HMARS: A Hierarchical Multi-Agent Memory System for Long-Context Reasoning
Pith reviewed 2026-06-30 11:28 UTC · model grok-4.3
The pith
A hierarchical multi-agent system manages long contexts by assigning sub-agents to bounded memory regions and mid-agents to query-specific coordination, retrieving supporting evidence more completely than top-K retrieval.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
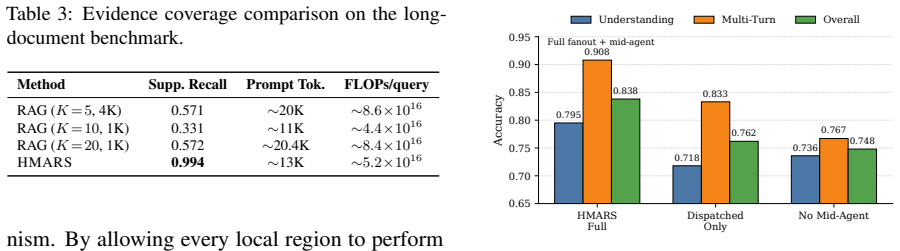
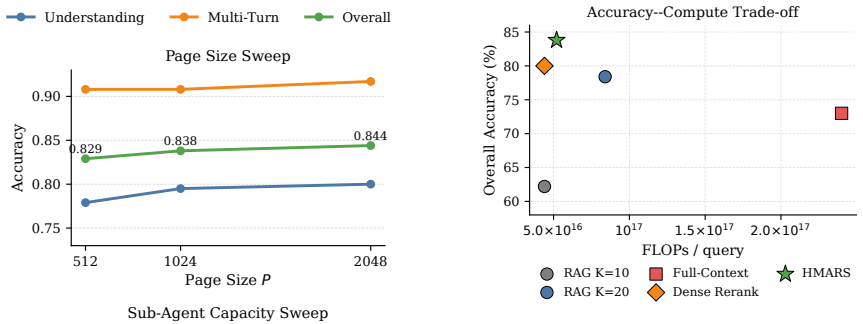
HMARS achieves the best overall performance across long-document and multi-turn memory tasks against retrieval, reranking, full-context, graph-based, and agentic long-context baselines, with evidence coverage analysis showing the gains come from retrieving the required supporting evidence more completely.
What carries the argument
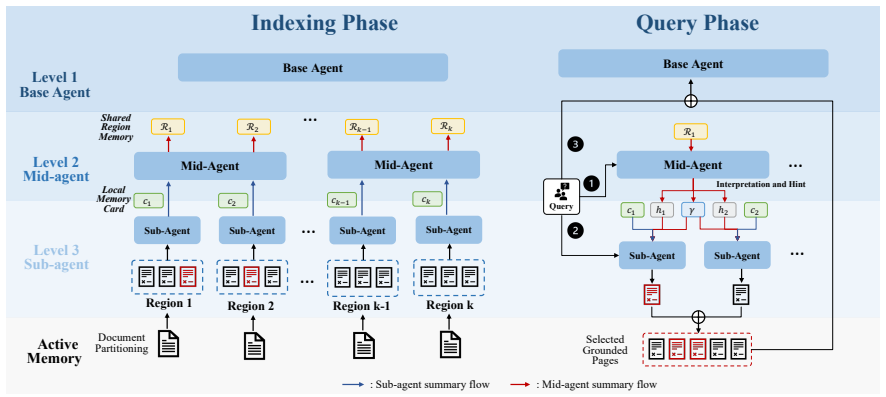
The hierarchical multi-agent memory system, in which sub-agents maintain access to bounded memory regions, mid-agents manage regional context and query-specific coordination, and a frontier model performs final reasoning over evidence pages.
If this is right
- The system outperforms standard retrieval, reranking, full-context, graph-based, and agentic baselines on long-document and multi-turn tasks.
- Performance gains trace directly to more complete retrieval of supporting evidence rather than changes to the final reasoning prompt.
- The approach targets evidence breadth and context-dependent relevance through its diagnostic benchmarks.
- Sub-agents and mid-agents together reduce passive access losses that occur when relevance depends on surrounding context.
Where Pith is reading between the lines
- The structure might allow memory regions to be updated or reorganized dynamically without re-running full retrieval.
- Similar coordination layers could be tested on tasks that combine multiple long documents where evidence spans document boundaries.
- If the hierarchy generalizes, it could reduce the need for ever-larger context windows by focusing agent effort on relevant sub-regions.
Load-bearing premise
Dividing long contexts into hierarchical agent-managed regions will surface context-dependent relevant evidence without the information loss that occurs in flat top-K retrieval.
What would settle it
A diagnostic task in which flat top-K retrieval covers all required evidence but the hierarchical boundaries cause HMARS to miss some pieces, producing lower performance than the flat baseline.
