Agentic Hardware Design as Repository-Level Code Evolution
Pith reviewed 2026-06-29 01:46 UTC · model grok-4.3
The pith
A self-evolving agent framework treats hardware design as repository-level code evolution and reaches 100% completion on all evaluated benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
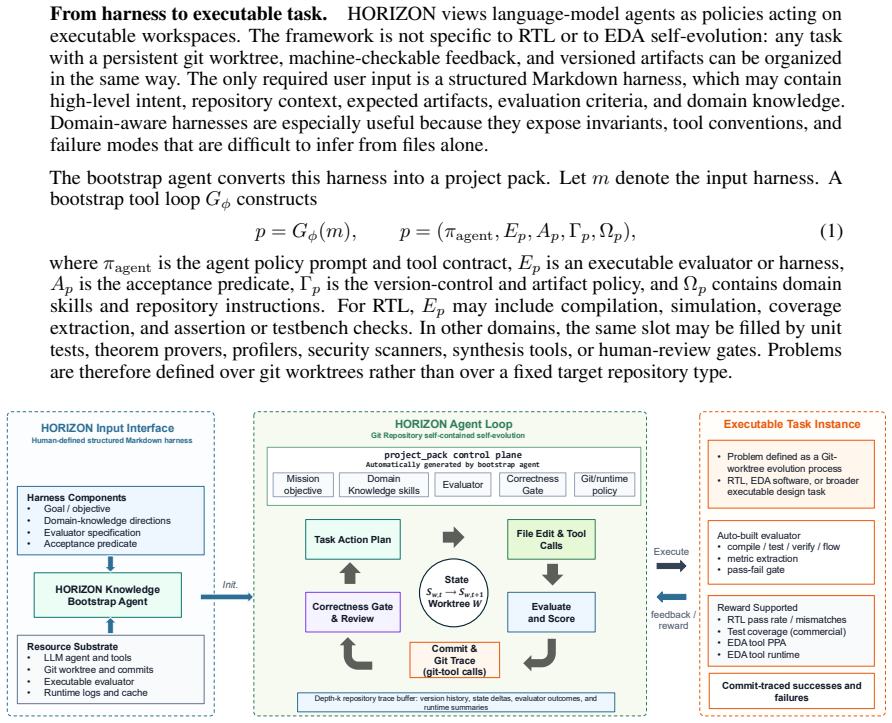
HORIZON shows that hardware design can be cast as repository-level code evolution: a Markdown harness is compiled into a project pack that supplies the agent with domain knowledge, an executable evaluator, an acceptance predicate, and git or runtime policies; the agent then operates a hands-free loop on an isolated git worktree, applying repository operations for state management, tracing, and replay until the design satisfies the predicate, producing 100% completion across the tested suites.
What carries the argument
The Markdown harness compiled into a project pack that contains domain knowledge, an executable evaluator, an acceptance predicate, and a git or runtime policy; the hands-free agent loop that evolves an isolated git worktree using repository operations.
If this is right
- Hardware design artifacts can be evolved to full benchmark success using only repository operations inside isolated git worktrees.
- Self-evolution techniques previously demonstrated on EDA software systems extend directly to hardware design code.
