Improving Patient Subtyping on Longitudinal Data using Representations from Mamba-based Architecture
Pith reviewed 2026-06-30 00:27 UTC · model grok-4.3
The pith
A self-supervised Mamba-based model learns representations from longitudinal EHR data that improve classification accuracy and patient subtyping over baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that specific design choices in their self-supervised Mamba-based model produce representations from temporal EHR data that yield higher performance than competitive baselines on classification tasks and that enable clustering methods to reveal meaningful patient subtypes on both public and private real-world datasets.
What carries the argument
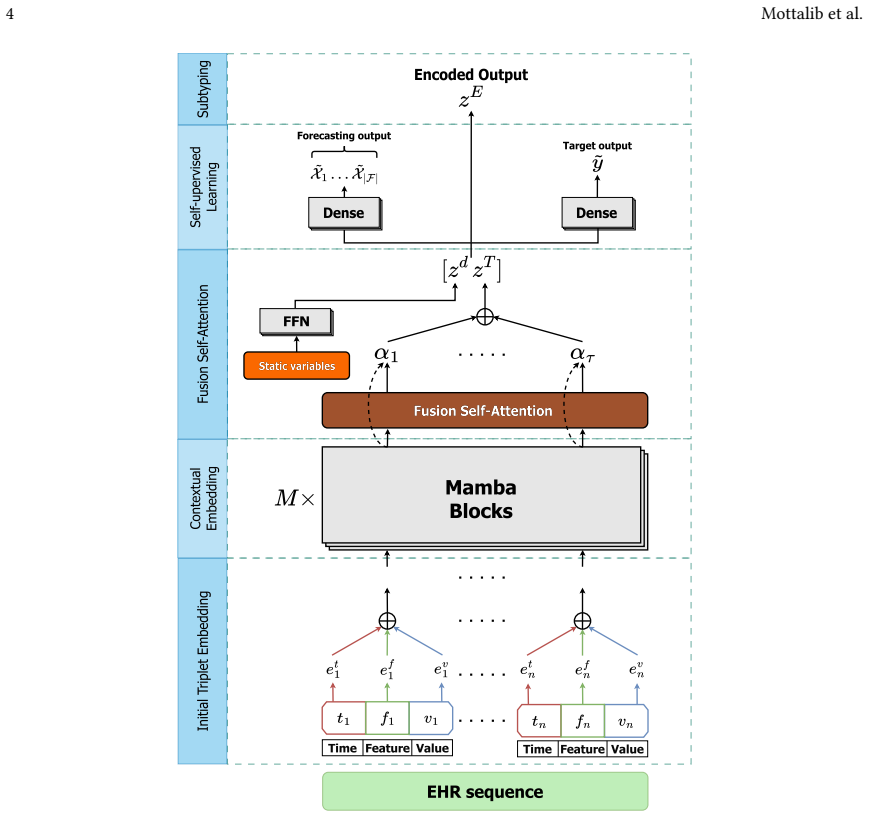
Self-supervised Mamba-based architecture that processes sequential longitudinal EHR data to produce representations for downstream prediction and clustering.
If this is right
- The model achieves better performance than competitive baselines on classification of EHR data with available labels.
- Clustering techniques applied to the learned representations provide insights into patient subtypes from temporal records.
- The approach works on both public and private real-world longitudinal EHR datasets.
- Design choices in the Mamba architecture contribute to the improved representation quality for these tasks.
Where Pith is reading between the lines
- The same self-supervised representations could support additional tasks such as forecasting future health events not examined in the current experiments.
- Explicit modeling of missingness patterns in EHR data might further strengthen the learned representations beyond what the current architecture achieves.
- Similar Mamba-based self-supervised training could be tested on other irregular sequential medical datasets such as vital-sign streams from ICU monitors.
Load-bearing premise
A self-supervised Mamba model can produce representations from irregular longitudinal EHR data that are meaningfully better for both prediction and subtyping, without explicit mechanisms described for handling missing values or irregular timing.
What would settle it
A head-to-head evaluation on the same public and private EHR datasets showing that the Mamba model does not exceed baseline accuracy on classification or produce higher-quality clusters according to standard metrics such as silhouette score or adjusted Rand index.
