UNICS: Multilingual Code Search via Unified Pseudocode and Contrastive Transfer Learning
Pith reviewed 2026-06-29 04:06 UTC · model grok-4.3
The pith
UNICS pre-trains on pseudocode to learn cross-lingual code logic then transfers via multi-task contrastive learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UNICS pre-trains on a constructed pseudocode dataset to learn a cross-lingual, algorithm-level logic that preserves full semantic fidelity, then applies a multi-task transfer learning strategy that decomposes code into semantic slices and adds tasks for hard positive mining and cross-lingual dynamic hard negative sampling to adapt the general knowledge to specific languages, producing state-of-the-art results on multilingual and cross-lingual benchmarks with particular strength in zero-shot transfer to low-resource languages.
What carries the argument
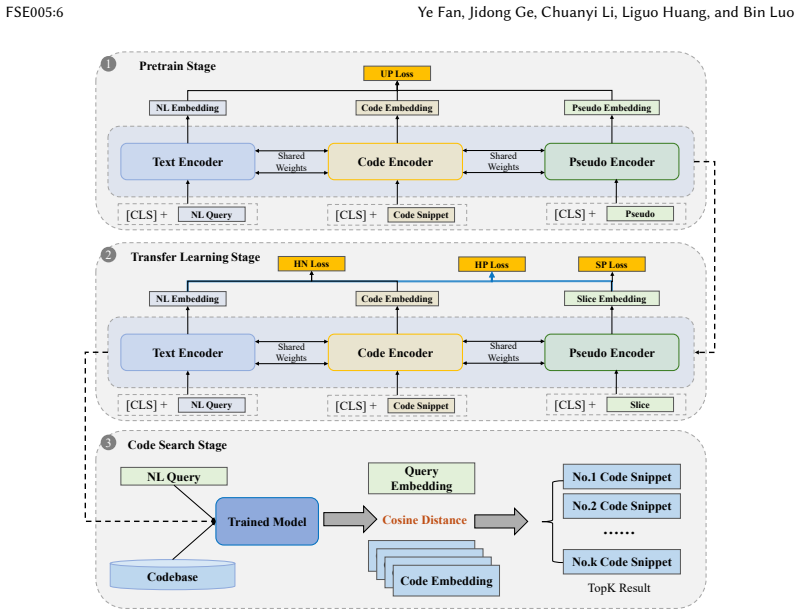
Two-stage training that first uses pseudocode as a unified representation for cross-lingual pre-training and then applies multi-task contrastive transfer with semantic slices and hard mining.
Load-bearing premise
The pseudocode dataset keeps every important semantic detail from the original code and the multi-task transfer step moves knowledge to new languages without creating interference between them.
What would settle it
A new low-resource language benchmark where UNICS scores below current baselines, or a controlled test showing that the pseudocode translation step drops critical semantic information.
Figures


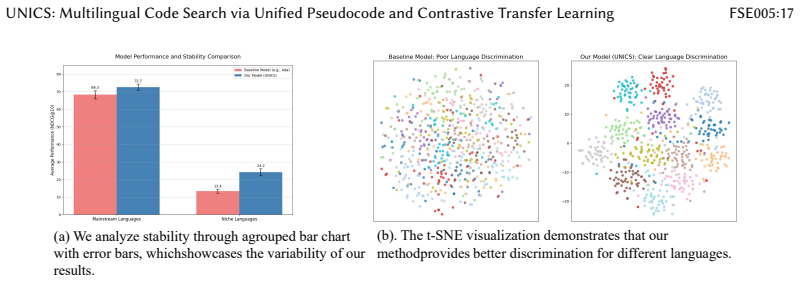
read the original abstract
While pre-trained models have achieved remarkable success in code search, their multilingual capabilities remain a major hurdle, plagued by data imbalance, cross-lingual semantic interference, and the loss of critical information from existing unified representations like Abstract Syntax Trees (ASTs) or Intermediate Representations (IRs). Furthermore, conventional contrastive learning strategies often rely on simplistic hard negative sampling while overlooking the potential of mining hard positives to learn code's intrinsic semantic invariance. To address these challenges, we introduce UNICS, a framework for multilingual code search built on a two-stage training strategy. In the first stage, UNICS is pre-trained on a novel dataset we constructed, which uses pseudo-code as a unified representation to learn a cross-lingual, algorithm-level logic that preserves full semantic fidelity. The second stage employs a multi-task transfer learning strategy that adapts this general knowledge to specific languages by decomposing code into semantic slices (e.g., API calls, function bodies) and incorporating tasks for hard positive mining and cross-lingual dynamic hard negative sampling. Experimental results demonstrate that UNICS achieves state-of-the-art performance across multiple multilingual and cross-lingual benchmarks, showcasing superior generalization and performance balance, especially in zero-shot transfer tasks to low-resource languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UNICS, a two-stage framework for multilingual code search. The first stage pre-trains a model on a novel pseudocode dataset constructed to serve as a unified cross-lingual representation that preserves full semantic fidelity and captures algorithm-level logic. The second stage applies multi-task transfer learning that decomposes code into semantic slices, incorporates hard-positive mining, and uses cross-lingual dynamic hard-negative sampling. The central claim is that this yields state-of-the-art results on multiple multilingual and cross-lingual code-search benchmarks, with particular gains in zero-shot transfer to low-resource languages.
