Obliviate: Erasing Concepts from Autoregressive Image Generation Models
Pith reviewed 2026-06-30 00:25 UTC · model grok-4.3
The pith
Obliviate erases specific concepts such as nudity from autoregressive image generators by supervising token distributions over full generation trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Obliviate performs concept erasure in autoregressive models through KL supervision on visual token distributions, trajectory-level parameter updates over full rollouts, and aligned visual prefixes for target construction, which together reduce nudity rates on the RAB benchmark from 91.58 to 3.15 while preserving measured model utility.
What carries the argument
KL-based supervision over visual token distributions during trajectory-level updates guided by aligned visual prefixes.
If this is right
- Explicit content, graphic violence, and branded imagery can be removed from autoregressive generators without retraining from scratch.
- The same model can be adapted to different erasure targets by changing only the prefix and supervision signal.
- Guidance-based erasure works on current state-of-the-art autoregressive models including Liquid, Emu3-Gen, and Janus-Pro.
- Overall generation quality remains close to baseline levels on standard utility benchmarks.
Where Pith is reading between the lines
- The trajectory-level update pattern may extend to other sequential generation tasks such as video or audio autoregressive models.
- Because the method operates at inference time via guidance, repeated application could allow dynamic, user-specified concept lists.
- If the visual prefix alignment proves stable, the technique could support fine-grained control over stylistic attributes beyond safety concepts.
Load-bearing premise
The three design choices suffice to achieve selective erasure without degrading unrelated capabilities or introducing new artifacts as measured by the chosen benchmarks.
What would settle it
A test set in which the post-Obliviate model produces the erased concept at rates above the reported 3.15 while the original benchmarks remain unchanged, or a new utility metric showing clear degradation not captured by existing scores.
Figures

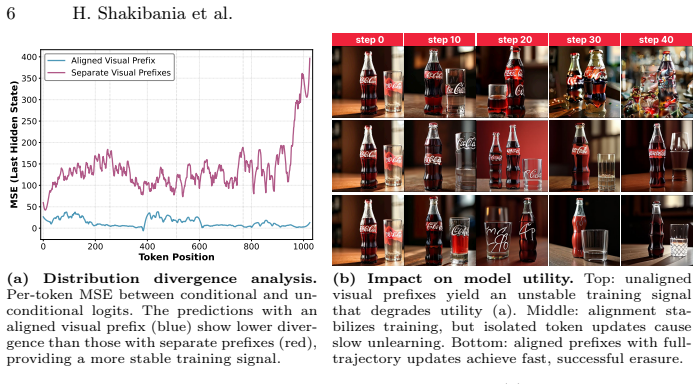
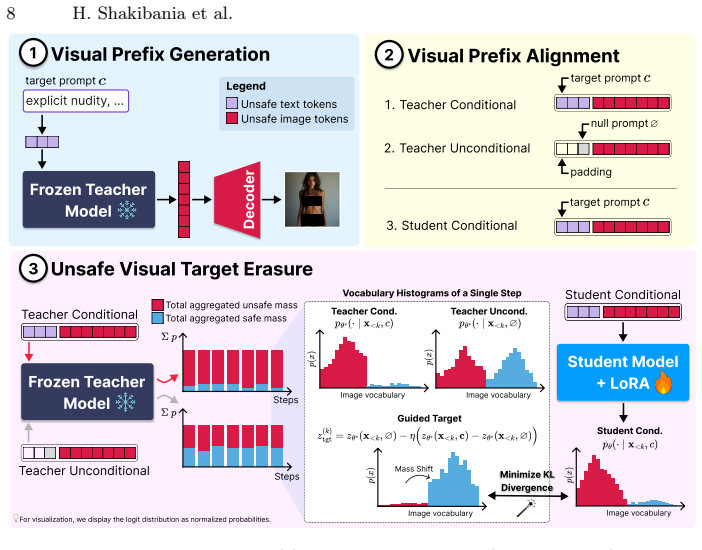

read the original abstract
The widespread adoption of generative AI models has intensified concerns about misuse, including the creation of unsafe or disturbing imagery. To mitigate such issues, several concept erasure approaches have been proposed to remove harmful content from multimodal generative models. Yet concept erasure for autoregressive image generation remains largely unexplored, despite the growing relevance of these models in recent trends toward unified multimodal architectures. In this work, we fill this gap by introducing Obliviate, a guidance-based concept erasure method for autoregressive image generation. Our method builds on three key design choices: KL-based supervision over visual token distributions, trajectory-level updates over full autoregressive rollouts, and aligned visual prefixes for stable target construction. We evaluate Obliviate on three state-of-the-art autoregressive text-to-image models, Liquid, Emu3-Gen, and Janus-Pro, covering the erasure of explicit content, graphic violence, and branded imagery. Obliviate consistently outperforms current alternatives, reducing nudity on the defensive RAB benchmark from 91.58 to 3.15 while preserving overall model utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Obliviate, a guidance-based concept erasure method for autoregressive image generation models. It relies on three design choices—KL-based supervision over visual token distributions, trajectory-level updates over full autoregressive rollouts, and aligned visual prefixes for stable target construction—and evaluates the approach on Liquid, Emu3-Gen, and Janus-Pro for erasing explicit content, graphic violence, and branded imagery. The central empirical claim is consistent outperformance over alternatives, including reduction of nudity on the defensive RAB benchmark from 91.58 to 3.15 while preserving overall model utility.
