TA-SparseMG: Trend-Aware Sparse Forecasting via Multi-Scale Gating for Long-Term Time Series
Pith reviewed 2026-06-29 04:25 UTC · model grok-4.3
The pith
TA-SparseMG adds trend-aware normalization, scale-adaptive gated denoising, and multiscale gated-attention MLP to SparseTSF to handle nonstationarity and cross-period dependencies in long-term forecasts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
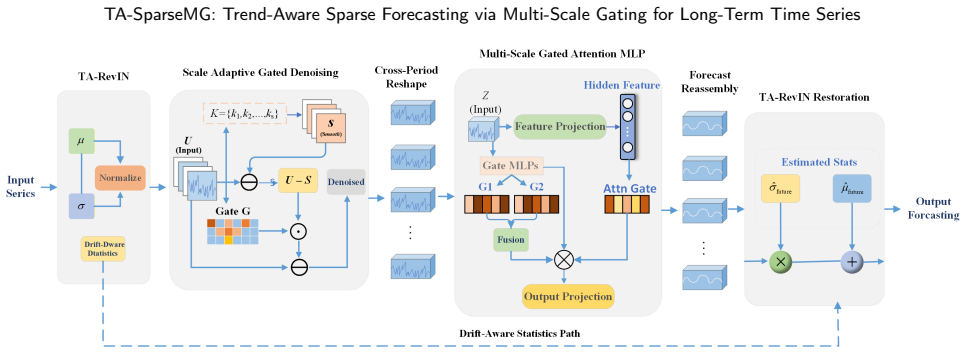
TA-SparseMG is a lightweight cross-period forecasting model built on SparseTSF's sparse cross-period modeling framework. It incorporates a trend-aware reversible instance normalization module that captures input-window statistics and calibrates forecast-window distributions to mitigate distribution shift, a scale-adaptive gated denoising module that performs feature smoothing and residual suppression before period rearrangement to reduce interference from high-frequency perturbations, and a multiscale gated-attention MLP forecasting module that strengthens the prediction head's adaptive representational capacity via conditional gating and feature modulation. Extensive experiments across mult
What carries the argument
The three modules (trend-aware reversible instance normalization, scale-adaptive gated denoising, and multiscale gated-attention MLP) added to SparseTSF's sparse cross-period modeling framework to address nonstationarity, perturbations, and dependencies.
If this is right
- The trend-aware normalization reduces mismatch between training and forecast window distributions.
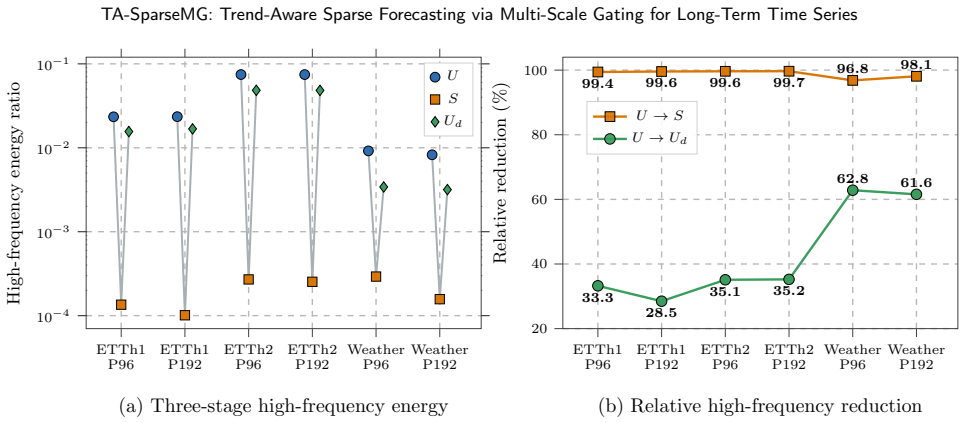
- The gated denoising step suppresses high-frequency noise prior to period rearrangement.
- The multiscale gated-attention MLP increases the prediction head's ability to adapt representations conditionally.
