DiStash: A Disaggregated Multi-Stash Transactional Key-Value Store
Pith reviewed 2026-06-29 02:10 UTC · model grok-4.3
The pith
DiStash enables a single transaction to read and write copies of key-value pairs across multiple disaggregated stash pools.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
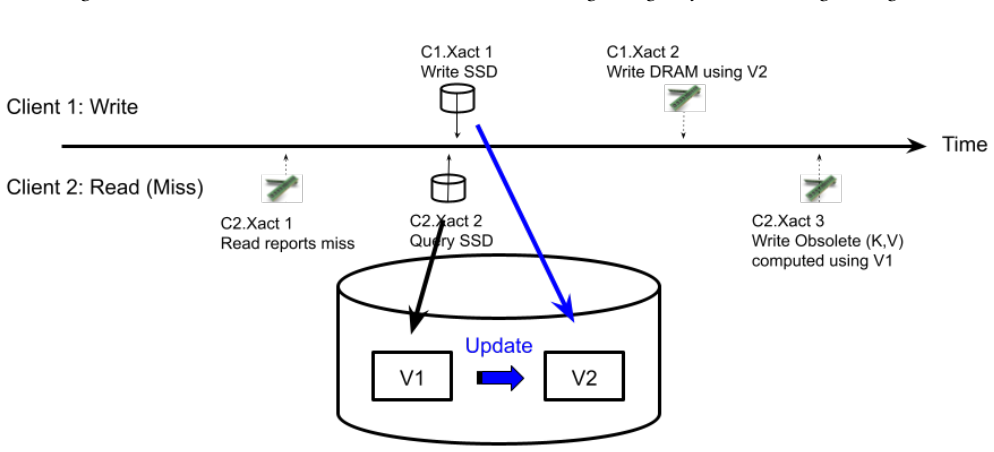
DiStash governs KVs across pools of stash types and enables an application to use a single transaction to read and write different copies of one or more key-value pairs across the different pools of stashes, simplifying application logic by preventing undesirable race conditions that may cause copies of data to reflect different values and failures that may result in loss of key-value pairs.
What carries the argument
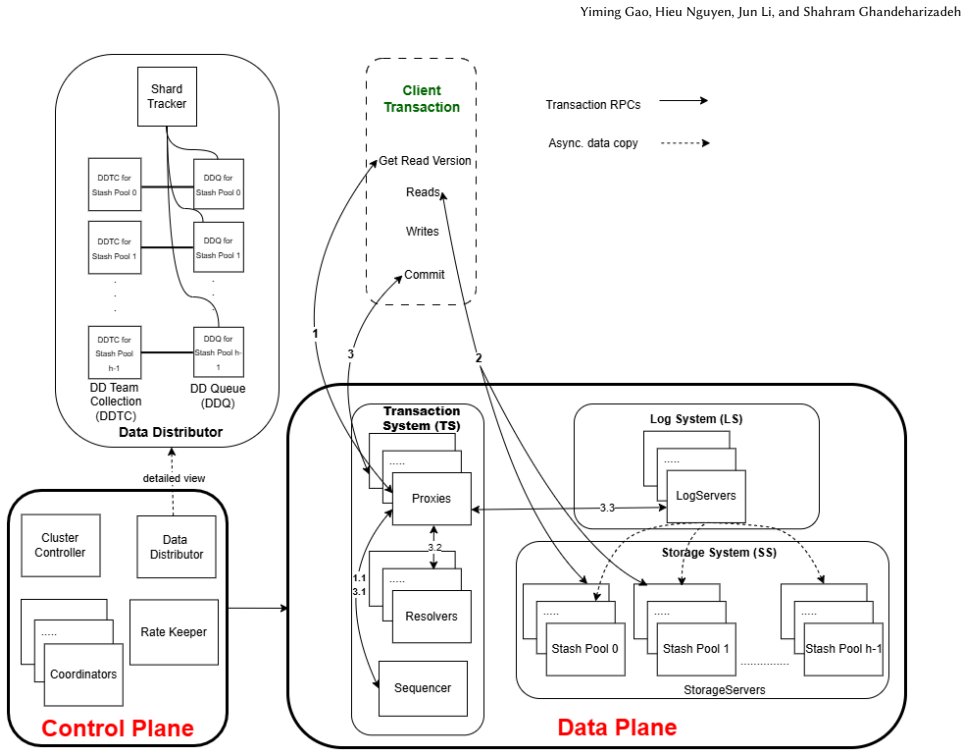
The multi-stash transactional coordination layer, built by extending FoundationDB, that enforces atomicity across disaggregated inclusive or exclusive stash pools.
