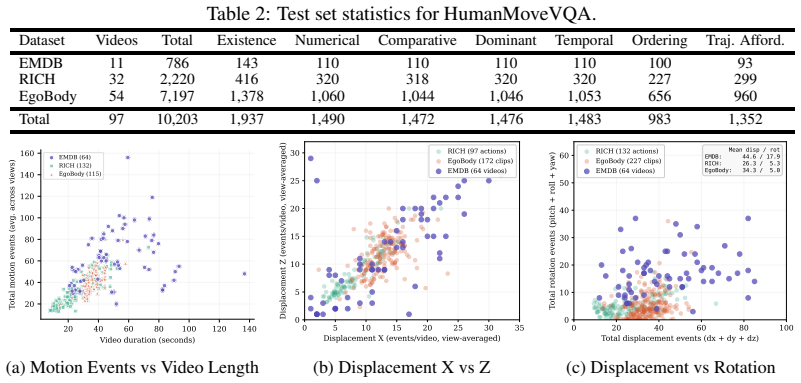
HumanMoveVQA: Can Video MLLMs reason about human movement in videos?
Pith reviewed 2026-06-29 04:50 UTC · model grok-4.3
The pith
Video MLLMs fail at global human trajectory and orientation reasoning but improve markedly when fine-tuned on world-consistent 3D motion data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
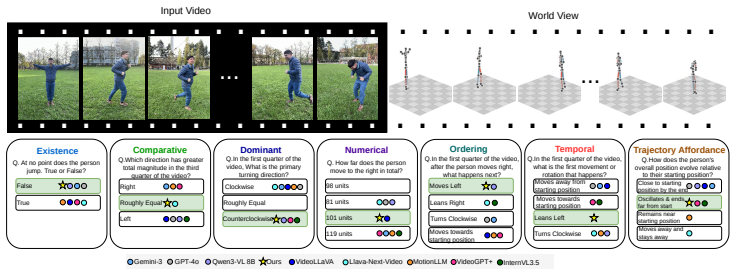
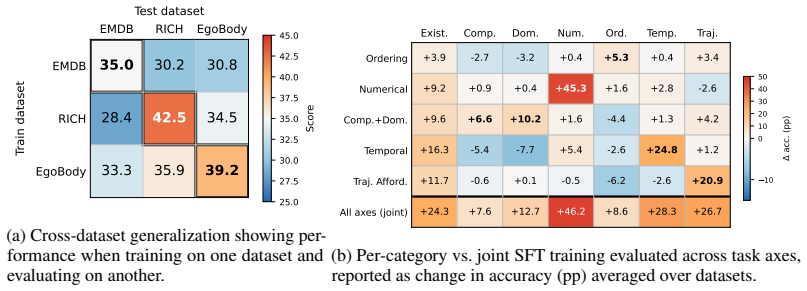
HumanMoveVQA shows that current video MLLMs reduce complex human motion to broad semantic labels and cannot reliably answer questions about global trajectories or orientation shifts, but fine-tuning an open-source model on the benchmark's world-consistent 3D supervision produces clear gains across the seven reasoning categories.
What carries the argument
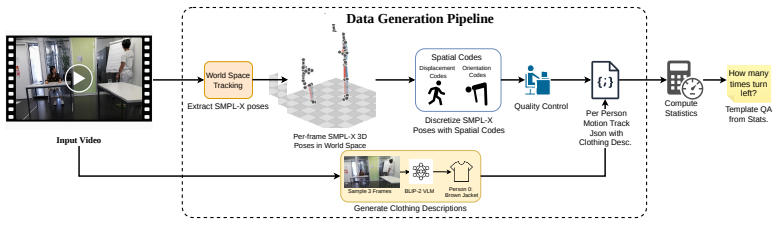
The multi-stage pipeline that converts 2D video frames into world-consistent 3D motion tracks anchored to the first frame, generating structured QA pairs that test trajectory-level and orientation reasoning.
If this is right
- Fine-tuned open-source models can outperform proprietary ones on global human motion tasks when given the same world-consistent supervision.
- Video understanding systems can move beyond local joint or scene labels to handle trajectory aggregation and sequential ordering questions.
- The seven reasoning categories supply a structured way to measure progress on movement-aware video models.
- A geometric, first-frame-anchored coordinate system provides a repeatable foundation for generating motion QA data at scale.
Where Pith is reading between the lines
- The same lifting pipeline could be applied to non-human moving objects such as vehicles or animals to create similar benchmarks.
