Enhancing Layer Interaction Using Key-Correlated Layer Attention
Pith reviewed 2026-06-30 01:07 UTC · model grok-4.3
The pith
Key-Correlated Layer Attention reduces cross-layer interaction to linear complexity while retaining dynamic updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
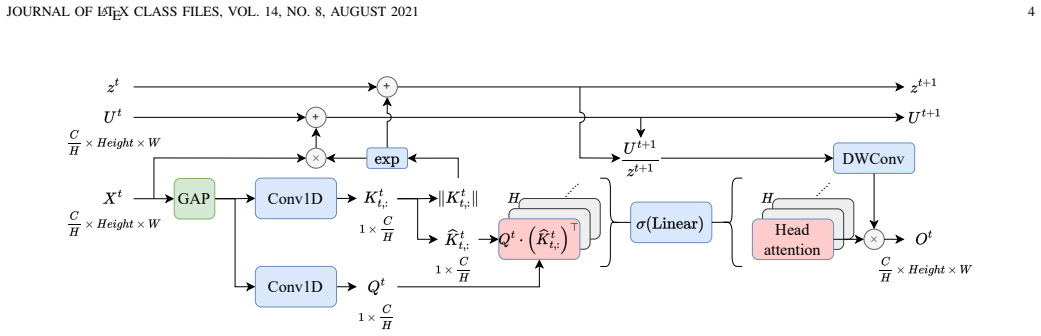
KCLA is obtained by replacing the full key-query interaction in layer attention with a correlated-key form, yielding linear time complexity, preserved dynamic updates, maintained long-range dependencies, and constant spatial cost independent of network depth.
What carries the argument
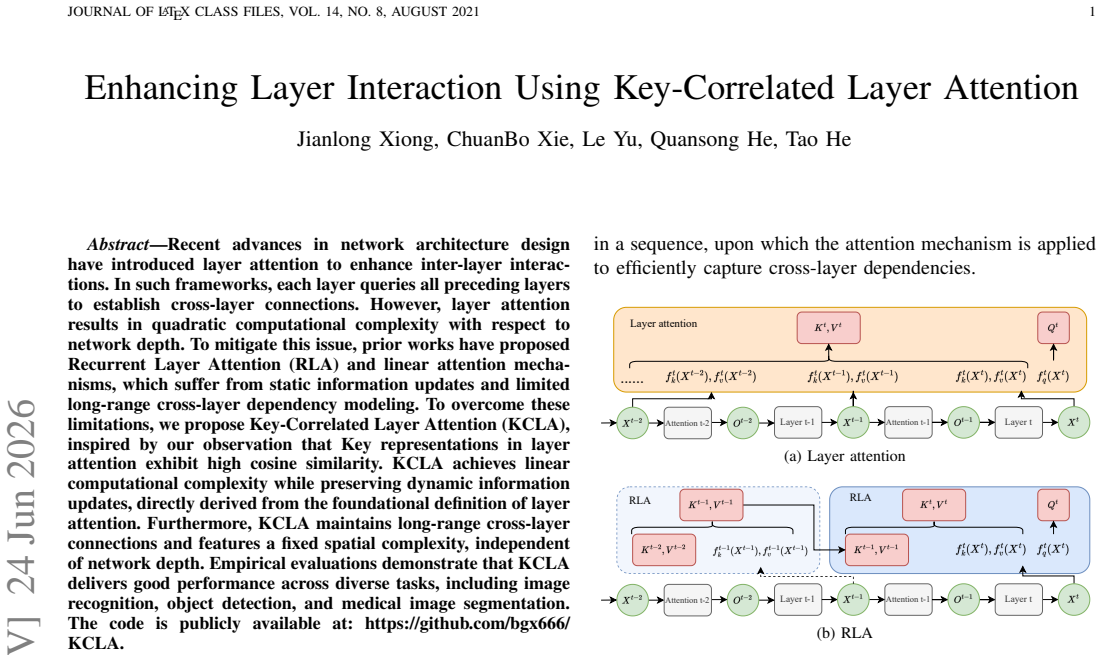
Key-Correlated Layer Attention (KCLA), which exploits high cosine similarity among key representations to linearize the attention computation while following the original layer attention definition.