Figures


read the original abstract
Long-context reasoning requires models to access, retrieve, and integrate evidence scattered across documents, dialogues, and accumulated interaction histories. Standard retrieval-augmented generation reduces this problem to top-$K$ chunk retrieval, but such passive access can discard relevant evidence before reasoning begins, especially when relevance depends on broader context. We propose HMARS, a hierarchical multi-agent memory system that treats long contexts as managed memory rather than a flat retrieval corpus. Sub-agents maintain grounded access to bounded memory regions, mid-agents manage regional context and provide query-specific coordination, and a frontier model performs final reasoning over retrieved evidence pages. To evaluate this view, we construct two diagnostic benchmarks targeting evidence breadth and context-dependent relevance. Across long-document and multi-turn memory tasks, HMARS achieves the best overall performance against retrieval, reranking, full-context, graph-based, and agentic long-context baselines. Evidence coverage analysis further shows that its gains come from retrieving the required supporting evidence more completely, rather than merely changing the final answer prompt.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HMARS, a hierarchical multi-agent memory system for long-context reasoning in which sub-agents maintain grounded access to bounded memory regions, mid-agents manage regional context and query-specific coordination, and a frontier model performs final reasoning over retrieved evidence pages. It constructs two diagnostic benchmarks targeting evidence breadth and context-dependent relevance, and claims that HMARS achieves the best overall performance against retrieval, reranking, full-context, graph-based, and agentic baselines on long-document and multi-turn memory tasks, with gains attributable to more complete retrieval of supporting evidence.
Significance. If the performance claims and evidence-coverage analysis are substantiated with reproducible experiments, the work would offer a concrete advance over passive top-K retrieval by showing how hierarchical agent coordination can mitigate context-dependent information loss in long-context settings.
major comments (2)
- [Abstract] Abstract: the assertion that 'HMARS achieves the best overall performance' and that 'its gains come from retrieving the required supporting evidence more completely' is presented without any quantitative metrics, result tables, statistical tests, baseline implementation details, or benchmark construction information, rendering the central empirical claim impossible to evaluate.
- [Abstract] Abstract: the motivating claim that the hierarchical division into sub-agents and mid-agents 'will reliably surface context-dependent relevant evidence without the information loss that occurs in flat top-K retrieval' is unsupported by any description of memory-bounding mechanics, coordination protocols, evidence-page construction, or the precise evidence-coverage metric.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that the abstract can be strengthened to better support its empirical claims and mechanistic descriptions while remaining concise, and we will revise it accordingly. The main body of the manuscript already contains the requested details on metrics, baselines, benchmarks, and system mechanics.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'HMARS achieves the best overall performance' and that 'its gains come from retrieving the required supporting evidence more completely' is presented without any quantitative metrics, result tables, statistical tests, baseline implementation details, or benchmark construction information, rendering the central empirical claim impossible to evaluate.
Authors: We acknowledge that the abstract, as a high-level summary, does not embed the full quantitative details. The manuscript provides these elements in the experimental evaluation, including result tables comparing against all listed baselines, statistical tests, baseline implementation details, and benchmark construction information. To address the concern directly, we will revise the abstract to incorporate key quantitative highlights (such as overall performance gains and evidence coverage improvements) and explicit references to the supporting tables and sections. revision: yes
-
Referee: [Abstract] Abstract: the motivating claim that the hierarchical division into sub-agents and mid-agents 'will reliably surface context-dependent relevant evidence without the information loss that occurs in flat top-K retrieval' is unsupported by any description of memory-bounding mechanics, coordination protocols, evidence-page construction, or the precise evidence-coverage metric.
