JD Oxygen AI Item Center (Oxygen AIIC) V1: An Industrial-Scale LLM/VLM-Centric Solution for Item Understanding, Management, and Applications
Pith reviewed 2026-06-30 09:41 UTC · model grok-4.3
The pith
Oxygen AIIC uses self-evolving LLMs and VLMs to produce item knowledge for tens of billions of SKUs at 94.2% precision and 82.8% recall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
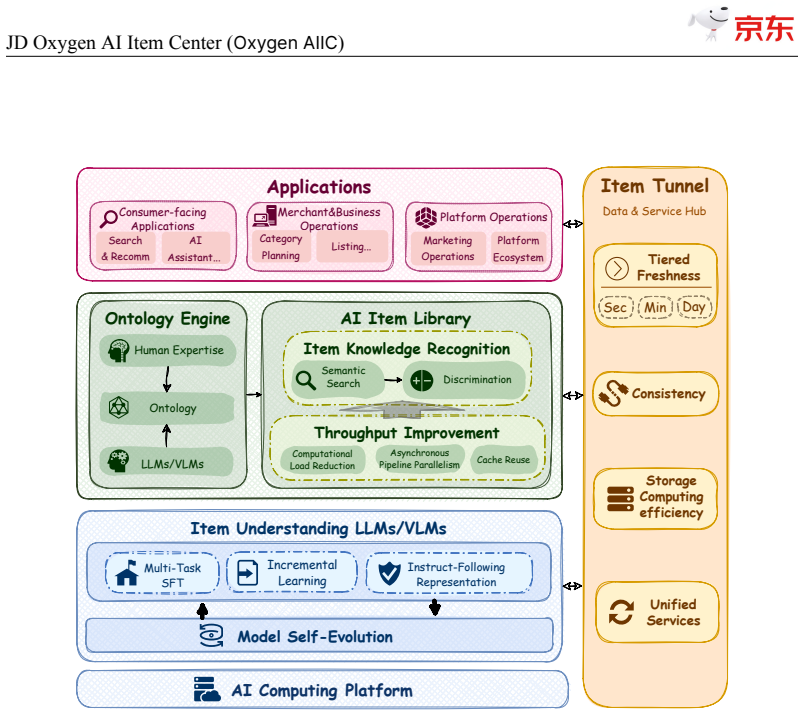
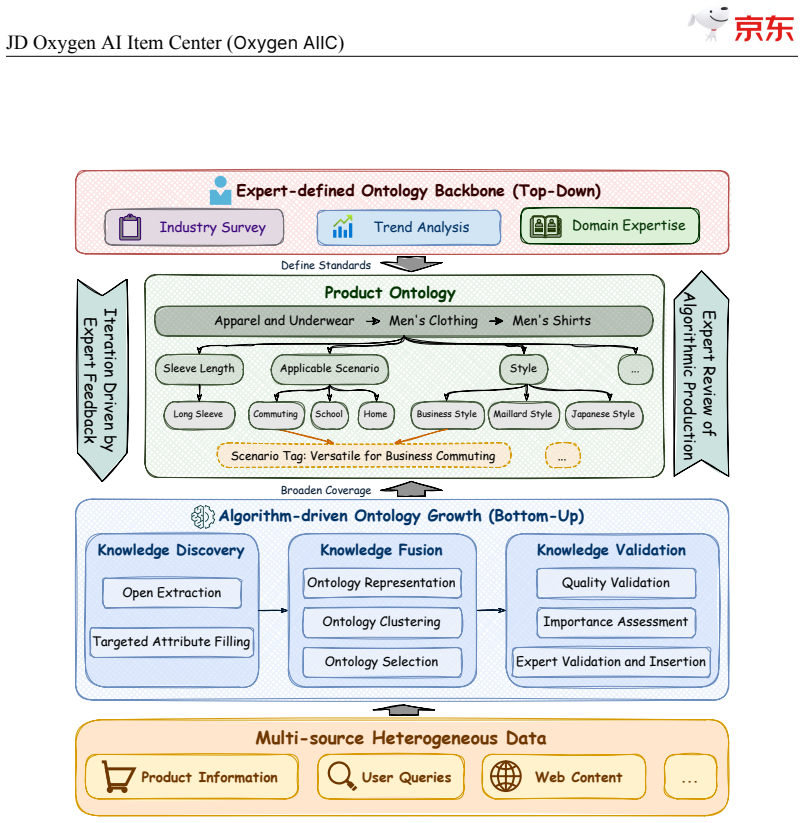
The central claim is that self-evolving item-understanding LLMs and VLMs, when paired with human-AI ontology engineering and the S2D knowledge identification architecture, enable scalable production of high-quality structured item knowledge for tens of billions of SKUs, delivering 94.2% precision, 82.8% recall, and measurable operational gains while running at hundreds of millions of daily updates.