If this is right
- Deeper networks can add cross-layer connections without quadratic runtime increase.
- Dynamic information flow between layers remains possible at linear cost.
- Spatial memory usage does not grow with added layers.
- The same mechanism supports image recognition, object detection, and medical segmentation without task-specific redesign.
Where Pith is reading between the lines
- The linear form might transfer to transformer-style models where key similarity also appears.
- A direct test on networks deeper than those in the paper would confirm the claimed depth-independent spatial cost.
- If the similarity property holds in non-vision domains, the same derivation could apply to sequence models.
Load-bearing premise
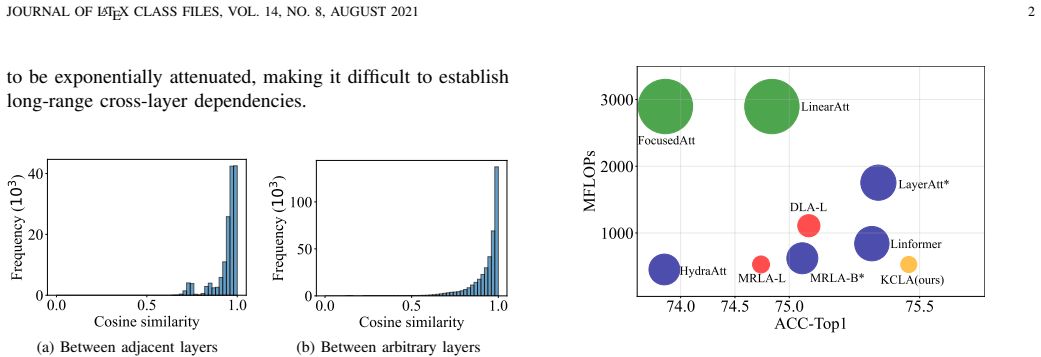
Key representations across layers exhibit high cosine similarity.
What would settle it
Train a network, measure actual cosine similarity of its keys, and test whether KCLA performance collapses relative to full layer attention when similarity falls below the assumed high level.
Figures
read the original abstract
Recent advances in network architecture design have introduced layer attention to enhance inter-layer interactions. In such frameworks, each layer queries all preceding layers to establish cross-layer connections. However, layer attention results in quadratic computational complexity with respect to network depth. To mitigate this issue, prior works have proposed Recurrent Layer Attention (RLA) and linear attention mechanisms, which suffer from static information updates and limited long-range cross-layer dependency modeling. To overcome these limitations, we propose Key-Correlated Layer Attention (KCLA), inspired by our observation that Key representations in layer attention exhibit high cosine similarity. KCLA achieves linear computational complexity while preserving dynamic information updates, directly derived from the foundational definition of layer attention. Furthermore, KCLA maintains long-range cross-layer connections and features a fixed spatial complexity, independent of network depth. Empirical evaluations demonstrate that KCLA delivers good performance across diverse tasks, including image recognition, object detection, and medical image segmentation. The code is publicly available at https://github.com/bgx666/KCLA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Key-Correlated Layer Attention (KCLA) to address the quadratic complexity of standard layer attention in deep networks. Based on the observation that key representations exhibit high cosine similarity across layers, the authors derive KCLA which achieves linear computational complexity, preserves dynamic information updates, maintains long-range cross-layer connections, and has fixed spatial complexity independent of depth. The method is evaluated on image recognition, object detection, and medical image segmentation tasks, with code made publicly available.
Significance. If the central derivation holds and the similarity assumption is robust, KCLA could offer an efficient alternative for modeling inter-layer dependencies without the drawbacks of recurrent or standard linear attentions. The public code availability is a positive for reproducibility. However, the significance depends on validating the load-bearing assumption about key similarity.
major comments (1)
- Abstract: The claim that KCLA is 'directly derived from the foundational definition of layer attention' and achieves linear complexity while preserving dynamic updates hinges on the high cosine similarity of keys. The abstract presents this similarity as an empirical observation without providing quantitative analysis, bounds, or proof that it holds independently of network depth or task, which is necessary to confirm the derivation is exact rather than approximate.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on the abstract. We agree that the key similarity assumption requires stronger empirical support in the manuscript to substantiate the derivation claims. Below we address the major comment point by point.
read point-by-point responses
-
Referee: Abstract: The claim that KCLA is 'directly derived from the foundational definition of layer attention' and achieves linear complexity while preserving dynamic updates hinges on the high cosine similarity of keys. The abstract presents this similarity as an empirical observation without providing quantitative analysis, bounds, or proof that it holds independently of network depth or task, which is necessary to confirm the derivation is exact rather than approximate.