If this is right
- Applications can issue one atomic operation instead of separate reads and writes that risk inconsistency across storage types.
- Stash pools can be configured as either replicated copies or tiered exclusive storage without changing the transaction interface.
- Stashes can be treated as ephemeral or durable storage depending on the durability requirements set by the application.
- Performance and consistency tradeoffs become measurable through standard microbenchmarks and production traces.
Where Pith is reading between the lines
- The same multi-stash pattern could be added to other transactional key-value systems to support flexible storage hierarchies.
- Independent scaling of individual stash pools becomes possible while still presenting a unified transactional view.
- Applications that previously required custom synchronization code for multi-tier storage may be able to simplify their logic further.
Load-bearing premise
Extending FoundationDB with multi-stash logic preserves its original transactional guarantees and failure semantics when stashes are disaggregated and configured as inclusive or exclusive.
What would settle it
A transaction that commits yet leaves different stash pools holding inconsistent values for the same keys, or that loses data under a failure scenario that FoundationDB would have survived, would show the extension does not preserve the original guarantees.
Figures




read the original abstract
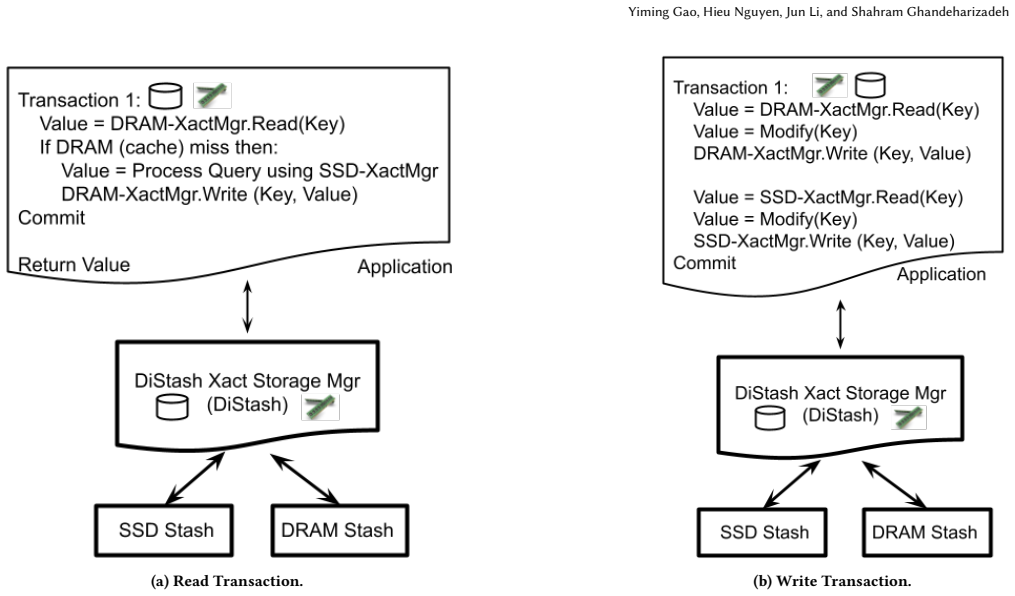
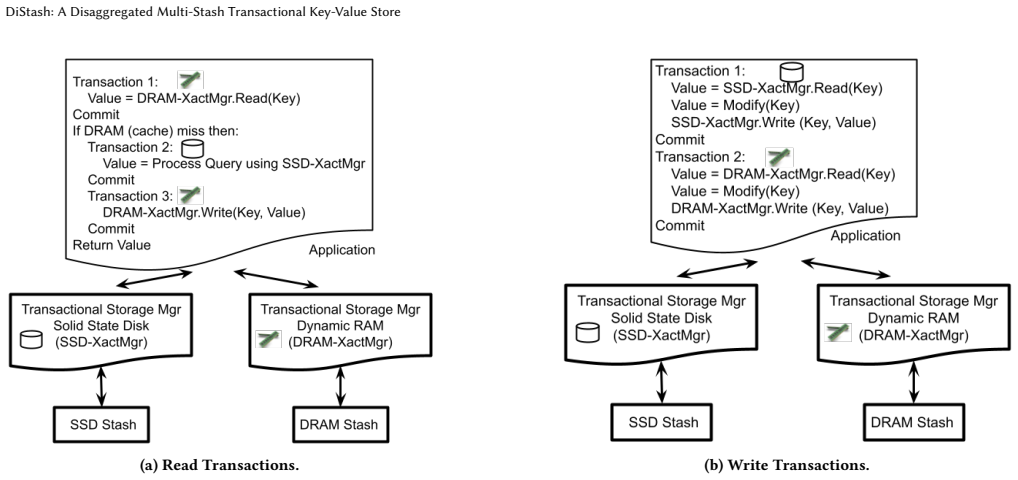
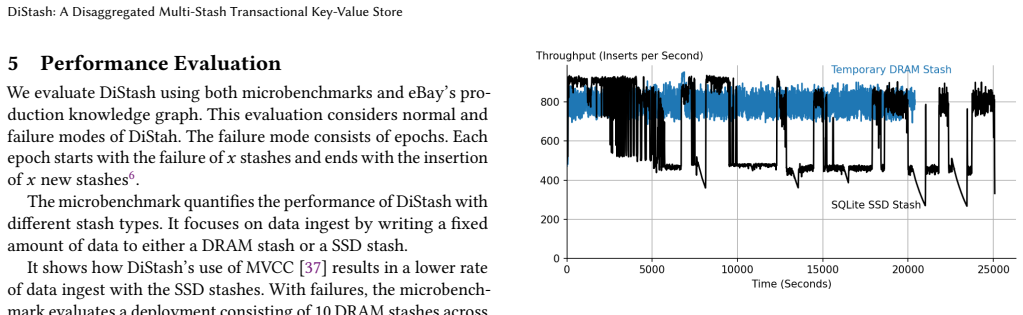
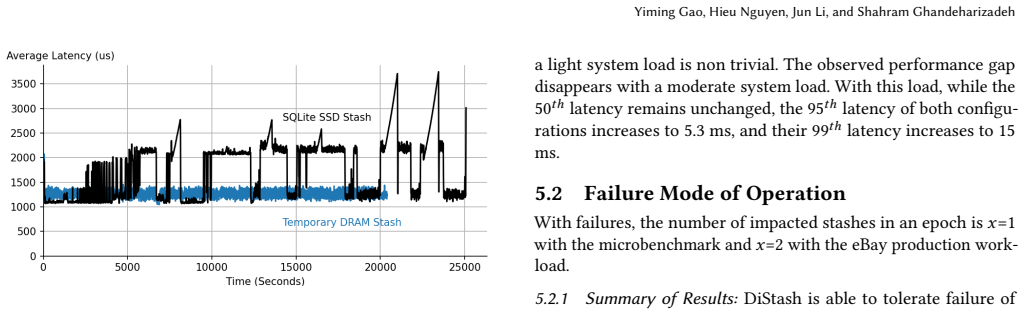
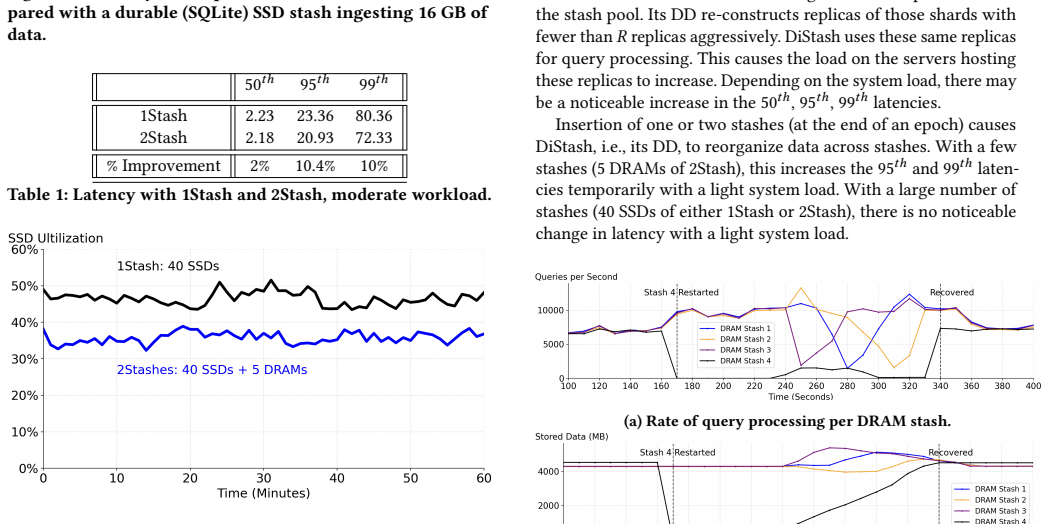
