Evolutional Math: Cross-Validated Island-Model Genetic Programming for Interpretable Symbolic Regression on Small, Wide Datasets
Pith reviewed 2026-06-30 11:25 UTC · model grok-4.3
The pith
Cross-validated island-model genetic programming recovers compact symbolic expressions on small wide datasets within tens of thousands of evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a multi-island genetic programming architecture, when fitness is defined as cross-validation R-squared rather than training-set correlation, when populations are seeded with distinct operator subsets and allowed ring migration, when formulas are deduplicated by structure rather than constants, and when constants are refined by L-BFGS-B after migration, consistently locates compact, high-accuracy symbolic models on small wide data using only tens of thousands of unique formula evaluations.
What carries the argument
The four-island genetic programming system that measures fitness by held-out R-squared, migrates individuals across algebraic/logarithmic/trigonometric/full operator islands, deduplicates by structural equivalence, and applies numerical constant optimization after each migration phase.
If this is right
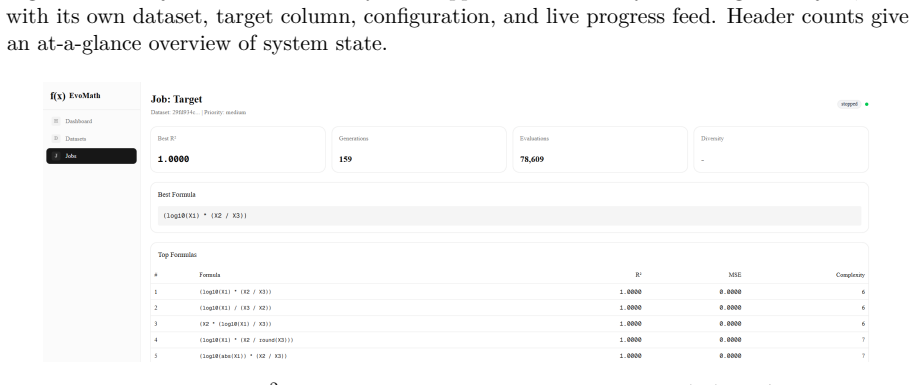
- The method produces models whose R-squared on held-out folds reaches or exceeds 0.99 for log-ratio and trigonometric target forms.
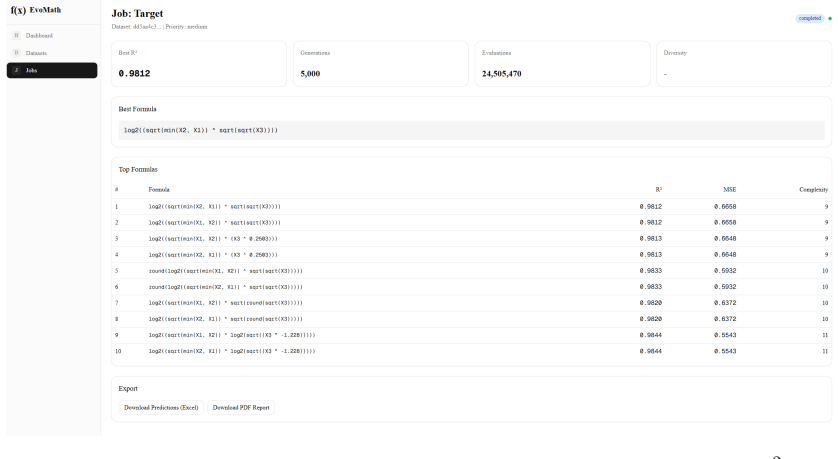
- On a 24-row clinical dataset with roughly 290 numeric features the system yields compact expressions that generalize.
- Structural deduplication plus post-migration constant refinement keeps the elite archive from filling with near-identical variants.
- The total number of unique formula evaluations stays in the low tens of thousands while still locating the ground-truth structure.
Where Pith is reading between the lines
- The same four design choices could be transferred to other evolutionary search methods that currently overfit on small data regimes such as feature selection in genomics.
- If the operator subsets prove too restrictive, one could test whether dynamically adding new operators during migration restores performance without reintroducing bloat.
- The structural deduplication step might reduce memory use in any population-based symbolic search, even outside the island model.
