MASS: Motion-Aligned Selective Scan for Refinement in Flow-Based Video Frame Interpolation
Pith reviewed 2026-06-29 04:48 UTC · model grok-4.3
The pith
Scanning features along motion trajectories refines video frame interpolation for large displacements
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
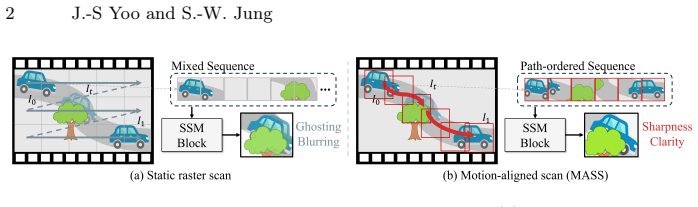
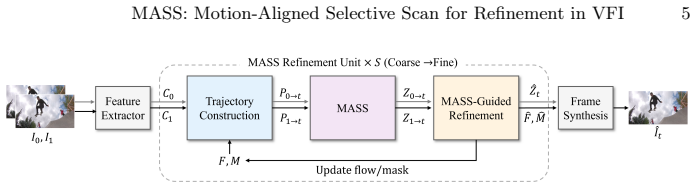
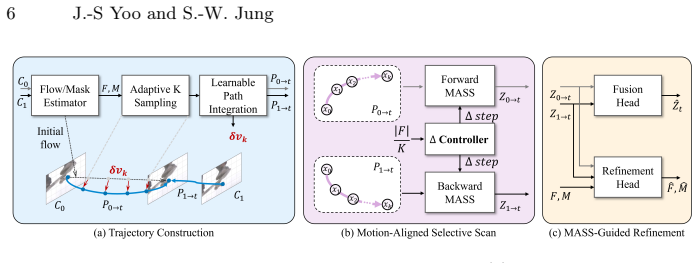
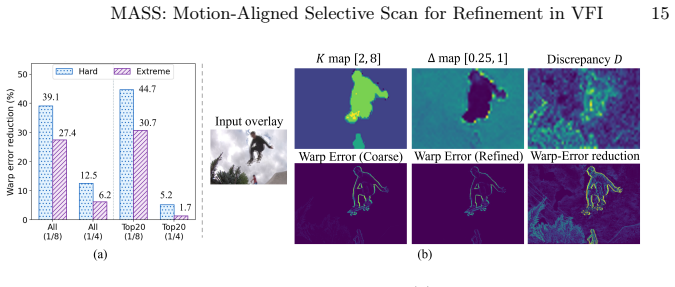
MASS reformulates the scanning process in selective state space models for VFI from static grids to dynamic trajectories guided by optical flow. It introduces learnable non-linear path integration to approximate curved trajectories with residual velocity updates and a velocity-aware SSM that dynamically adjusts sampling budget and step size based on motion magnitude. The aggregated states from this process guide a refinement module to correct intermediate flows and masks.
What carries the argument
Motion-Aligned Selective Scan (MASS), which builds feature sequences along each pixel's flow-guided trajectory and aggregates them with a velocity-aware SSM to guide flow and mask refinement.
If this is right
- Allocates more sampling to fast-moving regions while being efficient for static areas.
- Improves handling of large displacements and complex dynamics.
- Produces states that enable end-to-end rectification of flows and masks.
- Achieves state-of-the-art results particularly in challenging scenarios.
- Maintains competitive performance on standard VFI benchmarks.
Where Pith is reading between the lines
- The approach might apply to other video processing tasks involving motion, such as frame rate conversion or motion compensation.
- If trajectory estimation is robust, it could reduce error propagation in multi-frame interpolation.
- Testing on videos with varying motion speeds could reveal optimal parameters for the velocity-aware adjustments.
Load-bearing premise
The flow estimates used to guide the trajectories are sufficiently accurate to align features with true pixel paths.
What would settle it
A comparison experiment on videos with ground-truth large curved motions where MASS shows equivalent or worse PSNR and visual quality than static scanning baselines.