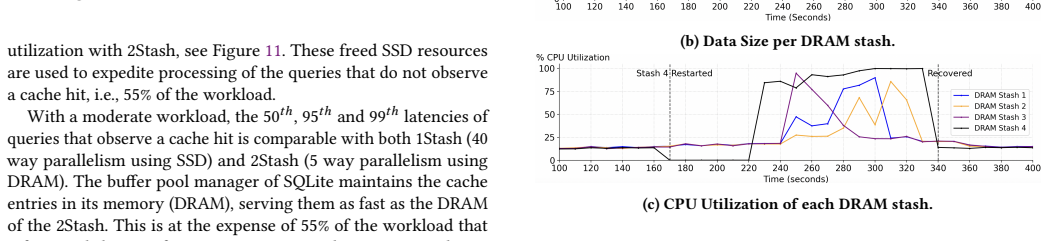
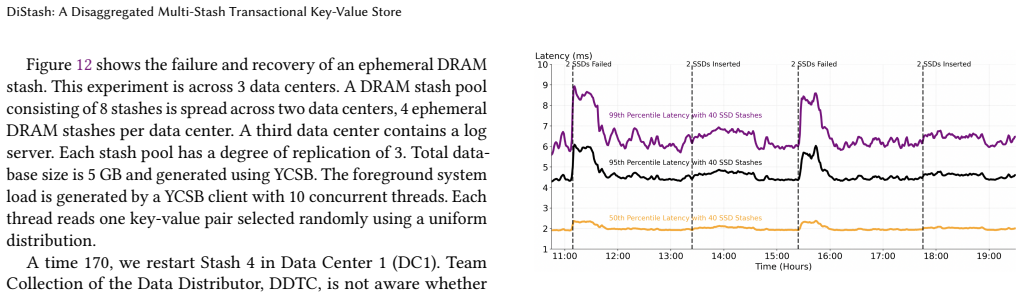
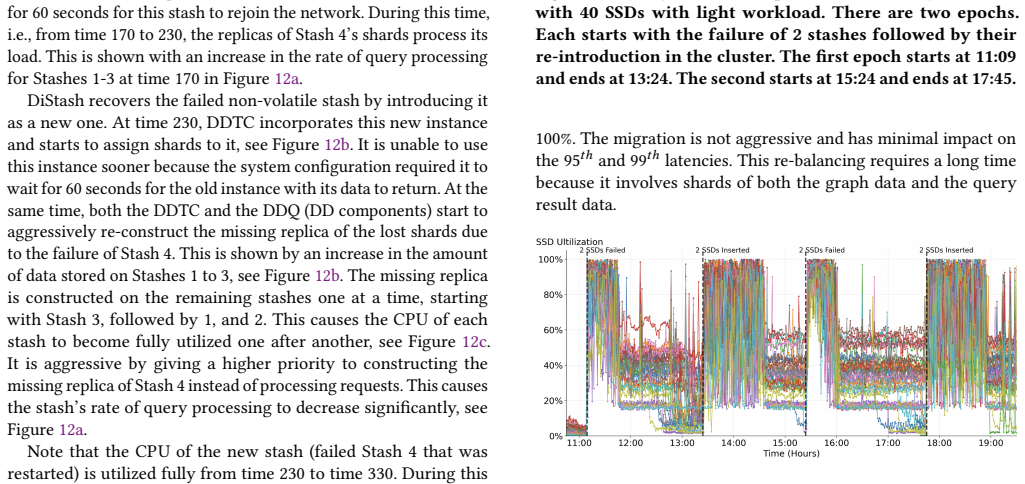
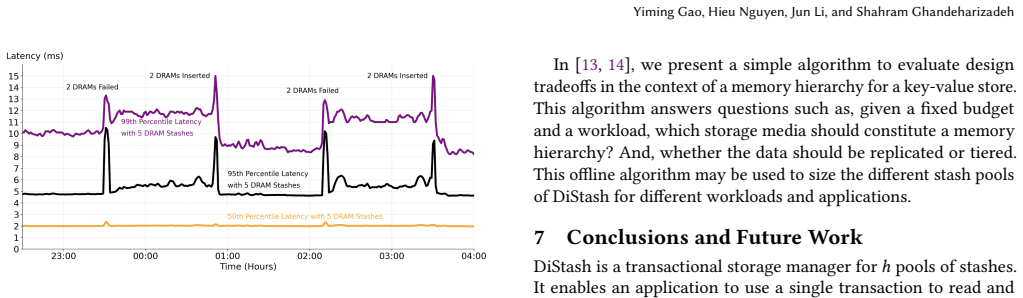
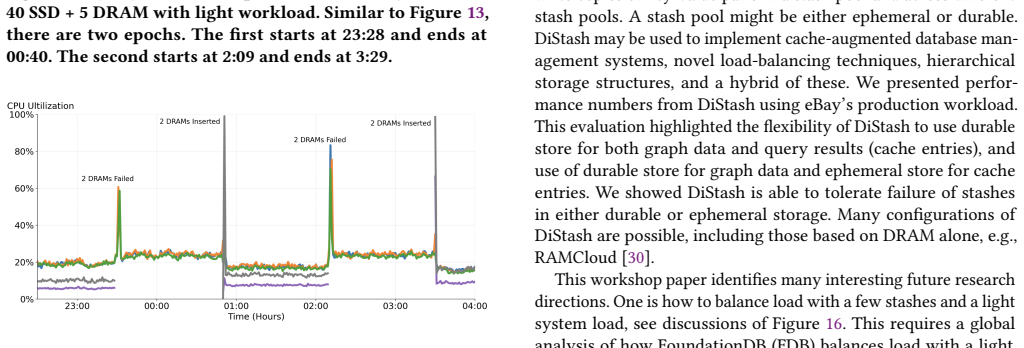
A stash is a storage medium such as Dynamic Random Access Memory (DRAM), Solid State Disk (SSD), Hard Disk Drive (HDD), or Non-Volatile Memory (NVM). This paper presents a disaggregated transactional key-value (KV) store, DiStash, that governs KVs cross pools of stash types. It enables an application to use a single transaction to read and write different copies of one or more key-value pair across the different pools of stashes. It simplifies the application logic by (a) preventing undesirable race conditions that may cause copies of data across different stash pools to reflect different values and/or (b) failures that may result in loss of key-value pairs. A configuration of DiStash may use a pool of stashes as either ephemeral or durable storage. The application dictates whether the content of its participating stashes are inclusive (replicated) or exclusive (tiered). We implement a DiStash by extending FoundationDB. We quantify the tradeoffs with its design decisions using microbenchmarks and eBay's production workload. We open source our implementation at https://github.com/ebay-USC/DiStash.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DiStash, a disaggregated transactional key-value store built by extending FoundationDB. It allows a single transaction to read and write different copies of one or more key-value pairs across pools of heterogeneous stashes (DRAM, SSD, HDD, NVM), with pools configurable