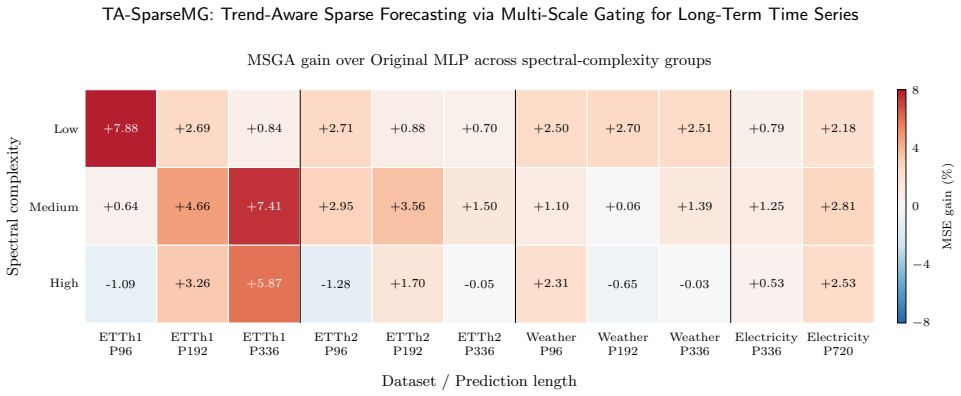
- Ablation results indicate that removing any one module degrades robustness or adaptation on the tested benchmarks.
- The overall model maintains lightweight parameter counts while delivering higher forecast accuracy than the base SparseTSF framework.
Where Pith is reading between the lines
- Similar gating and normalization layers could be tested on other sparse or period-based forecasting architectures to check transferability.
- The approach might be extended to handle streaming data where distribution shifts occur continuously rather than in fixed windows.
- If the modules prove robust, they could reduce reliance on heavier transformer-based models for resource-constrained forecasting deployments.
Load-bearing premise
The three added modules each independently mitigate distribution shift, high-frequency perturbations, and cross-period mapping limitations as described without confounding factors in the experimental setup.
What would settle it
A replication on the same LTSF benchmarks that finds no statistically significant accuracy gain when the three modules are added individually to SparseTSF would falsify the claim that the modules produce the reported improvements.
Figures
read the original abstract
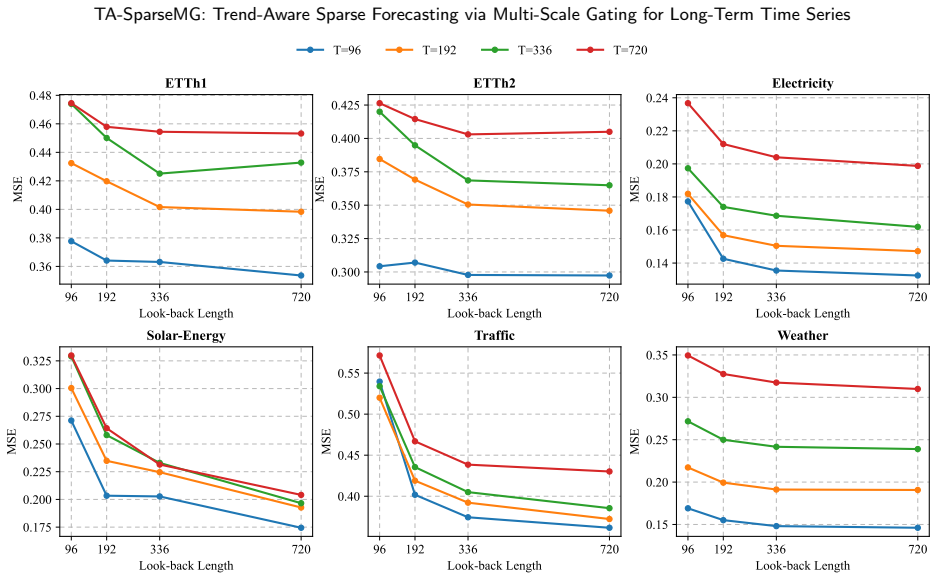
Long-term time series forecasting finds extensive applications in domains such as power demand, traffic flow, meteorological observation, and renewable energy dispatch. Forecasting dynamically varying long-term time series poses inherent challenges, including statistical nonstationarity, local high-frequency disturbances, and coupled cross-period dependencies, which make it difficult for lightweight models to balance parameter efficiency and forecasting performance. To address this issue, this study presents TA-SparseMG, a lightweight cross-period forecasting model built on SparseTSF's sparse cross-period modeling framework. It incorporates three key modules: a trend-aware reversible instance normalization module, a scale-adaptive gated denoising module, and a multiscale gated-attention MLP forecasting module. The trend-aware normalization module captures input-window statistics and calibrates forecast-window distributions, effectively mitigating distribution shift. The scale-adaptive gated denoising module performs feature smoothing and residual suppression before period rearrangement, thereby reducing interference from high-frequency perturbations. The multiscale gated attention prediction module strengthens the prediction head's adaptive representational capacity via conditional gating and feature modulation. Extensive experiments across multiple LTSF benchmarks demonstrate that the proposed TA-SparseMG consistently achieves superior, stable performance. Ablation studies confirm that each module independently improves distribution adaptation, input robustness, and cross-period feature mapping capability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TA-SparseMG, an extension of the SparseTSF sparse cross-period modeling framework for long-term time series forecasting (LTSF). It adds three modules—a trend-aware reversible instance normalization module to mitigate distribution shift, a scale-adaptive gated denoising module to reduce high-frequency perturbations, and a multiscale gated-attention MLP to improve cross-period feature mapping—and claims that extensive experiments on multiple LTSF benchmarks show consistently superior and stable performance, with ablation studies confirming that each module independently contributes to these improvements.
