SpikeVLA: Vision-Language-Action Models with Spiking Neural Networks
Pith reviewed 2026-06-29 04:39 UTC · model grok-4.3
The pith
SpikeVLA replaces dense transformer layers with event-driven spiking networks across vision, language, and action to lower energy use in robotic tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
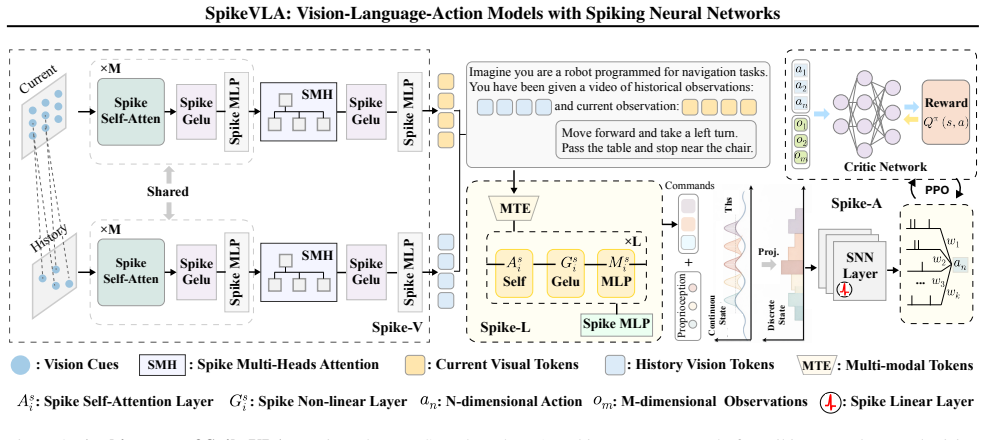
SpikeVLA consists of Spike-V, a spiking vision encoder using event-driven layers; Spike-L, a multi-modal spiking large language model with token-level event-driven sparsity; and Spike-A, a spiking action policy network based on Laplacian-kernel population coding in a multi-layer fully connected SNN that decodes to continuous control signals. Together these enable energy-efficient inference for embodied tasks.
What carries the argument
Three-component spiking VLA architecture (Spike-V, Spike-L, Spike-A) that substitutes event-driven spiking dynamics for dense continuous computation in each modality.
If this is right
- Robotic systems can run VLA policies on lower-power hardware with reduced inference cost.
- Token-level sparsity in the language component further cuts computation during cross-modal reasoning.
- Laplacian-kernel population coding produces stable continuous actions from spiking activity.
- The overall design supports real-time embodied intelligence under strict energy budgets.
Where Pith is reading between the lines
- Hybrid spiking-traditional networks could be explored where full spiking proves insufficient for certain modalities.
- The approach may generalize to other sequential decision tasks beyond navigation if the sparsity patterns transfer.
- Energy measurements on actual neuromorphic hardware would provide a direct test of the claimed savings.
Load-bearing premise
Event-driven spiking layers can maintain sufficient representational capacity and cross-modal alignment in vision, language, and action modules to support effective embodied reasoning and control.
What would settle it
An experiment measuring that SpikeVLA accuracy on standard navigation or manipulation benchmarks falls more than a small margin below a matched transformer VLA baseline while energy measurements are recorded.