Figures
read the original abstract
Effective sub-typing (also known as grouping or clustering) of patients using their electronic health record (EHR) data can greatly inform precision medicine efforts. However, subtyping temporal EHR datasets is known to be challenging due to inherent EHR issues, including complexity and irregularity. In this study, we propose a self-supervised Mamba-based model that learns effective EHR representations and enables enhanced patient subtyping. We evaluate the proposed model on public and private real-world EHR datasets to classify the data based on the available labels and subtype patients based on the representations learned from the model. Through an extensive set of experiments, we demonstrate that our model's design choices lead to better performance compared to competitive baseline models for prediction. Moreover, we evaluate several clustering techniques to demonstrate that our findings offer valuable insights into subtyping patients based on temporal records from EHR models\footnote{Our implementations are available at https://github.com/healthylaife/triplet_mamba.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-supervised Mamba-based model to learn representations from longitudinal EHR data that are then used both for supervised prediction (classification based on available labels) and for unsupervised patient subtyping via multiple clustering techniques. It claims that the model's design choices yield better performance than competitive baselines on public and private real-world EHR datasets and that the learned representations provide valuable insights into patient subtyping.
Significance. If the claimed performance gains are shown to arise from the Mamba architecture's ability to capture temporal structure rather than from unstated preprocessing choices, the work could contribute a practical approach to precision-medicine subtyping on irregular EHR time series. The public release of implementations is a positive factor for reproducibility.
major comments (3)
- [Abstract, §3] Abstract and §3 (Proposed Method): the central claim that the model 'learns effective EHR representations' for irregular longitudinal data is not supported by any description of how visit irregularity, time deltas, or missing features are encoded or masked before the Mamba blocks. Without this mechanism the reported gains cannot be attributed to the architecture rather than to preprocessing.
- [§4] §4 (Experiments): the comparison to baselines does not report whether the same preprocessing pipeline (including any handling of irregularity) was applied to all models; this is load-bearing for the claim that 'our model's design choices lead to better performance'.
- [§5] §5 (Clustering evaluation): the subtyping results are presented without quantitative metrics (e.g., silhouette score, adjusted Rand index against known phenotypes) or ablation on representation dimensionality, making it impossible to assess whether the Mamba representations genuinely improve clustering over raw or baseline features.
minor comments (2)
- [footnote] The GitHub link in the footnote should be verified to contain the exact code and hyperparameters used in the reported experiments.
- [§3] Notation for the self-supervised loss and the Mamba state-space parameters should be introduced consistently in §3 before being referenced in the experimental section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We provide point-by-point responses to the major comments below and will make revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Proposed Method): the central claim that the model 'learns effective EHR representations' for irregular longitudinal data is not supported by any description of how visit irregularity, time deltas, or missing features are encoded or masked before the Mamba blocks. Without this mechanism the reported gains cannot be attributed to the architecture rather than to preprocessing.
Authors: We agree that the handling of irregularity was not described in sufficient detail. In the revised manuscript, we will add a clear description in §3 of how time deltas are encoded as additional input features, missing features are handled via masking, and visit irregularity is managed through sequence padding and Mamba's state space model properties. This will support that the performance gains stem from the architecture. revision: yes
-
Referee: [§4] §4 (Experiments): the comparison to baselines does not report whether the same preprocessing pipeline (including any handling of irregularity) was applied to all models; this is load-bearing for the claim that 'our model's design choices lead to better performance'.
Authors: The same preprocessing pipeline was indeed applied to all models, as noted in the data preparation section. To make this explicit, we will revise §4 to include a statement confirming uniform preprocessing across the proposed model and all baselines. revision: yes
-
Referee: [§5] §5 (Clustering evaluation): the subtyping results are presented without quantitative metrics (e.g., silhouette score, adjusted Rand index against known phenotypes) or ablation on representation dimensionality, making it impossible to assess whether the Mamba representations genuinely improve clustering over raw or baseline features.