Significance. If the empirical results are reproducible and the pseudocode representation is shown to preserve semantics, the work would offer a concrete route to mitigating data imbalance and cross-lingual interference in code search, with direct relevance to improving retrieval for low-resource languages.
major comments (3)
- [Section 3.1] Section 3.1 (pseudocode dataset construction): no equivalence metric, human validation protocol, or automated semantic-fidelity check is described; the claim that the dataset 'preserves full semantic fidelity' is therefore unsupported, which is load-bearing for both the cross-lingual transfer argument and the zero-shot low-resource results.
- [Section 5] Section 5 (experimental results): the abstract and main text assert SOTA performance yet supply no concrete metrics, baseline names, dataset cardinalities, or statistical significance tests; the central empirical claim cannot be evaluated from the provided evidence.
- [Section 4.2] Section 4.2 (multi-task transfer): the decomposition into semantic slices and the contrastive objectives are introduced without ablation studies that isolate the contribution of hard-positive mining versus dynamic negative sampling, preventing attribution of reported gains to the proposed components.
minor comments (2)
- [Abstract] Abstract: the specific benchmark names and language pairs used for the multilingual and cross-lingual evaluations are not listed.
- Notation: the definition of 'semantic slices' (API calls, function bodies, etc.) would benefit from a short illustrative example in the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, indicating where revisions will be made to strengthen the paper.
read point-by-point responses
-
Referee: [Section 3.1] Section 3.1 (pseudocode dataset construction): no equivalence metric, human validation protocol, or automated semantic-fidelity check is described; the claim that the dataset 'preserves full semantic fidelity' is therefore unsupported, which is load-bearing for both the cross-lingual transfer argument and the zero-shot low-resource results.
Authors: We agree that Section 3.1 does not currently describe an equivalence metric, human validation protocol, or automated semantic-fidelity check, leaving the 'full semantic fidelity' claim unsupported. In the revised manuscript we will expand Section 3.1 to include: (i) an automated equivalence metric based on embedding cosine similarity between original code and pseudocode, (ii) a human validation protocol on a random sample of 500 pairs with reported inter-annotator agreement, and (iii) the results of that validation. These additions will directly support the cross-lingual and zero-shot arguments. revision: yes
-
Referee: [Section 5] Section 5 (experimental results): the abstract and main text assert SOTA performance yet supply no concrete metrics, baseline names, dataset cardinalities, or statistical significance tests; the central empirical claim cannot be evaluated from the provided evidence.
Authors: We acknowledge that the abstract and introductory paragraphs of Section 5 do not list concrete metrics, baseline names, dataset cardinalities, or significance tests, making the SOTA claim difficult to evaluate from those passages alone. We will revise the abstract and the opening of Section 5 to explicitly report key metrics (e.g., MRR on each benchmark), name all baselines, state dataset sizes, and include statistical significance results. The detailed tables already present in Section 5 will remain and be cross-referenced. revision: yes
-
Referee: [Section 4.2] Section 4.2 (multi-task transfer): the decomposition into semantic slices and the contrastive objectives are introduced without ablation studies that isolate the contribution of hard-positive mining versus dynamic negative sampling, preventing attribution of reported gains to the proposed components.