Figures



read the original abstract
Vision-Language-Action (VLA) models have become a dominant paradigm for embodied intelligence. However, most existing approaches are built on large-scale transformers, resulting in substantial inference latency and energy consumption that limit their practical deployment in low-power, real-time scenarios. We propose SpikeVLA, a spiking VLA architecture for embodied navigation with energy-efficient inference, consisting of three key components. (i) A spiking vision encoder, Spike-V, that replaces dense continuous layers with event-driven spiking layers to reduce the energy consumption of visual representation learning. (ii) A multi-modal spiking large language model, Spike-L, that reformulates cross-modal reasoning with spiking dynamics and token-level event-driven sparsity to further lower computational cost. (iii) A spiking action policy network, Spike-A employs Laplacian-kernel population coding with a multi-layer fully connected SNN, and decodes spiking activities into stable and robust continuous control with energy-efficient inference under low-power constraints. Experiments on navigation and robotic control tasks show that SpikeVLA significantly reduces energy consumption and computational cost while maintaining competitive performance, highlighting its potential for low-power, real-time embodied intelligence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
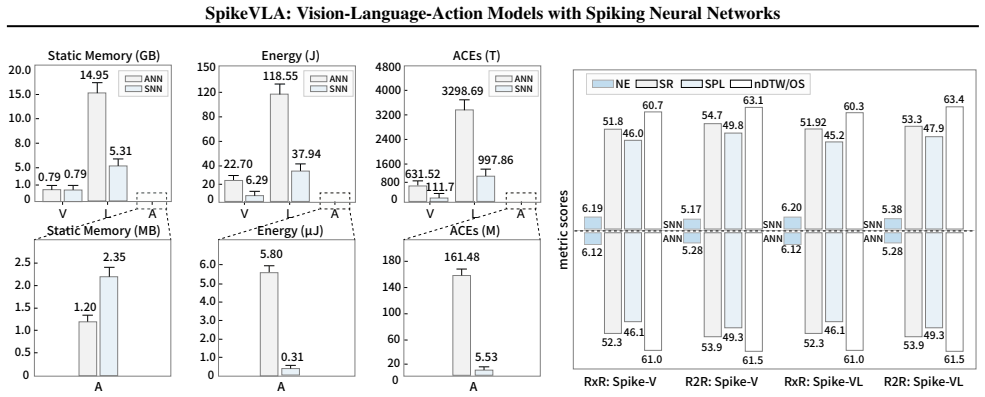
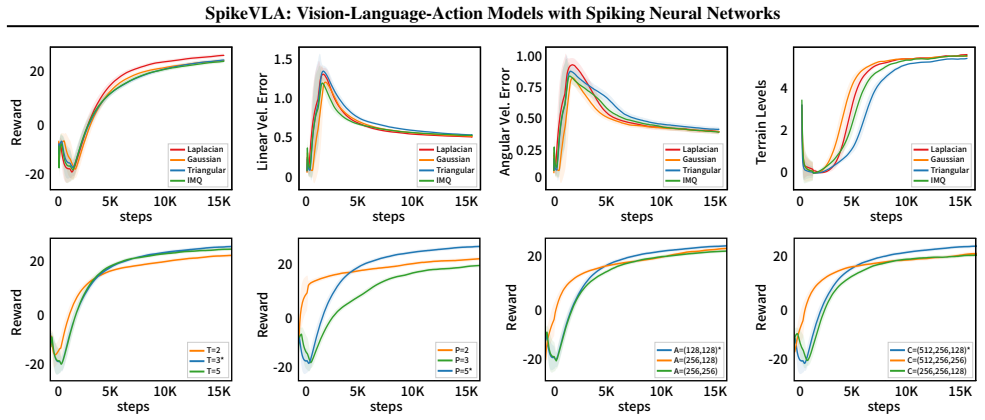
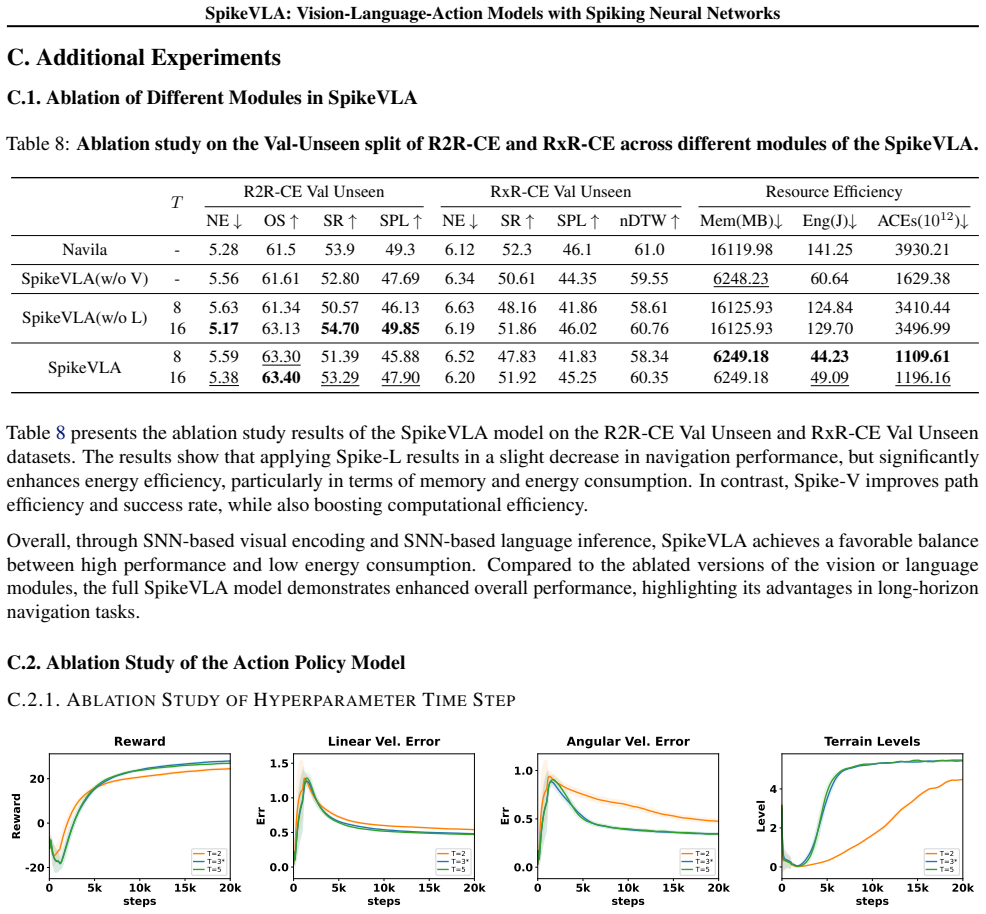
Summary. The paper proposes SpikeVLA, a spiking neural network architecture for vision-language-action models in embodied navigation. It replaces standard transformer components with three spiking elements: a spiking vision encoder (Spike-V), a multi-modal spiking LLM (Spike-L) using token-level event-driven sparsity, and a spiking action policy (Spike-A) based on Laplacian-kernel population coding in a multi-layer SNN. The central claim is that this yields substantially lower energy consumption and computational cost while preserving competitive performance on navigation and robotic control tasks.
Significance. If the experimental claims hold with rigorous validation, the work could meaningfully advance low-power, real-time embodied AI by demonstrating that spiking dynamics can be integrated across vision, language, and action modules without prohibitive loss in cross-modal reasoning capacity. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described.