Authors: We acknowledge the value of quantitative metrics. In the revision, we will incorporate silhouette scores and adjusted Rand index (where applicable) for the clustering results in §5, along with an ablation study varying the representation dimensionality to evaluate its effect on subtyping quality. revision: yes
Circularity Check
No circularity: empirical ML evaluation on EHR data is self-contained
full rationale
The paper proposes and empirically evaluates a self-supervised Mamba model for EHR representation learning, reporting performance gains on classification and clustering tasks versus baselines. No mathematical derivation chain, first-principles predictions, or fitted parameters presented as independent results exist in the abstract or description. Claims rest on standard held-out evaluation rather than any self-definitional, self-citation load-bearing, or ansatz-smuggling steps. The work is self-contained against external benchmarks with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Shaojie Bai, J Zico Kolter, and Vladlen Koltun. 2018. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv preprint arXiv:1803.01271(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[3]
Maria Bampa, Ioanna Miliou, Braslav Jovanovic, and Panagiotis Papapetrou. 2024. M-ClustEHR: A multimodal clustering approach for electronic health records.Artificial Intelligence in Medicine154 (2024), 102905
2024
-
[4]
William Baskett, Benjamin Black, Adnan I Qureshi, and Ch-Ren Shyu. 2025. Identifying homogenous patient subgroups using transformer based hierarchical clustering of heterogeneous Mixed-Modality medical data.Journal of Biomedical Informatics(2025), 104878
2025
-
[5]
Inci M Baytas, Cao Xiao, Xi Zhang, Fei Wang, Anil K Jain, and Jiayu Zhou. 2017. Patient subtyping via time-aware LSTM networks. InProceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining. 65–74
2017
-
[6]
Zhengping Che, Sanjay Purushotham, Kyunghyun Cho, David Sontag, and Yan Liu. 2018. Recurrent neural networks for multivariate time series with missing values.Scientific reports8, 1 (2018), 6085
2018
-
[7]
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. 2014. Empirical evaluation of gated recurrent neural networks on sequence modeling.arXiv preprint arXiv:1412.3555(2014)
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[8]
Tri Dao, Daniel Y Fu, Khaled K Saab, Armin W Thomas, Atri Rudra, and Christopher Ré. 2023. Hungry Hungry Hippos: Towards Language Modeling with State Space Models. InProceedings of the 11th International Conference on Learning Representations (ICLR)
2023
-
[9]
Jip WTM de Kok, Frank van Rosmalen, Jacqueline Koeze, Frederik Keus, Sander MJ van Kuijk, José Castela Forte, Ronny M Schnabel, Rob GH Driessen, Thijs TW van Herpt, Jan-Willem EM Sels, et al. 2024. Deep embedded clustering generalisability and adaptation for integrating mixed datatypes: two critical care cohorts.Scientific Reports14, 1 (2024), 1045
2024
- [10]
-
[11]
Timothy Bunnell, Thao-Ly T
Hamed Fayyaz, Mehak Gupta, Alejandra Perez Ramirez, Claudine Jurkovitz, H. Timothy Bunnell, Thao-Ly T. Phan, and Rahmatollah Beheshti. 2025. An Interoperable Machine Learning Pipeline for Pediatric Obesity Risk Estimation. InProceedings of the 4th Machine Learning for Health Symposium (Proceedings of Machine Learning Research, Vol. 259), Stefan Hegselmann...