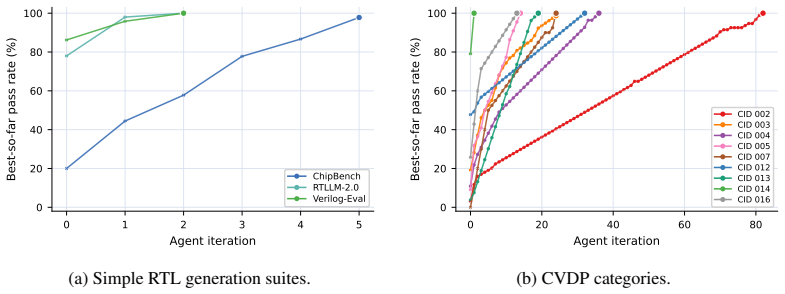
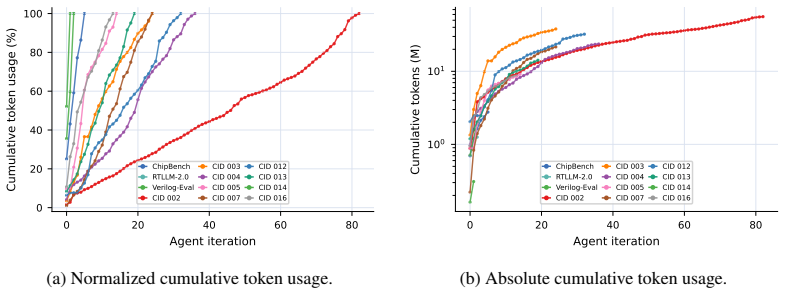
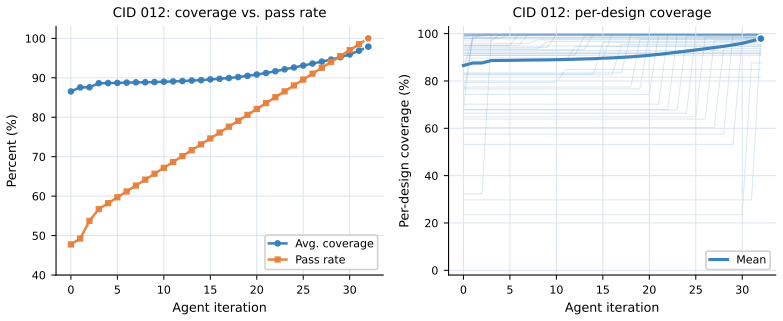
- A fully hands-free agentic loop suffices to complete every task in ChipBench, RTLLM, Verilog-Eval, and the nine CVDP categories.
- The same compilation of Markdown specifications into evaluators and predicates supports reproducible evolution across multiple hardware description tasks.
Where Pith is reading between the lines
- The same harness-to-project-pack conversion could be applied to other code-like engineering artifacts such as testbenches or firmware, provided acceptance predicates can be written in equivalent form.
- If the git-based tracing and replay features prove robust, they could reduce the cost of auditing how an agent reaches a passing design.
- Extending the loop to include synthesis or place-and-route feedback would test whether the current 100% result on RTL-level tasks survives downstream physical design checks.
- The controlled nature of the benchmarks leaves open whether the same harness format remains sufficient when requirements come from natural-language specifications that contain ambiguities.
Load-bearing premise
The Markdown harness and acceptance predicates supplied to the agent correctly encode the requirements and evaluation criteria for the hardware design tasks in a way that generalizes beyond the specific benchmark suites.
What would settle it
A new hardware design benchmark suite, drawn from tasks outside the original four suites, on which the same hands-free loop fails to reach full completion while using harnesses written in the same Markdown format.
Figures
read the original abstract
We present HORIZON, a self-evolving agent framework that treats hardware design as repository-level code evolution. A Markdown harness is compiled into a project pack containing domain knowledge, an executable evaluator, an acceptance predicate, and a git/runtime policy; a hands-free agent loop then evolves an isolated git worktree, using repository operations for state management, tracing, and replay. This extends prior works of repository-scale self-evolution from EDA software systems, to hardware-design artifacts themselves. We evaluate our approach on ChipBench, RTLLM, Verilog-Eval, and nine CVDP categories, achieving 100\% benchmark completion across all suites with a fully hands-free agentic loop. However, we do not claim that agentic AI for hardware design is solved: these benchmarks are controlled proxies for a much broader engineering problem in chip design. Section~\ref{sec:discuss} examines the limitations of the current study and highlights open research challenges.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HORIZON, a self-evolving agent framework that treats hardware design as repository-level code evolution. A Markdown harness is compiled into a project pack containing domain knowledge, an executable evaluator, an acceptance predicate, and a git/runtime policy; a hands-free agent loop then evolves an isolated git worktree using repository operations for state management, tracing, and replay. The approach is evaluated on ChipBench, RTLLM, Verilog-Eval, and nine CVDP categories, achieving 100% benchmark completion across all suites with a fully hands-free agentic loop. The authors caveat that these benchmarks are controlled proxies and do not claim agentic AI for hardware design is solved.
