusion) to state only that CascadeOcc achieves state-of-the-art results among vision-centric approaches. The broader claim that the work validates inherent representations as a powerful alternative will be removed or rephrased as a motivating hypothesis rather than a validated conclusion. revision: yes
Circularity Check
No circularity; empirical model proposal with benchmark validation
full rationale
The paper presents an architectural proposal (cascaded VQ + TimeMixer dual hierarchy) and supports its value via reported experimental results on 4D occupancy forecasting and motion planning benchmarks among vision-centric methods. No derivation chain, first-principles prediction, or fitted parameter is shown to reduce by construction to its own inputs; the central claim rests on external benchmark comparisons rather than self-referential fitting or self-citation load-bearing. The abstract's contrast with external modalities is an interpretive framing of the empirical outcome, not a mathematical reduction. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via perspective supervision,
C. Yang, Y . Chen, H. Tian, C. Tao, X. Zhu, Z. Zhang, G. Huang, H. Li, Y . Qiao, L. Luet al., “Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via perspective supervision,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 830–17 839
2023
-
[2]
BEVDet: High-performance Multi-camera 3D Object Detection in Bird-Eye-View
J. Huang, G. Huang, Z. Zhu, Y . Ye, and D. Du, “Bevdet: High- performance multi-camera 3d object detection in bird-eye-view,”arXiv preprint arXiv:2112.11790, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Monoscene: Monocular 3d semantic scene completion,
A.-Q. Cao and R. De Charette, “Monoscene: Monocular 3d semantic scene completion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 3991–4001
2022
-
[4]
V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion,
Y . Li, Z. Yu, C. Choy, C. Xiao, J. M. Alvarez, S. Fidler, C. Feng, and A. Anandkumar, “V oxformer: Sparse voxel transformer for camera- based 3d semantic scene completion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 9087– 9098
2023
-
[5]
Full surround monodepth from multiple cameras,
V . Guizilini, I. Vasiljevic, R. Ambrus, G. Shakhnarovich, and A. Gaidon, “Full surround monodepth from multiple cameras,”IEEE Robotics and Automation Letters, vol. 7, no. 2, pp. 5397–5404, 2022
2022
-
[6]
Surrounddepth: Entangling surrounding views for self-supervised multi- camera depth estimation,
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, Y . Rao, G. Huang, J. Lu, and J. Zhou, “Surrounddepth: Entangling surrounding views for self-supervised multi- camera depth estimation,” inConference on robot learning. PMLR, 2023, pp. 539–549
2023
-
[7]
R3d3: Dense 3d reconstruction of dynamic scenes from multiple cameras,
A. Schmied, T. Fischer, M. Danelljan, M. Pollefeys, and F. Yu, “R3d3: Dense 3d reconstruction of dynamic scenes from multiple cameras,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3216–3226
2023
-
[8]
Monocular depth estimation with multi-scale feature fusion,
X. Xu, Z. Chen, and F. Yin, “Monocular depth estimation with multi-scale feature fusion,”IEEE Signal Processing Letters, vol. 28, pp. 678–682, 2021
2021
-
[9]
Adv-depth: Self-supervised monocular depth estimation with an adversarial loss,
K. Li, Z. Fu, H. Wang, Z. Chen, and Y . Guo, “Adv-depth: Self-supervised monocular depth estimation with an adversarial loss,”IEEE Signal Processing Letters, vol. 28, pp. 638–642, 2021
2021
-
[10]
Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,
Z. Li, W. Wang, H. Li, E. Xie, C. Sima, T. Lu, Q. Yu, and J. Dai, “Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
2024
-
[11]
Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,
J. Philion and S. Fidler, “Lift, splat, shoot: Encoding images from arbitrary camera rigs by implicitly unprojecting to 3d,” inEuropean conference on computer vision. Springer, 2020, pp. 194–210
2020
-
[12]
Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving,
Y . Wei, L. Zhao, W. Zheng, Z. Zhu, J. Zhou, and J. Lu, “Surroundocc: Multi-camera 3d occupancy prediction for autonomous driving,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 21 729–21 740
2023
-
[13]
Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,