What carries the argument
Self-evolving item-understanding LLMs/VLMs together with the Semantic Search then Discrimination (S2D) architecture, which together drive stable model improvement and high-throughput knowledge identification across the item catalog.
If this is right
- Search-traffic coverage reaches 80.4% in core business scenarios.
- Item-information quality issues drop by 37%.
- Automated fill rate of core attributes during item listing exceeds 80%.
- The platform accumulates hundreds of billions of item-knowledge assets while operating on Huawei Ascend NPUs.
Where Pith is reading between the lines
- The self-evolving loop may reduce the fraction of human effort required per new ontology entry as the catalog grows.
- The S2D architecture could be adapted to other large-scale structured-data domains that combine text and image signals.
- A unified item tunnel may lower the engineering cost of connecting the knowledge base to additional downstream services such as dynamic pricing or inventory forecasting.
Load-bearing premise
The reported precision, recall, and business-impact numbers measured on current production data will remain stable as the ontology expands to millions of entries and daily update volume stays at hundreds of millions.
What would settle it
A new evaluation set drawn from categories added after the reported measurements shows precision or recall falling materially below 94.2% and 82.8%.
Figures


read the original abstract
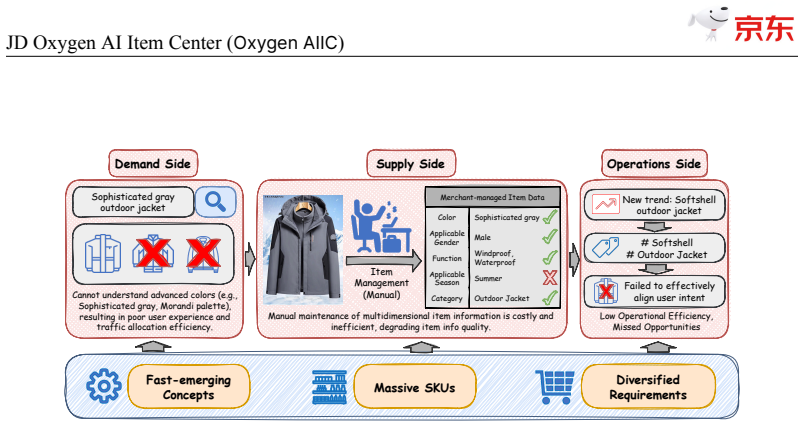
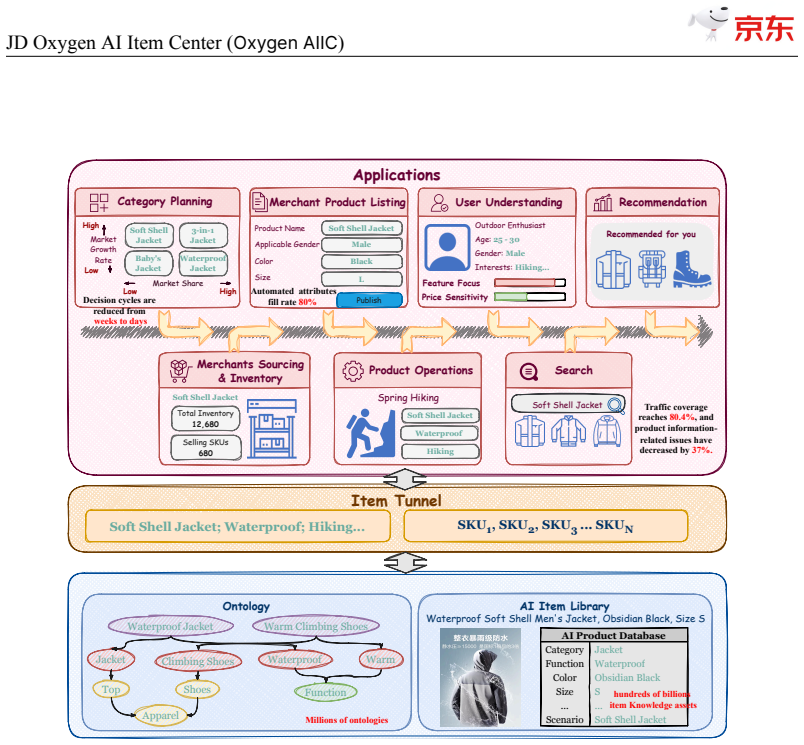
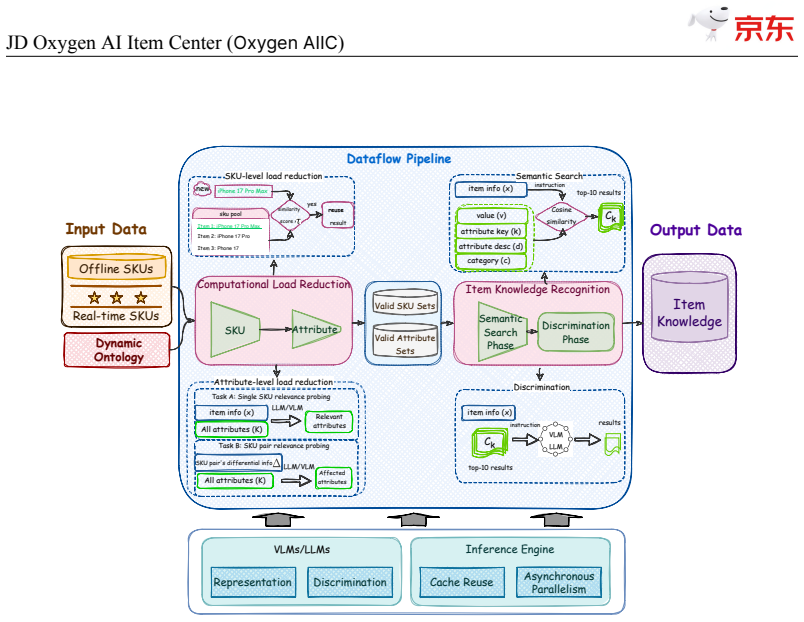
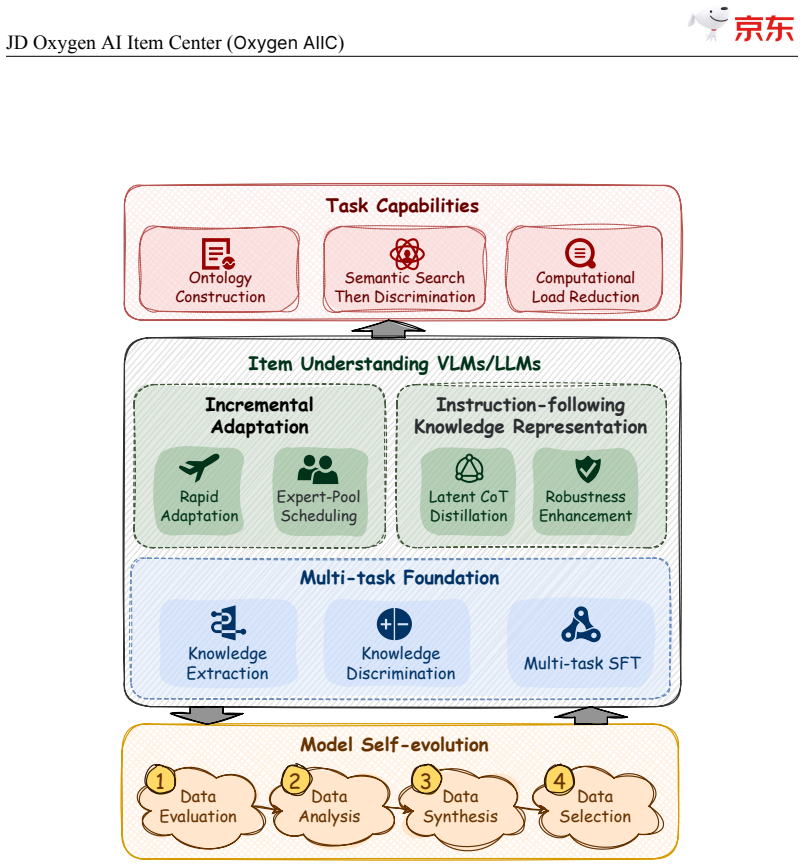