2025
-
[12]
Helge Fredriksen, Per Joel Burman, Ashenafi Zebene Woldaregay, Karl Oyvind Mikalsen, and Stale Nymo. 2024. Categorization of phenotype trajectories utilizing transformers on clinical time-series. InProceedings of the 2024 9th International Conference on Machine Learning Technologies. 311–316
2024
-
[13]
Daniel Y Fu, Elliot L Epstein, Eric Nguyen, Armin W Thomas, Michael Zhang, Tri Dao, Atri Rudra, and Christopher Ré. 2023. Simple hardware-efficient long convolutions for sequence modeling. InInternational Conference on Machine Learning. PMLR, 10373–10391
2023
-
[14]
Aditya Gorla, Jonathan Witonsky, Zeyuan Johnson Chen, Jennifer R Elhawary, Joel Mefford, Javier Perez-Garcia, Anne-Marie Madore, Scott Huntsman, Donglei Hu, Celeste Eng, et al . 2025. Epigenetic patient stratification reveals a sub-endotype of type 2 asthma with altered B-cell response.medRxiv(2025), 2025–08
2025
-
[15]
Albert Gu and Tri Dao. 2024. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. InFirst Conference on Language Modeling
2024
-
[16]
Albert Gu, Tri Dao, Stefano Ermon, Atri Rudra, and Christopher Ré. 2020. Hippo: Recurrent memory with optimal polynomial projections.Advances in neural information processing systems33 (2020), 1474–1487
2020
-
[17]
Albert Gu, Karan Goel, and Christopher Re. 2022. Efficiently Modeling Long Sequences with Structured State Spaces. InInternational Conference on Learning Representations
2022
-
[18]
Mehak Gupta, Brennan Gallamoza, Nicolas Cutrona, Pranjal Dhakal, Raphael Poulain, and Rahmatollah Beheshti. 2022. An Extensive Data Processing Pipeline for MIMIC-IV. InProceedings of the 2nd Machine Learning for Health symposium (Proceedings of Machine Learning Research, Vol. 193), Antonio Parziale, Monica Agrawal, Shalmali Joshi, Irene Y. Chen, Shengpu T...
2022
-
[19]
Sarah E Hampl, Sandra G Hassink, Asheley C Skinner, Sarah C Armstrong, Sarah E Barlow, Christopher F Bolling, Kimberly C Avila Edwards, Ihuoma Eneli, Robin Hamre, Madeline M Joseph, et al. 2023. Clinical practice guideline for the evaluation and treatment of children and adolescents with obesity.Pediatrics151, 2 (2023)
2023
-
[20]
Max Horn, Michael Moor, Christian Bock, Bastian Rieck, and Karsten Borgwardt. 2020. Set functions for time series. InInternational Conference on Machine Learning. PMLR, 4353–4363
2020
-
[21]
Dino Ienco and Roberto Interdonato. 2020. Deep multivariate time series embedding clustering via attentive-gated autoencoder. InAdvances in Knowledge Discovery and Data Mining: 24th Pacific-Asia Conference, PAKDD 2020, Singapore, May 11–14, 2020, Proceedings, Part I 24. Springer, 318–329
2020
-
[22]
Xilin Jiang, Martin Jinye Zhang, Yidong Zhang, Arun Durvasula, Michael Inouye, Chris Holmes, Alkes L Price, and Gil McVean. 2023. Age-dependent topic modeling of comorbidities in UK Biobank identifies disease subtypes with differential genetic risk.Nature genetics55, 11 (2023), 1854–1865
2023
-
[23]
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Steven Horng, Leo Anthony Celi, and Roger Mark. 2020. Mimic-iv.PhysioNet. A vailable online at: https://physionet. org/content/mimiciv/1.0/(accessed August 23, 2021)(2020), 49–55. Improving Patient Subtyping 13
2020
-
[24]
Alex Labach, Aslesha Pokhrel, Xiao Shi Huang, Saba Zuberi, Seung Eun Yi, Maksims Volkovs, Tomi Poutanen, and Rahul G Krishnan. 2023. DuETT: dual event time transformer for electronic health records. InMachine Learning for Healthcare Conference. PMLR, 403–422
2023
-
[25]
Changhee Lee and Mihaela Van Der Schaar. 2020. Temporal phenotyping using deep predictive clustering of disease progression. InInternational conference on machine learning. PMLR, 5767–5777
2020
-
[26]
Deyi Li, Aditi Shukla, Sravani Chandaka, Bradley Taylor, Jie Xu, and Mei Liu. 2025. Autoencoder-Based Representation Learning for Similar Patients Retrieval From Electronic Health Records: Comparative Study.JMIR Medical Informatics13 (2025), e68830
2025
-
[27]
Xiaoyu Li, Taosheng Xu, Jinyu Chen, Jun Wan, and Wenwen Min. 2023. Multimodal attention-based variational autoencoder for clinical risk prediction. In2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 1260–1265
2023
-
[28]
Yikuan Li, Mohammad Mamouei, Gholamreza Salimi-Khorshidi, Shishir Rao, Abdelaali Hassaine, Dexter Canoy, Thomas Lukasiewicz, and Kazem Rahimi. 2022. Hi-BEHRT: hierarchical transformer-based model for accurate prediction of clinical events using multimodal longitudinal electronic health records.IEEE journal of biomedical and health informatics27, 2 (2022),...