Authors: We agree that the current version of Section 4.2 introduces the multi-task components without ablation studies isolating hard-positive mining from dynamic hard-negative sampling. In the revision we will add a dedicated ablation subsection (or appendix) that reports performance when each component is removed individually and when both are used together, thereby allowing attribution of gains to the proposed techniques. revision: yes
Circularity Check
No circularity; claims rest on external benchmarks and experimental outcomes
full rationale
The paper describes a two-stage training framework evaluated on multilingual code search benchmarks. No equations, fitted parameters, or derivations are present that reduce to inputs by construction. The pseudocode dataset and transfer strategy are presented as inputs to the method, with performance claims tied to external test results rather than self-referential definitions or self-citation chains. This is a standard experimental ML paper with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Github Website
2023. Github Website. https://www.github.com
2023
-
[2]
Code Embedding
2026. Code Embedding. https://bitbucket.org/anonymous_code/code_embedding
2026
-
[3]
Shushan Arakelyan, Anna Hakhverdyan, Miltiadis Allamanis, Luis Garcia, Christophe Hauser, and Xiang Ren. 2022. NS3: Neuro-symbolic Semantic Code Search. (2022). doi:10.52202/068431-0761
-
[4]
Joel Brandt, Mira Dontcheva, Marcos Weskamp, and Scott R. Klemmer. 2010. Example-centric programming: integrating web search into the development environment. InProceedings of the 28th International Conference on Human Factors in Computing Systems, CHI 2010, Atlanta, Georgia, USA, April 10-15, 2010, Elizabeth D. Mynatt, Don Schoner, Geraldine Fitzpatrick,...
-
[5]
Guo, Joel Lewenstein, Mira Dontcheva, and Scott R
Joel Brandt, Philip J. Guo, Joel Lewenstein, Mira Dontcheva, and Scott R. Klemmer. 2009. Two studies of opportunistic programming: interleaving web foraging, learning, and writing code. InProceedings of the 27th International Conference on Human Factors in Computing Systems, CHI 2009, Boston, MA, USA, April 4-9, 2009, Dan R. Olsen Jr., Richard B. Arthur, ...
arXiv 2009
-
[6]
Nghi D. Q. Bui, Yijun Yu, and Lingxiao Jiang. 2021. Self-Supervised Contrastive Learning for Code Retrieval and Summarization via Semantic-Preserving Transformations. InSIGIR ’21: The 44th International ACM SIGIR Conference Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE005. Publication date: July 2026. UNICS: Multilingual Code Search via Unified Pseu...
-
[7]
Róbert Busa-Fekete, György Szarvas, Tamás Elteto, and Balázs Kégl. 2012. An apple-to-apple comparison of learning- to-rank algorithms in terms of normalized discounted cumulative gain. InECAI 2012-20th European Conference on Artificial Intelligence: Preference Learning: Problems and Applications in AI Workshop, Vol. 242. Ios Press
2012
-
[8]
José Cambronero, Hongyu Li, Seohyun Kim, Koushik Sen, and Satish Chandra. 2019. When deep learning met code search. InProceedings of the ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, ESEC/SIGSOFT FSE 2019, Tallinn, Estonia, August 26-30, 2019, Marlon Dumas, Dietmar Pfahl, Sven Apel,...