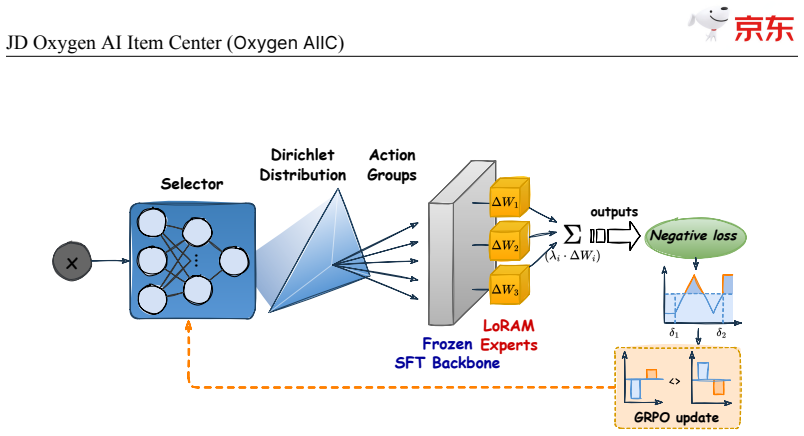
JD$.$com, one of the world's largest e-commerce platforms, serves over 700 million active users and millions of merchants, with a catalog of tens of billions of SKUs. At this scale, high-quality, structured item knowledge underpins a better consumer experience, lower management costs, and higher operational efficiency-yet producing and serving it poses three industrial-scale challenges: fast-emerging concepts, high-quality knowledge production for massive SKUs, and diverse downstream requirements. To address these challenges, we present the JD Oxygen AI Item Center (Oxygen AIIC), an industrial-scale platform built on LLMs/VLMs for item-knowledge production and service. Oxygen AIIC is built around four core pillars: (i) ontology engineering driven by efficient human-AI collaboration, which supports the dynamic evolution and agile expansion of an ontology with millions of entries; (ii) a "Semantic Search then Discrimination"(S2D) knowledge identification architecture that, combined with throughput improvement strategies, enables scalable, extensible, and high-throughput AI Item Library production for tens of billions of SKUs; (iii) self-evolving item-understanding LLMs/VLMs that improve in a stable and controllable manner, enabling knowledge production with 94.2% precision and 82.8% recall; and (iv) a unified item tunnel that serves as the data and service hub. Oxygen AIIC now covers tens of thousands of JD categories and processes hundreds of millions of item updates per day on Huawei Ascend NPUs. It has accumulated hundreds of billions of item-knowledge assets. Deployed across core