Authors: The abstract summarizes the approach at a high level. The full manuscript details the memory-bounding mechanics for sub-agents, the coordination protocols used by mid-agents, evidence-page construction, and the precise evidence-coverage metric in the methods and evaluation sections. We will revise the abstract to include a brief description of these components to better ground the motivating claim. revision: yes
Circularity Check
No circularity: empirical performance claims with no derivations
full rationale
The paper describes an architectural proposal (hierarchical sub-agents, mid-agents, evidence pages) and reports empirical results on constructed benchmarks against baselines. No equations, derivations, fitted parameters, or mathematical claims appear in the abstract or described full text. Central claims rest on observed performance and evidence-coverage metrics rather than any reduction to self-definitions, self-citations, or renamed inputs. The evaluation is self-contained as an experimental comparison without load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[2]
International Conference on Learning Representations , volume=
Raptor: Recursive abstractive processing for tree-organized retrieval , author=. International Conference on Learning Representations , volume=
-
[5]
arXiv preprint arXiv:2401.11504 , year=
With greater text comes greater necessity: Inference-time training helps long text generation , author=. arXiv preprint arXiv:2401.11504 , year=
-
[6]
Llmlingua: Compressing prompts for accelerated inference of large language models , author=. arXiv preprint arXiv:2310.05736 , year=
-
[7]
arXiv preprint arXiv:2403.12968 , year=
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression , author=. arXiv preprint arXiv:2403.12968 , year=
-
[8]
2025 , eprint=
Context Cascade Compression: Exploring the Upper Limits of Text Compression , author=. 2025 , eprint=
2025
-
[9]
Advances in Neural Information Processing Systems , volume=
Learning to compress prompts with gist tokens , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
arXiv preprint arXiv:2310.04408 , year=
Recomp: Improving retrieval-augmented lms with compression and selective augmentation , author=. arXiv preprint arXiv:2310.04408 , year=
-
[11]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Compressing context to enhance inference efficiency of large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[12]
arXiv preprint arXiv:2401.03462 , year=
Long context compression with activation beacon , author=. arXiv preprint arXiv:2401.03462 , year=
-
[13]
arXiv preprint arXiv:2209.15189 , year=
Learning by distilling context , author=. arXiv preprint arXiv:2209.15189 , year=
-
[14]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A silver bullet or a compromise for full attention? a comprehensive study of gist token-based context compression , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[15]
arXiv preprint arXiv:2405.03085 , year=
Compressing long context for enhancing rag with amr-based concept distillation , author=. arXiv preprint arXiv:2405.03085 , year=
-
[16]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Leveraging attention to effectively compress prompts for long-context llms , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
arXiv preprint arXiv:2407.01527 , year=
Kv cache compression, but what must we give in return? a comprehensive benchmark of long context capable approaches , author=. arXiv preprint arXiv:2407.01527 , year=
-
[19]
Perception Compressor: A Training-Free Prompt Compression Framework in Long Context Scenarios
Tang, Jiwei and Xu, Jin and Lu, Tingwei and Zhang, Zhicheng and YimingZhao, YimingZhao and LinHai, LinHai and Zheng, Hai-Tao. Perception Compressor: A Training-Free Prompt Compression Framework in Long Context Scenarios. Findings of the Association for Computational Linguistics: NAACL 2025. 2025. doi:10.18653/v1/2025.findings-naacl.229
-
[20]
Test-time learning for large language models,
Test-Time Learning for Large Language Models , author=. arXiv preprint arXiv:2505.20633 , year=
-
[21]
Test-time training on nearest neighbors for large language models , author=. arXiv preprint arXiv:2305.18466 , year=
-
[22]
arXiv preprint arXiv:2410.08020 , year=
Efficiently learning at test-time: Active fine-tuning of llms , author=. arXiv preprint arXiv:2410.08020 , year=
-
[23]
2024 , eprint=
StreamAdapter: Efficient Test Time Adaptation from Contextual Streams , author=. 2024 , eprint=
2024
-
[24]
2024 , eprint=
Generative Adapter: Contextualizing Language Models in Parameters with A Single Forward Pass , author=. 2024 , eprint=
2024
-
[25]
2025 , eprint=
InfiniteICL: Breaking the Limit of Context Window Size via Long Short-term Memory Transformation , author=. 2025 , eprint=
2025
-
[26]
2021 , eprint=
A General Language Assistant as a Laboratory for Alignment , author=. 2021 , eprint=
2021
-
[27]
2022 , eprint=
Prompt Injection: Parameterization of Fixed Inputs , author=. 2022 , eprint=
2022
-
[28]
2022 , eprint=
Prompt Compression and Contrastive Conditioning for Controllability and Toxicity Reduction in Language Models , author=. 2022 , eprint=
2022
-
[29]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Adapting Language Models to Compress Contexts , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[30]
In-context autoencoder for context compression in a large language model,
In-context autoencoder for context compression in a large language model , author=. arXiv preprint arXiv:2307.06945 , year=
-
[31]
2024 , eprint=
Compressed Context Memory For Online Language Model Interaction , author=. 2024 , eprint=
2024
-
[32]
Advances in Neural Information Processing Systems , volume=
H2o: Heavy-hitter oracle for efficient generative inference of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
Advances in Neural Information Processing Systems , volume=
Snapkv: Llm knows what you are looking for before generation , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
Proceedings of the 39th International Conference on Machine Learning , pages =
Efficient Test-Time Model Adaptation without Forgetting , author =. Proceedings of the 39th International Conference on Machine Learning , pages =. 2022 , editor =
2022
-
[35]
2024 , eprint=
Test-Time Model Adaptation with Only Forward Passes , author=. 2024 , eprint=
2024
-
[36]
Tent: Fully Test-time Adaptation by Entropy Minimization