- Models trained this way may transfer better to downstream tasks that require predicting future paths from observed motion.
- The gap between proprietary and fine-tuned performance suggests other video reasoning shortfalls could also close with targeted geometric data rather than scale alone.
Load-bearing premise
The pipeline that lifts 2D observations into 3D motion tracks keeps translation and rotation accurate relative to the fixed starting point without introducing errors that would invalidate the generated questions and answers.
What would settle it
A direct comparison of the pipeline's 3D tracks against ground-truth motion capture data on the same videos that reveals systematic drift in position or rotation, or a re-run of the fine-tuning experiment on a fresh set of real videos that shows no accuracy gain.
Figures






read the original abstract
Despite the rapid advance of Multimodal Large Language Models (MLLMs) in high-level video understanding, a fundamental bottleneck remains: these models collapse complex human motion into coarse semantic labels. Existing benchmarks mostly focus on scene-centric events or local joint articulations, failing to probe global human motion in space over time (trajectory and orientation changes). We introduce HumanMoveVQA, the first comprehensive benchmark designed to evaluate global trajectory and orientation reasoning from an exocentric perspective. Our benchmark utilizes a first-frame anchored world coordinate system, preserving translation and rotation relative to a fixed starting point. We propose a scalable, multi-stage pipeline that lifts 2D video observations into world-consistent 3D motion tracks to generate over 10K structured question-answer pairs across seven reasoning categories, including motion aggregation, sequential ordering, and trajectory-level inference. Our extensive evaluation reveals a critical capability gap in state-of-the-art proprietary models on deep human motion understanding. However, we demonstrate that this is a learnable problem; by fine-tuning an open-source baseline with our targeted, world-consistent supervision, we achieve a significant improvement.HumanMoveVQA establishes a rigorous geometric foundation for developing next-generation, movement-aware video understanding models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HumanMoveVQA, the first benchmark targeting global human trajectory and orientation reasoning in videos from an exocentric perspective. It describes a first-frame-anchored world coordinate system and a multi-stage 2D-to-3D lifting pipeline used to generate over 10K QA pairs across seven categories (motion aggregation, sequential ordering, trajectory inference, etc.). Evaluations on the benchmark reveal capability gaps in state-of-the-art proprietary video MLLMs, while fine-tuning an open-source baseline with the generated world-consistent supervision yields significant gains.
Significance. If the 3D lifting pipeline is shown to be accurate, the work supplies a geometrically grounded benchmark that addresses a clear gap in existing video-understanding evaluations, which largely emphasize semantic events or local joint motion rather than global trajectory and orientation changes over time. The explicit demonstration that the observed gap is learnable via targeted supervision is a constructive finding for the field.
major comments (1)
- [Method section describing the 2D-to-3D lifting pipeline] The multi-stage 2D-to-3D lifting pipeline (described in the method section) is load-bearing for the entire benchmark and all downstream claims, yet the manuscript reports no quantitative validation against ground-truth 3D data (e.g., position/orientation drift or mocap error on held-out sequences). Systematic biases in translation or rotation relative to the first-frame anchor would directly corrupt the seven reasoning categories and the fine-tuning supervision.
minor comments (1)
- [Abstract] The abstract states results at a high level but omits any reference to dataset statistics, error analysis, or validation of the generated QA pairs, making it difficult to assess reliability from the provided description alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive evaluation of the benchmark's significance. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [Method section describing the 2D-to-3D lifting pipeline] The multi-stage 2D-to-3D lifting pipeline (described in the method section) is load-bearing for the entire benchmark and all downstream claims, yet the manuscript reports no quantitative validation against ground-truth 3D data (e.g., position/orientation drift or mocap error on held-out sequences). Systematic biases in translation or rotation relative to the first-frame anchor would directly corrupt the seven reasoning categories and the fine-tuning supervision.
