DeVAR: Low-Dose CT Denoising via Visual Autoregressive Modeling
Pith reviewed 2026-06-30 01:20 UTC · model grok-4.3
The pith
DeVAR uses visual autoregressive modeling to denoise low-dose CT images by generating normal-dose CT token maps from LDCT global context and refining residuals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
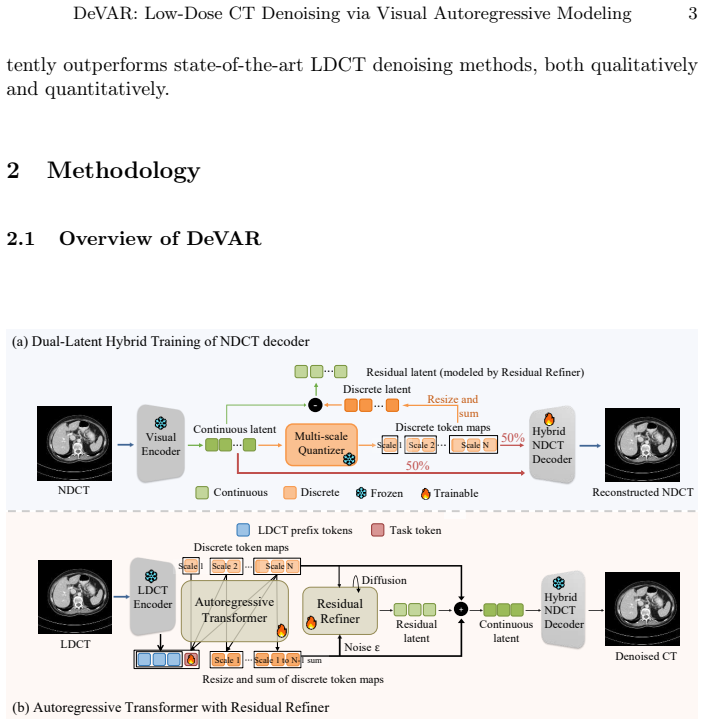
DeVAR is a generative framework that applies visual autoregressive modeling to LDCT denoising for the first time. Conditioned on global context provided by LDCT prefix tokens, it progressively generates discrete token maps of the target NDCT via next-scale prediction. A residual refiner captures subtle anatomical structures beyond the discrete codebook, and a dual-representation hybrid training strategy allows the hybrid NDCT decoder to integrate continuous and discrete latents for high-fidelity reconstruction, leading to superior performance on two public datasets.
What carries the argument
Visual autoregressive modeling with next-scale prediction conditioned on LDCT prefix tokens, augmented by a residual refiner and dual-representation hybrid NDCT decoder.
If this is right
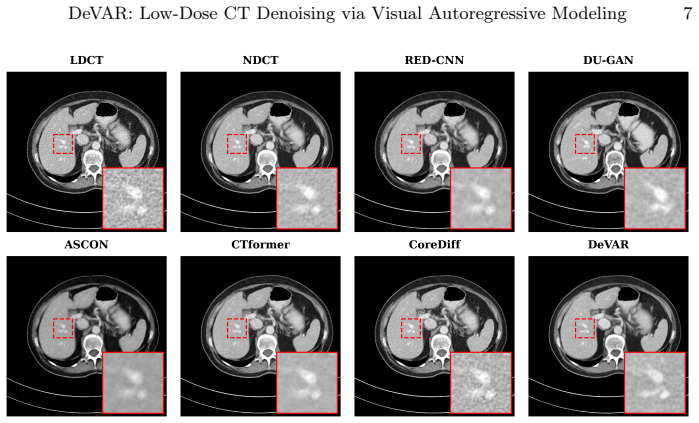
- Superior qualitative and quantitative results on public LDCT datasets compared to existing methods.
- Improved preservation of fine anatomical details through global-to-local dependency capture.
- Effective handling of quantization losses via the residual refiner.
- The hybrid training enables seamless integration of discrete and continuous representations.
Where Pith is reading between the lines
- Similar autoregressive conditioning could be tested on other denoising tasks like MRI or ultrasound.
- If the approach scales, it might reduce the need for high radiation in routine scans.