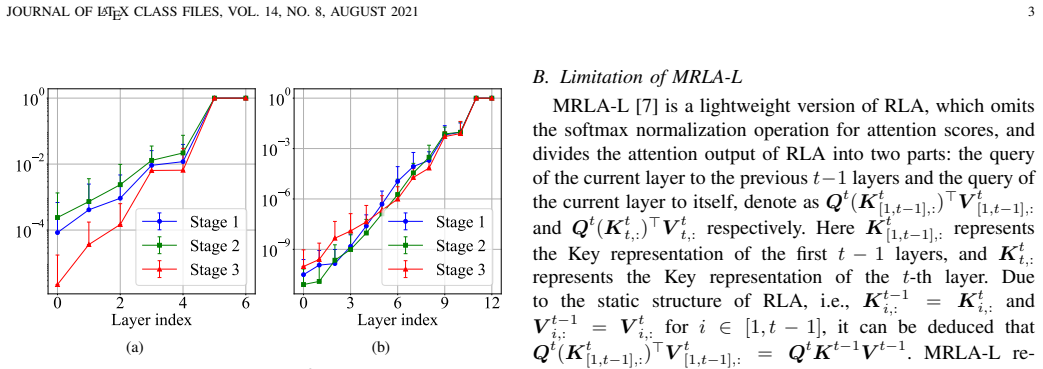
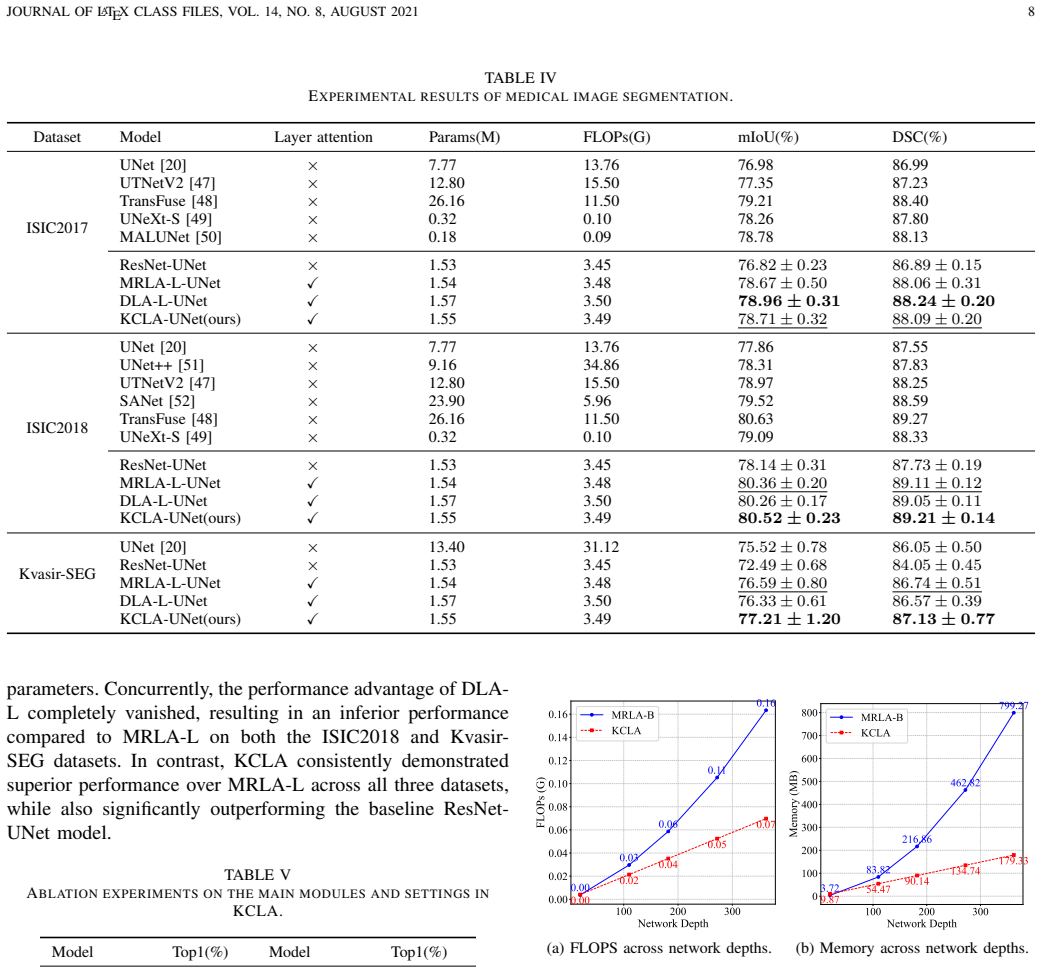
Authors: We agree that the abstract would benefit from quantitative support for the key cosine similarity observation. In the revised version, we will add a new figure and table in Section 3 (or a dedicated subsection) reporting average cosine similarities between keys across consecutive layers, computed on ImageNet, COCO, and medical segmentation datasets for networks of varying depths (e.g., 12 to 50 layers). This will include mean, std, and min/max values to demonstrate robustness. The derivation itself remains exact under the modeling choice of replacing the full key matrix with its highly correlated approximation; the similarity is the enabling empirical condition rather than an approximation in the math. We cannot supply theoretical bounds or a proof of similarity holding for arbitrary depth/task, as this is an observed property of trained transformers rather than a universal guarantee. revision: partial
- A mathematical proof or theoretical bounds that would guarantee high key cosine similarity independently of network depth or task.
Circularity Check
No significant circularity; derivation presented as independent of empirical observation
full rationale
The paper states that KCLA 'achieves linear computational complexity while preserving dynamic information updates, directly derived from the foundational definition of layer attention' after noting an empirical observation of high key cosine similarity as inspiration. No equations or steps are shown that reduce the linear form to the similarity observation by construction, nor are there self-citations, fitted inputs renamed as predictions, or uniqueness theorems invoked. The central claim is framed as following from the layer attention definition itself, rendering the derivation self-contained against external benchmarks with no load-bearing reduction to inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Key representations in layer attention exhibit high cosine similarity.
invented entities (1)
-
Key-Correlated Layer Attention (KCLA)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural informa- tion processing systems, 2017
2017
-
[2]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in2016 IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR), 2016
2016
-
[3]
