The Voronoi Bottleneck: Capacity-Aware Dense Retrieval for Product Search
Pith reviewed 2026-06-30 10:33 UTC · model grok-4.3
The pith
Voronoi complexity and sign-rank are equivalent for top-1 retrieval, enabling a label-free diagnostic for per-query failure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
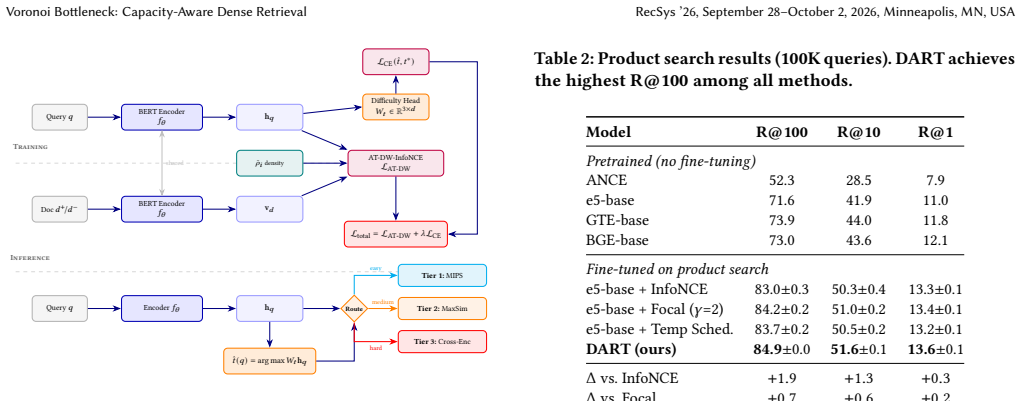
We prove that Voronoi complexity and sign-rank are equivalent for top-1 retrieval, yielding tight dimension bounds and a computable diagnostic, the Capacity Utilization Score (CUS), that predicts per-query retrieval failure with AUC (> 0.8) without relevance labels. CUS identifies moderate and vacuous capacity regimes. On a 100K-query synthetic product-search corpus we introduce AT-DW-InfoNCE, an Adaptive-Temperature Density-Weighted contrastive objective with formally derived optimal weighting, which improves Recall@100 by 1.9 points over an InfoNCE baseline.
What carries the argument
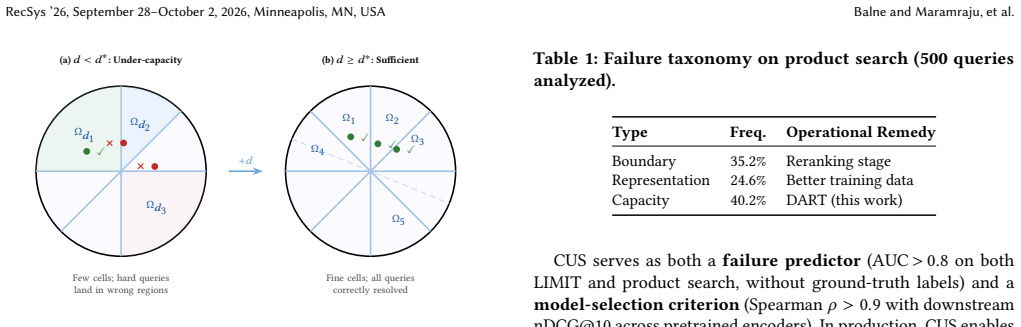
The Voronoi Bottleneck: the geometric limit on the number of distinct top-1 relevance patterns that can be expressed by an inner-product embedding of fixed dimension d, shown to be equivalent to sign-rank.
If this is right
- CUS predicts per-query retrieval failure with AUC greater than 0.8 in the absence of relevance labels.
- CUS partitions queries into a moderate-capacity regime where density-aware training yields gains and a vacuous regime where it does not.