- The next-scale prediction mechanism may generalize to other image restoration problems where structure is hierarchical.
Load-bearing premise
That conditioning on global LDCT prefix tokens and next-scale autoregressive prediction will intrinsically capture global-to-local structural dependencies better than prior deep-learning approaches.
What would settle it
A head-to-head comparison on the two public datasets where DeVAR fails to exceed the best existing method in metrics such as PSNR, SSIM, or visual detail preservation.
Figures
read the original abstract
Computed tomography (CT) plays a crucial role in medical diagnosis, but minimizing radiation exposure while maintaining image quality remains a critical challenge. Low-dose CT (LDCT) protocols reduce radiation risks but inevitably suffer from severe noise and artifacts that compromise diagnostic accuracy. While existing deep learning methods have achieved promising results, there remains a continuous quest for generative paradigms that intrinsically capture global-to-local structural dependencies to better preserve fine anatomical details. To this end, we propose DeVAR, a novel generative framework that applies visual autoregressive modeling (VAR) to LDCT denoising for the first time. Conditioned on global context provided by LDCT prefix tokens, DeVAR progressively generates discrete token maps of the target normal-dose CT (NDCT) via next-scale prediction. Because quantization inherently discards high-frequency information, we introduce a residual refiner to capture subtle anatomical structures beyond the capacity of a discrete codebook. Finally, empowered by a dual-representation hybrid training strategy, our hybrid NDCT decoder seamlessly integrates continuous and discrete latents to reconstruct high-fidelity, detail-preserved images. Extensive experiments on two public datasets demonstrate that DeVAR consistently achieves superior qualitative and quantitative performance compared to state-of-the-art LDCT denoising methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeVAR, a novel generative framework applying visual autoregressive modeling (VAR) to low-dose CT (LDCT) denoising for the first time. It conditions on global LDCT prefix tokens to progressively generate discrete token maps of normal-dose CT (NDCT) via next-scale prediction, adds a residual refiner to recover high-frequency anatomical details lost to quantization, and employs a dual-representation hybrid decoder integrating continuous and discrete latents. The authors claim that extensive experiments on two public datasets demonstrate consistent superiority in both qualitative and quantitative performance over state-of-the-art LDCT denoising methods.
Significance. If the superiority claims hold under detailed scrutiny, this work would mark a meaningful contribution by extending visual autoregressive modeling to medical image denoising, offering a new way to model global-to-local structural dependencies while mitigating quantization losses through the residual refiner and hybrid decoder. The novelty of applying VAR in this domain and the hybrid training strategy could influence subsequent research on detail-preserving generative models for low-radiation imaging.
major comments (1)
- [Experiments] The central claim of consistent superiority over SOTA methods is load-bearing for the paper's contribution, yet the provided manuscript text (including the abstract) contains no quantitative metrics, dataset sizes, error bars, statistical tests, ablation results, or baseline implementation details. This prevents verification of the performance gains or ruling out post-hoc data choices, as noted in the review constraints.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for detailed experimental reporting. We agree that quantitative metrics, dataset details, error bars, statistical tests, ablations, and baseline information are essential to substantiate the superiority claims and enable verification. We will revise the manuscript to include a comprehensive Experiments section addressing all points raised.
read point-by-point responses
-
Referee: [Experiments] The central claim of consistent superiority over SOTA methods is load-bearing for the paper's contribution, yet the provided manuscript text (including the abstract) contains no quantitative metrics, dataset sizes, error bars, statistical tests, ablation results, or baseline implementation details. This prevents verification of the performance gains or ruling out post-hoc data choices, as noted in the review constraints.
