From Regulatory Approvals to Patents: Cross-Domain Linking for Cardiovascular Device Traceability
Pith reviewed 2026-06-30 11:30 UTC · model grok-4.3
The pith
A coarse-to-fine framework links FDA cardiovascular devices to USPTO patents at 91.6 percent recall using ontology normalization and multi-signal ranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
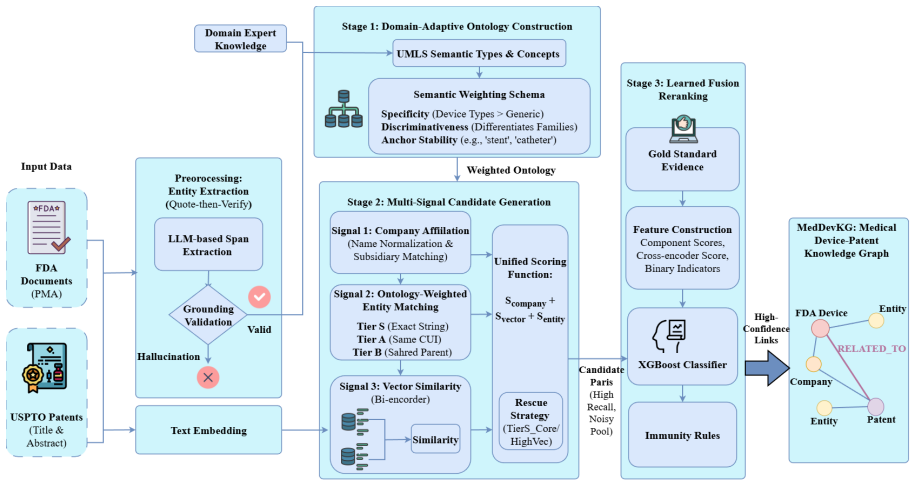
The central claim is that Bridge-MedDevKG, by anchoring device concepts via three-tier UMLS normalization in MedDevOnto, fusing company affiliation with semantic similarity and ontology-weighted overlap for candidate generation, and applying heterogeneous reranking with multi-signal scoring plus XGBoost on hard negatives, achieves a conservative lower-bound recall of 91.6 percent on the gold standard of 585 expert-verified pairs together with 50.9 percent noise reduction, thereby generating 6.8 million high-confidence device-patent links.
What carries the argument
Bridge-MedDevKG coarse-to-fine framework that integrates MedDevOnto ontology for concept anchoring, multi-signal candidate generation, and heterogeneous reranking with XGBoost classification.
If this is right
- Manufacturers and regulators can trace recall events back to specific patented mechanisms for root-cause analysis.
- Companies gain a tool for discovering relevant intellectual property during mergers and acquisitions involving medical devices.
- Analysts can map how cardiovascular technologies evolve by following the generated patent linkages over time.
- The same pipeline supplies a scalable base for building similar regulatory-IP graphs in other device specialties.
Where Pith is reading between the lines
- The ontology and signal combination might transfer to non-cardiovascular devices such as orthopedic implants if the UMLS tiers cover their terminology.
- The high-confidence links could serve as training data to improve automated prior-art searches during new device patent filings.
- Overlaying the resulting graph with adverse-event databases could surface correlations between patented features and clinical outcomes.
- Periodic re-running of the pipeline on newly issued approvals and patents would keep the knowledge graph current without full manual re-verification.
Load-bearing premise
The 585 expert-verified pairs form an unbiased sample that represents the true distribution of device-patent relationships across the full patent corpus and the three-tier UMLS normalization captures all valid connections without systematic omission.
What would settle it
A manual review of several hundred randomly sampled pairs from the 698K patents that finds many true device-patent connections missed by the system would falsify the reported recall.
Figures


read the original abstract
Linking FDA-approved medical devices to their underlying United States Patent and Trademark Office (USPTO) patents enables critical applications such as recall root-cause analysis, M&A-driven IP discovery, and technology trajectory mapping. However, this cross-domain entity linking task remains unexplored due to severe *semantic gaps*: FDA documents focus on clinical outcomes, while patents describe technical mechanisms, yielding minimal lexical overlap. We formalize medical device-patent linking as a challenging cross-domain entity linking problem characterized by label scarcity and domain shifts. Using cardiovascular devices as a high-impact, representative domain featuring diverse technologies, high recall rates, and abundant disclosures, we construct a benchmark with 434 devices, 698K patents, and 585 high-fidelity expert-verified pairs. To address these challenges, we propose Bridge-MedDevKG, a coarse-to-fine framework that integrates (1) **MedDevOnto**, a domain-specific ontology that anchors device concepts via three-tier UMLS normalization; (2) **Multi-signal candidate generation** fusing company affiliation, semantic similarity, and ontology-weighted entity overlap; and (3) **Heterogeneous reranking** with multi-signal scoring and XGBoost classification on hard negatives. Our approach achieves a conservative lower-bound recall of 91.6% on the gold standard with 50.9% noise reduction, substantially outperforming LLM baselines under comparable evaluation. The resulting MedDevKG provides 6.8M high-confidence links, laying a scalable foundation for regulatory-IP integration across medical specialties.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes cross-domain linking between FDA-approved cardiovascular devices and USPTO patents as a label-scarce entity linking task with large semantic gaps. It introduces Bridge-MedDevKG, which combines MedDevOnto (three-tier UMLS normalization), multi-signal candidate generation (company affiliation, semantic similarity, ontology-weighted overlap), and XGBoost heterogeneous reranking on hard negatives. On a benchmark of 434 devices, 698K patents, and 585 expert-verified pairs, the method reports 91.6% lower-bound recall and 50.9% noise reduction, outperforming LLM baselines, and releases MedDevKG containing 6.8M high-confidence links.