business scenarios-including search, recommendation, operations, category planning-Oxygen AIIC has delivered measurable gains at scale. Search-traffic coverage reaches 80.4%, item-information quality issues drop by 37%, the automated fill rate of core attributes during item listing exceeds 80%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the JD Oxygen AI Item Center (Oxygen AIIC), an industrial-scale platform at JD.com for item-knowledge production and service using LLMs/VLMs. It outlines four pillars: (i) ontology engineering via human-AI collaboration supporting millions of entries, (ii) a Semantic Search then Discrimination (S2D) architecture for high-throughput processing of tens of billions of SKUs, (iii) self-evolving item-understanding models claimed to achieve 94.2% precision and 82.8% recall, and (iv) a unified item tunnel. The system reportedly processes hundreds of millions of daily updates, has accumulated hundreds of billions of knowledge assets, and delivers business gains including 80.4% search-traffic coverage and a 37% reduction in item-information quality issues across search, recommendation, and operations scenarios.
Significance. If the performance and impact claims are substantiated with rigorous evaluation, the work would represent a significant case study of LLM/VLM deployment at extreme industrial scale, demonstrating practical solutions for ontology evolution, scalable knowledge extraction, and integration with e-commerce workflows. The emphasis on self-evolving models and throughput strategies could inform similar large-scale systems, provided the metrics prove stable and generalizable.