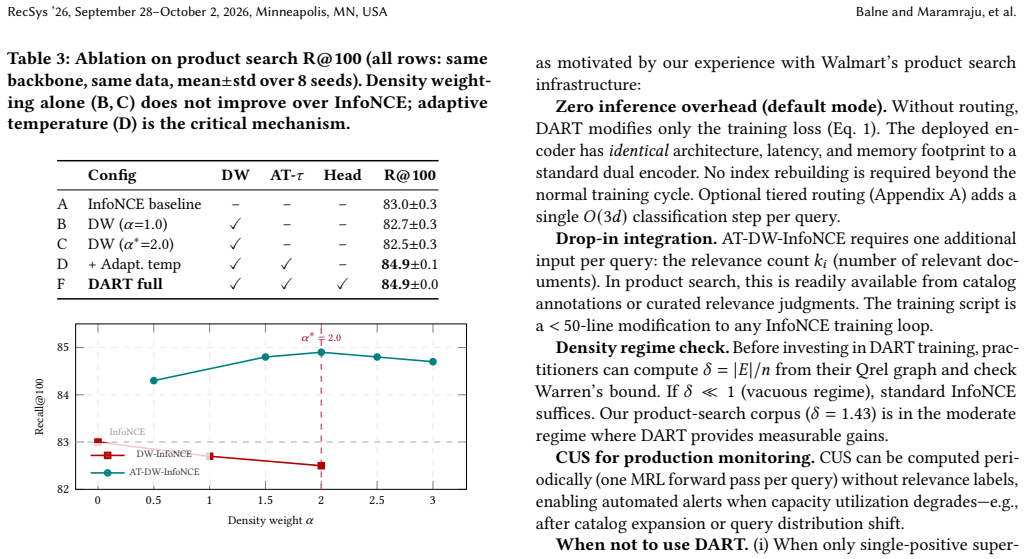
- AT-DW-InfoNCE with optimal weighting alpha star equals 2.0 raises Recall@100 by 1.9 points over a same-data InfoNCE baseline on the synthetic corpus.
- The training change adds zero inference-time overhead and can be used with any dual-encoder system.
Where Pith is reading between the lines
- If the equivalence extends to real distributions, CUS offers an a priori test that lets practitioners skip retraining on queries already at capacity.
- The same capacity argument may supply dimension lower bounds for tasks beyond product search that also rely on top-1 inner-product decisions.
- Query-level CUS values could be used to allocate variable embedding dimensions or to route difficult queries to a second-stage model.
Load-bearing premise
The equivalence between Voronoi complexity and sign-rank, together with the resulting CUS diagnostic, transfers from the controlled synthetic relevance structure to real product-search distributions.
What would settle it
A collection of real product-search queries on which the Capacity Utilization Score shows no statistical correlation with observed retrieval failures would falsify the claim that the diagnostic works without labels.
Figures
read the original abstract
Dense embedding retrieval compresses all relevance information into a single inner product, imposing a fundamental geometric limit -- the Voronoi Bottleneck -- on the number of query-document relevance patterns expressible at fixed embedding dimension (d). We make three contributions. (1) Unified capacity theory. We prove that Voronoi complexity and sign-rank are equivalent for top-1 retrieval, yielding tight dimension bounds and a computable diagnostic, the Capacity Utilization Score (CUS), that predicts per-query retrieval failure with AUC (> 0.8) without relevance labels. (2) Diagnosis. CUS identifies two capacity regimes -- moderate ((\delta \gtrsim 1)), where density-aware training yields measurable gains, and vacuous ((\delta \ll 1)), where it does not -- giving practitioners an a priori check before investing in retraining. (3) DART training. We introduce AT-DW-InfoNCE, an Adaptive-Temperature Density-Weighted contrastive objective with formally derived optimal weighting (\alpha^* = 2.0). On a 100K-query synthetic product-search corpus with controlled relevance structure, DART improves +1.9 Recall@100 over a same-data InfoNCE baseline ((84.9 \pm 0.0) vs. (83.0 \pm 0.3); 8 seeds, (p < 0.001)), outperforming focal loss and temperature-schedule alternatives. DART requires zero inference-time overhead -- it is a drop-in training objective that improves any dual-encoder system.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims a fundamental geometric limit (Voronoi Bottleneck) on dense retrieval expressivity at fixed dimension d. It proves equivalence between Voronoi complexity and sign-rank for top-1 retrieval, yielding dimension bounds and the Capacity Utilization Score (CUS) diagnostic that predicts per-query failure (AUC > 0.8) without relevance labels. It identifies moderate (δ ≳ 1) and vacuous (δ ≪ 1) capacity regimes, and introduces AT-DW-InfoNCE with formally derived α^*=2.0, reporting +1.9 Recall@100 gain (84.9 vs 83.0, p<0.001) over InfoNCE on a 100K-query synthetic product-search corpus with controlled relevance.