as inclusive (replicated) or exclusive (tiered) and as ephemeral or durable storage. The design aims to simplify applications by avoiding cross-stash races and data loss. The authors report an implementation, microbenchmarks, and evaluation on eBay's production workload, and release the code at https://github.com/ebay-USC/DiStash.
Significance. If the extension to FoundationDB correctly preserves ACID properties and failure semantics across disaggregated stash pools, the work would offer a practical mechanism for transactional access to tiered heterogeneous storage, reducing the need for application-level coordination. The open-source release supports reproducibility and further experimentation.
major comments (2)
- [Abstract] Abstract: the central claim requires that the multi-stash extension preserves FoundationDB's original transactional guarantees and failure semantics (including cross-stash conflict detection, commit coordination, and recovery) when stashes are disaggregated and configured as inclusive or exclusive. No description of the modified transaction protocol, logging, or recovery paths is supplied, leaving the preservation assumption unverified.
- [Abstract and Evaluation section] Abstract and Evaluation section: the abstract states that microbenchmarks and an eBay workload were used to quantify design tradeoffs, yet supplies no performance data, error bars, throughput/latency numbers, or comparison baselines, preventing assessment of whether the claimed simplifications are achieved in practice.
minor comments (1)
- [Abstract] Abstract: 'one or more key-value pair' should read 'pairs'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on DiStash. The comments highlight areas where additional detail would strengthen the presentation of transactional guarantees and empirical results. We address each point below and commit to revisions that directly incorporate the requested information without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim requires that the multi-stash extension preserves FoundationDB's original transactional guarantees and failure semantics (including cross-stash conflict detection, commit coordination, and recovery) when stashes are disaggregated and configured as inclusive or exclusive. No description of the modified transaction protocol, logging, or recovery paths is supplied, leaving the preservation assumption unverified.
Authors: We agree that the manuscript does not supply a description of the modified transaction protocol, logging, or recovery paths. The current text focuses on the high-level design and implementation overview. In the revised version we will add a dedicated section that explains the extensions to FoundationDB's transaction protocol, including how cross-stash conflict detection, commit coordination, and recovery are handled for both inclusive and exclusive configurations while preserving the original ACID and failure semantics. revision: yes
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: the abstract states that microbenchmarks and an eBay workload were used to quantify design tradeoffs, yet supplies no performance data, error bars, throughput/latency numbers, or comparison baselines, preventing assessment of whether the claimed simplifications are achieved in practice.
