How to deal with machine learning bias in economic history
Pith reviewed 2026-06-29 01:50 UTC · model grok-4.3
The pith
Machine learning bias in economic history can be corrected with recent debiasing methods using only a small set of expert-coded labels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Prediction errors produced by machine learning models in economic history are frequently correlated with covariates of interest in ways that bias downstream estimates, yet this bias can be removed for a wide class of applications by applying recent debiasing methods to a small, randomly sampled set of expert-coded labels without sacrificing the efficiency of large-scale automated prediction.
What carries the argument
Debiasing methods that adjust large-scale machine-learning predictions by incorporating labels from a small random sample of expert-coded records to offset systematic error-covariate correlations.
If this is right
- Researchers can run large-scale machine-learning predictions on historical sources and still obtain unbiased estimates of relationships of interest.
- Only a modest additional investment in expert labeling is required to correct bias rather than labeling the entire corpus.
- Standard validation against proxies is insufficient in many cases, but debiasing extends the set of usable applications.
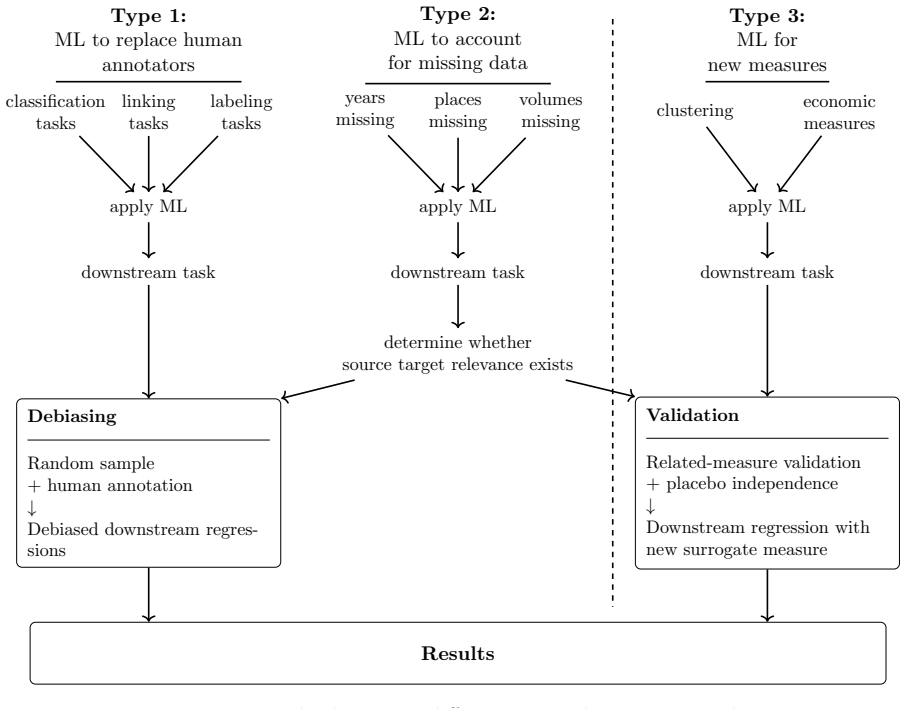
- The three-task taxonomy clarifies which machine-learning uses in economic history are addressable by debiasing and which require alternative checks.
- Reproducibility and model-choice guidelines can now incorporate bias-correction steps as routine practice.
Where Pith is reading between the lines
- The same small-sample debiasing approach could be tested in other social-science domains that rely on machine learning for text or archival data.
- If the error-covariate relationship takes a form outside the reach of current debiasing tools, new methods tailored to historical data structures would be required.
- Repeated application across different historical periods could show whether the required expert-sample size remains stable or varies with data quality.
- Linking the procedure more explicitly to classical measurement-error corrections in econometrics might yield sharper bounds on remaining uncertainty.
Load-bearing premise
The form of the correlation between prediction errors and the covariates of interest must be one that current debiasing methods can address, and the small random expert-labeled sample must be large enough and representative enough to identify and remove that correlation.
What would settle it
Apply the debiasing procedure to a historical-text dataset where both a large automated prediction and a complete expert labeling are available, then check whether the debiased coefficients match the coefficients obtained from the fully expert-labeled data.