Significance. If the equivalence is general and CUS transfers, the work supplies a theoretical diagnostic for when density-aware objectives help and a parameter-free optimal weighting (α^*=2.0) that is a clear strength. The label-free nature of CUS and zero inference overhead of the objective would be practically useful. Current evidence, however, is confined to synthetic data whose relevance structure is author-controlled, limiting immediate significance for real product-search distributions.
major comments (3)
- [Abstract, contribution (1)] Abstract, contribution (1): The claimed equivalence of Voronoi complexity and sign-rank, and the resulting CUS diagnostic with AUC > 0.8, are supported exclusively on the 100K-query synthetic corpus whose relevance patterns are explicitly controlled by the authors; no experiments on real user-behavior or heterogeneous catalog data are reported to substantiate transfer of the dimension bounds or predictive power.
- [Abstract, contribution (2) and (3)] Abstract, contribution (2) and (3): The identification of the two capacity regimes and the +1.9 Recall@100 gain of AT-DW-InfoNCE (with 8 seeds) are demonstrated only under the synthetic relevance structure; this leaves the practical claim that CUS provides an a priori check before retraining unsupported for real product-search workloads.
- [Abstract] Abstract: The formal derivation of α^*=2.0 is presented as a strength, yet the manuscript supplies no verification that the same optimal weighting or CUS threshold remains stable when the embedding-to-relevance mapping deviates from the controlled synthetic regime used to define the capacity regimes.
minor comments (1)
- [Abstract] Abstract: Double parentheses around the regime conditions ((δ ≳ 1)) and ((δ ≪ 1)) should be standardized to conventional single-parenthesis notation for readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We agree that the empirical support for CUS predictive power, capacity regimes, and AT-DW-InfoNCE gains is confined to the controlled synthetic corpus, which limits immediate claims about transfer to real product-search distributions. The theoretical equivalence and derivation of α^*=2.0 are general, but we address each point below and note the standing limitations honestly.
read point-by-point responses
-
Referee: [Abstract, contribution (1)] The claimed equivalence of Voronoi complexity and sign-rank, and the resulting CUS diagnostic with AUC > 0.8, are supported exclusively on the 100K-query synthetic corpus whose relevance patterns are explicitly controlled by the authors; no experiments on real user-behavior or heterogeneous catalog data are reported to substantiate transfer of the dimension bounds or predictive power.
Authors: The equivalence between Voronoi complexity and sign-rank is a theoretical result for top-1 retrieval and does not depend on the synthetic data; it yields general dimension bounds. The AUC > 0.8 for CUS is, however, measured only on the synthetic corpus. We cannot substantiate transfer without real-data experiments, which are absent from the current manuscript. revision: no
-
Referee: [Abstract, contribution (2) and (3)] The identification of the two capacity regimes and the +1.9 Recall@100 gain of AT-DW-InfoNCE (with 8 seeds) are demonstrated only under the synthetic relevance structure; this leaves the practical claim that CUS provides an a priori check before retraining unsupported for real product-search workloads.
Authors: We agree the capacity regimes (moderate δ ≳ 1 vs. vacuous δ ≪ 1) and the reported gain are shown exclusively under the author-controlled synthetic relevance structure. The a priori check claim therefore rests on the theory plus synthetic evidence and lacks real-workload validation in the manuscript. revision: no
-
Referee: [Abstract] The formal derivation of α^*=2.0 is presented as a strength, yet the manuscript supplies no verification that the same optimal weighting or CUS threshold remains stable when the embedding-to-relevance mapping deviates from the controlled synthetic regime used to define the capacity regimes.