2022
-
[29]
Yikuan Li, Shishir Rao, José Roberto Ayala Solares, Abdelaali Hassaine, Rema Ramakrishnan, Dexter Canoy, Yajie Zhu, Kazem Rahimi, and Gholamreza Salimi-Khorshidi. 2020. BEHRT: transformer for electronic health records.Scientific reports10, 1 (2020), 7155
2020
-
[30]
Rupa Makadia and Patrick B Ryan. 2014. Transforming the premier perspective®hospital database into the observational medical outcomes partnership (omop) common data model.Egems2, 1 (2014), 1110
2014
-
[31]
Timothy Bunnell, and Thao-Ly T
Md Mozaharul Mottalib, Rahmatollah Beheshti, Karthik Viswanathan, H. Timothy Bunnell, and Thao-Ly T. Phan. 2026. Pre- dicting Weight Outcomes From Obesity Medications in a Paediatric Population.Pediatric Obesity21, 2 (2026), e70089. arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/ijpo.70089 doi:10.1111/ijpo.70089 e70089 IJPO-2025-0189
-
[32]
Md Mozaharul Mottalib, Jessica C Jones-Smith, Bethany Sheridan, and Rahmatollah Beheshti. 2023. Subtyping patients with chronic disease using longitudinal BMI patterns.IEEE Journal of Biomedical and Health Informatics27, 4 (2023), 2083–2093
2023
-
[33]
Md Mozaharul Mottalib, Thao-Ly T Phan, and Rahmatollah Beheshti. 2025. HyMaTE: A Hybrid Mamba and Transformer Model for EHR Representation Learning. InProceedings of the 16th ACM International Conference on Bioinformatics, Computational Biology, and Health Informatics. 1–9
2025
-
[34]
Chao Pang, Xinzhuo Jiang, Krishna S Kalluri, Matthew Spotnitz, RuiJun Chen, Adler Perotte, and Karthik Natarajan. 2021. CEHR-BERT: Incorporating temporal information from structured EHR data to improve prediction tasks. InMachine Learning for Health. PMLR, 239–260
2021
-
[35]
Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. 2023. Hyena hierarchy: Towards larger convolutional language models. InInternational Conference on Machine Learning. PMLR, 28043–28078
2023
-
[36]
Raphael Poulain and Rahmatollah Beheshti. 2024. Graph transformers on EHRs: Better representation improves downstream performance. InThe Twelfth International Conference on Learning Representations
2024
-
[37]
Alvin Rajkomar, Eyal Oren, Kai Chen, Andrew M Dai, Nissan Hajaj, Michaela Hardt, Peter J Liu, Xiaobing Liu, Jake Marcus, Mimi Sun, et al. 2018. Scalable and accurate deep learning with electronic health records.NPJ digital medicine1, 1 (2018), 1–10
2018
-
[38]
Laila Rasmy, Yang Xiang, Ziqian Xie, Cui Tao, and Degui Zhi. 2021. Med-BERT: pretrained contextualized embeddings on large-scale structured electronic health records for disease prediction.NPJ digital medicine4, 1 (2021), 86