Tent: Fully test-time adaptation by entropy minimization , author=. arXiv preprint arXiv:2006.10726 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[37]
Know What You Don't Know: Unanswerable Questions for SQuAD
Know what you don't know: Unanswerable questions for SQuAD , author=. arXiv preprint arXiv:1806.03822 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
2021 , eprint=
BookSum: A Collection of Datasets for Long-form Narrative Summarization , author=. 2021 , eprint=
2021
-
[39]
ArXiv , year=
Don't Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization , author=. ArXiv , year=
-
[40]
2023 , eprint=
GPQA: A Graduate-Level Google-Proof Q&A Benchmark , author=. 2023 , eprint=
2023
-
[41]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[42]
Transactions of the Association for Computational Linguistics , volume=
Coqa: A conversational question answering challenge , author=. Transactions of the Association for Computational Linguistics , volume=. 2019 , publisher=
2019
-
[43]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv preprint arXiv:2510.00636 , year=
Expected Attention: KV Cache Compression by Estimating Attention from Future Queries Distribution , author=. arXiv preprint arXiv:2510.00636 , year=
-
[45]
arXiv preprint arXiv:2502.00299 , year=
Chunkkv: Semantic-preserving kv cache compression for efficient long-context llm inference , author=. arXiv preprint arXiv:2502.00299 , year=
-
[46]
500x C ompressor: Generalized Prompt Compression for Large Language Models
Li, Zongqian and Su, Yixuan and Collier, Nigel. 500x C ompressor: Generalized Prompt Compression for Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1219
-
[48]
arXiv e-prints , year = 2017, eid =
triviaqa: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. arXiv e-prints , year = 2017, eid =
2017
-
[49]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
International conference on learning representations , volume=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. International conference on learning representations , volume=
-
[53]
Advances in Neural Information Processing Systems , volume=
Chain of agents: Large language models collaborating on long-context tasks , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Advances in Neural Information Processing Systems , volume=
A-mem: Agentic memory for llm agents , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[59]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[60]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[61]
Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
H-mem: Hierarchical memory for high-efficiency long-term reasoning in llm agents , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[62]
2026 , eprint=
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG , author=. 2026 , eprint=
2026
-
[63]
2025 , eprint=
Hierarchical Document Refinement for Long-context Retrieval-augmented Generation , author=. 2025 , eprint=
2025
-
[67]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
LONGAGENT: achieving question answering for 128k-token-long documents through multi-agent collaboration , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[68]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[72]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[73]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. Gpt-4 technical report. arXiv preprint arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[74]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avi Sil, and Hannaneh Hajishirzi. 2024. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In International conference on learning representations, volume 2024, pages 9112--9141
2024
-
[75]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, and 1 others. 2024. Longbench: A bilingual, multitask benchmark for long context understanding. In Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119--3137
2024
-
[76]
Yushi Bai, Shangqing Tu, Jiajie Zhang, Hao Peng, Xiaozhi Wang, Xin Lv, Shulin Cao, Jiazheng Xu, Lei Hou, Yuxiao Dong, and 1 others. 2025. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3639--3664
2025
- [77]
-
[78]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. 2024. From local to global: A graph rag approach to query-focused summarization. arXiv preprint arXiv:2404.16130
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [81]
- [82]
- [83]
- [84]
- [85]
-
[86]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, and 1 others. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459--9474
2020
-
[87]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher Manning. 2024. Raptor: Recursive abstractive processing for tree-organized retrieval. In International Conference on Learning Representations, volume 2024, pages 32628--32649
2024
-
[88]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, and 467 others. 2026 a . https://arxiv.org/abs/2601.03267 Openai gpt-5 system...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[89]
Agentic Retrieval-Augmented Generation: A Survey on Agentic RAG
Aditi Singh, Abul Ehtesham, Saket Kumar, Tala Talaei Khoei, and Athanasios V. Vasilakos. 2026 b . https://arxiv.org/abs/2501.09136 Agentic retrieval-augmented generation: A survey on agentic rag . Preprint, arXiv:2501.09136
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[90]
Haoran Sun, Shaoning Zeng, and Bob Zhang. 2026. H-mem: Hierarchical memory for high-efficiency long-term reasoning in llm agents. In Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 341--350
2026
-
[91]
Zhen Tan, Jun Yan, I-Hung Hsu, Rujun Han, Zifeng Wang, Long Le, Yiwen Song, Yanfei Chen, Hamid Palangi, George Lee, and 1 others. 2025. In prospect and retrospect: Reflective memory management for long-term personalized dialogue agents. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), page...
2025
-
[92]
Yu Wang and Xi Chen. 2025. Mirix: Multi-agent memory system for llm-based agents. arXiv preprint arXiv:2507.07957
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[93]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2026. A-mem: Agentic memory for llm agents. Advances in Neural Information Processing Systems, 38:17577--17604
2026
-
[94]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z Pan, and 1 others. 2025. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning. arXiv preprint arXiv:2508.19828
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[95]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.