major comments (2)
- [Abstract] Abstract: the claim that experiments 'show that SpikeVLA significantly reduces energy consumption and computational cost while maintaining competitive performance' is presented without any quantitative metrics, baselines, error bars, ablation results, or task specifications. This absence makes the central empirical claim impossible to evaluate from the provided text.
- [Abstract] Abstract: the assumption that event-driven spiking layers in Spike-V, Spike-L, and Spike-A can preserve sufficient representational capacity and cross-modal alignment is stated but not supported by any architectural details, training procedure, or preliminary evidence that would allow assessment of whether the energy savings come at an acceptable performance cost.
minor comments (1)
- [Abstract] The abstract refers to 'navigation and robotic control tasks' without naming the specific benchmarks, datasets, or evaluation protocols used.
Simulated Author's Rebuttal
We thank the referee for the detailed comments on the abstract. We address each point below and will revise the abstract accordingly to improve clarity and support for the central claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that experiments 'show that SpikeVLA significantly reduces energy consumption and computational cost while maintaining competitive performance' is presented without any quantitative metrics, baselines, error bars, ablation results, or task specifications. This absence makes the central empirical claim impossible to evaluate from the provided text.
Authors: We agree that the abstract would be strengthened by including representative quantitative metrics. The full manuscript reports specific results on navigation and robotic control tasks, including energy consumption reductions relative to transformer-based VLA baselines and task success rates with standard deviations. In the revision, we will incorporate key figures (e.g., energy savings and performance deltas) directly into the abstract while respecting length constraints. revision: yes
-
Referee: [Abstract] Abstract: the assumption that event-driven spiking layers in Spike-V, Spike-L, and Spike-A can preserve sufficient representational capacity and cross-modal alignment is stated but not supported by any architectural details, training procedure, or preliminary evidence that would allow assessment of whether the energy savings come at an acceptable performance cost.