Authors: The derivation of α^*=2.0 follows directly from the AT-DW-InfoNCE objective and is independent of any particular data regime. No empirical check of stability under alternative mappings is provided, as all experiments use the synthetic corpus. revision: no
- Transfer of dimension bounds, CUS predictive power (AUC > 0.8), and capacity regimes to real user-behavior or heterogeneous catalog data
- Stability of α^*=2.0 and CUS thresholds when the embedding-to-relevance mapping deviates from the synthetic regime
Circularity Check
No significant circularity; derivation is a first-principles proof with separate empirical validation
full rationale
The central claims rest on a mathematical proof equating Voronoi complexity and sign-rank for top-1 retrieval, from which CUS and the optimal weighting α^*=2.0 are derived. These steps are presented as formal results independent of any fitted data. The subsequent evaluation on a 100K-query synthetic corpus (with controlled relevance) serves only to measure predictive AUC and recall gains; it does not redefine or constrain the preceding theory. No self-citation chains, ansatzes smuggled via prior work, or predictions that reduce to the same fitted parameters appear in the provided text. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- alpha^* =
2.0
axioms (1)
- domain assumption Voronoi complexity and sign-rank are equivalent for top-1 retrieval
invented entities (2)
-
Voronoi Bottleneck
no independent evidence
-
Capacity Utilization Score (CUS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sebastian Hofstätter, Sheng-Chieh Lin, Jheng-Hong Yang, Jimmy Lin, and Allan Hanbury. 2021. Efficiently Teaching an Effective Dense Retriever with Balanced Topic Aware Sampling. InProceedings of the 44th International ACM SIGIR Con- ference on Research and Development in Information Retrieval. 113–122
2021
-
[2]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2021. Billion-Scale Similarity Search with GPUs.IEEE Transactions on Big Data7, 3 (2021), 535–547
2021
-
[3]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 6769–6781
2020
-
[4]
Omar Khattab and Matei Zaharia. 2020. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 39–48
2020
-
[5]
Aditya Kusupati, Gantavya Bhatt, Aniket Rege, Matthew Wallingford, Aditya Sinha, Vivek Ramanujan, William Howard-Snyder, Kaifeng Chen, Sham Kakade, Prateek Jain, and Ali Farhadi. 2022. Matryoshka Representation Learning.Ad- vances in Neural Information Processing Systems35 (2022)
2022
-
[6]
Jinhyuk Lee, Zhuyun Dai, Xiaoqi Ren, Blair Chen, Daniel Cer, Jeremy R. Cole, Kai Hui, Michael Boratko, Rajvi Kapadia, Wen Ding, Yi Luan, Sai Meher Karthik Duddu, Gustavo Hernandez Abrego, Weiqiang Shi, Nithi Gupta, Aditya Kusupati, Prateek Jain, Siddhartha Reddy Jonnalagadda, Ming-Wei Chang, and Iftekhar Naim. 2024. Gecko: Versatile Text Embeddings Distil...
-
[7]
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. 2023. Towards General Text Embeddings with Multi-stage Contrastive Learning.arXiv preprint arXiv:2308.03281(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Ilya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. InInternational Conference on Learning Representations
2019
- [9]
- [10]
-
[11]
Zach Nussbaum, John X Morris, Brandon Duderstadt, and Andriy Mulyar. 2024. Nomic Embed: Training a Reproducible Long Context Text Embedder.arXiv preprint arXiv:2402.01613(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. 2021. Contrastive Learning with Hard Negative Samples. InInternational Conference on Learning Representations
2021
-
[13]
Keshav Santhanam, Omar Khattab, Jon Saad-Falcon, Christopher Potts, and Matei Zaharia. 2022. ColBERTv2: Effective and Efficient Retrieval via Lightweight Late Interaction. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL)
2022
-
[14]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track
2021
-
[15]
Georges Voronoï. 1908. Nouvelles applications des paramètres continus à la théorie des formes quadratiques.Journal für die reine und angewandte Mathematik 133 (1908), 97–178
1908
-
[16]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text Embeddings by Weakly-Supervised Contrastive Pre-Training.arXiv preprint arXiv:2212.03533(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Hugh E. Warren. 1968. Lower Bounds for Approximation by Nonlinear Manifolds. Trans. Amer. Math. Soc.133, 1 (1968), 167–178
1968
- [18]
-
[19]
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. 2023. C-Pack: Packaged Resources To Advance General Chinese Embedding.arXiv preprint arXiv:2309.07597(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Bennett, Junaid Ahmed, and Arnold Overwijk
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. 2021. Approximate Nearest Neighbor Neg- ative Contrastive Learning for Dense Text Retrieval. InInternational Conference on Learning Representations. A Routing Policy: Theorem and Algorithm The difficulty head trained in §4 enables tiered routin...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.