Figures
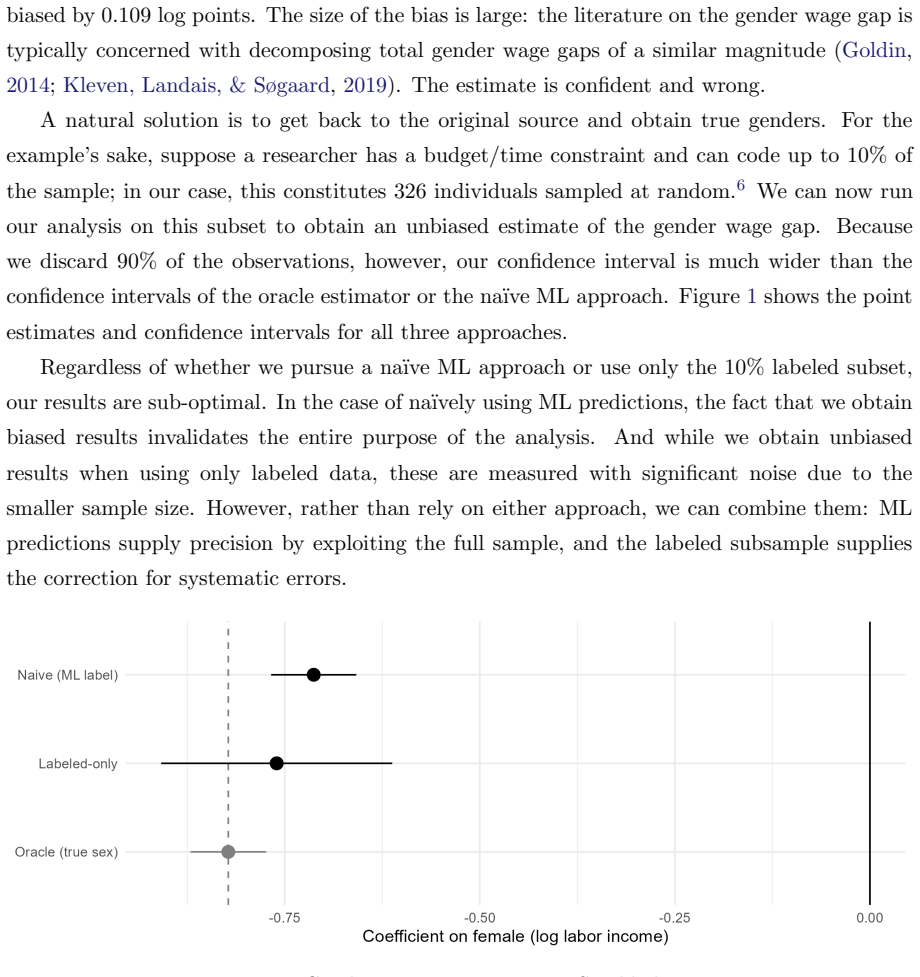
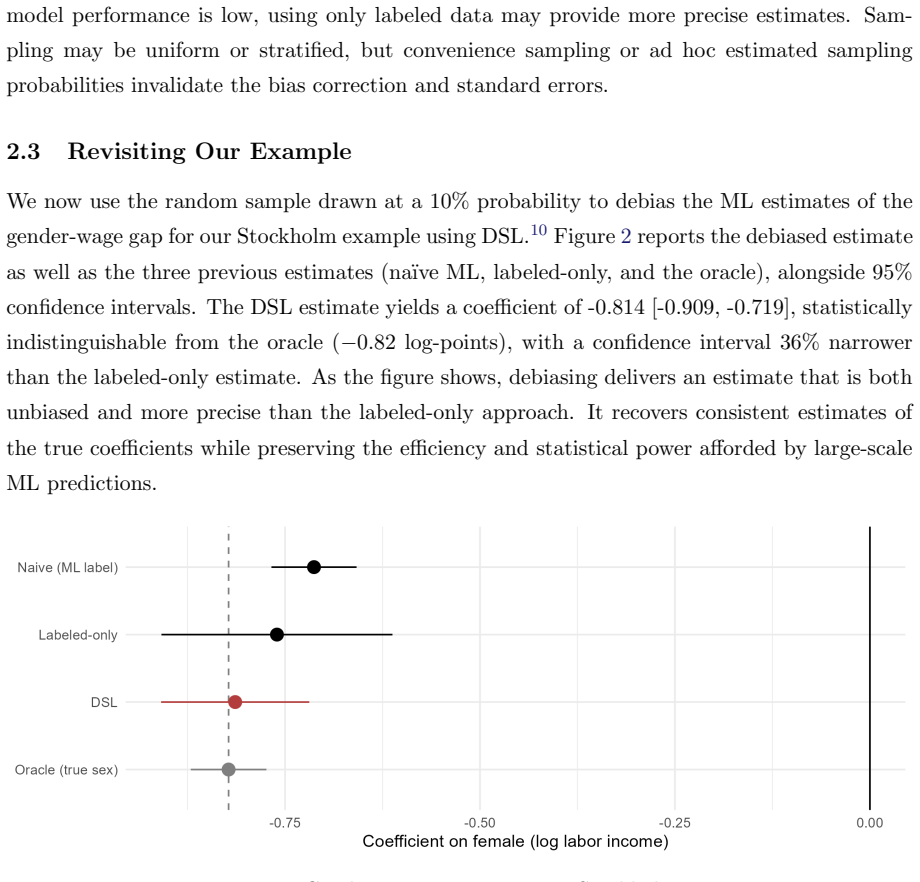
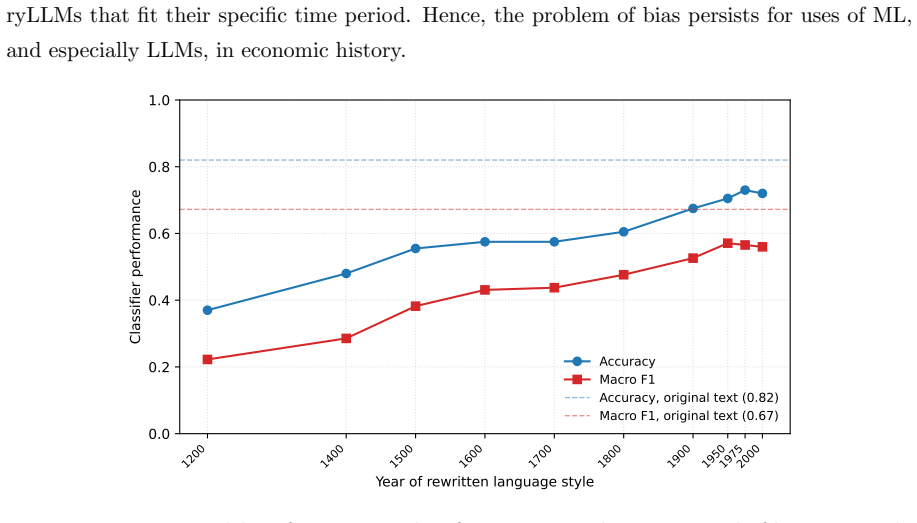
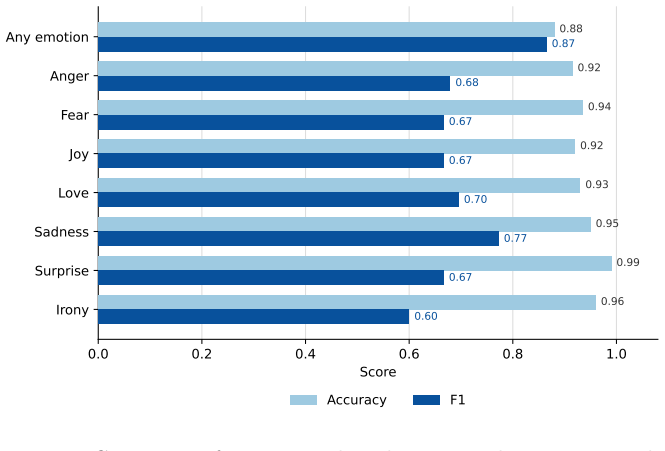

read the original abstract
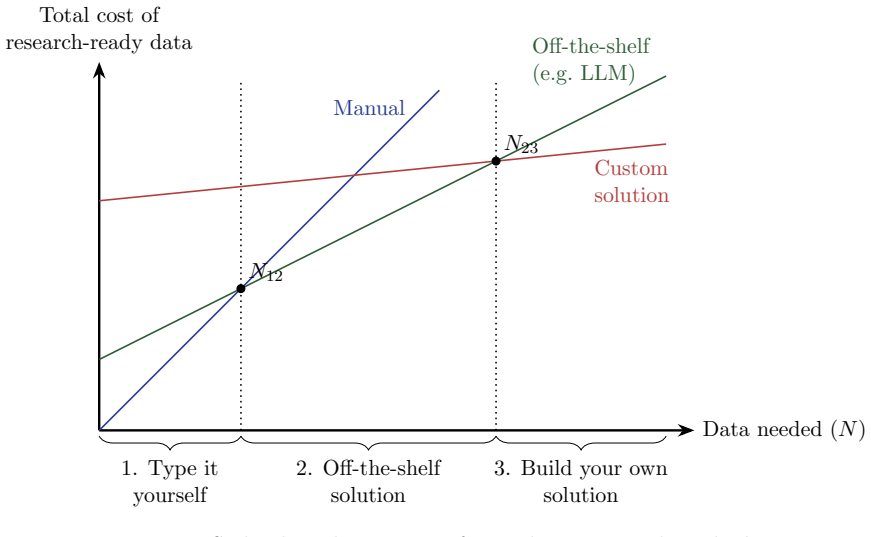
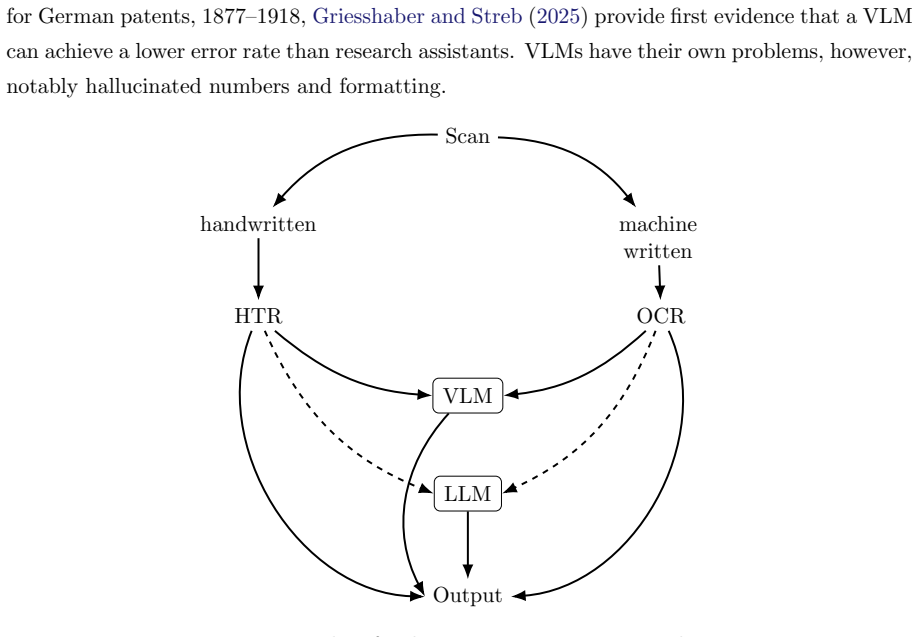
Machine learning (ML) has rapidly transformed economic history, lowering costs of digitization, data linkage, and imputation, and making information in historical text usable at scale. This paper offers a practical guide to using these tools well. However, ML tools have also created new problems. Prediction errors are often systematically correlated with covariates of interest, so even highly accurate models can distort and sometimes reverse coefficients, and standard validation cannot detect this. Given that ML tools often perform worse for historical data, this problem is especially severe for the field of economic history. We also identify a solution to this problem. We show that recent debiasing methods can correct such bias for a wide class of applications, using