Figures

read the original abstract
Video frame interpolation (VFI) remains a challenging task, particularly when dealing with large, non-linear motions and complex occlusions. While flow-based methods are prevalent, they often struggle with ambiguous correspondences. Recent VFI methods based on selective State Space Models (SSMs) are still limited by static grid-based scanning that misaligns with physical motion. In this paper, we propose Motion-Aligned Selective Scan (MASS), a novel framework that reformulates feature scanning from static spatial grids to dynamic motion trajectories. MASS builds a feature sequence along each pixel's flow-guided trajectory and aggregates it with an SSM. Specifically, we introduce a learnable non-linear path integration to approximate complex curved trajectories via residual velocity updates, and a velocity-aware SSM that dynamically adjusts the sampling budget and step size based on motion magnitude. This adaptive strategy allocates denser sampling to fast-motion regions while keeping static regions efficient. Furthermore, the aggregated states guide a refinement module to rectify intermediate flows and masks in an end-to-end manner. Extensive experiments indicate that MASS achieves highly competitive overall performance on standard benchmarks, establishing state-of-the-art results particularly in challenging scenarios with large displacements and complex dynamics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MASS, a framework for video frame interpolation that replaces static grid-based scanning in selective SSMs with dynamic feature sequences constructed along flow-guided trajectories. It introduces learnable non-linear path integration via residual velocity updates and a velocity-aware SSM that adjusts sampling budget and step size according to motion magnitude; the resulting states are used to guide end-to-end rectification of intermediate flows and masks. The central claim is that this yields highly competitive performance on standard benchmarks and establishes state-of-the-art results especially under large displacements and complex dynamics.
Significance. If the robustness assumption holds, the work would meaningfully advance flow-based VFI by aligning SSM scanning with physical motion rather than fixed grids, offering a principled way to allocate computation to fast-moving regions while addressing ambiguous correspondences. The adaptive, motion-magnitude-dependent sampling is a concrete and potentially reusable idea.
major comments (2)
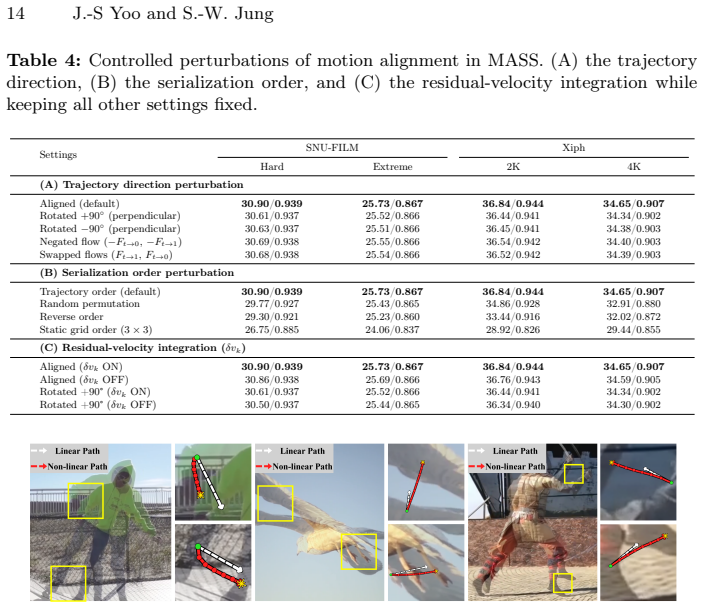
- [Abstract] Abstract (final paragraph): the performance claim that the aggregated SSM states 'guide a refinement module to rectify intermediate flows and masks' and produce SOTA results in large-displacement regimes rests on the unverified assumption that flow-guided trajectories remain sufficiently accurate even when the initial flow estimates contain errors; no derivation, error-propagation analysis, or targeted experiment demonstrates that residual velocity updates or velocity-aware budget adjustment can recover from such initial misalignment.
- [Abstract] Abstract: the assertion of 'establishing state-of-the-art results' is presented without any quantitative metrics, benchmark tables, ablation studies, or error analysis in the manuscript, so the central empirical claim cannot be evaluated from the supplied text.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on the abstract. We agree that the claims require stronger support within the provided text and will revise the abstract accordingly. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): the performance claim that the aggregated SSM states 'guide a refinement module to rectify intermediate flows and masks' and produce SOTA results in large-displacement regimes rests on the unverified assumption that flow-guided trajectories remain sufficiently accurate even when the initial flow estimates contain errors; no derivation, error-propagation analysis, or targeted experiment demonstrates that residual velocity updates or velocity-aware budget adjustment can recover from such initial misalignment.
Authors: We acknowledge that the manuscript does not include a dedicated derivation or error-propagation analysis of how residual velocity updates recover from initial flow inaccuracies. The end-to-end training of the refinement module is intended to mitigate such issues, but a targeted experiment isolating robustness to noisy initial flows is absent. We will add this analysis and experiment in the revision. revision: yes
-
Referee: [Abstract] Abstract: the assertion of 'establishing state-of-the-art results' is presented without any quantitative metrics, benchmark tables, ablation studies, or error analysis in the manuscript, so the central empirical claim cannot be evaluated from the supplied text.
