Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
Pith reviewed 2026-06-30 09:50 UTC · model grok-4.3
The pith
Transition-aware best-of-N sampling improves longitudinal chest X-ray reports by scoring candidates against real exam-to-exam changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
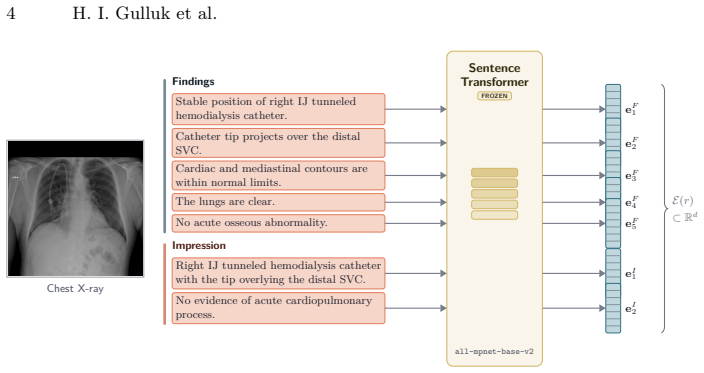
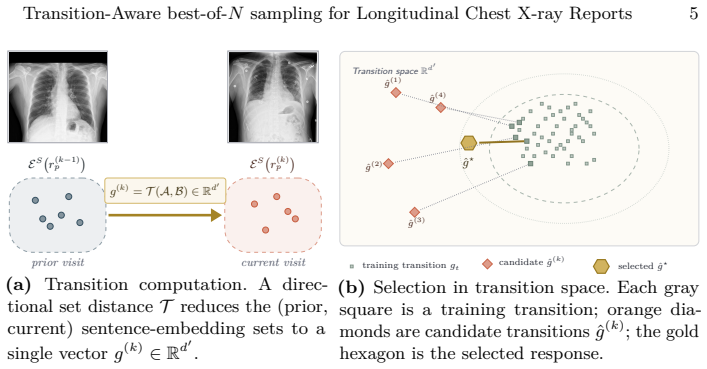
The authors claim to present the first training-free best-of-N sampling scheme for pre-trained chest X-ray report generators that is explicitly aware of the longitudinal prior-to-current transition. Each report is split into sentences and embedded as an unordered set; each pair is reduced to a fixed-dimensional directional vector via a set-to-set distance; candidates are then scored by cosine distance from their transition vector to a bank of ground-truth training transitions, aggregated as min or kNN. Four directional distances are instantiated and the approach is shown to outperform random selection, especially on the Impression section.
What carries the argument
Transition-aware best-of-N sampling, which reduces each (prior, current) report pair to a directional transition vector via set-to-set distances (mean-shift, novelty residual, directed-Hausdorff anchor, cost-weighted optimal transport) and scores candidates by cosine similarity to cached ground-truth transitions.
If this is right
- The same sampling procedure can be applied to any pre-trained vision-language report generator without retraining or fine-tuning.
- Gains are largest on the Impression section, which is the part of the report that most directly communicates change.
- Performance holds across multiple prompt styles and generator architectures on a multi-visit AP-PA cohort.
- The method requires only a cached bank of ground-truth transition vectors from the training set.
Where Pith is reading between the lines
- The approach could be extended to other longitudinal medical imaging tasks such as CT or MRI follow-up reports where change detection matters.
- If the embedding model used for sentence sets is swapped for a domain-specific clinical encoder, the transition vectors might capture finer medical distinctions.
- Combining this sampling with temperature tuning or beam search inside the generator could produce further gains without additional training.
Load-bearing premise
The chosen set-to-set distances and cosine scoring against cached ground-truth transitions will reliably identify reports that are clinically superior rather than merely similar in embedding space.
What would settle it
A reader study in which radiologists directly compare transition-aware best-of-N reports against random best-of-N reports on the same images and rate whether the selected report better describes the clinically relevant change from the prior exam.
Figures
read the original abstract
In longitudinal clinical practice, every chest X-ray is read in the context of the patients prior exam, and much of what the radiologist communicates is the change from one visit to the next. To the best of our knowledge, we present the first training-free best-of-N sampling scheme for pre-trained chest X-ray report generators that is explicitly aware of this longitudinal prior to current transition. We call it transition-aware best-of-N sampling, each report is split into sentences and embedded into an unordered set in Rd; each (prior, current) pair is reduced to a fixed-dim directional vector via a set-to-set distance designed to encode the change between the two sets; and candidates are scored by cosine distance from their candidate transition vector to a cached bank of ground-truth training transition vectors, aggregated as min or kNN. We instantiate the framework with four directional set distances (mean-shift, novelty residual, directed-Hausdorff anchor, and cost-weighted optimal transport) and evaluate on a multi-visit AP-PA cohort, running inference under three prompts on three vision-language generators. Transition-aware best-of-N outperforms random selection across the board, with the largest relative gains on the Impression section.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the first training-free best-of-N sampling scheme for pre-trained chest X-ray report generators that incorporates longitudinal transition awareness. Reports are split into sentence sets, reduced to directional transition vectors via one of four set-to-set distances (mean-shift, novelty residual, directed-Hausdorff, cost-weighted OT), and ranked by cosine similarity (min or kNN) to a cached bank of ground-truth training transitions. It evaluates the approach on a multi-visit AP-PA cohort using three prompts on three vision-language models and claims consistent outperformance over random selection, with largest relative gains on the Impression section.