Densely connected convolutional networks,
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Wein- berger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017
2017
-
[4]
On a sparse shortcut topology of artificial neural networks,
F.-L. Fan, D. Wang, H. Guo, Q. Zhu, P. Yan, G. Wang, and H. Yu, “On a sparse shortcut topology of artificial neural networks,”IEEE Transactions on Artificial Intel- ligence, 2021
2021
-
[5]
G. Xu, X. Wang, X. Wu, X. Leng, and Y . Xu, “Devel- opment of skip connection in deep neural networks for computer vision and medical image analysis: A survey,” arXiv preprint arXiv:2405.01725, 2024
-
[6]
Recurrence along depth: Deep convolutional neural networks with recur- rent layer aggregation,
J. Zhao, Y . Fang, and G. Li, “Recurrence along depth: Deep convolutional neural networks with recur- rent layer aggregation,” inAdvances in Neural Informa- tion Processing Systems, M. Ranzato, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds. Curran Associates, Inc., 2021
2021
-
[7]
Cross-layer retrospective retrieving via layer attention,
Y . Fang, Y . Cai, J. Chen, J. Zhao, G. Tian, and G. Li, “Cross-layer retrospective retrieving via layer attention,” 2023
2023
-
[8]
Strengthening layer interaction via dynamic layer attention,
K. Wang, X. Xia, J. Liu, Z. Yi, and T. He, “Strengthening layer interaction via dynamic layer attention,”arXiv preprint arXiv:2406.13392, 2024
-
[9]
Linformer: Self-Attention with Linear Complexity
S. Wang, B. Z. Li, M. Khabsa, H. Fang, and H. Ma, “Linformer: Self-attention with linear complexity,”arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[10]
Hydra attention: Efficient attention with many heads,
D. Bolya, C.-Y . Fu, X. Dai, P. Zhang, and J. Hoffman, “Hydra attention: Efficient attention with many heads,” inEuropean Conference on Computer Vision. Springer, 2022
2022
-
[11]
Transformer-vq: Linear-time transformers via vector quantization,
L. D. Lingle, “Transformer-vq: Linear-time transformers via vector quantization,”arXiv preprint arXiv:2309.16354, 2023
-
[12]
Gated linear attention transformers with hardware- efficient training,
S. Yang, B. Wang, Y . Shen, R. Panda, and Y . Kim, “Gated linear attention transformers with hardware- efficient training,” 2024
2024
-
[13]
A bidirectional feedforward neural network architecture using the discretized neural memory ordinary differential equation,