major comments (1)
- [Abstract] Abstract (and any results/evaluation sections): The central claims of production-grade performance rest on the stated 94.2% precision and 82.8% recall for self-evolving LLMs/VLMs, plus downstream metrics (80.4% search coverage, 37% quality-issue reduction). No evaluation protocol, test-set sampling method from the tens-of-billions SKU catalog, ground-truth construction or validation process, ontology-subset representativeness, or non-self-evolving baseline comparisons are provided. This absence makes it impossible to assess whether the numbers support the claims of stable, controllable improvement under the stated daily update volume.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the constructive comment on evaluation rigor. We address the point below and will revise the manuscript to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract] Abstract (and any results/evaluation sections): The central claims of production-grade performance rest on the stated 94.2% precision and 82.8% recall for self-evolving LLMs/VLMs, plus downstream metrics (80.4% search coverage, 37% quality-issue reduction). No evaluation protocol, test-set sampling method from the tens-of-billions SKU catalog, ground-truth construction or validation process, ontology-subset representativeness, or non-self-evolving baseline comparisons are provided. This absence makes it impossible to assess whether the numbers support the claims of stable, controllable improvement under the stated daily update volume.
Authors: We agree that the manuscript would benefit from an explicit evaluation section. In the revision we will add a dedicated subsection that describes: (1) the stratified sampling procedure used to construct the test sets from the full SKU catalog while preserving category and ontology coverage; (2) the multi-stage ground-truth construction process (human annotation guidelines, inter-annotator agreement, and adjudication); (3) how ontology subsets were chosen for representativeness; and (4) the non-self-evolving baseline models against which the reported gains were measured. We will also clarify the temporal split used to simulate the daily-update regime. Because the underlying data are proprietary, we will present the protocol at a level that allows reproducibility of the evaluation design without releasing raw item records. revision: yes
Circularity Check
No circularity: descriptive system paper with no derivations or load-bearing self-citations
full rationale
The manuscript is a high-level engineering description of an industrial platform (four pillars: ontology engineering, S2D architecture, self-evolving LLMs/VLMs, unified tunnel) rather than a theoretical argument containing equations, fitted parameters, or first-principles derivations. Performance figures (94.2% precision, 82.8% recall) are presented as observed outcomes of the deployed system without any reduction to prior inputs by construction, and no self-citations, uniqueness theorems, or ansatzes are invoked to justify core claims. The derivation chain is therefore self-contained as a factual report of architecture and metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bert: Pre-training of deep bidirectional transformers for language understanding , author=. Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers) , pages=
2019
-
[2]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
LLaMA-E: Empowering E-commerce authoring with object-interleaved instruction following , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[3]
Bo Peng and Xinyi Ling and Ziru Chen and Huan Sun and Xia Ning , booktitle=. eCe. 2024 , url=
2024
-
[4]
arXiv preprint arXiv:2406.12023 , year=
LiLiuM: eBay's Large Language Models for e-commerce , author=. arXiv preprint arXiv:2406.12023 , year=
-
[5]
Proceedings of the web conference 2020 , pages=
TaxoExpan: Self-supervised taxonomy expansion with position-enhanced graph neural network , author=. Proceedings of the web conference 2020 , pages=
2020
-
[6]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Octet: Online catalog taxonomy enrichment with self-supervision , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[7]
Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
KATIE: a system for key attributes identification in product knowledge graph construction , author=. Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[8]
Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Opentag: Open attribute value extraction from product profiles , author=. Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[9]
Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Learning to extract attribute value from product via question answering: A multi-task approach , author=. Proceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[10]
CatalogRAG: Retrieval-guided LLM prediction for multilingual e-commerce product attributes , author=
-
[11]
Proceedings of the 2020 ACM SIGMOD international conference on management of data , pages=
Alicoco: Alibaba e-commerce cognitive concept net , author=. Proceedings of the 2020 ACM SIGMOD international conference on management of data , pages=
2020
-
[12]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
Alicoco2: Commonsense knowledge extraction, representation and application in e-commerce , author=. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
-
[13]
Proceedings of the 27th ACM SIGKDD Conference on knowledge discovery & data mining , pages=
All you need to know to build a product knowledge graph , author=. Proceedings of the 27th ACM SIGKDD Conference on knowledge discovery & data mining , pages=
-
[14]
Proceedings of the 13th International Conference on Web Search and Data Mining , pages=
Product Knowledge Graph Embedding for E-commerce , author=. Proceedings of the 13th International Conference on Web Search and Data Mining , pages=. 2020 , doi=