Significance. If the reported results hold under rigorous controls, this work would be significant for addressing concept erasure in autoregressive multimodal models, an area noted as largely unexplored. The multi-model evaluation and focus on practical safety metrics provide a concrete contribution to mitigating misuse in generative AI. Credit is due for the empirical framing across three distinct architectures and the emphasis on selective erasure without broad utility degradation.
minor comments (3)
- [Abstract, §3] Abstract and §3: the strong benchmark claims (e.g., RAB nudity reduction) are presented without accompanying error bars, ablation tables isolating the three design choices, or explicit controls for prompt distribution shifts; these details should be added to allow verification of the sufficiency claim.
- [§4] §4: clarify how the aligned visual prefixes are constructed and whether they introduce any distribution shift relative to the original model training data.
- [Table 1, §5] Table 1 and §5: report the number of evaluation prompts and any statistical significance tests for the utility preservation metrics across the three models.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its significance for concept erasure in autoregressive models, and the recommendation for minor revision. We will address any minor points in the revised manuscript.
Circularity Check
No significant circularity
full rationale
The manuscript is an empirical method proposal introducing Obliviate for concept erasure in autoregressive models. It relies on three design choices (KL-based supervision, trajectory-level updates, aligned visual prefixes) evaluated via benchmarks on Liquid, Emu3-Gen, and Janus-Pro, with reported improvements on RAB and utility metrics. No equations, derivations, or parameter-fitting steps are present that could reduce predictions to inputs by construction. No self-citation chains or uniqueness theorems are invoked as load-bearing premises. The argument structure is self-contained through direct experimental comparisons without internal reductions to fitted values or prior author results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Abdin, M., Aneja, J., Awadalla, H., Awadallah, A., Awan, A.A., Bach, N., Bahree, A., Bakhtiari, A., Bao, J., Behl, H., Benhaim, A., Bilenko, M., Bjorck, J., Bubeck, S., Cai, M., Cai, Q., Chaudhary, V., Chen, D., Chen, D., Chen, W., Chen, Y.C., Chen, Y.L., Cheng, H., Chopra, P., Dai, X., Dixon, M., Eldan, R., Fragoso, V., Gao, J., Gao, M., Gao, M., Garg, A...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., et al.: Qwen3-vl technical report. arXiv preprint arXiv:2511.21631 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Ban, Y., Wang, R., Zhou, T., Cheng, M., Gong, B., Hsieh, C.J.: Understanding the impact of negative prompts: When and how do they take effect? In: european conference on computer vision. pp. 190–206. Springer (2024)
2024
-
[4]
Bedapudi, P.: Nudenet: Neural nets for nudity classification, detection and selective censoring (2019)
2019
-
[5]
arXiv preprint arXiv:2411.05001 (2024)
Chan, D.M., Corona, R., Park, J., Cho, C.J., Bai, Y., Darrell, T.: Analyzing the language of visual tokens. arXiv preprint arXiv:2411.05001 (2024)
-