Significance. If the gold-standard evaluation is shown to be representative and free of selection or tuning bias, the work supplies a concrete, large-scale resource for regulatory-IP integration that could support recall analysis, M&A discovery, and technology mapping. The ontology-driven bridging of clinical and technical vocabularies and the multi-signal candidate stage are technically interesting contributions to cross-domain linking.
major comments (2)
- [Benchmark construction] Benchmark construction (abstract and §3): The manuscript states that the 585 pairs are 'high-fidelity expert-verified' but supplies no description of the sampling frame, selection criteria, or stratification used to draw them from the 698K-patent corpus. Without this information it is impossible to assess whether the reported 91.6% recall is an unbiased estimate or whether the gold standard over-represents lexically or ontologically easy matches.
- [Evaluation methodology] Evaluation and model training (abstract and §4–5): The multi-signal candidate generator and XGBoost reranker are described as being tuned and evaluated on the same 585-pair set. The paper does not report whether a held-out split, cross-validation, or external validation set was used, raising the possibility that the 91.6% recall and 50.9% noise-reduction figures reflect overfitting rather than generalization to the full population of device-patent links.
minor comments (2)
- [Abstract] The abstract refers to a 'conservative lower-bound recall' without defining how the bound is computed or why it is conservative; this definition should appear in the evaluation section.
- [Experiments] Table or figure captions for the LLM baseline comparisons should explicitly state the prompting strategy, temperature, and number of shots used so that the 'comparable evaluation' claim can be reproduced.
Simulated Author's Rebuttal
We thank the referee for highlighting important issues in benchmark construction and evaluation methodology. We address each comment below and will revise the manuscript to provide the requested details and clarifications.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction (abstract and §3): The manuscript states that the 585 pairs are 'high-fidelity expert-verified' but supplies no description of the sampling frame, selection criteria, or stratification used to draw them from the 698K-patent corpus. Without this information it is impossible to assess whether the reported 91.6% recall is an unbiased estimate or whether the gold standard over-represents lexically or ontologically easy matches.
Authors: We agree the manuscript lacks sufficient detail on benchmark construction. The 585 pairs were obtained via expert verification of candidates generated by the multi-signal pipeline (company affiliation + semantic similarity + ontology overlap), with domain experts in cardiovascular devices confirming true matches. However, the sampling frame, selection criteria, and any stratification are not described. We will add a dedicated subsection in §3 that fully documents the construction process, including how the 698K-patent corpus was filtered, the expert review protocol, and steps taken to ensure diversity across device types and patent classes. This will allow readers to evaluate potential selection bias. revision: yes
-
Referee: [Evaluation methodology] Evaluation and model training (abstract and §4–5): The multi-signal candidate generator and XGBoost reranker are described as being tuned and evaluated on the same 585-pair set. The paper does not report whether a held-out split, cross-validation, or external validation set was used, raising the possibility that the 91.6% recall and 50.9% noise-reduction figures reflect overfitting rather than generalization to the full population of device-patent links.
Authors: The reported 91.6% figure is presented as a conservative lower-bound recall precisely because the gold standard may not capture all true links in the 698K corpus. Candidate generation and reranking were developed iteratively with hard-negative mining, but the manuscript does not describe held-out splits or cross-validation. We will revise §4 and §5 to explicitly document the evaluation protocol, including any internal validation (e.g., k-fold on the 585 pairs for hyperparameter tuning) and emphasize that the lower-bound recall and noise-reduction metrics are computed on the verified set while the final MedDevKG release applies the model to the full corpus. If external validation data become available, we will report it in future work. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical cross-domain linking pipeline evaluated on an externally constructed gold standard of 585 expert-verified pairs drawn from a 434-device benchmark. No equations, self-definitional mappings, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text that would reduce the reported 91.6% recall or 6.8M-link count to a quantity defined by the method itself. The multi-signal generator and XGBoost reranker are presented as operating on independent signals and hard negatives, with performance measured against the expert pairs as an external benchmark, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Three-tier UMLS normalization anchors device concepts across FDA clinical language and USPTO technical language
- domain assumption Expert-verified pairs form a high-fidelity gold standard representative of the full device-patent space
invented entities (2)
-
MedDevOnto
no independent evidence
-
Bridge-MedDevKG
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Colleen Cunningham and David Hall
Building a knowledge graph to enable pre- cision medicine.Scientific Data, 10(1):67. Colleen Cunningham and David Hall. 2025. Linking medical device technologies and product markets. Working paper, May 2025. Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage re- trieval ...