Authors: We agree that the 2D-to-3D lifting pipeline is central to the benchmark and that the absence of quantitative validation against ground-truth 3D data is a limitation. The pipeline composes established off-the-shelf components (2D pose estimation, monocular depth, and camera pose estimation) with a first-frame anchoring step, but we did not report end-to-end error metrics on held-out mocap sequences. In the revised manuscript we will add a dedicated validation subsection that measures position and orientation drift on sequences with available 3D ground truth, thereby quantifying any systematic biases relative to the anchor frame. revision: yes
Circularity Check
No circularity; benchmark pipeline and evaluations are independent of each other
full rationale
The paper constructs HumanMoveVQA via a described multi-stage 2D-to-3D lifting pipeline to produce QA pairs, then separately evaluates proprietary and open-source MLLMs on those pairs and shows fine-tuning gains. No equations, fitted parameters, or self-citations are presented as load-bearing derivations. The pipeline is an input method for data generation, not a quantity derived from or equivalent to the model results. The central claims (capability gap + learnability) rest on external model evaluations rather than reducing to the pipeline definition itself. This matches the default expectation of a non-circular benchmark paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Qwen3-vl technical report, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
2025
-
[3]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, Zhaokai Wang, Zhe Chen, Hongjie Zhang, Ganlin Yang, Haomin Wang, Qi Wei, Jinhui Yin, Wenhao Li, Erfei Cui, Guanzhou Chen, Zichen Ding, Changyao Tian, Zhenyu Wu, Jingjing Xie, Zehao Li, Bowen Yang, Yuchen Duan, Xuehui Wang, Haoran H...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Activitynet-qa: a dataset for understanding complex web videos via question answering
Zhou Yu, Dejing Xu, Jun Yu, Ting Yu, Zhou Zhao, Yueting Zhuang, and Dacheng Tao. Activitynet-qa: a dataset for understanding complex web videos via question answering. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educ...
-
[5]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InCVPR, 2025
2025
-
[6]
Next-qa: Next phase of question- answering to explaining temporal actions.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
Junbin Xiao, Xindi Shang, Angela Yao, and Tat seng Chua. Next-qa: Next phase of question- answering to explaining temporal actions.2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
2021
-
[7]
Star: A benchmark for situated reasoning in real-world videos.ArXiv, abs/2405.09711, 2024
Bo Wu and Shoubin Yu. Star: A benchmark for situated reasoning in real-world videos.ArXiv, abs/2405.09711, 2024
-
[8]
Msr-vtt: A large video description dataset for bridging video and language
Jun Xu, Tao Mei, Ting Yao, and Yong Rui. Msr-vtt: A large video description dataset for bridging video and language. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[9]
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long- context interleaved video-language understanding, 2024. URL https://arxiv.org/abs/ 2407.15754
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Lvbench: An extreme long video understanding benchmark, 2024
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Shiyu Huang, Bin Xu, Yuxiao Dong, Ming Ding, and Jie Tang. Lvbench: An extreme long video understanding benchmark, 2024
2024
-
[11]
Sqa3d: Situated question answering in 3d scenes
Xiaojian Ma, Silong Yong, Zilong Zheng, Qing Li, Yitao Liang, Song-Chun Zhu, and Siyuan Huang. Sqa3d: Situated question answering in 3d scenes. InInternational Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=IDJx97BC38. 10
2023
-
[12]
Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment, 2023
Bin Zhu, Bin Lin, Munan Ning, Yang Yan, Jiaxi Cui, Wang HongFa, Yatian Pang, Wenhao Jiang, Junwu Zhang, Zongwei Li, Cai Wan Zhang, Zhifeng Li, Wei Liu, and Li Yuan. Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment, 2023
2023
-
[13]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. InProceedings of the IEEE/CVF international conference on computer vision, pages 1728–1738, 2021