a small, randomly sampled set of expert-coded labels while retaining the efficiency of large-scale prediction. We organize the field with a taxonomy of three ML tasks, survey the literature along it, and indicate where debiasing applies and where validation against proxies remains the only recourse. We close with best-practice guidance on digitization, model choice, and reproducibility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that ML predictions in economic history frequently exhibit errors systematically correlated with covariates of interest, distorting or reversing regression coefficients in ways undetectable by standard validation. It proposes that recent debiasing methods can correct this bias for a wide class of applications using only a small, randomly sampled set of expert-coded labels while retaining the efficiency of large-scale ML. The manuscript organizes the literature via a taxonomy of three ML tasks, surveys applications along this taxonomy, indicates where debiasing applies versus where proxy validation is the only option, and closes with best-practice guidance on digitization, model choice, and reproducibility.
Significance. If the debiasing claim is substantiated, the paper would be a useful contribution to economic history by mitigating a documented risk in ML-assisted digitization, linkage, and text analysis. The taxonomy and survey could help structure a rapidly growing literature, and the emphasis on reproducibility is a clear strength. No machine-checked proofs or parameter-free derivations are present, but the focus on practical, falsifiable guidance for when debiasing succeeds versus fails is a positive feature.
major comments (2)
- [Abstract] Abstract: the assertion that debiasing methods 'can correct such bias for a wide class of applications, using a small, randomly sampled set of expert-coded labels while retaining the efficiency of large-scale prediction' is presented without any equations, simulation results, or empirical validation. This is load-bearing for the central claim and must be addressed with concrete demonstrations.