-
[9]
Brock Angus Campbell and Christoph Treude. 2017. NLP2Code: Code Snippet Content Assist via Natural Language Tasks. In2017 IEEE International Conference on Software Maintenance and Evolution, ICSME 2017, Shanghai, China, September 17-22, 2017. IEEE Computer Society, 628–632. doi:10.1109/ICSME.2017.56
-
[10]
Yitian Chai, Hongyu Zhang, Beijun Shen, and Xiaodong Gu. 2022. Cross-Domain Deep Code Search with Meta Learning. In44th IEEE/ACM 44th International Conference on Software Engineering, ICSE 2022, Pittsburgh, PA, USA, May 25-27, 2022. ACM, 487–498. doi:10.1145/3510003.3510125
-
[11]
Wing-Kwan Chan, Hong Cheng, and David Lo. 2012. Searching connected API subgraph via text phrases. In20th ACM SIGSOFT Symposium on the Foundations of Software Engineering (FSE-20), SIGSOFT/FSE’12, Cary, NC, USA - November 11 - 16, 2012, Will Tracz, Martin P. Robillard, and Tevfik Bultan (Eds.). ACM, 10. doi:10.1145/2393596.2393606
-
[12]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi- lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation.arXiv preprint arXiv:2402.03216(2024). doi:10.48550/arXiv.2402.03216
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03216 2024
-
[13]
Guanyi Chu, Xiao Wang, Chuan Shi, and Xunqiang Jiang. 2021. CuCo: Graph Representation with Curriculum Contrastive Learning.. InIJCAI. 2300–2306. doi:10.24963/ijcai.2021/317
-
[14]
Samip Dahal, Adyasha Maharana, and Mohit Bansal. 2022. Scotch: A Semantic Code Search Engine for IDEs. InDeep Learning for Code Workshop. https://openreview.net/forum?id=rSxfCiOZk-c
2022
-
[15]
Jingtao Ding, Yuhan Quan, Quanming Yao, Yong Li, and Depeng Jin. 2020. Simplify and robustify negative sampling for implicit collaborative filtering.Advances in Neural Information Processing Systems33 (2020), 1094–1105. doi:10. 48550/arXiv.2009.03376
arXiv 2020
-
[16]
Hongchao Fang and Pengtao Xie. 2020. CERT: Contrastive Self-supervised Learning for Language Understanding. CoRRabs/2005.12766 (2020). arXiv:2005.12766 doi:10.48550/arXiv.2005.12766
-
[17]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. In Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020 (Findings of ACL, Vol. EMNLP 2020), Trev...
-
[18]
Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. SimCSE: Simple Contrastive Learning of Sentence Embeddings. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (Ed...
-
[19]
Xiaodong Gu, Hongyu Zhang, and Sunghun Kim. 2018. Deep code search. InProceedings of the 40th International Conference on Software Engineering, ICSE 2018, Gothenburg, Sweden, May 27 - June 03, 2018, Michel Chaudron, Ivica Crnkovic, Marsha Chechik, and Mark Harman (Eds.). ACM, 933–944. doi:10.1145/3180155.3180167
-
[20]
Daya Guo, Shuai Lu, Nan Duan, Yanlin Wang, Ming Zhou, and Jian Yin. 2022. UniXcoder: Unified Cross-Modal Pre-training for Code Representation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, May 22-27, 2022, Smaranda Muresan, Preslav Nakov, and Aline Villavicenci...
-
[21]
Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin B. Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang, and Ming Zhou. 2021. GraphCodeBERT: Pre-training Code Representations with Data Flow. In9th International Conference on Learning Repre...
Pith/arXiv arXiv 2021
-
[22]
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, et al. 2021. Measuring coding challenge competence with apps.arXiv preprint arXiv:2105.09938 (2021). doi:10.48550/arXiv.2105.09938
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2105.09938 2021
-
[23]
Reid Holmes, Rylan Cottrell, Robert J. Walker, and Jörg Denzinger. 2009. The end-to-end use of source code examples: An exploratory study. In25th IEEE International Conference on Software Maintenance (ICSM 2009), September 20-26, Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE005. Publication date: July 2026. FSE005:22 Ye Fan, Jidong Ge, Chuanyi Li, L...
-
[24]
Junjie Huang, Duyu Tang, Linjun Shou, Ming Gong, Ke Xu, Daxin Jiang, Ming Zhou, and Nan Duan. 2021. CoSQA: 20, 000+ Web Queries for Code Search and Question Answering. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volum...
-
[25]
Xiangbing Huang, Yingwei Ma, Haifang Zhou, Zhijie Jiang, Yuanliang Zhang, Teng Wang, and Shanshan Li. 2023. Towards better multilingual code search through cross-lingual contrastive learning. InProceedings of the 14th Asia- Pacific Symposium on Internetware. 22–32. doi:10.1145/3609437.3609439
-
[26]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. CodeSearchNet Challenge: Evaluating the State of Semantic Code Search.CoRRabs/1909.09436 (2019). arXiv:1909.09436 doi:10.48550/ arXiv.1909.09436
Pith/arXiv arXiv 2019
-
[27]
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. 2021. Unsupervised dense information retrieval with contrastive learning.arXiv preprint arXiv:2112.09118 (2021). doi:10.48550/arXiv.2112.09118
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2112.09118 2021
-
[28]
Paras Jain, Ajay Jain, Tianjun Zhang, Pieter Abbeel, Joseph Gonzalez, and Ion Stoica. 2021. Contrastive Code Representation Learning. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, ...
