Phase Matters: Characterizing Heterogeneous Vision-Language Inference on a Mobile SoC
Pith reviewed 2026-06-29 02:13 UTC · model grok-4.3
The pith
NPU speedups for vision-language models on mobile SoCs depend on the inference phase, with larger benefits in prefill than decode that improve temperature and energy use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
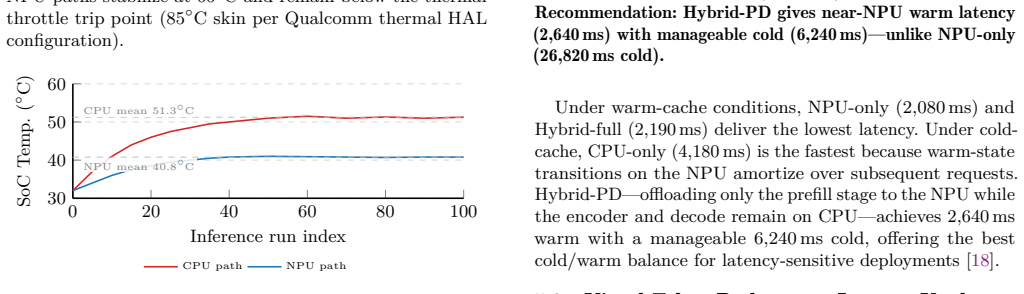
On the Snapdragon 8 Elite, NPU execution for FastVLM-0.5B delivers 1.64x speedup in prefill but only 1.18x in decode compared to CPU, while vision encoders from four families run 20-45x faster on NPU. These phase-specific gains produce 10.47 degrees C lower steady-state temperature and 2.52x lower energy, preventing thermal throttling. A four-step graph rewrite further allows unsupported encoders such as Phi-3.5-V to achieve up to 22x speedup on the NPU path.
What carries the argument
Phase-dependent NPU execution for VLM pipelines, distinguishing prefill and decode stages along with a four-step graph rewrite for encoder support.
If this is right
- Optimal mapping of VLM components to NPU requires separate consideration of prefill and decode phases.
- Vision encoders should be offloaded to NPU for the highest performance returns.
- Always-on VLM applications can avoid thermal throttling through NPU use.
- Energy consumption drops by a factor of 2.52 with heterogeneous execution.
- Unsupported encoders can be enabled for NPU with a repeatable four-step porting process.
Where Pith is reading between the lines
- Phase-aware hardware schedulers could further improve efficiency on future mobile chips.
- The observed effects may apply to other autoregressive models that separate input processing from generation.
- Similar graph modifications might unlock NPU paths for additional operators in other ML runtimes.
- Characterizing cache-state effects and token-budget sensitivity provides a template for evaluating new SoCs.
Load-bearing premise
The speedups, temperature reductions, and energy savings measured on the SM8750 with FastVLM-0.5B and four encoder families will hold for other mobile SoCs, model sizes, and VLM pipelines.
What would settle it
Repeating the 100-run thermal and energy measurements on a different mobile SoC with comparable NPU capabilities and observing no significant temperature or energy difference between CPU-only and heterogeneous configurations.
Figures



read the original abstract
Recent phone-class mobile SoCs expose practical NPU execution paths for on-device vision-language model (VLM) inference, but developers still lack phase-level guidance for mapping VLM pipelines across heterogeneous backends. We present a hardware-in-the-loop characterization of VLM inference on the Qualcomm SM8750 (Snapdragon 8 Elite), covering phase throughput, cache-state effects, 100-run thermal stability, energy, heterogeneous CPU/NPU pipeline configurations, and visual-token-budget sensitivity. Using FastVLM-0.5B as an end-to-end case study, together with encoder-only measurements across four architecture families, we show that phase matters: NPU execution is highly phase-dependent, delivering 1.64x speedup for prefill but only 1.18x for decode, while vision encoders achieve 20-45x speedups over CPU. These gains translate into 10.47 degrees C lower steady-state temperature and 2.52x lower energy, avoiding thermal throttling in always-on settings. Finally, we show that a four-step graph rewrite enables previously unsupported encoders, such as Phi-3.5-V, to reach the QNN path with up to 22x speedup, providing a practical porting recipe for mobile VLM deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a hardware-in-the-loop characterization of VLM inference on the Qualcomm SM8750 SoC using FastVLM-0.5B as case study and four encoder families. It reports that NPU execution is phase-dependent (1.64x speedup for prefill vs. 1.18x for decode), vision encoders achieve 20-45x speedups over CPU, these translate to 10.47°C lower steady-state temperature and 2.52x lower energy (avoiding thermal throttling), and a four-step graph rewrite enables previously unsupported encoders such as Phi-3.5-V to reach the QNN path with up to 22x speedup.