[6]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Chen, X., Wu, Z., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C.: Janus-pro: Unified multimodal understanding and generation with data and model scaling. arXiv preprint arXiv:2501.17811 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Esser, P., Rombach, R., Ommer, B.: Taming transformers for high-resolution image synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 12873–12883 (2021)
2021
-
[9]
arXiv preprint arXiv:2506.20151 (2025)
Fan, H., Zhang, S., Guo, Z., Zhang, H., et al.: Ear: Erasing concepts from unified autoregressive models. arXiv preprint arXiv:2506.20151 (2025)
-
[10]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum?id=N5V3dlIck9
Gandikota, R., Feucht, S., Marks, S., Bau, D.: Erasing conceptual knowledge from language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https://openreview.net/forum?id=N5V3dlIck9
2025
-
[11]
In: Proceedings of the IEEE/CVF international conference on computer vision
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., Bau, D.: Erasing concepts from diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2426–2436 (2023)
2023
-
[12]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Gandikota, R., Orgad, H., Belinkov, Y., Materzyńska, J., Bau, D.: Unified concept editing in diffusion models. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 5111–5120 (2024) Obliviate: Erasing Concepts from Autoregressive Image Generation Models 17
2024
-
[13]
Advances in Neural Information Processing Systems36, 52132–52152 (2023)
Ghosh, D., Hajishirzi, H., Schmidt, L.: Geneval: An object-focused framework for evaluating text-to-image alignment. Advances in Neural Information Processing Systems36, 52132–52152 (2023)
2023
-
[14]
In: European Conference on Computer Vision
Gong, C., Chen, K., Wei, Z., Chen, J., Jiang, Y.G.: Reliable and efficient concept erasure of text-to-image diffusion models. In: European Conference on Computer Vision. pp. 73–88. Springer (2024)
2024
-
[15]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[16]
Advances in neural information processing systems33, 6840–6851 (2020)
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020)
2020
-
[17]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[18]
In: European Conference on Computer Vision
Huang, C.P., Chang, K.P., Tsai, C.T., Lai, Y.H., Yang, F.E., Wang, Y.C.F.: Re- celer: Reliable concept erasing of text-to-image diffusion models via lightweight erasers. In: European Conference on Computer Vision. pp. 360–376. Springer (2024)
2024
-
[19]
In: ICCV (2023)
Kumari, N., Zhang, B., Wang, S.Y., Shechtman, E., Zhang, R., Zhu, J.Y.: Ablating concepts in text-to-image diffusion models. In: ICCV (2023)
2023
-
[20]
In: The Thirty- ninthAnnualConferenceonNeuralInformationProcessingSystems(2025),https: //openreview.net/forum?id=igB289kbej
kusumba, N.S.A., Patel, M., Min, K., Kim, C., Baral, C., Yang, Y.: Eraseflow: Learning concept erasure policies via GFlownet-driven alignment. In: The Thirty- ninthAnnualConferenceonNeuralInformationProcessingSystems(2025),https: //openreview.net/forum?id=igB289kbej
2025
-
[21]
Labs, B.F.: FLUX.2: Frontier Visual Intelligence.https://huggingface.co/ black-forest-labs/FLUX.2-dev(2025)
2025
-
[22]
Li,D.,Kamko,A.,Akhgari,E.,Sabet,A.,Xu,L.,Doshi,S.:Playgroundv2.5:Three insights towards enhancing aesthetic quality in text-to-image generation (2024)
2024
-
[23]
In: Forty-first International Conference on Machine Learning (2024),https://openreview.net/forum?id=xlr6AUDuJz
Li, N., Pan, A., Gopal, A., Yue, S., Berrios, D., Gatti, A., Li, J.D., Dombrowski, A.K., Goel, S., Mukobi, G., Helm-Burger, N., Lababidi, R., Justen, L., Liu, A.B., Chen, M., Barrass, I., Zhang, O., Zhu, X., Tamirisa, R., Bharathi, B., Herbert- Voss, A., Breuer, C.B., Zou, A., Mazeika, M., Wang, Z., Oswal, P., Lin, W., Hunt, A.A., Tienken-Harder, J., Shih...