Significance. If the result holds, the work demonstrates that repository-level self-evolution techniques can be extended from EDA software systems to hardware-design artifacts, achieving full completion on the listed benchmark suites via a hands-free loop. The explicit use of git worktrees for isolated evolution, tracing, and replay provides a reproducible mechanism that strengthens the empirical contribution. The framing in the abstract as controlled proxies, with limitations discussed in §\ref{sec:discuss}, appropriately bounds the claims.
major comments (1)
- [Abstract] Abstract: the 100% benchmark completion result is presented as an empirical outcome of the agent loop terminating when the acceptance predicate returns true. No details are given on the construction or independent verification of these predicates relative to the original benchmark specifications (as opposed to being derived from known passing solutions), which is load-bearing for interpreting whether the completions demonstrate genuine repository-level hardware evolution or are specific to the supplied harnesses.
minor comments (1)
- [Abstract] The abstract could explicitly define or expand the acronym CVDP on first use for readers unfamiliar with the benchmark suite.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need for greater transparency regarding the acceptance predicates. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the 100% benchmark completion result is presented as an empirical outcome of the agent loop terminating when the acceptance predicate returns true. No details are given on the construction or independent verification of these predicates relative to the original benchmark specifications (as opposed to being derived from known passing solutions), which is load-bearing for interpreting whether the completions demonstrate genuine repository-level hardware evolution or are specific to the supplied harnesses.
Authors: We agree that additional detail on predicate construction is required for proper interpretation. The acceptance predicates are the executable evaluators and pass criteria supplied directly by the original benchmark suites (ChipBench, RTLLM, Verilog-Eval, and the nine CVDP categories) and are compiled unchanged into each project pack; they are not derived from known passing solutions. The manuscript already notes that these are controlled proxies, but we will add an explicit subsection (new §3.4) describing the predicate compilation process, their one-to-one mapping to the benchmark specifications, and how they can be independently re-run against the benchmark test infrastructure. This revision will clarify that reported completions reflect satisfaction of the benchmark-defined criteria via repository-level edits. revision: yes
Circularity Check
No circularity in empirical agentic evaluation
full rationale
The paper reports an empirical outcome of running a described agent loop on external benchmarks (ChipBench, RTLLM, Verilog-Eval, CVDP), with no mathematical derivation chain, equations, fitted parameters, or self-citation load-bearing steps. The 100% completion claim is presented as an observed result of the hands-free loop on supplied harnesses, not reduced to inputs by construction. No load-bearing self-citations or ansatzes are invoked to justify the central result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AlphaEvolve: A Coding Agent for Scientific and Algorithmic Discovery
Alexander Novikov, Ngân V˜u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, et al. AlphaEvolve: A Coding Agent for Scientific and Algorithmic Discovery. arXiv preprint arXiv:2506.13131,
-
[2]
Autonomous Code Evolution Meets NP- Completeness
10 Cunxi Yu, Rongjian Liang, Chia-Tung Ho, and Haoxing Ren. Autonomous Code Evolution Meets NP- Completeness. arXiv preprint arXiv:2509.07367,
-
[3]
Autonomous Evolution of EDA Tools: Multi-Agent Self-Evolved ABC
Cunxi Yu, Rongjian Liang, Chia-Tung Ho, and Haoxing Ren. Autonomous Evolution of EDA Tools: Multi-Agent Self-Evolved ABC. arXiv preprint arXiv:2604.15082,
-
[4]
Nathaniel Pinckney, Chenhui Deng, Chia-Tung Ho, Yun-Da Tsai, Mingjie Liu, Wenfei Zhou, Brucek Khailany, and Haoxing Ren. Comprehensive Verilog Design Problems: A Next-Generation Benchmark Dataset for Eval- uating Large Language Models and Agents on RTL Design and Verification. arXiv preprint arXiv:2506.14074,