2021
-
[29]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick S. H. Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open-Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, Bonnie Webber, Trevor Cohn, Yulan He, a...
-
[30]
Iman Keivanloo, Juergen Rilling, and Ying Zou. 2014. Spotting working code examples. In36th International Conference on Software Engineering, ICSE ’14, Hyderabad, India - May 31 - June 07, 2014, Pankaj Jalote, Lionel C. Briand, and André van der Hoek (Eds.). ACM, 664–675. doi:10.1145/2568225.2568292
-
[31]
Rui Li, Liyang He, Qi Liu, Yuze Zhao, Zheng Zhang, Zhenya Huang, Yu Su, and Shijin Wang. 2024. Consider: Commonalities and specialties driven multilingual code retrieval framework. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 8679–8687. doi:10.1609/aaai.v38i8.28713
-
[32]
Xiaonan Li, Yeyun Gong, Yelong Shen, Xipeng Qiu, Hang Zhang, Bolun Yao, Weizhen Qi, Daxin Jiang, Weizhu Chen, and Nan Duan. 2022. CodeRetriever: Unimodal and Bimodal Contrastive Learning.CoRRabs/2201.10866 (2022). arXiv:2201.10866 doi:10.48550/arXiv.2201.10866
-
[33]
Xuan Li, Zerui Wang, Qianxiang Wang, Shoumeng Yan, Tao Xie, and Hong Mei. 2016. Relationship-aware code search for JavaScript frameworks. InProceedings of the 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, FSE 2016, Seattle, W A, USA, November 13-18, 2016, Thomas Zimmermann, Jane Cleland-Huang, and Zhendong Su (Eds.). ACM...
-
[34]
Erik Linstead, Sushil Krishna Bajracharya, Trung Chi Ngo, Paul Rigor, Cristina Videira Lopes, and Pierre Baldi. 2009. Sourcerer: mining and searching internet-scale software repositories.Data Min. Knowl. Discov.18, 2 (2009), 300–336. doi:10.1007/S10618-008-0118-X
-
[35]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin B. Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. 2021. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Unders...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2102.04664 2021
-
[36]
Fei Lv, Hongyu Zhang, Jian-Guang Lou, Shaowei Wang, Dongmei Zhang, and Jianjun Zhao. 2015. CodeHow: Effective Code Search Based on API Understanding and Extended Boolean Model (E). In30th IEEE/ACM International Conference on Automated Software Engineering, ASE 2015, Lincoln, NE, USA, November 9-13, 2015, Myra B. Cohen, Lars Grunske, and Michael Whalen (Ed...
-
[37]
Xiaofei Ma, Cícero Nogueira dos Santos, and Andrew O. Arnold. 2021. Contrastive Fine-tuning Improves Robustness for Neural Rankers. InFindings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, August 1-6, 2021 (Findings of ACL, Vol. ACL/IJCNLP 2021), Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (Eds.). Association...
-
[38]
Yingwei Ma, Yue Yu, Shanshan Li, Zhouyang Jia, Jun Ma, Rulin Xu, Wei Dong, and Xiangke Liao. 2023. Mulcs: Towards a unified deep representation for multilingual code search. In2023 IEEE International Conference on Software Analysis, Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE005. Publication date: July 2026. UNICS: Multilingual Code Search via Uni...
-
[39]
Collin McMillan, Mark Grechanik, Denys Poshyvanyk, Chen Fu, and Qing Xie. 2012. Exemplar: A Source Code Search Engine for Finding Highly Relevant Applications.IEEE Trans. Software Eng.38, 5 (2012), 1069–1087. doi:10.1109/TSE. 2011.84
work page doi:10.1109/tse 2012
-
[40]
Collin McMillan, Mark Grechanik, Denys Poshyvanyk, Qing Xie, and Chen Fu. 2011. Portfolio: finding relevant functions and their usage. InProceedings of the 33rd International Conference on Software Engineering, ICSE 2011, Waikiki, Honolulu , HI, USA, May 21-28, 2011, Richard N. Taylor, Harald C. Gall, and Nenad Medvidovic (Eds.). ACM, 111–120. doi:10.1145...