2021
-
[39]
Maurice Rupp, Oriane Peter, and Thirupathi Pattipaka. 2023. Exbehrt: Extended transformer for electronic health records. InInternational Workshop on Trustworthy Machine Learning for Healthcare. Springer, 73–84
2023
-
[40]
Satya Narayan Shukla and Benjamin Marlin. 2019. Interpolation-Prediction Networks for Irregularly Sampled Time Series. InInternational Conference on Learning Representations
2019
-
[41]
Ikaro Silva, George Moody, Daniel J Scott, Leo A Celi, and Roger G Mark. 2012. Predicting in-hospital mortality of icu patients: The phys- ionet/computing in cardiology challenge 2012. In2012 computing in cardiology. IEEE, 245–248
2012
-
[42]
Huan Song, Deepta Rajan, Jayaraman Thiagarajan, and Andreas Spanias. 2018. Attend and diagnose: Clinical time series analysis using attention models. InProceedings of the AAAI conference on artificial intelligence, Vol. 32
2018
-
[43]
Sindhu Tipirneni and Chandan K Reddy. 2022. Self-supervised transformer for sparse and irregularly sampled multivariate clinical time-series. ACM Transactions on Knowledge Discovery from Data (TKDD)16, 6 (2022), 1–17
2022
-
[44]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in neural information processing systems30 (2017)
2017
-
[45]
Qingsong Wen, Tian Zhou, Chaoli Zhang, Weiqi Chen, Ziqing Ma, Junchi Yan, and Liang Sun. 2023. Transformers in time series: a survey. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence. 6778–6786
2023
-
[46]
Michael Wornow, Suhana Bedi, Miguel Angel Fuentes Hernandez, Ethan Steinberg, Jason Alan Fries, Christopher Re, Sanmi Koyejo, and Nigam Shah. 2025. Context Clues: Evaluating Long Context Models for Clinical Prediction Tasks on EHR Data. InThe Thirteenth International Conference on Learning Representations
2025
-
[47]
Zhichao Yang, Avijit Mitra, Sunjae Kwon, and Hong Yu. 2024. ClinicalMamba: A Generative Clinical Language Model on Longitudinal Clinical Notes. InProceedings of the 6th Clinical Natural Language Processing Workshop. 54–63
2024
-
[48]
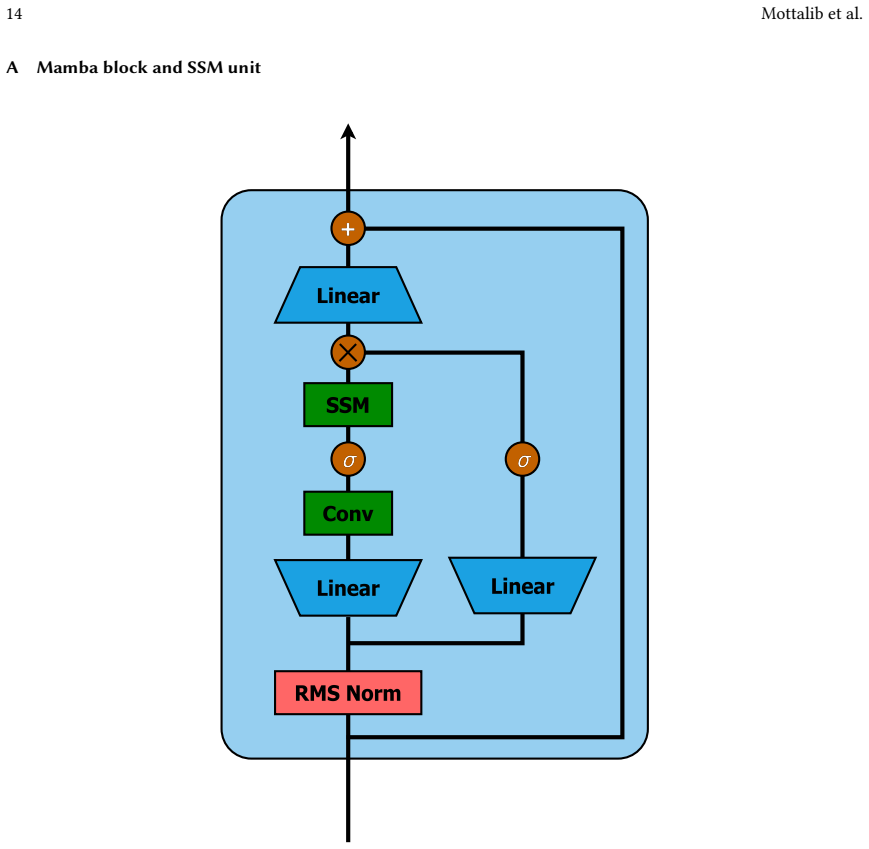
Changchang Yin, Ruoqi Liu, Dongdong Zhang, and Ping Zhang. 2020. Identifying sepsis subphenotypes via time-aware multi-modal auto-encoder. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 862–872. 14 Mottalib et al. A Mamba block and SSM unit Fig. 2. Mamba block SSM unit.The Mamba block (shown at the righ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.