- [Debiasing methods section (or equivalent)] The section on debiasing application: the claim that a small random expert subsample suffices to recover unbiased coefficients rests on the unexamined assumption that sampling variance remains low when the error-covariate mapping is driven by low-frequency historical categories or high-dimensional text features. No bounds, sensitivity checks, or counter-examples are supplied to show when N~100 labels retain efficiency without residual bias.
minor comments (2)
- [Taxonomy section] Taxonomy of three ML tasks: provide explicit definitions and decision rules for assigning a given application to each task so readers can apply the taxonomy consistently.
- [Literature survey] Literature survey: ensure recent ML debiasing references (post-2020) are included and that the survey distinguishes methods that require only random labels from those needing additional structure.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. The comments highlight important aspects of how the central claims are presented. We respond to each major comment below and indicate the revisions we will undertake.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that debiasing methods 'can correct such bias for a wide class of applications, using a small, randomly sampled set of expert-coded labels while retaining the efficiency of large-scale prediction' is presented without any equations, simulation results, or empirical validation. This is load-bearing for the central claim and must be addressed with concrete demonstrations.
Authors: The abstract is a concise summary and therefore omits technical details such as equations or specific results; these appear in the body of the manuscript. Section 4 contains simulation evidence on the performance of the debiasing procedure across different bias structures, and Section 5 reports an empirical illustration using a small expert-labeled subsample. To make the abstract claim more self-contained, we will revise the abstract to include a short parenthetical reference to the simulation and empirical validation provided later in the paper. revision: partial
-
Referee: [Debiasing methods section (or equivalent)] The section on debiasing application: the claim that a small random expert subsample suffices to recover unbiased coefficients rests on the unexamined assumption that sampling variance remains low when the error-covariate mapping is driven by low-frequency historical categories or high-dimensional text features. No bounds, sensitivity checks, or counter-examples are supplied to show when N~100 labels retain efficiency without residual bias.
Authors: We agree that the manuscript would benefit from explicit guidance on the conditions under which a small expert subsample remains reliable. The current text invokes the asymptotic properties of the cited debiasing estimators but does not examine finite-sample behavior under low-frequency categories or high-dimensional features. In the revision we will add a dedicated subsection containing Monte Carlo experiments that vary category frequency and feature dimensionality, report the resulting bias and variance for N around 100, and include counter-examples in which the procedure leaves residual bias. This will delineate the practical scope of the recommendation. revision: yes
Circularity Check
No circularity: draws on external debiasing methods
full rationale
The paper's central claim is that existing recent debiasing methods (referenced as external) can be applied to a small random expert-coded subsample to correct systematic prediction errors correlated with covariates, while preserving large-scale efficiency. No derivation chain reduces this to a self-definition, fitted parameter renamed as prediction, or self-citation load-bearing step; the taxonomy and guidance organize literature without re-deriving the debiasing technique itself. The demonstration therefore remains independent of the paper's own inputs and does not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recent debiasing methods from the machine learning literature can be applied to correct systematic prediction errors correlated with covariates in economic history data.