-
[41]
Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, et al. 2022. Text and code embeddings by contrastive pre-training.arXiv preprint arXiv:2201.10005(2022). doi:10.48550/arXiv.2201.10005
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2201.10005 2022
-
[42]
Changan Niu, Chuanyi Li, Bin Luo, and Vincent Ng. 2022. Deep Learning Meets Software Engineering: A Survey on Pre- Trained Models of Source Code. InProceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, Luc De Raedt (Ed.). ijcai.org, 5546–5555. doi:10.24963/IJCAI.2022/775
-
[43]
Luca Ponzanelli, Gabriele Bavota, Massimiliano Di Penta, Rocco Oliveto, and Michele Lanza. 2014. Mining StackOverflow to turn the IDE into a self-confident programming prompter. In11th Working Conference on Mining Software Repositories, MSR 2014, Proceedings, May 31 - June 1, 2014, Hyderabad, India, Premkumar T. Devanbu, Sung Kim, and Martin Pinzger (Eds....
-
[44]
Saksham Sachdev, Hongyu Li, Sifei Luan, Seohyun Kim, Koushik Sen, and Satish Chandra. 2018. Retrieval on source code: a neural code search. InProceedings of the 2nd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, MAPL@PLDI 2018, Philadelphia, PA, USA, June 18-22, 2018, Justin Gottschlich and Alvin Cheung (Eds.). ACM, 31–4...
-
[45]
Ensheng Shi, Wenchao Gu, Yanlin Wang, Lun Du, Hongyu Zhang, Shi Han, Dongmei Zhang, and Hongbin Sun
-
[46]
arXiv:2204.03293 doi:10.48550/ARXIV.2204.03293
Enhancing Semantic Code Search with Multimodal Contrastive Learning and Soft Data Augmentation.CoRR abs/2204.03293 (2022). arXiv:2204.03293 doi:10.48550/ARXIV.2204.03293
-
[47]
Ensheng Shi, Yanlin Wang, Wenchao Gu, Lun Du, Hongyu Zhang, Shi Han, Dongmei Zhang, and Hongbin Sun. 2023. CoCoSoDa: Effective Contrastive Learning for Code Search. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 2198–2210. doi:10.1109/ICSE48619.2023. 00185
-
[48]
Jianhang Shuai, Ling Xu, Chao Liu, Meng Yan, Xin Xia, and Yan Lei. 2020. Improving Code Search with Co-Attentive Representation Learning. InICPC ’20: 28th International Conference on Program Comprehension, Seoul, Republic of Korea, July 13-15, 2020. ACM, 196–207. doi:10.1145/3387904.3389269
-
[49]
Islam, Iman Keivanloo, Chanchal Kumar Roy, and Mohammad Mamun Mia
Jeffrey Svajlenko, Judith F. Islam, Iman Keivanloo, Chanchal Kumar Roy, and Mohammad Mamun Mia. 2014. Towards a Big Data Curated Benchmark of Inter-project Code Clones. In30th IEEE International Conference on Software Maintenance and Evolution, Victoria, BC, Canada, September 29 - October 3, 2014. IEEE Computer Society, 476–480. doi:10.1109/ICSME.2014.77
-
[50]
Alexey Svyatkovskiy, Shao Kun Deng, Shengyu Fu, and Neel Sundaresan. 2020. IntelliCode compose: code generation using transformer. InESEC/FSE ’20: 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Virtual Event, USA, November 8-13, 2020, Prem Devanbu, Myra B. Cohen, and Thomas Zimmermann (Eds...
-
[51]
Yao Wan, Jingdong Shu, Yulei Sui, Guandong Xu, Zhou Zhao, Jian Wu, and Philip S. Yu. 2019. Multi-modal Attention Network Learning for Semantic Source Code Retrieval. In34th IEEE/ACM International Conference on Automated Software Engineering, ASE 2019, San Diego, CA, USA, November 11-15, 2019. IEEE, 13–25. doi:10.1109/ASE.2019.00012
-
[52]
Wenhan Wang, Ge Li, Bo Ma, Xin Xia, and Zhi Jin. 2020. Detecting Code Clones with Graph Neural Network and Flow- Augmented Abstract Syntax Tree. In27th IEEE International Conference on Software Analysis, Evolution and Reengineering, SANER 2020, London, ON, Canada, February 18-21, 2020, Kostas Kontogiannis, Foutse Khomh, Alexander Chatzigeorgiou, Marios-El...