Authors: We agree that the evaluation section currently lacks the quantitative results, error bars, throughput/latency numbers, and baseline comparisons referenced in the abstract. The revised manuscript will expand the evaluation section to include these specific measurements from the microbenchmarks and eBay production workload, enabling direct assessment of the design tradeoffs. revision: yes
Circularity Check
No circularity: systems implementation paper with no derivations or equations
full rationale
The paper is a description of a disaggregated KV store implementation extending FoundationDB. It contains no equations, fitted parameters, predictions, or derivation chains. The central contribution is an engineering design evaluated via microbenchmarks and workload traces, which is self-contained and externally verifiable through the open-sourced code and described configuration options. No load-bearing steps reduce to self-definition or self-citation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Steve Byan, James Lentini, Anshul Madan, Luis Pabon, Michael Condict, Jeff Kimmel, Steve Kleiman, Christopher Small, and Mark Storer. 2012. Mercury: Host-Side Flash Caching for the Data Center. In2012 IEEE 28th symposium on mass storage systems and technologies (MSST). IEEE, 1–12
2012
-
[2]
2013.Redis in Action
Josiah Carlson. 2013.Redis in Action. Simon and Schuster
2013
-
[3]
Ronald P Cenker, Donald G Clemons, William R Huber, Joseph B Petrizzi, Frank J Procyk, and George M Trout. 1979. A Fault-Tolerant 64K Dynamic Random- Access Memory.IEEE Transactions on Electron Devices26, 6 (1979), 853–860
1979
-
[4]
Feng Chen, Binbing Hou, and Rubao Lee. 2016. Internal Parallelism of Flash Memory-Based Solid-State Drives.ACM Transactions on Storage (TOS)12, 3 (2016), 1–39
2016
-
[5]
Pierre Clouzet, Clément Foyer, Brice Goglin, Emmanuel Jeannot, Jannis Klinken- berg, Christian Terboven, and Anara Kozhokanova. 2024. H2M: Heuristics for DiStash: A Disaggregated Multi-Stash Transactional Key-Value Store Heterogeneous Memory. InHMEM 2024-5th Workshop on Heterogeneity and Memory Systems
2024
-
[6]
Biplob Debnath, Sudipta Sengupta, and Jin Li. 2010. FlashStore: High Throughput Persistent Key-Value Store.Proc. VLDB Endow.3, 1–2 (Sept. 2010), 1414–1425. doi:10.14778/1920841.1921015
-
[7]
Cagdas Dirik and Bruce Jacob. 2009. The Performance of PC Solid-State Disks (SSDs) as a Function of Bandwidth, Concurrency, Device Architecture, and System Organization.ACM SIGARCH Computer Architecture News37, 3 (2009), 279–289
2009
-
[8]
Siying Dong, Mark Callaghan, Leonidas Galanis, Dhruba Borthakur, Tony Savor, and Michael Strum. 2017. Optimizing Space Amplification in RocksDB.. InCIDR, Vol. 3. 3
2017
-
[9]
Andersen, and Michael Kaminsky
Bin Fan, Hyeontaek Lim, David G. Andersen, and Michael Kaminsky. 2011. Small Cache, Big Effect: Provable Load Balancing for Randomly Partitioned Cluster Services. InProceedings of the 2nd ACM Symposium on Cloud Computing(Cascais, Portugal)(SOCC ’11). Association for Computing Machinery, New York, NY, USA, Article 23, 12 pages. doi:10.1145/2038916.2038939
-
[10]
Dashti, and Cyrus Shahabi
Shahram Ghandeharizadeh, Ali E. Dashti, and Cyrus Shahabi. 1995. Pipelining Mechanism to Minimize the Latency Time in Hierarchical Multimedia Storage Managers.Comput. Commun.18, 3 (1995), 170–184
1995
-
[11]
Shahram Ghandeharizadeh, Connor Gorman, Sandy Irani, Shiva Jahangiri, Jenny Lam, Hieu Nguyen, Ryan Tani, and Jason Yap. 2014. A Demonstration of KOSAR: An Elastic, Scalable, Highly Available SQL Middleware. InProceedings of the Middleware ’14 Posters & Demos Session, Bordeaux, France, December 8-12, 2014, Romain Rouvoy (Ed.). ACM, 23–24. doi:10.1145/26785...