2021
-
[14]
Yi-Xing Peng, Qize Yang, Yu-Ming Tang, Shenghao Fu, Kun-Yu Lin, Xihan Wei, and Wei-Shi Zheng. Actionart: Advancing multimodal large models for fine-grained human-centric video understanding.arXiv preprint arXiv:2504.18152, 2025
-
[15]
Mmhu: A massive-scale multimodal benchmark for human behavior understanding, 2025
Renjie Li, Ruijie Ye, Mingyang Wu, Hao Frank Yang, Zhiwen Fan, Hezhen Hu, and Zhengzhong Tu. Mmhu: A massive-scale multimodal benchmark for human behavior understanding, 2025
2025
-
[16]
Motionllm: Understanding human behaviors from human motions and videos.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Ling-Hao Chen, Shunlin Lu, Ailing Zeng, Hao Zhang, Benyou Wang, Ruimao Zhang, and Lei Zhang. Motionllm: Understanding human behaviors from human motions and videos.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[17]
Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models, 2025
Wenyi Hong, Yean Cheng, Zhuoyi Yang, Weihan Wang, Lefan Wang, Xiaotao Gu, Shiyu Huang, Yuxiao Dong, and Jie Tang. Motionbench: Benchmarking and improving fine-grained video motion understanding for vision language models, 2025
2025
-
[18]
Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning
Wufei Ma, Yu-Cheng Chou, Qihao Liu, Xingrui Wang, Celso M de Melo, Jianwen Xie, and Alan Yuille. Spatialreasoner: Towards explicit and generalizable 3d spatial reasoning. In Advances in Neural Information Processing Systems, volume 38, 2025
2025
-
[19]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14455–14465, June 2024
2024
-
[20]
Spatial- thinker: Reinforcing 3d reasoning in multimodal llms via spatial rewards, 2025
Hunar Batra, Haoqin Tu, Hardy Chen, Yuanze Lin, Cihang Xie, and Ronald Clark. Spatial- thinker: Reinforcing 3d reasoning in multimodal llms via spatial rewards, 2025
2025
-
[21]
EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Manuel Kaufmann, Jie Song, Chen Guo, Kaiyue Shen, Tianjian Jiang, Chengcheng Tang, Juan José Zárate, and Otmar Hilliges. EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. InInternational Conference on Computer Vision (ICCV), 2023
2023
-
[22]
Huang, Hongwei Yi, Markus Höschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J
Chun-Hao P. Huang, Hongwei Yi, Markus Höschle, Matvey Safroshkin, Tsvetelina Alexiadis, Senya Polikovsky, Daniel Scharstein, and Michael J. Black. Capturing and inferring dense full-body human-scene contact. InProceedings IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[23]
Egobody: Human body shape and motion of interacting people from head-mounted devices
Siwei Zhang, Qianli Ma, Yan Zhang, Zhiyin Qian, Taein Kwon, Marc Pollefeys, Federica Bogo, and Siyu Tang. Egobody: Human body shape and motion of interacting people from head-mounted devices. InEuropean Conference on Computer Vision, 2022
2022
-
[24]
Mvbench: A comprehensive multi-modal video understanding benchmark.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, Limin Wang, and Yu Qiao. Mvbench: A comprehensive multi-modal video understanding benchmark.2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2024
-
[25]
Spatialrgpt: Grounded spatial reasoning in vision-language models
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models. In NeurIPS, 2024
2024
-
[26]
Jihan Yang, Shusheng Yang, Anjali Gupta, Rilyn Han, Fei-Fei Li, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10632– 10643, 2024. 11
2025
-
[27]
4D-RGPT: Toward Region-level 4D Understanding via Perceptual Distillation
Chiao-An Yang, Ryo Hachiuma, Sifei Liu, Subhashree Radhakrishnan, Raymond A Yeh, Yu- Chiang Frank Wang, and Min-Hung Chen. 4d-rgpt: Toward region-level 4d understanding via perceptual distillation.arXiv preprint arXiv:2512.17012, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Learning situated awareness in the real world, 2026
Chuhan Li, Ruilin Han, Joy Hsu, Yongyuan Liang, Rajiv Dhawan, Jiajun Wu, Ming-Hsuan Yang, and Xin Eric Wang. Learning situated awareness in the real world, 2026
2026
-
[29]
Video-LLaV A: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-LLaV A: Learning united visual representation by alignment before projection. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, Florida, USA, November 2024. Association fo...