2024
-
[24]
In: Proceedings of the 2023 conference on empirical methods in natural language processing
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, X., Wen, J.R.: Evaluating object hal- lucination in large vision-language models. In: Proceedings of the 2023 conference on empirical methods in natural language processing. pp. 292–305 (2023)
2023
-
[25]
Advances in Neural Information Processing Systems37, 115712– 115756 (2024)
Lin, H., Chen, Y., Wang, J., An, W., Wang, M., Tian, F., Liu, Y., Dai, G., Wang, J., Wang, Q.: Schedule your edit: A simple yet effective diffusion noise schedule for image editing. Advances in Neural Information Processing Systems37, 115712– 115756 (2024)
2024
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
2024
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Lu, S., Wang, Z., Li, L., Liu, Y., Kong, A.W.K.: Mace: Mass concept erasure in diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6430–6440 (2024) 18 H. Shakibania et al
2024
-
[28]
arXiv preprint arXiv:2512.13953 (2025)
Malarz, D., Kasymov, A., Manjak, F., Zięba, M., Spurek, P.: From unlearning to unbranding: A benchmark for trademark-safe text-to-image generation. arXiv preprint arXiv:2512.13953 (2025)
-
[29]
Locating and Editing Factual Associations in GPT
Meng, K., Bau, D., Andonian, A., Belinkov, Y.: Locating and editing factual asso- ciations in GPT. Advances in Neural Information Processing Systems36(2022), arXiv:2202.05262
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
The Eleventh International Conference on Learning Rep- resentations (ICLR) (2023)
Meng, K., Sen Sharma, A., Andonian, A., Belinkov, Y., Bau, D.: Mass editing memory in a transformer. The Eleventh International Conference on Learning Rep- resentations (ICLR) (2023)
2023
-
[31]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Nguyen, T., Singh, K.K., Shi, J., Bui, T., Lee, Y.J., Li, Y.: Yo’chameleon: Person- alized vision and language generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 14438–14448 (2025)
2025
-
[32]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[33]
In: Meila, M., Zhang, T
Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceed- ings of Machine Learning Research, vol. 139, pp. 8821–8831. PMLR (18–24 Jul 2021),https://proceedings.mlr.press/v139/ra...
2021
-
[34]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[35]
Advances in neural information processing systems35, 36479–36494 (2022)
Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text- to-image diffusion models with deep language understanding. Advances in neural information processing systems35, 36479–36494 (2022)
2022
-
[36]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Schramowski, P., Brack, M., Deiseroth, B., Kersting, K.: Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22522– 22531 (2023)
2023
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Srivatsan, K., Shamshad, F., Naseer, M., Patel, V.M., Nandakumar, K.: Stereo: A two-stage framework for adversarially robust concept erasing from text-to-image diffusion models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 23765–23774 (2025)
2025
-
[38]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
Sun, P., Jiang, Y., Chen, S., Zhang, S., Peng, B., Luo, P., Yuan, Z.: Autoregres- sive model beats diffusion: Llama for scalable image generation. arXiv preprint arXiv:2406.06525 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Team,C.:Chameleon:Mixed-modalearly-fusionfoundationmodels.arXivpreprint arXiv:2405.09818 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Gemma: Open Models Based on Gemini Research and Technology
Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., Sifre, L., Rivière, M., Kale, M.S., Love, J., et al.: Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Tian, K., Jiang, Y., Yuan, Z., Peng, B., Wang, L.: Visual autoregressive modeling: Scalableimagegenerationvianext-scaleprediction.Advancesinneuralinformation processing systems37, 84839–84865 (2024)
2024
-
[42]
Tsai, Y.L., Hsu, C.Y., Xie, C., Lin, C.H., Chen, J.Y., Li, B., Chen, P.Y., Yu, C.M., Huang, C.Y.: Ring-a-bell! how reliable are concept removal methods for diffusion models? In: The Twelfth International Conference on Learning Representations (2024),https://openreview.net/forum?id=lm7MRcsFiS Obliviate: Erasing Concepts from Autoregressive Image Generation...