H. Niu, Z. Yi, and T. He, “A bidirectional feedforward neural network architecture using the discretized neural memory ordinary differential equation,”International Journal of Neural Systems, vol. 34, no. 04, p. 2450015, 2024
2024
-
[14]
Cnm-unet: Continuous ordinary differential equations for medical image segmentation,
T. Xu, Y . Zhu, Q. He, Y . Cao, K. Wang, Z. Yi, and T. He, “Cnm-unet: Continuous ordinary differential equations for medical image segmentation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 14, 2026, pp. 11 406–11 414
2026
-
[15]
Mobileode: An extra lightweight network,
L. Yu, J. Wu, B. Gou, X. Min, L. Zhang, Z. Yi, and T. He, “Mobileode: An extra lightweight network,”Advances in Neural Information Processing Systems, vol. 38, pp. 120 931–120 956, 2026
2026
-
[16]
A lightweight u-like network utilizing neural memory ordinary differen- tial equations for slimming the decoder,
Q. He, X. Yao, J. Wu, Z. Yi, and T. He, “A lightweight u-like network utilizing neural memory ordinary differen- tial equations for slimming the decoder,” inProceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 2024, pp. 821–829
2024
-
[17]
En- hancing feature fusion of u-like networks with dynamic skip connections,
Y . Cao, Q. He, K. Wang, J. Xiong, Z. Yi, and T. He, “En- hancing feature fusion of u-like networks with dynamic skip connections,”Medical Image Analysis, p. 104010, 2026. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
2026
-
[18]
Subtraction gates: Another way to learn long-term dependencies in recurrent neural networks,
T. He, H. Mao, and Z. Yi, “Subtraction gates: Another way to learn long-term dependencies in recurrent neural networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 4, pp. 1740–1751, 2020
2020
-
[19]
Cascade-refine model for cephalometric land- mark detection in high-resolution orthodontic images,
T. He, J. Guo, W. Tang, W. Zeng, P. He, F. Zeng, and Z. Yi, “Cascade-refine model for cephalometric land- mark detection in high-resolution orthodontic images,” Knowledge-Based Systems, vol. 265, p. 110332, 2023
2023
-
[20]
U-net: Convo- lutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convo- lutional networks for biomedical image segmentation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention, 2015
2015
-
[21]
Why is everyone training very deep neural network with skip connections?