2024
-
[30]
Muhammad Maaz, Hanoona Abdul Rasheed, Salman H. Khan, and Fahad Shahbaz Khan. Videogpt+: Integrating image and video encoders for enhanced video understanding.ArXiv, abs/2406.09418, 2024
-
[31]
Llava- video: Video instruction tuning with synthetic data.Trans
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Llava- video: Video instruction tuning with synthetic data.Trans. Mach. Learn. Res., 2025, 2024
2025
-
[32]
Video instruction tuning with synthetic data, 2024
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024
2024
-
[33]
Liang Xu, Shaoyang Hua, Zili Lin, Yifan Liu, Feipeng Ma, Yichao Yan, Xin Jin, Xiaokang Yang, and Wenjun Zeng. Motionbank: A large-scale video motion benchmark with disentangled rule-based annotations.arXiv preprint arXiv:2410.13790, 2024
-
[34]
PoseScript: 3D Human Poses from Natural Language
Delmas, Ginger and Weinzaepfel, Philippe and Lucas, Thomas and Moreno-Noguer, Francesc and Rogez, Grégory. PoseScript: 3D Human Poses from Natural Language. InECCV, 2022
2022
-
[35]
Yao Feng, Jing Lin, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, and Michael J. Black. Chatpose: Chatting about 3d human pose. InCVPR, 2024
2024
-
[36]
HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips
Antoine Miech, Dimitri Zhukov, Jean-Baptiste Alayrac, Makarand Tapaswi, Ivan Laptev, and Josef Sivic. HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. InICCV, 2019
2019
-
[37]
Mllm-4d: Towards visual-based spatial-temporal intelligence.arXiv preprint arXiv:2603.00515, 2026
Xingyilang Yin, Chengzhengxu Li, Jiahao Chang, Chi-Man Pun, and Xiaodong Cun. Mllm-4d: Towards visual-based spatial-temporal intelligence.arXiv preprint arXiv:2603.00515, 2026
-
[38]
Motion-x: A large-scale 3d expressive whole-body human motion dataset.Advances in Neural Information Processing Systems, 36:25268–25280, 2023
Jing Lin, Ailing Zeng, Shunlin Lu, Yuanhao Cai, Ruimao Zhang, Haoqian Wang, and Lei Zhang. Motion-x: A large-scale 3d expressive whole-body human motion dataset.Advances in Neural Information Processing Systems, 36:25268–25280, 2023
2023
-
[39]
Prompthmr: Promptable human mesh recovery.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1148–1159, 2025
Yufu Wang, Yu Sun, Priyanka Patel, Kostas Daniilidis, Michael John Black, and Muhammed Kocabas. Prompthmr: Promptable human mesh recovery.2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1148–1159, 2025
2025
-
[40]
Motionscript: Natural language descriptions for expressive 3d human motions
Payam Jome Yazdian, Rachel Lagasse, Hamid Mohammadi, Eric Liu, Li Cheng, and Angelica Lim. Motionscript: Natural language descriptions for expressive 3d human motions. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2025
2025
-
[41]
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
2023
-
[42]
Georgios Pavlakos, Vasileios Choutas, Nima Ghorbani, Timo Bolkart, Ahmed A. A. Osman, Dimitrios Tzionas, and Michael J. Black. Expressive body capture: 3D hands, face, and body from a single image. InProceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 10975–10985, 2019
2019
-
[43]
Gemini 3 flash model card
Google DeepMind. Gemini 3 flash model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf , 2025. Accessed: 2026-05-01. 12
2025
-
[44]
Llamafactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand, 2024. Association for Computational Linguist...
2024
-
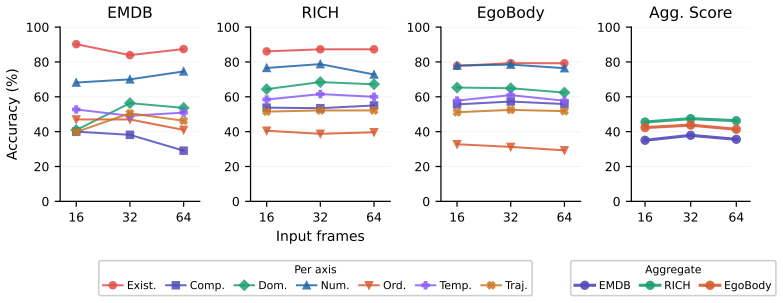
[45]
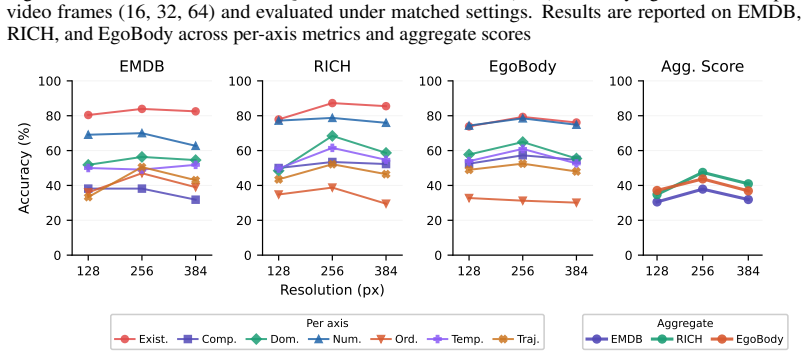
How sensitive is the training to the number of frames?
-
[46]
How sensitive is the training to the resolution of the videos?
-
[47]
How does it perform if trained with a short reasoning trace?