- On real clinical data the recovered formulas could be checked against domain experts to see whether the cross-validation filter preserves scientifically meaningful relationships.
Load-bearing premise
The assumption that any true underlying expression can be expressed using only the four supplied operator subsets and that cross-validation R-squared will reliably discard overfit shortcuts even when the real data-generating process is unknown.
What would settle it
Apply the system to a new small-wide synthetic dataset whose ground-truth expression uses operators outside the four supplied subsets; if the method either fails to reach R-squared above 0.9 or returns bloated expressions that pass cross-validation but fail on fresh test rows, the central claim is falsified.
Figures

read the original abstract
Symbolic regression via genetic programming routinely fails on small, wide datasets - a regime common in clinical-trial monitoring, biostatistics, and engineering pilot studies - by converging on bloated, overfit expressions that exploit correlation rather than prediction. We present Evolutional Math, an open-source genetic programming system that combines four design choices to yield compact, interpretable formulas in this regime. First, fitness is measured by R-squared on held-out cross-validation folds rather than Pearson correlation on the training set, eliminating single-variable shortcuts that correlate but mis-scale. Second, a multi-island architecture runs independent populations seeded with distinct operator subsets (algebraic, logarithmic, trigonometric, and full) with ring-topology migration every M generations, preventing the search from collapsing into one region of formula space. Third, a structural deduplication scheme treats formulas differing only in constants as equivalent, so the elite archive contains structurally distinct candidates rather than near-duplicate variants. Fourth, top-k individuals undergo numerical constant refinement via scipy L-BFGS-B after each migration phase, decoupling structure search from parameter fitting. We evaluate the system on synthetic benchmarks of the form log(x_i) * x_j / (x_k * c), trigonometric mixtures, and an anonymized clinical site-monitoring dataset with 24 rows and approximately 290 candidate numeric features. The system consistently recovers compact ground-truth structures with R-squared at or above 0.99 within tens of thousands of unique formula evaluations. A reference implementation is released under a noncommercial source-available license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Evolutional Math, an island-model genetic programming system for symbolic regression on small, wide datasets. It uses four design choices: R-squared fitness on held-out CV folds (instead of training Pearson correlation), a multi-island architecture with distinct operator subsets (algebraic, logarithmic, trigonometric, full) and ring-topology migration every M generations, structural deduplication treating constant variants as equivalent, and post-migration L-BFGS-B constant refinement. The system is evaluated on synthetic benchmarks matching forms like log(x_i)*x_j/(x_k*c) and trigonometric mixtures, plus an anonymized clinical dataset (n=24 rows, ~290 features), claiming consistent recovery of compact ground-truth structures with R^2 >=0.99 within tens of thousands of unique evaluations. Code is released under a noncommercial source-available license.
Significance. If the central performance claims hold under rigorous validation, the work would offer a targeted approach for interpretable symbolic regression in data-limited regimes common to clinical monitoring and pilot studies. The combination of CV-based fitness to block single-variable shortcuts and island diversity to maintain structural variety directly targets documented GP failure modes on small-n data. The explicit release of a reference implementation strengthens the contribution by enabling direct reproducibility.
major comments (3)
- [Abstract] Abstract / clinical dataset evaluation: the central claim of R^2 >=0.99 on the anonymized clinical dataset (n=24) rests on cross-validated R^2, yet with n=24 the held-out folds are typically 4-5 points; R^2 on such tiny folds has high variance and does not reliably distinguish non-spurious structure from overfit when the true functional form is unknown. No protocol details (number of folds, stratification, or run-to-run variance) are supplied to support this.
- [Abstract] Abstract / evaluation description: no baseline comparisons to standard GP, other symbolic regression tools, or simpler linear models are reported, nor are statistical tests or ablation results isolating the four design choices; without these the claim that the specific combination 'yields compact, interpretable formulas' cannot be assessed.
- [Abstract] Synthetic benchmarks paragraph: the ground-truth expressions are constructed to lie inside the four supplied operator subsets by design; success on these therefore supplies limited evidence that the CV procedure will select non-spurious models on real data whose structure is unknown and may lie outside those subsets.
minor comments (2)
- The term 'Evolutional Math' in the title is nonstandard; 'Evolutionary' would improve immediate clarity.