Authors: The full manuscript contains quantitative results, benchmark comparisons, and ablations in the experiments section. However, the abstract itself presents the SOTA claim without metrics or references to specific results. We will revise the abstract to include key quantitative metrics supporting the claim. revision: yes
Circularity Check
No significant circularity; method is an independent proposal
full rationale
The paper presents MASS as a novel framework that reformulates feature scanning along flow-guided trajectories with a velocity-aware SSM and refinement module. No equations, derivations, or self-citations are shown that reduce the claimed performance or states to quantities defined by fitted parameters within the paper itself. The central construction and experimental claims on benchmarks are presented as independent design choices without self-definitional loops, fitted-input predictions, or load-bearing self-citation chains. This is the most common honest finding for a method paper whose claims rest on empirical results rather than closed-form reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Super slomo: High quality estimation of multiple intermediate frames for video interpolation , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[2]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Zooming slow-mo: Fast and accurate one-stage space-time video super-resolution , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[3]
European Conference on Computer Vision , pages=
Film: Frame interpolation for large motion , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[4]
Proceedings of the European Conference on Computer Vision , year=
Video Compression through Image Interpolation , author=. Proceedings of the European Conference on Computer Vision , year=
-
[5]
Proceedings of the 7th ACM International Conference on Multimedia in Asia , pages=
Hint-Guided Video Frame Interpolation for Video Compression , author=. Proceedings of the 7th ACM International Conference on Multimedia in Asia , pages=
-
[6]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Deep Stereo: Learning to Predict New Views from the World's Imagery , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=. 2016 , doi=
2016
-
[7]
ACM Transactions on Graphics , volume=
Learning-Based View Synthesis for Light Field Cameras , author=. ACM Transactions on Graphics , volume=
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Video frame interpolation via direct synthesis with the event-based reference , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Ifrnet: Intermediate feature refine network for efficient frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[10]
European Conference on Computer Vision , pages=
Real-time intermediate flow estimation for video frame interpolation , author=. European Conference on Computer Vision , pages=. 2022 , organization=
2022
-
[11]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Depth-aware video frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Adacof: Adaptive collaboration of flows for video frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Asymmetric bilateral motion estimation for video frame interpolation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[14]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Pwc-net: Cnns for optical flow using pyramid, warping, and cost volume , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[15]
European Conference on Computer Vision , pages=
Raft: Recurrent all-pairs field transforms for optical flow , author=. European Conference on Computer Vision , pages=. 2020 , organization=
2020
-
[16]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Sparse global matching for video frame interpolation with large motion , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[17]
First Conference on Language Modeling , year=
Mamba: Linear-time sequence modeling with selective state spaces , author=. First Conference on Language Modeling , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Vfimamba: Video frame interpolation with state space models , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
LC-Mamba: Local and Continuous Mamba with Shifted Windows for Frame Interpolation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[20]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Video frame interpolation with transformer , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[21]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Extracting motion and appearance via inter-frame attention for efficient video frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Amt: All-pairs multi-field transforms for efficient frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[23]
Advances in Neural Information Processing Systems , volume=
Attention is all you need , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Softmax splatting for video frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[25]
European Conference on Computer Vision , pages=
Enhanced quadratic video interpolation , author=. European Conference on Computer Vision , pages=. 2020 , organization=
2020
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
A unified pyramid recurrent network for video frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[27]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Xvfi: extreme video frame interpolation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[28]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Biformer: Learning bilateral motion estimation via bilateral transformer for 4k video frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[29]
Efficiently Modeling Long Sequences with Structured State Spaces
Efficiently modeling long sequences with structured state spaces , author=. arXiv preprint arXiv:2111.00396 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Vision mamba: Efficient visual representation learning with bidirectional state space model , author=. arXiv preprint arXiv:2401.09417 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Advances in Neural Information Processing Systems , volume=
Vmamba: Visual state space model , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
VCMamba: Bridging Convolutions with Multi-Directional Mamba for Efficient Visual Representation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[33]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Mambavision: A hybrid mamba-transformer vision backbone , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[34]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Many-to-many splatting for efficient video frame interpolation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[35]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Ucf101: A dataset of 101 human actions classes from videos in the wild , author=. arXiv preprint arXiv:1212.0402 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
International Journal of Computer Vision , volume=
Video enhancement with task-oriented flow , author=. International Journal of Computer Vision , volume=. 2019 , publisher=
2019
-
[37]
International Journal of Computer Vision , volume=
A database and evaluation methodology for optical flow , author=. International Journal of Computer Vision , volume=. 2011 , publisher=
2011
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Channel attention is all you need for video frame interpolation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[39]
, howpublished=
Montgomery, Christopher and Lars, H. , howpublished=
-
[40]
IEEE Transactions on Image Processing , volume=
TTVFI: Learning Trajectory-Aware Transformer for Video Frame Interpolation , author=. IEEE Transactions on Image Processing , volume=. 2023 , doi=
2023
-
[41]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Eden: Enhanced diffusion for high-quality large-motion video frame interpolation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[42]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Ldmvfi: Video frame interpolation with latent diffusion models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[43]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Video object segmentation-aware video frame interpolation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.