2020
-
[15]
arXiv preprint arXiv:2412.01837 , year=
Enabling Explainable Recommendation in E-commerce with LLM-powered Product Knowledge Graph , author=. arXiv preprint arXiv:2412.01837 , year=
-
[16]
Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
TaxoGen: Unsupervised Topic Taxonomy Construction by Adaptive Term Embedding and Clustering , author=. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2018 , doi=
2018
-
[17]
Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
HiExpan: Task-Guided Taxonomy Construction by Hierarchical Tree Expansion , author=. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2018 , doi=
2018
-
[18]
Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
STEAM: Self-Supervised Taxonomy Expansion with Mini-Paths , author=. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2020 , doi=
2020
-
[19]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=
Scaling up Open Tagging from Tens to Thousands: Comprehension Empowered Attribute Value Extraction from Product Title , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages=. 2019 , doi=
2019
-
[20]
Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining , pages=
MAVE: A Product Dataset for Multi-source Attribute Value Extraction , author=. Proceedings of the Fifteenth ACM International Conference on Web Search and Data Mining , pages=. 2022 , doi=
2022
-
[21]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Multimodal Joint Attribute Prediction and Value Extraction for E-commerce Product , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=. 2020 , doi=
2020
-
[22]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
PAM: Understanding Product Images in Cross Product Category Attribute Extraction , author=. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=. 2021 , doi=
2021
-
[23]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=
SMARTAVE: Structured Multimodal Transformer for Product Attribute Value Extraction , author=. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages=. 2022 , doi=
2022
-
[24]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=
Large Scale Generative Multimodal Attribute Extraction for E-commerce Attributes , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=. 2023 , doi=
2023
-
[25]
Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
Automatic Validation of Textual Attribute Values in E-commerce Catalog by Learning with Limited Labeled Data , author=. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2020 , doi=
2020
-
[26]
Advances in Databases and Information Systems , series=
Using LLMs for the Extraction and Normalization of Product Attribute Values , author=. Advances in Databases and Information Systems , series=. 2024 , publisher=
2024
-
[27]
Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining , pages=
Using Brand Knowledge Bases and LLM Agents to Enhance E-commerce Retailers' Catalog Quality , author=. Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining , pages=. 2026 , doi=
2026
-
[28]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Open-World Attribute Mining for E-Commerce Products with Multimodal Self-Correction Instruction Tuning , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2025 , doi=
2025
-
[29]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages=
Domain Adaptation of Foundation LLMs for e-Commerce , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 6: Industry Track) , pages=. 2025 , doi=
2025
-
[30]
arXiv preprint arXiv:2509.09121 , year=
Compass-v3: Scaling Domain-Specific LLMs for Multilingual E-Commerce in Southeast Asia , author=. arXiv preprint arXiv:2509.09121 , year=
-
[31]
Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining , pages=
MOON: Generative MLLM-based Multimodal Representation Learning for E-commerce Product Understanding , author=. Proceedings of the Nineteenth ACM International Conference on Web Search and Data Mining , pages=. 2026 , doi=
2026
-
[32]
arXiv preprint arXiv:2511.12449 , year=
MOON2.0: Dynamic Modality-balanced Multimodal Representation Learning for E-commerce Product Understanding , author=. arXiv preprint arXiv:2511.12449 , year=
-
[33]
Psychology of learning and motivation , volume=
Catastrophic interference in connectionist networks: The sequential learning problem , author=. Psychology of learning and motivation , volume=. 1989 , publisher=
1989
-
[34]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
2017
-
[35]
International Conference on Learning Representations , year=
Finetuned Language Models are Zero-Shot Learners , author=. International Conference on Learning Representations , year=
-
[36]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[37]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[38]
Advances in Neural Information Processing Systems , volume=
The primacy of magnitude in low-rank adaptation , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Mixture of Lo
Xun Wu and Shaohan Huang and Furu Wei , booktitle=. Mixture of Lo. 2024 , url=
2024
-
[40]
arXiv preprint arXiv:2405.00361 , year=
Adamole: Fine-tuning large language models with adaptive mixture of low-rank adaptation experts , author=. arXiv preprint arXiv:2405.00361 , year=
-
[41]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
arXiv preprint arXiv:2311.01460 , year =
Implicit chain of thought reasoning via knowledge distillation , author=. arXiv preprint arXiv:2311.01460 , year=
-
[43]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
FANoise: Singular Value-Adaptive Noise Modulation for Robust Multimodal Representation Learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[44]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[45]
Advances in Neural Information Processing Systems , volume=
Doremi: Optimizing data mixtures speeds up language model pretraining , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