Reference graph
Works this paper leans on
-
[1]
Grajzl, Peter and Murrell, Peter. Combining Machine Learning and Econometrics to Examine the Historical Roots of Institutions and Cultures. Handbook of New Institutional Economics. 2025. doi:10.1007/978-3-031-50810-3_39
-
[2]
Annual Review of Economics , volume=
Text algorithms in economics , author=. Annual Review of Economics , volume=. 2023 , publisher=
2023
-
[3]
Advances in Neural Information Processing Systems , volume=
Using imperfect surrogates for downstream inference: Design-based supervised learning for social science applications of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
2024 , note=
Using Large Language Model Annotations for the Social Sciences: A General Framework of Using Predicted Variables in Downstream Analyses , author=. 2024 , note=
2024
-
[5]
Social Network Analysis and Mining , volume=
Generalizing sentiment analysis: a review of progress, challenges, and emerging directions , author=. Social Network Analysis and Mining , volume=. 2025 , publisher=
2025
-
[6]
Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
Recursive deep models for semantic compositionality over a sentiment treebank , author=. Proceedings of the 2013 conference on empirical methods in natural language processing , pages=
2013
-
[7]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[8]
The Cult of King Charles the Martyr , publisher=
Lacey, Andrew , year=. The Cult of King Charles the Martyr , publisher=
-
[9]
Secret rites and secret writing Royalist literature, 1641--1660 , author =
-
[10]
2024 , publisher=
The Blazing World: A New History of Revolutionary England, 1603-1689 , author=. 2024 , publisher=
2024
-
[11]
The Economic Journal , pages =
Baker, Jennifer L and Bjerregaard, Lise G and Dahl, Christian M and Johansen, Torben S D and Sørensen, Emil N and Wüst, Miriam , title =. The Economic Journal , pages =. 2026 , month =. doi:10.1093/ej/ueag057 , url =
-
[12]
International Journal of Epidemiology , volume =
Bjerregaard, Lise G and Wüst, Miriam and Johansen, Torben S D and Sørensen, Thorkild I A and Dahl, Christian M and Baker, Jennifer L , title =. International Journal of Epidemiology , volume =. 2023 , month =. doi:10.1093/ije/dyad096 , url =
-
[13]
and Hwang, Sam Il Myoung and Johansen, Torben S
Dahl, Christian M. and Hwang, Sam Il Myoung and Johansen, Torben S. D. and Squires, Munir. Improving Historical Census Transcriptions: A Machine Learning Approach. 2024
2024
-
[14]
2026 , month = jun, note =
Ferrara, Andreas , title =. 2026 , month = jun, note =
2026
-
[15]
1972 , publisher=
The World Turned Upside Down: Radical Ideas During the English Revolution , author=. 1972 , publisher=
1972
-
[16]
http://www.nber.org/papers/w34816
Giommoni, Tommaso and Loumeau, Gabriel and Tabellini, Marco. Extractive Taxation and the French Revolution. 2026. doi:10.3386/w34816 , URL = "http://www.nber.org/papers/w34816", abstract =
-
[17]
Wolsky and Naoki Egami and Brandon M
Alessandra Rister Portinari Maranca and Jihoon Chung and Musashi Hinck and Adam D. Wolsky and Naoki Egami and Brandon M. Stewart , title =. Sociological Methods & Research , volume =. 2025 , doi =
2025
-
[18]
arXiv preprint arXiv:2406.01382 , year=
Do large language models perform the way people expect? measuring the human generalization function , author=. arXiv preprint arXiv:2406.01382 , year=
-
[19]
Christian Møller Dahl and Torben Johansen and Christian Vedel , year=. Breaking the. 2402.13604 , archivePrefix=
-
[20]
Historical Methods: A Journal of Quantitative and Interdisciplinary History , volume=
The creation of LIFE-M: The longitudinal, intergenerational family electronic micro-database project , author=. Historical Methods: A Journal of Quantitative and Interdisciplinary History , volume=. 2023 , publisher=
2023
-
[21]
Explorations in Economic History , pages=
Breakthroughs in historical record linking using genealogy data: The census tree project , author=. Explorations in Economic History , pages=. 2025 , volume =
2025
-
[22]
Explorations in Economic History , volume=
Examining the role of training data for supervised methods of automated record linkage: Lessons for best practice in economic history , author=. Explorations in Economic History , volume=. 2025 , publisher=
2025
-
[23]
A machine learning approach for nominative record linkage in
Yu, Yue and Hou, Yueran and Wu, Yibei and Campbell, Cameron , journal=. A machine learning approach for nominative record linkage in. 2026 , publisher=
2026
-
[24]
1824 , address =
Ranke, Leopold von , title =. 1824 , address =
-
[25]
1954 , address =
Bloch, Marc , title =. 1954 , address =
1954
-
[26]
2015 , address =
Tosh, John , title =. 2015 , address =
2015
-
[27]
Political Science Research and Methods , author=