Significance. If the empirical results hold under rigorous controls, the work would provide a lightweight, modular approach to handling non-stationarity and noise in LTSF that builds directly on an existing sparse framework, potentially improving parameter efficiency while targeting specific failure modes. The explicit framing of module contributions via ablation is a positive feature when the protocol is transparent.
major comments (2)
- [Ablation studies] Ablation studies section: the claim that the three modules 'each independently improve distribution adaptation, input robustness, and cross-period feature mapping capability' is load-bearing for the central contribution, yet the manuscript provides no protocol details (sequential vs. leave-one-out addition, fixed vs. retuned hyperparameters per variant, or statistical testing of performance deltas). Without these, interactions (e.g., denoising altering statistics seen by normalization) cannot be ruled out, undermining attribution of gains.
- [Experimental results] Experimental results section (benchmark tables): the abstract and reported claims assert 'superior, stable performance' across LTSF benchmarks, but no error bars, statistical significance tests, dataset exclusion criteria, or hyperparameter search details are referenced. This prevents assessment of whether observed improvements are robust or could arise from tuning variance.
minor comments (1)
- [Introduction] The abstract states the model is 'built on SparseTSF's sparse cross-period modeling framework' but does not include the base equations or a clear citation to the original SparseTSF formulation, which would aid readers in understanding the precise extensions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important aspects of experimental transparency. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Ablation studies] Ablation studies section: the claim that the three modules 'each independently improve distribution adaptation, input robustness, and cross-period feature mapping capability' is load-bearing for the central contribution, yet the manuscript provides no protocol details (sequential vs. leave-one-out addition, fixed vs. retuned hyperparameters per variant, or statistical testing of performance deltas). Without these, interactions (e.g., denoising altering statistics seen by normalization) cannot be ruled out, undermining attribution of gains.
Authors: We agree that the ablation protocol requires explicit description to support the attribution claims. In the revised version we will clarify that ablations were performed via leave-one-out addition to the full model, with hyperparameters retuned independently for each variant using the same search procedure as the main experiments, and that performance deltas were evaluated with paired statistical tests across multiple seeds. This will allow readers to assess potential module interactions. revision: yes
-
Referee: [Experimental results] Experimental results section (benchmark tables): the abstract and reported claims assert 'superior, stable performance' across LTSF benchmarks, but no error bars, statistical significance tests, dataset exclusion criteria, or hyperparameter search details are referenced. This prevents assessment of whether observed improvements are robust or could arise from tuning variance.