2025
-
[2]
Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240. Fangyu Liu, Ehsan Shareghi, Zaiqiao Meng, Marco Basaldella, and Nigel Collier. 2021. Self-alignment 10 pretraining for biomedical entity representations. In Proceedings of the 2021 conference of the North American chapter of the ass...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Structure and semantics preserving document representations. InProceedings of the 45th Inter- national ACM SIGIR Conference on Research and Development in Information Retrieval, pages 780– 790. Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. InProceedings of the 2019 Conference on Empiri- cal Methods ...
-
[4]
Llm-rankfusion: Mitigating intrinsic in- consistency in llm-based ranking.arXiv preprint arXiv:2406.00231. Jingtao Zhan, Qingyao Ai, Yiqun Liu, Jiaxin Mao, Xi- aohui Xie, Min Zhang, and Shaoping Ma. 2022. Disentangled modeling of domain and relevance for adaptable dense retrieval.arXiv preprint arXiv:2208.05753. Longhui Zhang, Yanzhao Zhang, Dingkun Long,...
-
[5]
Keyword matching: Device name or trade name contains cardiovascular terms:cardio, vascular, coronary, atrial, heart, stent, valve, artery, aortic, mitral, pacemaker, defibrillator, ablation, angioplasty, graft, catheter, atherec- tomy, embolectomy, oximeter, electrode, annu- loplasty, cannula, occluder, arrhythmia
-
[6]
Table 9: Non-cardiovascular device exclusions by category
Product code matching: FDA product codes in cardiovascular categories (DXY , LWS, NKE, PAQ, NPT, NIQ, MIH, LJP, MIP, MAJ, etc.) Manual Exclusion.We curate an exclusion list of 29 non-cardiovascular devices that passed initial filters (Table 9). Table 9: Non-cardiovascular device exclusions by category. Category Count Example PMA Orthopedic/Spine 13 P00002...
2016
-
[7]
expandable prosthesis
In-Context Standardization.The model is instructed to perform implicit normalization during extraction. For instance, engineering descriptions like “expandable prosthesis” are mapped to “Stent,” and “RF thermal heating” is mapped to “Cardiac Ablation” (as seen in thePatent Translation Rules section of our prompt)
-
[8]
System,” “Device,
The Anti-Super-Node Rule.To prevent the knowledge graph from degenerating into generic nodes, we enforce a specificity constraint: generic terms (e.g., “System,” “Device,” “Method”) are forbidden unless modified (e.g., “Stent Delivery System”). This directly addresses the granularity challenge (§3, C2)
-
[9]
Precision Extractor
Domain-Specific Role Play.We use distinct system personas: • FDA Extractor: Acts as a “Precision Extractor” focusing on identifying clinical indications and standardized product codes. • Patent Decoder: Acts as a “Translator” to con- vert obfuscated engineering embodiments into standardized clinical functional terms. C.3 Quote-then-Verify Validation To en...
-
[10]
Exact match: Span appears verbatim in source
-
[11]
Case-insensitive: Span matches after lower- casing
-
[12]
bi-directional steerable catheter
Fuzzy match: Levenshtein similarity ≥ 0.85. Non-grounded spans are rejected. Table 10 sum- marizes validation results. C.4 Final Entity Statistics The extraction process yields: • 21,002 unique COMPONENTentities • 12,057 unique MECHANISMentities Table 10: Quote-then-Verify validation statistics. Match Type Count Percentage Exact match 700,054 97.9% Case-i...
-
[13]
Direct yes/no classification
-
[14]
Chain-of-thought reasoning
-
[15]
catheter
Structured criteria for functional matching All models use the final structured prompt requir- ing explicit reasoning about component overlap, functional alignment, and temporal plausibility. Models Evaluated.GPT-4, GPT-4-turbo, Claude-3.5-Sonnet, Gemini-2.5-pro, Gemini-2.5- flash, Qwen2.5-72B, Qwen3-32B, GLM-4-32B, Kimi-K2, DeepSeek-V3. E.2 Full Results ...
-
[16]
Patent litigation filings: PACER database, ITC Section 337 investigations
-
[17]
Virtual patent marking: Manufacturer web- sites listing patents covering specific products
-
[18]
SEC filings: 10-K risk factors, 8-K material events mentioning IP
-
[19]
Investor presentations: Quarterly earnings calls, analyst day materials
-
[20]
bi-directional navigation catheter irrigation path
FDA submissions: PMA summary docu- ments citing prior art I.2 Coverage Statistics • Devices searched: 434 • Devices with disclosed patents: 88 (20.3%) • Total verified pairs: 585 • Patents per device: median = 5, max = 83 The low disclosure rate (20.3%) reflects strate- gic corporate practices—companies selectively dis- close patents for litigation or mar...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.