O. Oyedotun, K. Al Ismaeil, and D. Aouada, “Why is everyone training very deep neural network with skip connections?”IEEE Transactions on Neural Networks and Learning Systems, 2021
2021
-
[22]
Dianet: Dense-and-implicit attention network,
Z. Huang, S. Liang, M. Liang, and H. Yang, “Dianet: Dense-and-implicit attention network,” 2019
2019
-
[23]
Strengthening layer interaction via global-layer attention network for image classification,
J. You and K. Tang, “Strengthening layer interaction via global-layer attention network for image classification,” in2024 9th International Conference on Intelligent Com- puting and Signal Processing (ICSP), 2024
2024
-
[24]
From layers to states: A state space model perspective to deep neural network layer dynamics,
Q. Liu, W. Zhao, W. Huang, Y . Fang, L. Yu, and G. Li, “From layers to states: A state space model perspective to deep neural network layer dynamics,”arXiv preprint arXiv:2502.10463, 2025
-
[25]
Residual Connections Harm Generative Representation Learning
X. Zhang, R. Jiang, W. Gao, R. Willett, and M. Maire, “Residual connections harm generative representation learning,”arXiv preprint arXiv:2404.10947, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Mud- dformer: Breaking residual bottlenecks in transformers via multiway dynamic dense connections,
D. Xiao, Q. Meng, S. Li, and X. Yuan, “Mud- dformer: Breaking residual bottlenecks in transformers via multiway dynamic dense connections,”arXiv preprint arXiv:2502.12170, 2025
-
[27]
Enhancing Layer Attention Efficiency through Pruning Redundant Retrievals
H. Li and X. Huang, “Enhancing layer attention ef- ficiency through pruning redundant retrievals,”arXiv preprint arXiv:2503.06473, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Transformers are rnns: Fast autoregressive transformers with linear attention,
A. Katharopoulos, A. Vyas, N. Pappas, and F. Fleuret, “Transformers are rnns: Fast autoregressive transformers with linear attention,” 2020
2020
-
[29]
Flatten transformer: Vision transformer using focused linear at- tention,
D. Han, X. Pan, Y . Han, S. Song, and G. Huang, “Flatten transformer: Vision transformer using focused linear at- tention,” inProceedings of the IEEE/CVF international conference on computer vision, 2023
2023
-
[30]
Reformer: The Efficient Transformer
N. Kitaev, Ł. Kaiser, and A. Levskaya, “Reformer: The efficient transformer,”arXiv preprint arXiv:2001.04451, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[31]
Attention temperature matters in vit-based cross-domain few-shot learning,
Y . Zou, R. Ma, Y . Li, and R. Li, “Attention temperature matters in vit-based cross-domain few-shot learning,” inAdvances in Neural Information Processing Systems. Curran Associates, Inc., 2024
2024
-
[32]
Mitigating hallucinations in diffusion models through adaptive at- tention modulation,
T. Oorloff, Y . Yacoob, and A. Shrivastava, “Mitigating hallucinations in diffusion models through adaptive at- tention modulation,”arXiv preprint arXiv:2502.16872, 2025
-
[33]
Random search for hyper- parameter optimization,
J. Bergstra and Y . Bengio, “Random search for hyper- parameter optimization,”The journal of machine learn- ing research, 2012
2012
-
[34]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009
2009
-
[35]
Learning multiple layers of features from tiny images,
A. Krizhevsky, “Learning multiple layers of features from tiny images,” 2009
2009
-
[36]
Squeeze- and-excitation networks,
J. Hu, L. Shen, S. Albanie, G. Sun, and E. Wu, “Squeeze- and-excitation networks,” 2019
2019
-
[37]
Eca- net: Efficient channel attention for deep convolutional neural networks,
Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, and Q. Hu, “Eca- net: Efficient channel attention for deep convolutional neural networks,” 2020
2020
-
[38]
Ba-net: Bridge attention for deep convolutional neural networks,
Y . Zhao, J. Chen, Z. Zhang, and R. Zhang, “Ba-net: Bridge attention for deep convolutional neural networks,” inComputer Vision – ECCV 2022. Springer Nature Switzerland, 2022
2022
-
[39]
Non- local neural networks,
X. Wang, R. Girshick, A. Gupta, and K. He, “Non- local neural networks,” in2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
2018
-
[40]
Gcnet: Non- local networks meet squeeze-excitation networks and beyond,
Y . Cao, J. Xu, S. Lin, F. Wei, and H. Hu, “Gcnet: Non- local networks meet squeeze-excitation networks and beyond,” inProceedings of the IEEE/CVF international conference on computer vision workshops, 2019