-
[12]
Shahram Ghandeharizadeh, Douglas Ierardi, Dongho Kim, and Roger Zimmer- mann. 1996. Placement of Data in Multi-zone Disk Drives. InSecond International Baltic Workshop on DB and IS. Citeseer
1996
-
[13]
Shahram Ghandeharizadeh, Sandy Irani, and Jenny Lam. 2018. On Configuring a Hierarchy of Storage Media in the Age of NVM. In34th IEEE International Conference on Data Engineering, ICDE 2018, Paris, France, April 16-19, 2018. IEEE Computer Society, 1380–1383. doi:10.1109/ICDE.2018.00155
- [14]
-
[15]
Shahram Ghandeharizadeh and Hieu Nguyen. 2019. Design, Implementation, and Evaluation of Write-Back Policy with Cache Augmented Data Stores.Proceedings of the VLDB Endowment12, 8 (2019), 836–849
2019
-
[16]
Shahram Ghandeharizadeh and Jason Yap. 2017. SQL Query to Trigger Transla- tion: A Novel Transparent Consistency Technique for Cache Augmented SQL Systems. In28th International Workshop on Database and Expert Systems Applica- tions, DEXA 2017 Workshops, Lyon, France, August 28-31, 2017. IEEE Computer Society, 37–41. doi:10.1109/DEXA.2017.24
-
[17]
Shahram Ghandeharizadeh, Jason Yap, and Hieu Nguyen. 2014. Strong Con- sistency in Cache Augmented SQL Systems. InProceedings of the 15th Inter- national Middleware Conference, Bordeaux, France, December 8-12, 2014, Lau- rent Réveillère, Lucy Cherkasova, and François Taïani (Eds.). ACM, 181–192. doi:10.1145/2663165.2663318
-
[18]
Jim Gray and Franco Putzolu. 1987. The 5 Minute Rule for Trading Memory for Disc Accesses and the 10 Byte Rule for Trading Memory for CPU Time. In Proceedings of the 1987 ACM SIGMOD international conference on Management of data. 395–398
1987
-
[19]
Haoyu Huang and Shahram Ghandeharizadeh. 2021. Nova-LSM: A Distributed, Component-based LSM-tree Key-value Store. InSIGMOD ’21: International Con- ference on Management of Data, Virtual Event, China, June 20-25, 2021, Guoliang Li, Zhanhuai Li, Stratos Idreos, and Divesh Srivastava (Eds.). ACM, 749–763. doi:10.1145/3448016.3457297
-
[20]
Xin Jin, Xiaozhou Li, Haoyu Zhang, Robert Soulé, Jeongkeun Lee, Nate Foster, Changhoon Kim, and Ion Stoica. 2017. NetCache: Balancing Key-Value Stores with Fast In-Network Caching. InProceedings of the 26th Symposium on Operating Systems Principles(Shanghai, China)(SOSP ’17). Association for Computing Machinery, New York, NY, USA, 121–136. doi:10.1145/313...
-
[21]
Norman P Jouppi. 1993. Cache Write Policies and Performance.ACM SIGARCH Computer Architecture News21, 2 (1993), 191–201
1993
-
[22]
Bohyun Lee, Seongjae Moon, Jonghyeok Park, and Sang-Won Lee. 2025. Boosting OLTP Performance with Per-Page Logging on NVDIMM.Proceedings of the ACM on Management of Data3, 1 (2025), 1–28
2025
-
[23]
Changmin Lee, Wonjae Shin, Dae Jeong Kim, Yongjun Yu, Sung-Joon Kim, Taekyeong Ko, Deokho Seo, Jongmin Park, Kwanghee Lee, Seongho Choi, et al
-
[24]
In2020 IEEE International Symposium on High Performance Computer Architecture (HPCA)
NVDIMM-C: A Byte-Addressable Non-Volatile Memory Module for Com- patibility with Standard DDR Memory Interfaces. In2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 502–514
-
[25]
Jacques Lenfant. 1977. Fast Random and Sequential Access to Dynamic Memories of any Size.IEEE Trans. Comput.100, 9 (1977), 847–855
1977
-
[26]
memcached. [n. d.]. Memcached, http://www.memcached.org/. http://www. memcached.org/
-
[27]
Hieu Nguyen, Jun Li, and Shahram Ghandeharizadeh. 2023. Graph Stores with Application-Level Query Result Caches. InPerformance Evaluation and Benchmarking - 15th TPC Technology Conference, TPCTC 2023, Vancouver, British Columbia, Canada, August 28, 2023 (Lecture Notes in Computer Science, Vol. 14247), Raghunath Nambiar and Meikel Poess (Eds.). Springer
2023
- [28]
-
[29]
Li, Ryan McElroy, Mike Paleczny, Daniel Peek, Paul Saab, David Stafford, Tony Tung, and Venkateshwaran Venkataramani
Rajesh Nishtala, Hans Fugal, Steven Grimm, Marc Kwiatkowski, Herman Lee, Harry C. Li, Ryan McElroy, Mike Paleczny, Daniel Peek, Paul Saab, David Stafford, Tony Tung, and Venkateshwaran Venkataramani. 2013. Scaling Memcache at Facebook. InProceedings of the 10th USENIX Conference on Networked Systems Design and Implementation(Lombard, IL)(nsdi’13). USENIX ...