Significance. If the measurements hold, the work supplies concrete phase-level performance data and a practical porting recipe for on-device VLM deployment on mobile SoCs. The 100-run thermal stability measurements and heterogeneous pipeline configurations are strengths that could inform always-on mobile AI design.
major comments (2)
- [Abstract] Abstract: the central quantitative claims (1.64x prefill / 1.18x decode speedups, 10.47°C temperature reduction, 2.52x energy reduction) are presented without error bars, variance statistics, or details on the 100-run methodology, data exclusion rules, or raw traces; this directly affects the reliability of the performance and thermal results that underpin the phase-dependence conclusion.
- The broader claim that the observed phase-dependent effects and thermal/energy gains apply to 'typical VLM pipelines' and 'mobile VLM deployment' rests on a single SoC (SM8750) and narrow model set; a concrete test such as replication on a second mobile SoC would be required to rule out hardware-specific artifacts in cache-state or interconnect behavior.
minor comments (1)
- [Abstract] The abstract lists 'four architecture families' but does not name them; adding this detail would improve clarity without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, providing clarifications and indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central quantitative claims (1.64x prefill / 1.18x decode speedups, 10.47°C temperature reduction, 2.52x energy reduction) are presented without error bars, variance statistics, or details on the 100-run methodology, data exclusion rules, or raw traces; this directly affects the reliability of the performance and thermal results that underpin the phase-dependence conclusion.
Authors: We agree that additional statistical details would strengthen the presentation. Section 4.3 already describes the 100-run thermal stability protocol, but the revision will expand this with error bars and standard deviations on all reported speedups, temperature, and energy figures; explicit data exclusion rules (e.g., 3-sigma outlier removal); and a note that raw traces are available upon request. The abstract will be updated to reference the expanded methodology section. revision: yes
-
Referee: The broader claim that the observed phase-dependent effects and thermal/energy gains apply to 'typical VLM pipelines' and 'mobile VLM deployment' rests on a single SoC (SM8750) and narrow model set; a concrete test such as replication on a second mobile SoC would be required to rule out hardware-specific artifacts in cache-state or interconnect behavior.
Authors: The manuscript frames the work as a hardware-in-the-loop case study on the SM8750 using FastVLM-0.5B and four encoder families; it does not assert that the exact quantitative results hold for all mobile SoCs. We will add explicit qualifying language in the introduction, discussion, and conclusion to emphasize platform specificity and note potential cache/interconnect artifacts. Replication on additional SoCs lies outside the current experimental scope. revision: partial
- Replication on a second mobile SoC to empirically rule out hardware-specific artifacts
Circularity Check
No circularity: purely empirical measurements with no derivations or self-referential predictions
full rationale
The paper is a hardware characterization study reporting measured throughput, thermal, and energy values on the SM8750 SoC for specific VLM pipelines. It contains no equations, fitted parameters, predictions, or derivations that could reduce to the paper's own inputs by construction. No self-citation chains, uniqueness theorems, or ansatzes are invoked to support central claims; all results are direct experimental observations. This matches the default expectation of no significant circularity for self-contained empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
FastVLM: Efficient vision encoding for vision language models,
P. Bhattet al., “FastVLM: Efficient vision encoding for vision language models,”CVPR, 2025
2025
-
[2]
MobileVLM : A Fast, Strong and Open Vision Language Assistant for Mobile Devices
X. Chuet al., “MobileVLM: A fast, reproducible and strong vision language assistant for mobile devices,”arXiv:2312.16886, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
TextGrad: Automatic "Differentiation" via Text