Significance. If the empirical gains hold and the embedding-based scoring selects reports that are clinically superior (rather than merely typical in embedding space), the work would be a useful contribution by providing a simple, training-free way to inject longitudinal priors into existing report generators without retraining.
major comments (2)
- [Abstract] Abstract: the claim that transition-aware best-of-N 'outperforms random selection across the board' is presented without any quantitative results, error bars, ablation details, or metric definitions, so the magnitude and reliability of the reported gains cannot be assessed.
- [Evaluation] Evaluation description: the only baseline is random selection; without comparisons to standard best-of-N, other sampling strategies, or human/radiologist preference scores, it remains unclear whether the cosine-to-ground-truth scoring improves factual accuracy or completeness rather than simply recovering more typical transition patterns in the VLM embedding space.
minor comments (1)
- [Method] The four set-to-set distances are introduced without a clear statement of their computational complexity or any hyper-parameters that must be chosen when instantiating them.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and evaluation. We address each point below and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that transition-aware best-of-N 'outperforms random selection across the board' is presented without any quantitative results, error bars, ablation details, or metric definitions, so the magnitude and reliability of the reported gains cannot be assessed.
Authors: We agree that the abstract would benefit from quantitative context. In the revised manuscript we will add concise statements of the observed relative gains (including the largest gains on the Impression section) and the evaluation setup (three prompts, three VLMs, multi-visit cohort) while respecting length limits. Full error bars, ablation tables, and metric definitions remain in the experimental section. revision: yes
-
Referee: [Evaluation] Evaluation description: the only baseline is random selection; without comparisons to standard best-of-N, other sampling strategies, or human/radiologist preference scores, it remains unclear whether the cosine-to-ground-truth scoring improves factual accuracy or completeness rather than simply recovering more typical transition patterns in the VLM embedding space.
Authors: The manuscript positions random selection as the direct baseline precisely to isolate the effect of the transition-aware scoring function. Because the contribution is the directional transition vector itself, a "standard" best-of-N baseline would require an alternative non-transition scoring rule that is outside the scope of the work. The method selects candidates whose transition vectors are closest to observed ground-truth transitions from the training distribution; we therefore do not claim direct gains in factual accuracy or completeness beyond recovering clinically attested longitudinal patterns. Human preference studies are valuable but require a separate clinical evaluation and are noted as future work. revision: no
Circularity Check
No significant circularity; method uses external cached ground-truth as reference
full rationale
The described framework computes transition vectors from set-to-set distances on sentence embeddings and ranks via cosine similarity to a bank of training-set ground-truth transitions. This is a retrieval-style heuristic against independent data, not a self-referential derivation or fitted parameter renamed as prediction. No equations reduce to their inputs by construction, no uniqueness theorems are imported from self-citations, and no ansatz is smuggled via prior work. The evaluation against random selection provides an external benchmark. The paper's central claim (first training-free longitudinal-aware best-of-N) rests on the empirical performance of this external-reference scheme rather than on any definitional loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization
Banerjee, S., Lavie, A.: Meteor: An automatic metric for mt evaluation with improved correlation with human judgments. In: Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. pp. 65–72 (2005)
2005
-
[2]
Maira-2: Grounded radiology report generation
Bannur, S., Bouzid, K., Castro, D.C., Schwaighofer, A., Thieme, A., Bond-Taylor, S., Ilse, M., Pérez-García, F., Salvatelli, V., Sharma, H., et al.: Maira-2: Grounded radiology report generation, 2024. URL https://arxiv. org/abs/2406.04449
-
[3]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Bannur,S.,Hyland,S.,Liu,Q.,Perez-Garcia,F.,Ilse,M.,Castro,D.C.,Boecking,B., Sharma,H.,Bouzid,K.,Thieme,A.,etal.:Learningtoexploittemporalstructurefor biomedical vision-language processing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 15016–15027 (2023)