Authors: We agree with this assessment. The current manuscript draft does not include the requested quantitative details in the provided text. In the revised version, we will expand the Experiments section to report: (1) quantitative metrics (PSNR, SSIM, RMSE) with means and standard deviations (error bars) computed over the test sets; (2) dataset sizes and splits for the two public datasets; (3) statistical significance tests (e.g., paired t-tests or Wilcoxon tests) comparing DeVAR to baselines; (4) full ablation studies on the residual refiner, hybrid decoder, and next-scale prediction components; and (5) implementation details for all baselines, including training protocols and hyperparameters used for reproduction. These additions will directly support the claims and allow independent verification. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and method description introduce DeVAR as a novel application of visual autoregressive modeling (VAR) to LDCT denoising, with components like next-scale prediction, residual refiner, and hybrid decoder described at a high level without any equations, fitted parameters renamed as predictions, or self-citations that bear the central claim. No derivation chain reduces outputs to inputs by construction, and performance superiority is asserted via external experimental comparisons on public datasets rather than internal self-referential logic. This is a standard case of a self-contained proposal whose validity rests on empirical benchmarks outside the paper's own definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A non-local algorithm for image denoising[C]//2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05)
Buades A, Coll B, Morel J M. A non-local algorithm for image denoising[C]//2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05). Ieee, 2005, 2: 60-65
2005
-
[2]
Image denoising by sparse 3-D transform- domain collaborative filtering[J]
Dabov K, Foi A, Katkovnik V, et al. Image denoising by sparse 3-D transform- domain collaborative filtering[J]. IEEE Transactions on image processing, 2007, 16(8): 2080-2095
2007
-
[3]
Low-dose computed tomography image restoration using previous normal-dose scan[J]
Ma J, Huang J, Feng Q, et al. Low-dose computed tomography image restoration using previous normal-dose scan[J]. Medical physics, 2011, 38(10): 5713-5731
2011
-
[4]
Denoised and texture enhanced MVCT to improve soft tissue conspicuity[J]
Sheng K, Gou S, Wu J, et al. Denoised and texture enhanced MVCT to improve soft tissue conspicuity[J]. Medical physics, 2014, 41(10): 101916
2014
-
[5]
Low-dose CT with a residual encoder-decoder convolutional neural network[J]
Chen H, Zhang Y, Kalra M K, et al. Low-dose CT with a residual encoder-decoder convolutional neural network[J]. IEEE transactions on medical imaging, 2017, 36(12): 2524-2535
2017
-
[6]
Edcnn: Edge enhancement-based densely connected net- work with compound loss for low-dose ct denoising[C]//2020 15th IEEE International conference on signal processing (ICSP)
Liang T, Jin Y, Li Y, et al. Edcnn: Edge enhancement-based densely connected net- work with compound loss for low-dose ct denoising[C]//2020 15th IEEE International conference on signal processing (ICSP). IEEE, 2020, 1: 193-198
2020
-
[7]
Low-dose CT image denoising using a generative ad- versarial network with Wasserstein distance and perceptual loss[J]
Yang Q, Yan P, Zhang Y, et al. Low-dose CT image denoising using a generative ad- versarial network with Wasserstein distance and perceptual loss[J]. IEEE transactions on medical imaging, 2018, 37(6): 1348-1357
2018
-
[8]
DU-GAN: Generative adversarial networks with dual-domain U-Net-based discriminators for low-dose CT denoising[J]
Huang Z, Zhang J, Zhang Y, et al. DU-GAN: Generative adversarial networks with dual-domain U-Net-based discriminators for low-dose CT denoising[J]. IEEE Transactions on Instrumentation and Measurement, 2021, 71: 1-12
2021
-
[9]
ASCON: Anatomy-aware supervised contrastive learning framework for low-dose CT denoising[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention
Chen Z, Gao Q, Zhang Y, et al. ASCON: Anatomy-aware supervised contrastive learning framework for low-dose CT denoising[C]//International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham: Springer Nature Switzerland, 2023: 355-365
2023
-
[10]
CoreDiff: Contextual error-modulated generalized diffusion model for low-dose CT denoising and generalization[J]
Gao Q, Li Z, Zhang J, et al. CoreDiff: Contextual error-modulated generalized diffusion model for low-dose CT denoising and generalization[J]. IEEE Transactions on Medical Imaging, 2023, 43(2): 745-759
2023
-
[11]