- [Abstract] The migration interval M is listed as a free parameter but its chosen value and sensitivity are not stated.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We will revise the manuscript to address the concerns regarding evaluation details, baselines, and the scope of the synthetic benchmarks. Our responses to each major comment are provided below.
read point-by-point responses
-
Referee: [Abstract] Abstract / clinical dataset evaluation: the central claim of R^2 >=0.99 on the anonymized clinical dataset (n=24) rests on cross-validated R^2, yet with n=24 the held-out folds are typically 4-5 points; R^2 on such tiny folds has high variance and does not reliably distinguish non-spurious structure from overfit when the true functional form is unknown. No protocol details (number of folds, stratification, or run-to-run variance) are supplied to support this.
Authors: We agree that R² computed on very small held-out sets (4-5 points) can exhibit high variance and may not be sufficient to confirm non-spurious structure. In the revised version, we will expand the methods section to detail the cross-validation protocol, including the use of 5-fold CV, any stratification applied, the number of independent GP runs performed, and the observed variance in R² across runs. Additionally, we will report supplementary metrics such as MAE on the test folds and discuss the inherent limitations of this evaluation setup for small-n data. revision: yes
-
Referee: [Abstract] Abstract / evaluation description: no baseline comparisons to standard GP, other symbolic regression tools, or simpler linear models are reported, nor are statistical tests or ablation results isolating the four design choices; without these the claim that the specific combination 'yields compact, interpretable formulas' cannot be assessed.
Authors: The referee is correct that the current manuscript lacks baseline comparisons and ablations. We will add these in the revision: comparisons against a standard single-population GP using training-set Pearson correlation, against established symbolic regression packages, and against regularized linear regression. We will also include ablation experiments removing each of the four design choices in turn, along with appropriate statistical significance tests (e.g., paired t-tests or Wilcoxon tests) on the recovery rates and final R² values. revision: yes
-
Referee: [Abstract] Synthetic benchmarks paragraph: the ground-truth expressions are constructed to lie inside the four supplied operator subsets by design; success on these therefore supplies limited evidence that the CV procedure will select non-spurious models on real data whose structure is unknown and may lie outside those subsets.
Authors: This is a valid observation. The synthetic benchmarks were designed to verify that the system can recover expressions when they are representable within the island operator sets. To address the concern, the revised manuscript will include a new subsection discussing this limitation and will present additional synthetic experiments where ground-truth expressions incorporate operators or combinations outside the predefined subsets. This will provide a more stringent test of whether the CV-based fitness can still identify compact, predictive models. revision: partial
Circularity Check
No circularity: empirical method description with no derivation chain
full rationale
The paper presents a genetic programming system defined by four explicit design choices (CV-based R^2 fitness, multi-island operator subsets with migration, structural deduplication, and post-migration constant refinement) and reports empirical recovery rates on synthetic benchmarks (where ground truth is constructed inside the allowed operators) plus one clinical dataset. No mathematical derivation, uniqueness theorem, or first-principles result is claimed. No parameter is fitted to a subset and then relabeled as a prediction. No self-citations appear in the supplied text. The evaluation is a direct performance measurement of the described system rather than a reduction of any claimed result to its own inputs. This matches the default case of a self-contained empirical method paper.