2023
-
[4]
In: AAAI 2024 Spring Symposium on Clinical Foundation Models (2024)
Chen, Z., Varma, M., Delbrouck, J.B., Paschali, M., Blankemeier, L., Van Veen, D., Valanarasu, J.M.J., Youssef, A., Cohen, J.P., Reis, E.P., et al.: Chexagent: Towards a foundation model for chest x-ray interpretation. In: AAAI 2024 Spring Symposium on Clinical Foundation Models (2024)
2024
-
[5]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
In: Findings of the Association for Computational Linguistics: EMNLP
Delbrouck, J.B., Chambon, P., Bluethgen, C., Tsai, E., Almusa, O., Langlotz, C.: Improving the factual correctness of radiology report generation with semantic rewards. In: Findings of the Association for Computational Linguistics: EMNLP
-
[7]
4348–4360 (2022)
pp. 4348–4360 (2022)
2022
-
[8]
In: Machine learning for health
Endo, M., Krishnan, R., Krishna, V., Ng, A.Y., Rajpurkar, P.: Retrieval-based chest x-ray report generation using a pre-trained contrastive language-image model. In: Machine learning for health. pp. 209–219. PMLR (2021)
2021
-
[9]
SDR: Set-Distance Rewards for Radiology Report Generation
Gulluk, H.I., Van Puyvelde, M., Van Criekinge, W., Gevaert, O.: Sdr: Set-distance rewards for radiology report generation. arXiv preprint arXiv:2606.00440 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Naval research logistics quarterly2(1-2), 83–97 (1955)
Kuhn, H.W.: The hungarian method for the assignment problem. Naval research logistics quarterly2(1-2), 83–97 (1955)
1955
-
[11]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, M., Lin, B., Chen, Z., Lin, H., Liang, X., Chang, X.: Dynamic graph en- hanced contrastive learning for chest x-ray report generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3334–3343 (2023)
2023
-
[12]
In: International Conference on Learning Representations
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., Cobbe, K.: Let’s verify step by step. In: International Conference on Learning Representations. vol. 2024, pp. 39578–39601 (2024)
2024
-
[13]
In: Text summarization branches out
Lin, C.Y.: Rouge: A package for automatic evaluation of summaries. In: Text summarization branches out. pp. 74–81 (2004)
2004
-
[14]
Liu, G., Hsu, T., McDermott, M., Boag, W., Weng, W., Szolovits, P., Ghas- semi, M.: Clinically accurate chest x-ray report generation. corr. arXiv preprint arXiv:1904.02633 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[15]
Informatics in Medicine Unlocked50, 101585 (2024)
Nicolson, A., Dowling, J., Anderson, D., Koopman, B.: Longitudinal data and a semantic similarity reward for chest x-ray report generation. Informatics in Medicine Unlocked50, 101585 (2024)
2024
-
[16]
In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics
Papineni, K., Roukos, S., Ward, T., Zhu, W.J.: Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th annual meeting of the Association for Computational Linguistics. pp. 311–318 (2002)
2002
-
[17]
WMT (2017) 10 H
Popović, M.: chrF++: words helping character n-grams. WMT (2017) 10 H. I. Gulluk et al
2017
-
[18]
In: Proceedings of the Seventh Conference on Machine Translation (WMT)
Rei, R., De Souza, J.G., Alves, D., Zerva, C., Farinha, A.C., Glushkova, T., Lavie, A., Coheur, L., Martins, A.F.: Comet-22: Unbabel-ist 2022 submission for the metrics shared task. In: Proceedings of the Seventh Conference on Machine Translation (WMT). pp. 578–585 (2022)
2022
-
[19]
In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP)
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP). pp. 3982–3992 (2019)
2019
-
[20]
In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP)
Smit, A., Jain, S., Rajpurkar, P., Pareek, A., Ng, A.Y., Lungren, M.: Combining automatic labelers and expert annotations for accurate radiology report labeling using bert. In: Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). pp. 1500–1519 (2020)
2020
-
[21]
Villani, C., et al.: Optimal transport: old and new, vol. 338. Springer (2009)
2009
-
[22]
Meta-Radiology1(3), 100033 (2023)
Wang, Z., Liu, L., Wang, L., Zhou, L.: R2gengpt: Radiology report generation with frozen llms. Meta-Radiology1(3), 100033 (2023)
2023
-
[23]
BERTScore: Evaluating Text Generation with BERT
Zhang, T., Kishore, V., Wu, F., Weinberger, K.Q., Artzi, Y.: Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[24]
Zhang, X., Acosta, J.N., Miller, J., Huang, O., Rajpurkar, P.: Rexgradient-160k: A large-scale publicly available dataset of chest radiographs with free-text reports. arXiv preprint arXiv:2505.00228 (2025) Transition-Aware best-of-Nsampling for Longitudinal Chest X-ray Reports 11 A Prompts We reproduce verbatim the three prompts used in the experiments. T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.