Fine-tuned large language models can replicate expert coding better than trained coders: a study on informative signals sent by interest groups , DOI=. Political Science Research and Methods , author=. 2026 , pages=
2026
-
[28]
http://www.nber.org/papers/w34834
Asirvatham, Hemanth and Mokski, Elliott and Shleifer, Andrei. GPT as a Measurement Tool. 2026. doi:10.3386/w34834 , URL = "http://www.nber.org/papers/w34834", abstract =
-
[29]
Explorations in Economic History , volume=
Digitizing historical balance sheet data: A practitioner’s guide , author=. Explorations in Economic History , volume=. 2023 , publisher=
2023
-
[30]
Historical Methods: A Journal of Quantitative and Interdisciplinary History , volume=
Applications of machine learning in tabular document digitisation , author=. Historical Methods: A Journal of Quantitative and Interdisciplinary History , volume=. 2023 , publisher=
2023
-
[31]
2025 , note =
dsl: Design-based Supervised Learning , author =. 2025 , note =
2025
-
[32]
American Economic Journal: Applied Economics , volume=
Gender attitudes in the judiciary: Evidence from US circuit courts , author=. American Economic Journal: Applied Economics , volume=. 2024 , publisher=
2024
-
[33]
The Economic Journal , volume =
Gennaro, Gloria and Ash, Elliott , title =. The Economic Journal , volume =. 2021 , month =. doi:10.1093/ej/ueab104 , url =
-
[34]
European Management Review , volume=
The value of European patents , author=. European Management Review , volume=. 2008 , publisher=
2008
-
[35]
The Rand journal of economics , pages=
A penny for your quotes: patent citations and the value of innovations , author=. The Rand journal of economics , pages=. 1990 , publisher=
1990
-
[36]
Management Science , volume=
Lens or prism? Patent citations as a measure of knowledge flows from public research , author=. Management Science , volume=. 2013 , publisher=
2013
-
[37]
R&D and productivity: the econometric evidence , pages=
Patent statistics as economic indicators: a survey , author=. R&D and productivity: the econometric evidence , pages=. 1998 , publisher=
1998
-
[38]
1996 , publisher =
Sharpe, James , title =. 1996 , publisher =
1996
-
[39]
Oxford Dictionary of National Biography , editor =
Sharpe, James , title =. Oxford Dictionary of National Biography , editor =. 2004 , doi =
2004
-
[40]
Nature , volume=
Papers and patents are becoming less disruptive over time , author=. Nature , volume=. 2023 , publisher=
2023
-
[41]
American economic review , volume=
How do patent laws influence innovation? Evidence from nineteenth-century world's fairs , author=. American economic review , volume=. 2005 , publisher=
2005
-
[42]
arXiv preprint arXiv:1907.12009 , year=
Representation degeneration problem in training natural language generation models , author=. arXiv preprint arXiv:1907.12009 , year=
-
[43]
Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , pages=
Glove: Global vectors for word representation , author=. Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) , pages=
2014
-
[44]
How contextual are contextualized word representations? Comparing the geometry of BERT, ELMo, and GPT-2 embeddings , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[45]
SimCSE: Simple Contrastive Learning of Sentence Embeddings
Simcse: Simple contrastive learning of sentence embeddings , author=. arXiv preprint arXiv:2104.08821 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Advances in neural information processing systems , volume=
Visualizing and measuring the geometry of BERT , author=. Advances in neural information processing systems , volume=
-
[47]
Bryson and Arvind Narayanan , title =
Aylin Caliskan and Joanna J. Bryson and Arvind Narayanan , title =. Science , volume =. 2017 , doi =. https://www.science.org/doi/pdf/10.1126/science.aal4230 , abstract =
-
[48]
International Conference on Document Analysis and Recognition , pages=
Layoutparser: A unified toolkit for deep learning based document image analysis , author=. International Conference on Document Analysis and Recognition , pages=. 2021 , organization=
2021
-
[49]
Statistics in medicine , volume=
Surrogate endpoints in clinical trials: definition and operational criteria , author=. Statistics in medicine , volume=. 1989 , publisher=
1989
-
[50]
2003 , publisher=
The statistical evaluation of medical tests for classification and prediction , author=. 2003 , publisher=
2003
-
[51]
Novelty and Impact: Using Document Similarity to Study Important Inventions in Historical Swedish Patents, 1890--1929 , journal =
La Mela, Mattia and Frankem. Novelty and Impact: Using Document Similarity to Study Important Inventions in Historical Swedish Patents, 1890--1929 , journal =. 2025 , doi =
1929
-