H. Yuanet al., “LiteVLM: Lightweight vision-language models for edge deployment,”arXiv:2406.07496, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Microsoft Research, “Phi-3 technical report: A highly capable language model locally on your phone,”arXiv:2404.14219, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiyet al., “An image is worth 16x16 words: Trans- formers for image recognition at scale,”ICLR, 2021
2021
-
[6]
SmolVLM: Redefining small and efficient multimodal models
H. Laurençonet al., “NanoVLM: Efficient vision-language models you can train and deploy on the edge,”arXiv:2504.05299, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Gemma 3n: An efficient multimodal model for edge devices,
Google DeepMind, “Gemma 3n: An efficient multimodal model for edge devices,” Technical Report, 2025
2025
-
[8]
J. Baiet al., “Qwen technical report,”arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wanget al., “Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution,”arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Learning transferable visual models from natural language supervision,
A. Radfordet al., “Learning transferable visual models from natural language supervision,”ICML, 2021
2021
-
[11]
Sigmoid loss for language image pre-training,
X. Zhaiet al., “Sigmoid loss for language image pre-training,” ICCV, 2023
2023
-
[12]
Snapdragon 8 Elite mobile plat- form product brief,
Qualcomm Technologies, Inc., “Snapdragon 8 Elite mobile plat- form product brief,” 2024
2024
-
[13]
Unlocking on-device generative AI with an NPU and heterogeneous computing,
Qualcomm Technologies, Inc., “Unlocking on-device generative AI with an NPU and heterogeneous computing,” 2024
2024
-
[14]
Qualcomm AI Engine direct: QNN SDK documentation,
Qualcomm Technologies, Inc., “Qualcomm AI Engine direct: QNN SDK documentation,” 2024
2024
-
[15]
LiteRT: Lightweight runtime for on-device inference,
Google, “LiteRT: Lightweight runtime for on-device inference,” https://ai.google.dev/edge/litert, 2024
2024
-
[16]
Fast on-device LLM inference with NPUs,
D. Xuet al., “Fast on-device LLM inference with NPUs,”ASP- LOS, 2025
2025
-
[17]
Characterizing mobile SoC for accelerating het- erogeneous LLM inference,
L. Chenet al., “Characterizing mobile SoC for accelerating het- erogeneous LLM inference,”SOSP, 2025
2025
-
[18]
NNV12: An efficient on-device inference framework for mobile vision tasks,
Z. Caoet al., “NNV12: An efficient on-device inference framework for mobile vision tasks,”MobiSys, 2024
2024
-
[19]
PASK: Preloaded-and-shared kernel for fast on- device DNN inference,
H. Liuet al., “PASK: Preloaded-and-shared kernel for fast on- device DNN inference,”MobiCom, 2024
2024
-
[20]
LLM.int8(): 8-bit matrix multiplication for transformers at scale,
T. Dettmerset al., “LLM.int8(): 8-bit matrix multiplication for transformers at scale,”NeurIPS, 2022
2022
-
[21]
AWQ: Activation-aware weight quantization for LLM compression and acceleration,
J. Linet al., “AWQ: Activation-aware weight quantization for LLM compression and acceleration,”MLSys, 2024
2024
-
[22]
FlashAttention: Fast and memory-efficient exact attention with IO-awareness,
T. Daoet al., “FlashAttention: Fast and memory-efficient exact attention with IO-awareness,”NeurIPS, 2022
2022
-
[23]
GQA: Training generalized multi-query trans- former models from multi-head checkpoints,
J. Ainslieet al., “GQA: Training generalized multi-query trans- former models from multi-head checkpoints,”EMNLP, 2023
2023
-
[24]
RoFormer: Enhanced transformer with rotary posi- tion embedding,
J. Suet al., “RoFormer: Enhanced transformer with rotary posi- tion embedding,”Neurocomputing, 2024
2024
-
[25]
ExecuTorch: On-device AI across mobile, embedded and edge for PyTorch,
Meta AI, “ExecuTorch: On-device AI across mobile, embedded and edge for PyTorch,” https://pytorch.org/executorch/, 2024
2024
-
[26]
MLC-LLM: Universal LLM deployment engine with ML compilation,
T. Chenet al., “MLC-LLM: Universal LLM deployment engine with ML compilation,”arXiv:2404.09542, 2024
-
[27]
TensorFlow Lite delegates,
Google, “TensorFlow Lite delegates,” https://www.tensorflow. org/lite/performance/delegates, 2024
2024
-
[28]
Roofline: An insightful visual performance model for multicore architectures,
S. Williamset al., “Roofline: An insightful visual performance model for multicore architectures,”CACM, 52(4):65–76, 2009
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.