Semantic product search , author=. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
-
[47]
Language Models are Few-Shot Learners , volume =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[48]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[49]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[50]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[51]
Advances in neural information processing systems , volume=
Flashattention: Fast and memory-efficient exact attention with io-awareness , author=. Advances in neural information processing systems , volume=
-
[52]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[53]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Don’t stop pretraining: Adapt language models to domains and tasks , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[54]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[55]
Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
Simcse: Simple contrastive learning of sentence embeddings , author=. Proceedings of the 2021 conference on empirical methods in natural language processing , pages=
2021
-
[56]
An Overview of Multi-Task Learning in Deep Neural Networks
An overview of multi-task learning in deep neural networks , author=. arXiv preprint arXiv:1706.05098 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
Journal of machine learning research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of machine learning research , volume=
-
[58]
International conference on machine learning , pages=
Parameter-efficient transfer learning for NLP , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[59]
Proceedings of the 28th international conference on computational linguistics , pages=
Continual lifelong learning in natural language processing: A survey , author=. Proceedings of the 28th international conference on computational linguistics , pages=
-
[60]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[61]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Advances in Neural Information Processing Systems , volume=
Star: Bootstrapping reasoning with reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
Advances in neural information processing systems , volume=
Self-refine: Iterative refinement with self-feedback , author=. Advances in neural information processing systems , volume=
-
[64]
Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Self-instruct: Aligning language models with self-generated instructions , author=. Proceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[65]
Companion of the 2024 International Conference on Management of Data , pages =
Yu, Changlong and Liu, Xin and Maia, Jefferson and Li, Yang and Cao, Tianyu and Gao, Yifan and Song, Yangqiu and Goutam, Rahul and Zhang, Haiyang and Yin, Bing and Li, Zheng , title =. Companion of the 2024 International Conference on Management of Data , pages =
2024
-
[66]
Findings of the Association for Computational Linguistics: ACL 2023 , pages =
Yu, Changlong and Wang, Weiqi and Liu, Xin and Bai, Jiaxin and Song, Yangqiu and Li, Zheng and Gao, Yifan and Cao, Tianyu and Yin, Bing , title =. Findings of the Association for Computational Linguistics: ACL 2023 , pages =
2023
-
[67]
Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
Autoknow: Self-driving knowledge collection for products of thousands of types , author=. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=
-
[68]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
AttributeForge: An Agentic LLM Framework for Automated Product Schema Modeling , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[69]
European Semantic Web Conference , pages=
Ontogenia: Ontology generation with metacognitive prompting in large language models , author=. European Semantic Web Conference , pages=
-
[70]
European semantic web conference , pages=
Navigating ontology development with large language models , author=. European semantic web conference , pages=
-
[71]
European Semantic Web Conference , pages=
Ontology generation using large language models , author=. European Semantic Web Conference , pages=
-
[72]
International semantic web conference , pages=
LLMs4OL: Large language models for ontology learning , author=. International semantic web conference , pages=
-
[73]
2023 25th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC) , pages=
Ontology engineering with large language models , author=. 2023 25th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing (SYNASC) , pages=
2023
-
[74]
European Semantic Web Conference , pages=
Neon-gpt: a large language model-powered pipeline for ontology learning , author=. European Semantic Web Conference , pages=
-
[75]
arXiv preprint arXiv:2412.02035 , year=
Llms4life: Large language models for ontology learning in life sciences , author=. arXiv preprint arXiv:2412.02035 , year=
-
[76]
arXiv preprint arXiv:2505.24163 , year=
LKD-KGC: Domain-specific KG construction via LLM-driven knowledge dependency parsing , author=. arXiv preprint arXiv:2505.24163 , year=
-
[77]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
From local to global: A graph rag approach to query-focused summarization , author=. arXiv preprint arXiv:2404.16130 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
arXiv preprint arXiv:2506.00664 , year=
OntoRAG: Enhancing question-answering through automated ontology derivation from unstructured knowledge bases , author=. arXiv preprint arXiv:2506.00664 , year=
-
[79]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Extract, define, canonicalize: An llm-based framework for knowledge graph construction , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[80]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
Schema-adaptable knowledge graph construction , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.