2019
-
[41]
Cbam: Convolutional block attention module,
S. Woo, J. Park, J.-Y . Lee, and I. S. Kweon, “Cbam: Convolutional block attention module,” 2018
2018
-
[42]
Attention augmented convolutional networks,
I. Bello, B. Zoph, Q. Le, A. Vaswani, and J. Shlens, “Attention augmented convolutional networks,” in2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019
2019
-
[43]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inComputer vision– ECCV 2014. Springer, 2014
2014
-
[44]
MMDetection: Open MMLab Detection Toolbox and Benchmark
K. Chen, J. Wang, J. Pang, Y . Cao, Y . Xiong, X. Li, S. Sun, W. Feng, Z. Liu, J. Xuet al., “Mmdetection: Open mmlab detection toolbox and benchmark,”arXiv preprint arXiv:1906.07155, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[45]
Faster r-cnn: Towards real-time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real-time object detection with region proposal networks,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017
2017
-
[46]
Mask r-cnn,
K. He, G. Gkioxari, P. Doll ´ar, and R. Girshick, “Mask r-cnn,” inProceedings of the IEEE international confer- ence on computer vision, 2017
2017
-
[47]
A multi-scale transformer for medical image segmentation: Architectures, model efficiency, and benchmarks,
Y . Gao, M. Zhou, D. Liu, and D. N. Metaxas, “A multi-scale transformer for medical image segmentation: Architectures, model efficiency, and benchmarks,”ArXiv, 2022
2022
-
[48]
Transfuse: Fusing trans- formers and cnns for medical image segmentation,
Y . Zhang, H. Liu, and Q. Hu, “Transfuse: Fusing trans- formers and cnns for medical image segmentation,” in Medical image computing and computer assisted inter- vention. Springer, 2021
2021
-
[49]
Unext: Mlp- based rapid medical image segmentation network,
J. M. J. Valanarasu and V . M. Patel, “Unext: Mlp- based rapid medical image segmentation network,” in International conference on medical image computing and computer-assisted intervention. Springer, 2022
2022
-
[50]
Malunet: A multi-attention and light-weight unet for skin lesion segmentation,
J. Ruan, S. Xiang, M. Xie, T. Liu, and Y . Fu, “Malunet: A multi-attention and light-weight unet for skin lesion segmentation,” in2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12 2022
2021
-
[51]
Unet++: A nested u-net architecture for med- ical image segmentation,
Z. Zhou, M. M. Rahman Siddiquee, N. Tajbakhsh, and J. Liang, “Unet++: A nested u-net architecture for med- ical image segmentation,” inDeep learning in medical image analysis and multimodal learning for clinical decision support. Springer, 2018
2018
-
[52]
Shallow attention network for polyp segmen- tation,
J. Wei, Y . Hu, R. Zhang, Z. Li, S. K. Zhou, and S. Cui, “Shallow attention network for polyp segmen- tation,” inMedical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part I 24. Springer, 2021
2021
-
[53]
N. C. F. Codella, D. Gutman, M. E. Celebi, B. Helba, M. A. Marchetti, S. W. Dusza, A. Kalloo, K. Liopyris, N. Mishra, H. Kittler, and A. Halpern, “Skin lesion analy- sis toward melanoma detection: A challenge at the 2017 international symposium on biomedical imaging (isbi), hosted by the international skin imaging collaboration (isic),” in2018 IEEE 15th I...
2017
-
[54]
N. Codella, V . Rotemberg, P. Tschandl, M. E. Celebi, S. Dusza, D. Gutman, B. Helba, A. Kalloo, K. Liopy- ris, M. Marchettiet al., “Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (isic),”arXiv preprint arXiv:1902.03368, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[55]
Kvasir- seg: A segmented polyp dataset,
D. Jha, P. H. Smedsrud, M. A. Riegler, P. Halvorsen, T. de Lange, D. Johansen, and H. D. Johansen, “Kvasir- seg: A segmented polyp dataset,” inMultiMedia Model- ing: 26th International Conference, 2020
2020
-
[56]
Ege-unet: an efficient group enhanced unet for skin lesion segmen- tation,
J. Ruan, M. Xie, J. Gao, T. Liu, and Y . Fu, “Ege-unet: an efficient group enhanced unet for skin lesion segmen- tation,” inInternational conference on medical image computing and computer-assisted intervention. Springer, 2023
2023
-
[57]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,”arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[58]
SGDR: Stochastic Gradient Descent with Warm Restarts
——, “Sgdr: Stochastic gradient descent with warm restarts,”arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.