Authors: The referee correctly identifies missing details that limit assessment of robustness. We will revise the experimental section to include error bars from multiple independent runs, report results of statistical significance tests on the observed improvements, state the dataset inclusion criteria explicitly, and document the hyperparameter search ranges together with the optimization method employed. These additions will directly support the stability claims. revision: yes
Circularity Check
No circularity: empirical model extension with no self-referential derivations or fitted predictions
full rationale
The paper proposes TA-SparseMG as an empirical extension of the SparseTSF framework, adding three modules whose contributions are asserted via experiments and ablations. No equations, derivations, or first-principles results are presented that reduce claimed performance or module effects to quantities defined by the model's own fitted parameters or self-citations. The central claims rest on external benchmark comparisons and ablation results rather than any self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation chain. This is the standard case of a non-circular empirical architecture paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y. Wang, H. Wu, J. Dong, Y. Liu, C. Wang, M. Long, J. Wang, Deep time series models: A comprehensive survey and bench- mark, IEEE Transactions on Pattern Analysis and Machine Intelligence (2026). doi:10.1109/TPAMI.2026.3690845
-
[2]
Q. Wen, T. Zhou, C. Zhang, W. Chen, Z. Ma, J. Yan, L. Sun, Transformersintimeseries:Asurvey,in:Proceedingsofthe32nd International Joint Conference on Artificial Intelligence, 2023, pp. 6778–6786. doi:10.24963/ijcai.2023/759
-
[3]
A. Zeng, M. Chen, L. Zhang, Q. Xu, Are transformers effective fortimeseriesforecasting?,ProceedingsoftheAAAIConference on Artificial Intelligence 37 (2023) 11121–11128. doi:10.1609/ aaai.v37i9.26317
2023
-
[4]
Z. Xu, A. Zeng, Q. Xu, FITS: Modeling time series with 10k parameters, in:Proceedingsofthe12thInternationalConference on Learning Representations, 2024. URL: https://openreview.n et/forum?id=bWcnvZ3qMb
2024
-
[5]
URL: https://openreview.net/forum ?id=Jbdc0vTOcol
Y.Nie,N.H.Nguyen,P.Sinthong,J.Kalagnanam, Atimeseries is worth 64 words: Long-term forecasting with transformers, in: Proceedings of the 11th International Conference on Learning Representations, 2023. URL: https://openreview.net/forum ?id=Jbdc0vTOcol
2023
-
[6]
Y. Liu, T. Hu, H. Zhang, H. Wu, S. Wang, L. Ma, M. Long, iTransformer: Inverted transformers are effective for time series forecasting, in:Proceedingsofthe12thInternationalConference on Learning Representations, 2024. URL: https://openreview.n et/forum?id=JePfAI8fah
2024
-
[7]
T. Zhou, Z. Ma, Q. Wen, X. Wang, L. Sun, R. Jin, FED- former: Frequency enhanced decomposed transformer for long- term series forecasting, in: Proceedings of the 39th International ConferenceonMachineLearning,2022,pp.27268–27286.URL: https://proceedings.mlr.press/v162/zhou22g.html
2022
-
[8]
W. Yue, Y. Liu, X. Ying, B. Xing, R. Guo, J. Shi, FreEformer: Frequency enhanced transformer for multivariate time series forecasting, in: Proceedings of the 34th International Joint Con- ference on Artificial Intelligence, 2025, pp. 3606–3614. doi:10.2 4963/ijcai.2025/401
2025
-
[9]
37797–37814
S.Lin,H.Chen,H.Wu,C.Qiu,W.Lin, Temporalquerynetwork for efficient multivariate time series forecasting, in: Proceedings ofthe42ndInternationalConferenceonMachineLearning,2025, pp. 37797–37814. URL: https://proceedings.mlr.press/v267/lin 25e.html
2025
-
[10]
S. Lin, W. Lin, W. Wu, H. Chen, C. L. P. Chen, SparseTSF: Lightweight and robust time series forecasting via sparse mod- eling, IEEE Transactions on Pattern Analysis and Machine Intelligence48(2026)170–183.doi:10.1109/TPAMI.2025.3602445
-
[11]
H. Chen, V. Luong, L. Mukherjee, V. Singh, SimpleTM: A simple baseline for multivariate time series forecasting, in: Proceedings of the 13th International Conference on Learning Representations, 2025. URL: https://openreview.net/forum ?id=oANkBaVci5
2025
-
[12]
T. Kim, J. Kim, Y. Tae, C. Park, J.-H. Choi, J. Choo, Re- versible instance normalization for accurate time-series forecast- ing against distribution shift, in: Proceedings of the 10th Inter- national Conference on Learning Representations, 2022. URL: https://openreview.net/forum?id=cGDAkQo1C0p
2022
-
[13]
W.Fan,P.Wang,D.Wang,D.Wang,Y.Zhou,Y.Fu, Dish-TS:A general paradigm for alleviating distribution shift in time series forecasting, Proceedings of the AAAI Conference on Artificial Intelligence 37 (2023) 7522–7529. doi:10.1609/aaai.v37i6.259 14
-
[14]
14273–14292
Z.Liu,M.Cheng,Z.Li,Z.Huang,Q.Liu,Y.Xie,E.Chen,Adap- tive normalization for non-stationary time series forecasting: A temporal slice perspective, in: Advances in Neural Information Processing Systems, volume 36, 2023, pp. 14273–14292. URL: https://proceedings.neurips.cc/paper_files/paper/2023/hash/2e1 9dab94882bc95ed094c4399cfda02-Abstract-Conference.html
2023
-
[15]
K. Yi, Q. Zhang, W. Fan, S. Wang, P. Wang, H. He, N. An, D. Lian, L. Cao, Z. Niu, Frequency-domain MLPs are more effective learners in time series forecasting, in: Advances in Neural Information Processing Systems, volume 36, 2023, pp. 76656–76679. URL: https://proceedings.neurips.cc/paper _files/paper/2023/hash/f1d16af76939f476b5f040fd1398c0a3- Abstract-...