-
[48]
inverted V
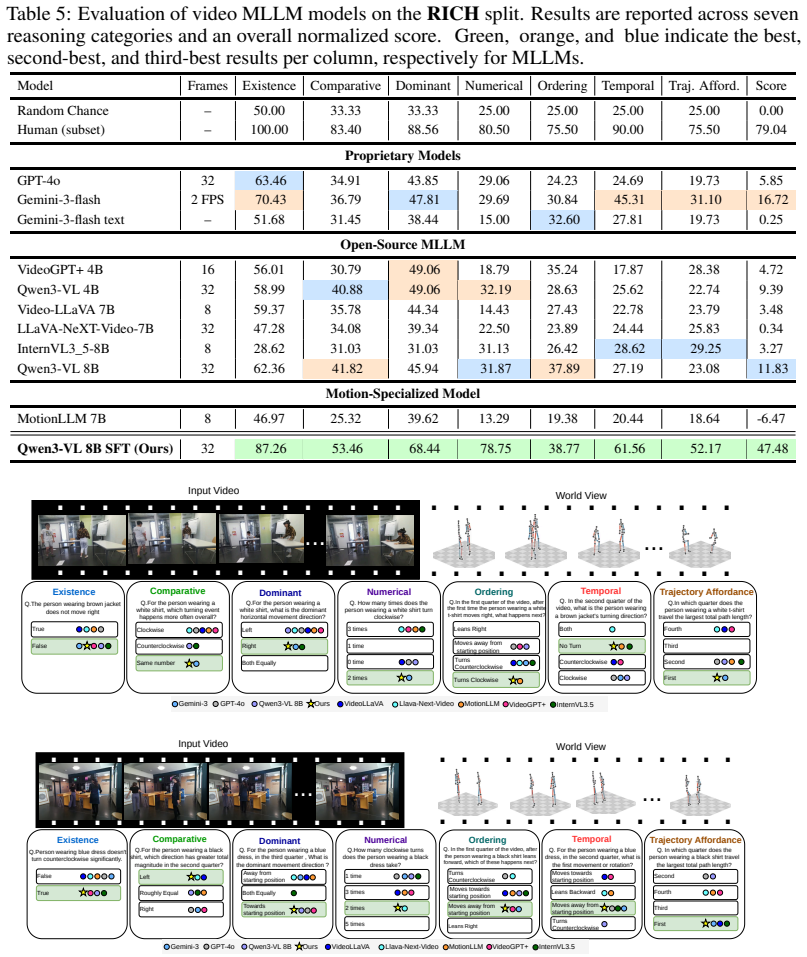
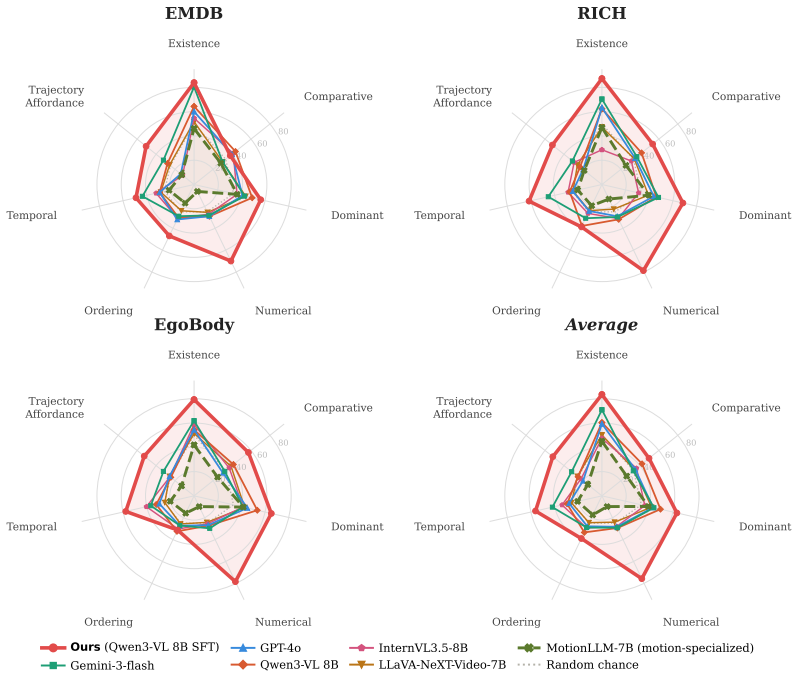
How does our model generalize to joint-level reasoning benchmarks like ActionArt? 14 Table 5: Evaluation of video MLLM models on theRICHsplit. Results are reported across seven reasoning categories and an overall normalized score. Green, orange, and blue indicate the best, second-best, and third-best results per column, respectively for MLLMs. Model Frame...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.