Axiom & Free-Parameter Ledger
free parameters (1)
- migration interval M
axioms (2)
- domain assumption R-squared on held-out cross-validation folds is a superior fitness measure to Pearson correlation on the training set for avoiding mis-scaled single-variable shortcuts
- domain assumption Distinct operator-subset islands plus ring migration prevent search collapse into one region of formula space
Reference graph
Works this paper leans on
-
[1]
J. R. Koza,Genetic Programming: On the Programming of Computers by Means of Natural Selection. MIT Press, 1992
1992
-
[2]
Distilling free-form natural laws from experimental data,
M. Schmidt and H. Lipson, “Distilling free-form natural laws from experimental data,” Science, vol. 324, no. 5923, pp. 81–85, 2009
2009
-
[3]
Interpretable Machine Learning for Science with PySR and SymbolicRegression.jl
M. Cranmer, “Interpretable machine learning for science with PySR and Symboli- cRegression.jl,” arXiv preprint arXiv:2305.01582, 2023. Software available at https: //github.com/MilesCranmer/PySR
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
AI Feynman: a physics-inspired method for symbolic regression,
S.-M. Udrescu and M. Tegmark, “AI Feynman: a physics-inspired method for symbolic regression,”Science Advances, vol. 6, no. 16, eaay2631, 2020
2020
-
[5]
Deep symbolic regression: recovering mathematical expressions from data via risk-seeking policy gradients,
B. K. Petersen, M. L. Larma, T. N. Mundhenk, C. P. Santiago, S. K. Kim, and J. T. Kim, “Deep symbolic regression: recovering mathematical expressions from data via risk-seeking policy gradients,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[6]
End-to-end symbolic regression with transformers,
P.-A. Kamienny, S. d’Ascoli, G. Lample, and F. Charton, “End-to-end symbolic regression with transformers,”Advances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[7]
R. Poli, W. B. Langdon, and N. F. McPhee,A Field Guide to Genetic Programming. Lulu Press, 2008.http://www.gp-field-guide.org.uk/
2008
-
[8]
Parallel genetic programming on a network of transputers,
D. Andre and J. R. Koza, “Parallel genetic programming on a network of transputers,” in Proc. Workshop on Genetic Programming, 1996
1996
-
[9]
Tomassini,Spatially Structured Evolutionary Algorithms
M. Tomassini,Spatially Structured Evolutionary Algorithms. Springer, 2005. 11
2005
-
[10]
Evolution in Mendelian populations,
S. Wright, “Evolution in Mendelian populations,”Genetics, vol. 16, no. 2, pp. 97–159, 1931
1931
-
[11]
Faster genetic programming based on local gradient search of numeric leaf values,
A. Topchy and W. F. Punch, “Faster genetic programming based on local gradient search of numeric leaf values,” inProc. GECCO, 2001, pp. 155–162
2001
-
[12]
Parameter identification for symbolic regression using nonlinear least squares,
M. Kommenda, B. Burlacu, G. Kronberger, and M. Affenzeller, “Parameter identification for symbolic regression using nonlinear least squares,”Genetic Programming and Evolvable Machines, vol. 21, no. 3, pp. 471–501, 2020
2020
-
[13]
A limited memory algorithm for bound constrained optimization,
R. H. Byrd, P. Lu, J. Nocedal, and C. Zhu, “A limited memory algorithm for bound constrained optimization,”SIAM J. Sci. Comput., vol. 16, no. 5, pp. 1190–1208, 1995
1995
-
[14]
Exhaustive symbolic regression,
D. J. Bartlett, H. Desmond, and P. G. Ferreira, “Exhaustive symbolic regression,” arXiv preprint arXiv:2109.13895, 2021
-
[15]
Symbolic regression,
Wikipedia, “Symbolic regression,” https://en.wikipedia.org/wiki/Symbolic_ regression
-
[16]
System and method for auto-query generation,
M. Schmidt et al., “System and method for auto-query generation,” U.S. Patent 10,102,483,
-
[17]
Assignee: DataRobot, Inc
-
[18]
System and method for auto-query generation,
M. Schmidt et al., “System and method for auto-query generation,” U.S. Patent 9,524,473,
-
[19]
Assignee: Nutonian, Inc
-
[20]
Experimental design for symbolic model discovery,
L. Horesh, K. L. Clarkson, C. Cornelio, and S. Magliacane, “Experimental design for symbolic model discovery,” U.S. Patent 11,657,194, 2023. Assignee: International Business Machines Corp
2023
-
[21]
Sequential residual symbolic regression,
“Sequential residual symbolic regression,” U.S. Patent Application 20250085454, 2024 (pending). Assignee: Halliburton Energy Services, Inc
2024
-
[22]
Genetic programming problem solver with automatically defined stores, loops and recursions,
J. R. Koza, “Genetic programming problem solver with automatically defined stores, loops and recursions,” U.S. Patent 6,532,453, 2003
2003
-
[23]
Method and apparatus for automated design of complex structures using genetic programming,
J. R. Koza, “Method and apparatus for automated design of complex structures using genetic programming,” U.S. Patent 6,360,191, 2002
2002
-
[24]
Method and system for genetic programming,
J. R. Koza, “Method and system for genetic programming,” WIPO Publica- tion WO1997032261, 1997. 12
1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.