2023
-
[16]
URL: https://openreview.net/forum?i d=zTQdHSQUQWc
T.Zhou,Z.Ma,X.Wang,Q.Wen,L.Sun,T.Yao,W.Yin,R.Jin, FiLM: Frequency improved legendre memory model for long- termtimeseriesforecasting, in:AdvancesinNeuralInformation Processing Systems, 2022. URL: https://openreview.net/forum?i d=zTQdHSQUQWc
2022
-
[17]
H. Wang, J. Peng, F. Huang, J. Wang, J. Chen, Y. Xiao, MICN: Multiscalelocalandglobalcontextmodelingforlong-termseries forecasting, in:Proceedingsofthe11thInternationalConference on Learning Representations, 2023. URL: https://openreview.n et/forum?id=zt53IDUR1U
2023
-
[18]
URL: https://openreview.net/forum?id=AyajSj TAzmg
M.Liu,A.Zeng,M.Chen,Z.Xu,Q.Lai,L.Ma,Q.Xu, SCINet: Time series modeling and forecasting with sample convolution and interaction, in: Advances in Neural Information Processing Systems, 2022. URL: https://openreview.net/forum?id=AyajSj TAzmg
2022
-
[19]
S.-A.Chen,C.-L.Li,S.O.Arik,N.C.Yoder,T.Pfister,TSMixer: Anall-MLParchitecturefortimeseriesforecasting, Transactions onMachineLearningResearch(2023).URL:https://openreview .net/forum?id=wbpxTuXgm0
2023
-
[20]
S. Wang, H. Wu, X. Shi, T. Hu, H. Luo, L. Ma, J. Y. Zhang, J. Zhou, TimeMixer: Decomposable multiscale mixing for time series forecasting, in: Proceedings of the 12th International Conference on Learning Representations, 2024. URL: https: //openreview.net/forum?id=7oLshfEIC2
2024
-
[21]
E.Perez,F.Strub,H.deVries,V.Dumoulin,A.Courville, FiLM: Visual reasoning with a general conditioning layer, Proceedings of the AAAI Conference on Artificial Intelligence 32 (2018) 3942–3951. doi:10.1609/aaai.v32i1.11671. Wenchao Liu et al.:Preprint submitted to ElsevierPage 13 of 14 TA-SparseMG: Trend-Aware Sparse Forecasting via Multi-Scale Gating for Lo...
-
[22]
G. E. P. Box, G. M. Jenkins, G. C. Reinsel, G. M. Ljung, Time SeriesAnalysis:ForecastingandControl,5ed.,Wiley,Hoboken,
-
[23]
URL: https://www.wiley.com/en-br/Time%2BSeries%2 BAnalysis%3A%2BForecasting%2Band%2BControl%2C%2B5t h%2BEdition-p-9781118675021
-
[24]
B. Lim, S. Zohren, Time-series forecasting with deep learning: Asurvey, PhilosophicalTransactionsoftheRoyalSocietyA379 (2021) 20200209. doi:10.1098/rsta.2020.0209
-
[25]
G. Lai, W.-C. Chang, Y. Yang, H. Liu, Modeling long- and short-term temporal patterns with deep neural networks, in: Proceedingsofthe41stInternationalACMSIGIRConferenceon Research and Development in Information Retrieval, 2018, pp. 95–104. doi:10.1145/3209978.3210006
-
[26]
S.Bai,J.Z.Kolter,V.Koltun, Anempiricalevaluationofgeneric convolutional and recurrent networks for sequence modeling, arXiv preprint arXiv:1803.01271 (2018). URL: https://arxiv. org/abs/1803.01271
Pith/arXiv arXiv 2018
-
[27]
doi:10.1609/aa ai.v35i12.17325
H.Zhou,S.Zhang,J.Peng,S.Zhang,J.Li,H.Xiong,W.Zhang, Informer: Beyond efficient transformer for long sequence time- series forecasting, Proceedings of the AAAI Conference on Artificial Intelligence 35 (2021) 11106–11115. doi:10.1609/aa ai.v35i12.17325
work page doi:10.1609/aa 2021
-
[28]
H. Wu, J. Xu, J. Wang, M. Long, Autoformer: Decomposition transformers with auto-correlation for long-term series forecast- ing, in: Advances in Neural Information Processing Systems, volume 34, 2021, pp. 22419–22430. URL: https://proceedi ngs.neurips.cc/paper_files/paper/2021/hash/bcc0d400288793e 8bdcd7c19a8ac0c2b-Abstract.html