[52]
Innovation under censorship: Effects on cultural production in early modern England , journal =
Peter Grajzl and Peter Murrell , keywords =. Innovation under censorship: Effects on cultural production in early modern England , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.jce.2026.02.004 , url =
-
[53]
2026 , note=
Did a feedback mechanism between propositional and prescriptive knowledge create modern growth? , author=. 2026 , note=
2026
-
[54]
Annual Review of Economics , volume=
Patents and innovation in economic history , author=. Annual Review of Economics , volume=. 2016 , publisher=
2016
-
[55]
2024 , note=
Breaking the HISCO Barrier: Automatic Occupational Standardization with OccCANINE , author=. 2024 , note=
2024
-
[56]
2025 , note=
Multimodal LLMs for OCR, OCR Post-Correction, and Named Entity Recognition in Historical Documents , author=. 2025 , note=
2025
-
[57]
Journal of Economic Literature , volume=
Text as data , author=. Journal of Economic Literature , volume=. 2019 , publisher=
2019
-
[58]
Journal of Economic Literature , volume=
Deep learning for economists , author=. Journal of Economic Literature , volume=. 2025 , publisher=
2025
-
[59]
2025 , note=
Multimodal LLMs for Historical Dataset Construction from Archival Image Scans: German Patents (1877-1918) , author=. 2025 , note=
1918
-
[60]
Arora, Abhishek and Dell, Melissa , booktitle=
-
[61]
Proceedings of the National Academy of Sciences , volume=
Augmenting the availability of historical GDP per capita estimates through machine learning , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[62]
Advances in Neural Information Processing Systems , volume=
American stories: A large-scale structured text dataset of historical us newspapers , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
Newswire: A Large-Scale Structured Database of a Century of Historical News , url =
Silcock, Emily and Arora, Abhishek and D Amico-Wong, Luca and Dell, Melissa , booktitle =. Newswire: A Large-Scale Structured Database of a Century of Historical News , url =. doi:10.52202/079017-1575 , editor =
-
[64]
Scientific Reports , volume=
Bias of AI-generated content: an examination of news produced by large language models , author=. Scientific Reports , volume=. 2024 , publisher=
2024
-
[65]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2021 , isbn =. doi:10.1145/3442188.3445922 , abstract =
-
[66]
2025 , month =
Total Recall? Evaluating the Macroeconomic Knowledge of Large Language Models , author =. 2025 , month =
2025
-
[67]
Defeating Nondeterminism in LLM Inference , journal =
Horace He and. Defeating Nondeterminism in LLM Inference , journal =. 2025 , note =
2025
-
[68]
2025 , eprint=
Understanding and Mitigating Numerical Sources of Nondeterminism in LLM Inference , author=. 2025 , eprint=
2025
-
[69]
Science , volume=
Prediction-powered inference , author=. Science , volume=. 2023 , publisher=
2023
-
[70]
2025 , month =
Eddie Yang and Zoey Wang and Carl Zhou and Yaosheng Xu , title =. 2025 , month =
2025
-
[71]
2025 , eprint=
Can LLMs Credibly Transform the Creation of Panel Data from Diverse Historical Tables? , author=. 2025 , eprint=
2025
-
[72]
2025 , institution=
Networks and geographic mobility: Evidence from world war ii navy ships , author=. 2025 , institution=
2025
-
[73]
History LLMs , institution =
G. History LLMs , institution =. 2025 , url =
2025
-
[74]
Public Choice , volume=
Quiet revolutions in early-modern England , author=. Public Choice , volume=. 2024 , publisher=
2024
-
[75]
BAFFI Centre Research Paper , number=
Text Analysis Methods for Historical Letters, The case of Michelangelo Buonarroti , author=. BAFFI Centre Research Paper , number=
-
[76]
2025 , institution=
Technology and Labor Markets: Past, Present, and Future; Evidence from Two Centuries of Innovation , author=. 2025 , institution=
2025
-
[77]
http://www.nber.org/papers/w29260
Arora, Ashish and Belenzon, Sharon and Kosenko, Konstantin and Suh, Jungkyu and Yafeh, Yishay. The Rise of Scientific Research in Corporate America. 2021. doi:10.3386/w29260 , URL = "http://www.nber.org/papers/w29260", abstract =
-
[78]
2023 , eprint=
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[79]
Proceedings of the Twelfth ACM Conference on Learning@ Scale , pages=
Automating Academic Transcript Evaluation: A Comparative Study of OCR Techniques for Course and Grade Evaluation , author=. Proceedings of the Twelfth ACM Conference on Learning@ Scale , pages=
-
[80]
Cox and Valentin Figueroa , keywords =
Gary W. Cox and Valentin Figueroa , keywords =. Agglomeration and creativity in early modern Britain , journal =. 2025 , issn =. doi:https://doi.org/10.1016/j.eeh.2024.101644 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.