Authors: The abstract is a concise summary; the manuscript body details the Spike-V encoder, Spike-L with token-level event-driven sparsity for cross-modal reasoning, and Spike-A with Laplacian-kernel population coding, including training procedures and ablation studies that quantify the trade-off between energy efficiency and task performance. To address the comment, we will add a brief clause in the revised abstract referencing these mechanisms and the empirical validation of preserved capacity. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper is an architectural proposal for SpikeVLA with three spiking components (Spike-V, Spike-L, Spike-A) and reports empirical results on energy reduction and performance on navigation/control tasks. No mathematical derivations, equations, first-principles predictions, or fitted parameters labeled as independent results appear in the provided text. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on experimental benchmarks rather than any chain that reduces to its own inputs by construction, making the work self-contained with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An, D., Qi, Y ., Li, Y ., Huang, Y ., Wang, L., Tan, T., and Shao, J. Bevbert: Multimodal map pre-training for language- guided navigation.arXiv preprint arXiv:2212.04385,
-
[2]
Navila: Legged robot vision-language- action model for navigation,
Cheng, A.-C., Ji, Y ., Yang, Z., Gongye, Z., Zou, X., Kautz, J., Bıyık, E., Yin, H., Liu, S., and Wang, X. Navila: Legged robot vision-language-action model for naviga- tion.arXiv preprint arXiv:2412.04453,
-
[3]
Vl-nav: real-time vision-language navigation with spatial reasoning.arXiv preprint arXiv:2502.00931,
Du, Y ., Fu, T., Chen, Z., Li, B., Su, S., Zhao, Z., and Wang, C. Vl-nav: real-time vision-language navigation with spatial reasoning.arXiv preprint arXiv:2502.00931,
-
[4]
Differential coding for training-free ann-to-snn conversion.arXiv preprint arXiv:2503.00301,
Huang, Z., Fang, W., Bu, T., Xue, P., Hao, Z., Liu, W., Tang, Y ., Yu, Z., and Huang, T. Differential coding for training-free ann-to-snn conversion.arXiv preprint arXiv:2503.00301,
-
[5]
Long, Y ., Cai, W., Wang, H., Zhan, G., and Dong, H. Instructnav: Zero-shot system for generic instruction navigation in unexplored environment.arXiv preprint arXiv:2406.04882,
-
[6]
Oh, H. and Lee, Y . Sign gradient descent-based neuronal dynamics: Ann-to-snn conversion beyond relu network. arXiv preprint arXiv:2407.01645,
-
[7]
Language-aligned waypoint (law) supervision for vision- and-language navigation in continuous environments
Raychaudhuri, S., Wani, S., Patel, S., Jain, U., and Chang, A. Language-aligned waypoint (law) supervision for vision- and-language navigation in continuous environments. In Proceedings of the 2021 conference on empirical methods in natural language processing, pp. 4018–4028,
2021
-
[8]
Deep reinforcement learning with population-coded spiking neural network for continuous control
10 SpikeVLA: Vision-Language-Action Models with Spiking Neural Networks Tang, G., Kumar, N., Yoo, R., and Michmizos, K. Deep reinforcement learning with population-coded spiking neural network for continuous control. InConference on robot learning, pp. 2016–2029. PMLR,
2016
-
[9]
Wei, M., Wan, C., Yu, X., Wang, T., Yang, Y ., Mao, X., Zhu, C., Cai, W., Wang, H., Chen, Y ., et al. Streamvln: Stream- ing vision-and-language navigation via slowfast context modeling.arXiv preprint arXiv:2507.05240,
-
[10]
A., Xiao, S., Du, L., Li, G., and Zhang, J
Xing, X., Gao, B., Zhang, Z., Clifton, D. A., Xiao, S., Du, L., Li, G., and Zhang, J. Spikellm: Scaling up spiking neural network to large language models via saliency- based spiking.arXiv preprint arXiv:2407.04752, 2024a. Xing, X., Zhang, Z., Ni, Z., Xiao, S., Ju, Y ., Fan, S., Wang, Y ., Zhang, J., and Li, G. Spikelm: Towards general spike-driven langua...
-
[11]
Yu, Z., Long, Y ., Yang, Z., Zeng, C., Fan, H., Zhang, J., and Dong, H. Correctnav: Self-correction flywheel empowers vision-language-action navigation model.arXiv preprint arXiv:2508.10416,
-
[12]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Zhang, D., Zhang, T., Jia, S., and Xu, B. Multi-scale dy- namic coding improved spiking actor network for rein- forcement learning. InProceedings of the AAAI con- ference on artificial intelligence, volume 36, pp. 59–67, 2022a. Zhang, J., Wang, K., Wang, S., Li, M., Liu, H., Wei, S., Wang, Z., Zhang, Z., and Wang, H. Uni-navid: A video- based vision-langu...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
11 SpikeVLA: Vision-Language-Action Models with Spiking Neural Networks A. Dataset & Metric Details A.1. Dataset. To comprehensively evaluate our method for vision-and-language navigation, we conduct experiments on three benchmarks: R2R-CE, RxR-CE, and VLN-CE-Isaac. R2R-CE is a continuous-control VLN benchmark set in photorealistic, reconstructed indoor e...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.