-
[53]
Xin Wang, Yasheng Wang, Fei Mi, Pingyi Zhou, Yao Wan, Xiao Liu, Li Li, Hao Wu, Jin Liu, and Xin Jiang. 2021. Syncobert: Syntax-guided multi-modal contrastive pre-training for code representation.arXiv preprint arXiv:2108.04556 (2021). doi:10.48550/arXiv.2108.04556
-
[54]
Yining Wang, Liwei Wang, Yuanzhi Li, Di He, and Tie-Yan Liu. 2013. A Theoretical Analysis of NDCG Type Ranking Measures. InCOLT 2013 - The 26th Annual Conference on Learning Theory, June 12-14, 2013, Princeton University, NJ, USA (JMLR Workshop and Conference Proceedings, Vol. 30), Shai Shalev-Shwartz and Ingo Steinwart (Eds.). JMLR.org, 25–54. doi:10.485...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1304.6480 2013
-
[55]
Yue Wang, Weishi Wang, Shafiq R. Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Understanding and Generation. InProceedings of the 2021 Conference on Em- pirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 Proc. ACM Softw. Eng., Vol...
-
[56]
Jun Xia, Lirong Wu, Ge Wang, Jintao Chen, and Stan Z Li. 2021. Progcl: Rethinking hard negative mining in graph contrastive learning.arXiv preprint arXiv:2110.02027(2021). doi:10.48550/arXiv.2110.02027
-
[57]
Huang Xie, Okko Räsänen, and Tuomas Virtanen. 2023. On negative sampling for contrastive audio-text retrieval. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 1–5. doi:10.1109/ICASSP49357.2023.10095319
-
[58]
Shuhan Yan, Hang Yu, Yuting Chen, Beijun Shen, and Lingxiao Jiang. 2020. Are the Code Snippets What We Are Searching for? A Benchmark and an Empirical Study on Code Search with Natural-Language Queries. In27th IEEE International Conference on Software Analysis, Evolution and Reengineering, SANER 2020, London, ON, Canada, February 18-21, 2020, Kostas Konto...
-
[59]
Weixiang Yan, Yuchen Tian, Yunzhe Li, Qian Chen, and Wen Wang. 2023. Codetransocean: A comprehensive multilingual benchmark for code translation.arXiv preprint arXiv:2310.04951(2023). doi:10.48550/arXiv.2310.04951
-
[60]
Hongyu Zhang, Anuj Jain, Gaurav Khandelwal, Chandrashekhar Kaushik, Scott Ge, and Wenxiang Hu. 2016. Bing developer assistant: improving developer productivity by recommending sample code. InProceedings of the 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, FSE 2016, Seattle, W A, USA, November 13-18, 2016, Thomas Zimmerma...
-
[61]
Zhilu Zhang and Mert R. Sabuncu. 2018. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. InAdvances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Graum...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1805.07836 2018
-
[62]
Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. 2024. Opencodeinterpreter: Integrating code generation with execution and refinement.arXiv preprint arXiv:2402.14658 (2024). doi:10.48550/arXiv.2402.14658
-
[63]
Jing Zhou and Robert J. Walker. 2016. API deprecation: a retrospective analysis and detection method for code examples on the web. InProceedings of the 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, FSE 2016, Seattle, W A, USA, November 13-18, 2016, Thomas Zimmermann, Jane Cleland-Huang, and Zhendong Su (Eds.). ACM, 266–2...
-
[64]
Ming Zhu, Aneesh Jain, Karthik Suresh, Roshan Ravindran, Sindhu Tipirneni, and Chandan K. Reddy. 2022. XLCoST: A Benchmark Dataset for Cross-lingual Code Intelligence. arXiv:2206.08474 doi:10.48550/arXiv.2206.08474 Received 2025-09-12; accepted 2025-12-22 Proc. ACM Softw. Eng., Vol. 3, No. FSE, Article FSE005. Publication date: July 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.