Taming transformers for high-resolution image synthesis[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser P, Rombach R, Ommer B. Taming transformers for high-resolution image synthesis[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021: 12873-12883
2021
-
[12]
Attention is all you need[J]
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30
2017
-
[13]
Visual autoregressive modeling: Scalable image generation via next-scale prediction[J]
Tian K, Jiang Y, Yuan Z, et al. Visual autoregressive modeling: Scalable image generation via next-scale prediction[J]. Advances in neural information processing systems, 2024, 37: 84839-84865
2024
-
[14]
Scalable diffusion models with transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision
Peebles W, Xie S. Scalable diffusion models with transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2023: 4195-4205
2023
-
[15]
Hart: Efficient visual generation with hybrid autoregressive transformer,
Tang H, Wu Y, Yang S, et al. Hart: Efficient visual generation with hybrid autore- gressive transformer[J]. arXiv preprint arXiv:2410.10812, 2024
-
[16]
Classifier-Free Diffusion Guidance
Ho J, Salimans T. Classifier-free diffusion guidance[J]. arXiv preprint arXiv:2207.12598, 2022. 10 X. Zhang et al
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
Low-dose CT for the detection and classification of metastatic liver lesions: results of the 2016 low dose CT grand challenge[J]
McCollough C H, Bartley A C, Carter R E, et al. Low-dose CT for the detection and classification of metastatic liver lesions: results of the 2016 low dose CT grand challenge[J]. Medical physics, 2017, 44(10): e339-e352
2016
-
[18]
Low-dose CT image and projection dataset[J]
Moen T R, Chen B, Holmes III D R, et al. Low-dose CT image and projection dataset[J]. Medical physics, 2021, 48(2): 902-911
2021
-
[19]
Language models are unsupervised multitask learners[J]
Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI blog, 2019, 1(8): 9
2019
-
[20]
Decoupled Weight Decay Regularization
Loshchilov I, Hutter F. Fixing weight decay regularization in adam[J]. arXiv preprint arXiv:1711.05101, 2017, 5(5): 5
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Deep residual learning for image recogni- tion[C]//Proceedings of the IEEE conference on computer vision and pattern recog- nition
He K, Zhang X, Ren S, et al. Deep residual learning for image recogni- tion[C]//Proceedings of the IEEE conference on computer vision and pattern recog- nition. 2016: 770-778
2016
-
[22]
Autoregressive image generation without vector quantiza- tion[J]
Li T, Tian Y, Li H, et al. Autoregressive image generation without vector quantiza- tion[J]. Advances in Neural Information Processing Systems, 2024, 37: 56424-56445
2024
-
[23]
Neural discrete representation learning[J]
Van Den Oord A, Vinyals O. Neural discrete representation learning[J]. Advances in neural information processing systems, 2017, 30
2017
-
[24]
CTformer: convolution-free Token2Token dilated vision transformer for low-dose CT denoising[J]
Wang D, Fan F, Wu Z, et al. CTformer: convolution-free Token2Token dilated vision transformer for low-dose CT denoising[J]. Physics in Medicine & Biology, 2023, 68(6): 065012
2023
-
[25]
Hformer: highly efficient vision transformer for low-dose CT denoising[J]
Zhang S Y, Wang Z X, Yang H B, et al. Hformer: highly efficient vision transformer for low-dose CT denoising[J]. Nuclear Science and Techniques, 2023, 34(4): 61
2023
-
[26]
Maniqa: Multi-dimension attention network for no- reference image quality assessment[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang S, Wu T, Shi S, et al. Maniqa: Multi-dimension attention network for no- reference image quality assessment[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 1191-1200
2022
-
[27]
Exploring clip for assessing the look and feel of images[C]//Proceedings of the AAAI conference on artificial intelligence
Wang J, Chan K C K, Loy C C. Exploring clip for assessing the look and feel of images[C]//Proceedings of the AAAI conference on artificial intelligence. 2023, 37(2): 2555-2563
2023
-
[28]
Musiq: Multi-scale image quality trans- former[C]//Proceedings of the IEEE/CVF international conference on computer vision
Ke J, Wang Q, Wang Y, et al. Musiq: Multi-scale image quality trans- former[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 5148-5157
2021
-
[29]
Image quality assessment: from error visibility to structural similarity[J]
Wang Z, Bovik A C, Sheikh H R, et al. Image quality assessment: from error visibility to structural similarity[J]. IEEE transactions on image processing, 2004, 13(4): 600-612
2004
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.