-
[5]
ACE- RTL: When Agentic Context Evolution Meets RTL-Specialized LLMs
Chenhui Deng, Zhongzhi Yu, Guan-Ting Liu, Nathaniel Pinckney, Brucek Khailany, and Haoxing Ren. ACE- RTL: When Agentic Context Evolution Meets RTL-Specialized LLMs. arXiv preprint arXiv:2602.10218,
-
[6]
ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation
Chenhui Deng, Yun-Da Tsai, Guan-Ting Liu, Zhongzhi Yu, and Haoxing Ren. ScaleRTL: Scaling LLMs with Reasoning Data and Test-Time Compute for Accurate RTL Code Generation. arXiv preprint arXiv:2506.05566,
-
[7]
Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie
arXiv:2309.07544. Yao Lu, Shang Liu, Qijun Zhang, and Zhiyao Xie. RTLLM: An Open-Source Benchmark for Design RTL Generation with Large Language Model. InProceedings of the Asia and South Pacific Design Automation Conference (ASP-DAC),
-
[8]
Shang Liu, Yao Lu, Wenji Fang, Mengming Li, and Zhiyao Xie
arXiv:2308.05345. Shang Liu, Yao Lu, Wenji Fang, Mengming Li, and Zhiyao Xie. OpenLLM-RTL: Open Dataset and Benchmark for LLM-Aided Design RTL Generation. InProceedings of the IEEE/ACM International Conference on Computer-Aided Design (ICCAD),
-
[9]
arXiv:2503.15112. Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri, and Siddharth Garg. VeriGen: A Large Language Model for Verilog Code Generation.ACM Transactions on Design Automation of Electronic Systems,
-
[10]
Shang Liu, Wenji Fang, Yao Lu, Jing Wang, Qijun Zhang, Hongce Zhang, and Zhiyao Xie
arXiv:2308.00708. Shang Liu, Wenji Fang, Yao Lu, Jing Wang, Qijun Zhang, Hongce Zhang, and Zhiyao Xie. RTLCoder: Fully Open-Source and Efficient LLM-Assisted RTL Code Generation Technique.IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,
-
[11]
Mingjie Liu, Teodor-Dumitru Ene, Robert Kirby, Chris Cheng, Nathaniel Pinckney, et al
arXiv:2312.08617. Mingjie Liu, Teodor-Dumitru Ene, Robert Kirby, Chris Cheng, Nathaniel Pinckney, et al. ChipNeMo: Domain- Adapted LLMs for Chip Design. arXiv preprint arXiv:2311.00176,
-
[12]
OriGen: Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection
Fan Cui, Chenyang Yin, Kexing Zhou, Youwei Xiao, Guangyu Sun, et al. OriGen: Enhancing RTL Code Generation with Code-to-Code Augmentation and Self-Reflection. arXiv preprint arXiv:2407.16237,
-
[13]
Mingjie Liu, Yun-Da Tsai, Wenfei Zhou, and Haoxing Ren. CraftRTL: High-quality Synthetic Data Generation for Verilog Code Models with Correct-by-Construction Non-Textual Representations and Targeted Code Repair. arXiv preprint arXiv:2409.12993,
-
[14]
AutoChip: Automating HDL Generation Using LLM Feedback
Shailja Thakur, Jason Blocklove, Hammond Pearce, Benjamin Tan, Siddharth Garg, and Ramesh Karri. AutoChip: Automating HDL Generation Using LLM Feedback. arXiv preprint arXiv:2311.04887,
-
[15]
Chia-Tung Ho, Haoxing Ren, and Brucek Khailany
arXiv:2311.16543. Chia-Tung Ho, Haoxing Ren, and Brucek Khailany. VerilogCoder: Autonomous Verilog Coding Agents with Graph-based Planning and Abstract Syntax Tree (AST)-based Waveform Tracing Tool. InProceedings of the AAAI Conference on Artificial Intelligence,
-
[16]
Yujie Zhao, Hejia Zhang, Hanxian Huang, Zhongming Yu, and Jishen Zhao
arXiv:2408.08927. Yujie Zhao, Hejia Zhang, Hanxian Huang, Zhongming Yu, and Jishen Zhao. MAGE: A Multi-Agent Engine for Automated RTL Code Generation. InProceedings of the 62nd ACM/IEEE Design Automation Conference (DAC),
-
[17]
Beichen Huang, Ran Cheng, and Kay Chen Tan
arXiv:2412.07822. Beichen Huang, Ran Cheng, and Kay Chen Tan. EvoGit: Decentralized Code Evolution via Git-Based Multi- Agent Collaboration. arXiv preprint arXiv:2506.02049,
-
[18]
Git Context Controller: Manage the Context of LLM-based Agents like Git
Junde Wu, Jiayuan Zhu, and Yuyuan Liu. Git Context Controller: Manage the Context of LLM-based Agents like Git. arXiv preprint arXiv:2508.00031,
-
[19]
Reem Aleithan, Haoran Xue, Mohammad Mahdi Mohajer, Elijah Nnorom, Gias Uddin, and Song Wang
arXiv:2310.06770. Reem Aleithan, Haoran Xue, Mohammad Mahdi Mohajer, Elijah Nnorom, Gias Uddin, and Song Wang. SWE-Bench+: Enhanced Coding Benchmark for LLMs. arXiv preprint arXiv:2410.06992,
-
[20]
Whether using test patch is allowed,
Preprint available as arXiv:2503.15223. pengfeigao1, “Whether using test patch is allowed,”SWE-bench/experiments, GitHub issue #16, Jun. 7,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.