X. Tian, T. Jiang, L. Yun, Y . Mao, H. Yang, Y . Wang, Y . Wang, and H. Zhao, “Occ3d: A large-scale 3d occupancy prediction benchmark for autonomous driving,”Advances in Neural Information Processing Systems, vol. 36, pp. 64 318–64 330, 2023
2023
-
[14]
Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception,
X. Wang, Z. Zhu, W. Xu, Y . Zhang, Y . Wei, X. Chi, Y . Ye, D. Du, J. Lu, and X. Wang, “Openoccupancy: A large scale benchmark for surrounding semantic occupancy perception,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 17 850–17 859
2023
-
[15]
Tri-perspective view for vision-based 3d semantic occupancy prediction,
Y . Huang, W. Zheng, Y . Zhang, J. Zhou, and J. Lu, “Tri-perspective view for vision-based 3d semantic occupancy prediction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 9223–9232
2023
-
[16]
Occworld: Learning a 3d occupancy world model for autonomous driving,
W. Zheng, W. Chen, Y . Huang, B. Zhang, Y . Duan, and J. Lu, “Occworld: Learning a 3d occupancy world model for autonomous driving,” in European conference on computer vision. Springer, 2024, pp. 55–72
2024
-
[17]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[18]
Occllama: An occupancy-language-action generative world model for autonomous driving,
J. Wei, S. Yuan, P. Li, Q. Hu, Z. Gan, and W. Ding, “Occllama: An occupancy-language-action generative world model for autonomous driving,”arXiv preprint arXiv:2409.03272, 2024
-
[19]
Occ-llm: Enhancing autonomous driving with occupancy-based large language models,
T. Xu, H. Lu, X. Yan, Y . Cai, B. Liu, and Y . Chen, “Occ-llm: Enhancing autonomous driving with occupancy-based large language models,”arXiv preprint arXiv:2502.06419, 2025
-
[20]
Renderworld: World model with self- supervised 3d label,
Z. Yan, W. Dong, Y . Shao, Y . Lu, L. Haiyang, J. Liu, H. Wang, Z. Wang, Y . Wang, F. Remondinoet al., “Renderworld: World model with self- supervised 3d label,”arXiv preprint arXiv:2409.11356, 2024
-
[21]
Fsf-net: Enhance 4d occupancy forecasting with coarse bev scene flow for autonomous driving,
E. Guo, P. An, Y . Yang, Q. Liu, and A.-A. Liu, “Fsf-net: Enhance 4d occupancy forecasting with coarse bev scene flow for autonomous driving,”Pattern Recognition, p. 112372, 2025
2025
-
[22]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
2023
-
[23]
Generating diverse high- fidelity images with vq-vae-2,
A. Razavi, A. Van den Oord, and O. Vinyals, “Generating diverse high- fidelity images with vq-vae-2,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[24]
nuscenes: A multimodal dataset for autonomous driving,
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11 621–11 631
2020
-
[25]
Feature pyramid networks for object detection,
T.-Y . Lin, P. Doll´ar, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125
2017
-
[26]
Cascade cost volume for high-resolution multi-view stereo and stereo matching,
X. Gu, Z. Fan, S. Zhu, Z. Dai, F. Tan, and P. Tan, “Cascade cost volume for high-resolution multi-view stereo and stereo matching,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 2495–2504
2020
-
[27]
WaveNet: A Generative Model for Raw Audio
A. Van Den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, N. Kalchbrenner, A. Senior, K. Kavukcuogluet al., “Wavenet: A generative model for raw audio,”arXiv preprint arXiv:1609.03499, vol. 12, p. 1, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
Scene as occupancy,
W. Tong, C. Sima, T. Wang, L. Chen, S. Wu, H. Deng, Y . Gu, L. Lu, P. Luo, D. Linet al., “Scene as occupancy,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8406–8415
2023
-
[29]
Autoregressive image generation using residual quantization,
D. Lee, C. Kim, S. Kim, M. Cho, and W.-S. Han, “Autoregressive image generation using residual quantization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 523–11 532
2022
-
[30]
Sequence Level Training with Recurrent Neural Networks
M. Ranzato, S. Chopra, M. Auli, and W. Zaremba, “Sequence level train- ing with recurrent neural networks,”arXiv preprint arXiv:1511.06732, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[31]
Is ego status all you need for open-loop end-to-end autonomous driving?
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez, “Is ego status all you need for open-loop end-to-end autonomous driving?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 864–14 873
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.