2021
-
[29]
Zhang, J
Y. Zhang, J. Yan, Crossformer: Transformer utilizing cross- dimension dependency for multivariate time series forecasting, in:Proceedingsofthe11thInternationalConferenceonLearning Representations, 2023. URL: https://openreview.net/forum?id= vSVLM2j9eie
2023
-
[30]
S. Liu, H. Yu, C. Liao, J. Li, W. Lin, A. X. Liu, S. Dustdar, Pyraformer: Low-complexity pyramidal attention for long-range timeseriesmodelingandforecasting, in:Proceedingsofthe10th International Conference on Learning Representations, 2022. URL: https://openreview.net/forum?id=0EXmFzUn5I
2022
-
[31]
B. N. Oreshkin, D. Carpov, N. Chapados, Y. Bengio, N-BEATS: Neural basis expansion analysis for interpretable time series forecasting, in: Proceedings of the 8th International Conference on Learning Representations, 2020. URL: https://openreview.n et/forum?id=r1ecqn4YwB
2020
-
[32]
A. Das, W. Kong, A. Leach, S. K. Mathur, R. Sen, R. Yu, Long-term forecasting with TiDE: Time-series dense encoder, TransactionsonMachineLearningResearch(2023).URL:https: //openreview.net/forum?id=pCbC3aQB5W
2023
-
[33]
D. Luo, X. Wang, ModernTCN: A modern pure convolution structure for general time series analysis, in: Proceedings of the 12th International Conference on Learning Representations,
-
[34]
URL: https://openreview.net/forum?id=vpJMJerXHU
-
[35]
H. Wu, T. Hu, Y. Liu, H. Zhou, J. Wang, M. Long, TimesNet: Temporal 2d-variation modeling for general time series analysis, in:Proceedingsofthe11thInternationalConferenceonLearning Representations, 2023. URL: https://openreview.net/forum?id= ju_Uqw384Oq
2023
-
[36]
M. Wang, H. Wang, F. Zhang, Correctformer: A transformer ar- chitecture for correcting periodic drift in time-series forecasting, Neural Networks 196 (2026) 108375. doi:10.1016/j.neunet.202 5.108375
-
[37]
Y. Liu, H. Wu, J. Wang, M. Long, Non-stationary transformers: Exploringthestationarityintimeseriesforecasting, in:Advances in Neural Information Processing Systems, volume 35, 2022, pp. 9881–9893. URL: https://proceedings.neurips.cc/paper_files/p aper/2022/hash/4054556fcaa934b0bf76da52cf4f92cb-Abstract- Conference.html
arXiv 2022
-
[38]
12271–12290
Y.Liu,C.Li,J.Wang,M.Long, Koopa:Learningnon-stationary time series dynamics with koopman predictors, in: Advances in Neural Information Processing Systems, volume 36, 2023, pp. 12271–12290. URL: https://proceedings.neurips.cc/paper _files/paper/2023/hash/28b3dc0970fa4624a63278a4268de997- Abstract-Conference.html
2023
-
[39]
C. Wang, F. Zhang, X. Zhang, H. Wang, DTFNet: A dual- modal time-frequency fusion network for non-stationary time seriesmodeling, Knowledge-BasedSystems343(2026)116022. doi:10.1016/j.knosys.2026.116022
-
[40]
F. Zhang, L. Yuan, W. Zhang, M. Zhang, H. Wang, Multi-scale temporal correlation multi-dimensional decomposition network fortimeseriesanalysis, PatternRecognition175(2026)113140. doi:10.1016/j.patcog.2026.113140
-
[41]
C. E. Shannon, A mathematical theory of communication, Bell System Technical Journal 27 (1948) 379–423. doi:10.1002/j.15 38-7305.1948.tb01338.x. Wenchao Liu et al.:Preprint submitted to ElsevierPage 14 of 14
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.