2013
-
[30]
Michael Norman, Vince Kellen, Shava Smallen, Brian DeMeulle, Shawn Strande, Ed Lazowska, Naomi Alterman, Rob Fatland, Sarah Stone, Amanda Tan, Katherine Yelick, Eric Van Dusen, and James Mitchell. 2021. CloudBank: Managed Services to Simplify Cloud Access for Computer Science Research and Education. In Practice and Experience in Advanced Research Computin...
-
[31]
John Ousterhout, Arjun Gopalan, Ashish Gupta, Ankita Kejriwal, Collin Lee, Behnam Montazeri, Diego Ongaro, Seo Jin Park, Henry Qin, Mendel Rosenblum, Stephen Rumble, Ryan Stutsman, and Stephen Yang. 2015. The RAMCloud Storage System.ACM Trans. Comput. Syst.33, 3, Article 7 (Aug. 2015), 55 pages. doi:10.1145/2806887
-
[32]
Onkar Patil, Latchesar Ionkov, Jason Lee, Frank Mueller, and Michael Lang
-
[33]
InProceedings of the International Symposium on Memory Systems
NVM-based Energy and Cost Efficient HPC Clusters. InProceedings of the International Symposium on Memory Systems. 1–14
-
[34]
David A Patterson, Garth Gibson, and Randy H Katz. 1988. A Case for Redundant Arrays of Inexpensive Disks (RAID). InProceedings of the 1988 ACM SIGMOD international conference on Management of data. 109–116
1988
-
[35]
Dan R. K. Ports, Austin T. Clements, Irene Zhang, Samuel Madden, and Barbara Liskov. 2010. Transactional Consistency and Automatic Management in an Ap- plication Data Cache. In9th USENIX Symposium on Operating Systems Design and Implementation, OSDI 2010, October 4-6, 2010, Vancouver, BC, Canada, Proceedings, Remzi H. Arpaci-Dusseau and Brad Chen (Eds.). ...
2010
-
[36]
Guoyu Wang, Xilong Che, Haoyang Wei, Shuo Chen, Puyi He, and Juncheng Hu
-
[37]
In23rd USENIX Conference on File and Storage Technologies (FAST 25)
Boosting File Systems Elegantly: A Transparent {NVM} Write-ahead Log for Disk File Systems. In23rd USENIX Conference on File and Storage Technologies (FAST 25). 19–34
-
[38]
Brian White, Jay Lepreau, Leigh Stoller, Robert Ricci, Shashi Guruprasad, Mac Newbold, Mike Hibler, Chad Barb, and Abhijeet Joglekar. 2002. An Integrated Experimental Environment for Distributed Systems and Networks.SIGOPS Oper. Syst. Rev.36, SI, 255–270. doi:10.1145/844128.844152
-
[39]
Arpaci-Dusseau, and Remzi H
Kan Wu, Zhihan Guo, Guanzhou Hu, Kaiwei Tu, Ramnatthan Alagappan, Rathijit Sen, Kwanghyun Park, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau
-
[40]
In19th USENIX Conference on File and Storage Technologies (FAST 21)
The Storage Hierarchy is Not a Hierarchy: Optimizing Caching on Modern Storage Devices with Orthus. In19th USENIX Conference on File and Storage Technologies (FAST 21). USENIX Association, 307–323. https://www.usenix.org/ conference/fast21/presentation/wu-kan
-
[42]
InProceedings of the 2021 International Conference on Management of Data
FoundationDB: A Distributed Unbundled Transactional Key Value Store. InProceedings of the 2021 International Conference on Management of Data. 2653– 2666
2021
-
[43]
Jingyu Zhou, Meng Xu, Alexander Shraer, Bala Namasivayam, Alex Miller, Evan Tschannen, Steve Atherton, Andrew J Beamon, Rusty Sears, John Leach, et al
-
[44]
ACM66, 6 (2023), 97–105
FoundationDB: A Distributed Key-Value Store.Commun. ACM66, 6 (2023), 97–105
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.