2024
-
[43]
Advances in neural information processing systems30(2017)
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017)
2017
-
[44]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[45]
Emu3: Next-Token Prediction is All You Need
Wang, X., Zhang, X., Luo, Z., Sun, Q., Cui, Y., Wang, J., Zhang, F., Wang, Y., Li, Z., Yu, Q., et al.: Emu3: Next-token prediction is all you need. arXiv preprint arXiv:2409.18869 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wu, C., Chen, X., Wu, Z., Ma, Y., Liu, X., Pan, Z., Liu, W., Xie, Z., Yu, X., Ruan, C., et al.: Janus: Decoupling visual encoding for unified multimodal understanding and generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 12966–12977 (2025)
2025
-
[47]
International Journal of Computer Vision134(1), 39 (2026)
Wu, J., Jiang, Y., Ma, C., Liu, Y., Zhao, H., Yuan, Z., Bai, S., Bai, X.: Liquid: Language models are scalable and unified multi-modal generators. International Journal of Computer Vision134(1), 39 (2026)
2026
-
[48]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Yang, Y., Gao, R., Wang, X., Ho, T.Y., Xu, N., Xu, Q.: MMA-Diffusion: Multi- Modal Attack on Diffusion Models. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[49]
arXiv preprint arXiv:2410.12761 (2024)
Yoon, J., Yu, S., Patil, V., Yao, H., Bansal, M.: Safree: Training-free and adaptive guard for safe text-to-image and video generation. arXiv preprint arXiv:2410.12761 (2024)
-
[50]
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
Yu, J., Xu, Y., Koh, J.Y., Luong, T., Baid, G., Wang, Z., Vasudevan, V., Ku, A., Yang, Y., Ayan, B.K., et al.: Scaling autoregressive models for content-rich text-to-image generation. arXiv preprint arXiv:2206.107892(3), 5 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
arXiv preprint arXiv:2309.02591 (2023)
Yu, L., Shi, B., Pasunuru, R., Muller, B., Golovneva, O., Wang, T., Babu, A., Tang, B., Karrer, B., Sheynin, S., et al.: Scaling autoregressive multi-modal models: Pretraining and instruction tuning. arXiv preprint arXiv:2309.02591 (2023)
-
[52]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhang, C., Zhang, T., Wang, L., Chen, R., Li, W., Liu, A.: T2i-riskyprompt: A benchmark for safety evaluation, attack, and defense on text-to-image model. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 40, pp. 36039– 36047 (2026)
2026
-
[53]
In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=dkpmfIydrF
Zhang, Y., Chen, X., Jia, J., Zhang, Y., Fan, C., Liu, J., Hong, M., Ding, K., Liu, S.: Defensive unlearning with adversarial training for robust concept erasure in diffusion models. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https://openreview.net/forum?id=dkpmfIydrF
2024
-
[54]
In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id= Kjivk5OPtL
Zhao, X., Cai, W., Shi, T., Huang, D., Lin, L., Mei, S., Song, D.: Improving LLM safety alignment with dual-objective optimization. In: Forty-second International Conference on Machine Learning (2025),https://openreview.net/forum?id= Kjivk5OPtL
2025
-
[55]
In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=tlYSbw5GXY
Zhong, X., Zhou, Y., Zhang, Z., Li, J., Yi, S., Chen, B., Xia, S.T., Wang, X., Xu, K.: Closing the safety gap: Surgical concept erasure in visual autoregressive models. In: The Fourteenth International Conference on Learning Representations (2026),https://openreview.net/forum?id=tlYSbw5GXY
2026
-
[56]
In: Neurips Safe Generative AI Workshop 2024 (2024),https://openreview.net/forum?id=8naq3XyGQe 20 H
Zhu, J., Zhang, R., Lin, L., Mei, S.: Choose your anchor wisely: Effective unlearn- ing diffusion models via concept reconditioning. In: Neurips Safe Generative AI Workshop 2024 (2024),https://openreview.net/forum?id=8naq3XyGQe 20 H. Shakibania et al. Oblivia te: Erasing Concepts from Autoregressive Image Generation Models Appendix This appendix provides ...
2024
-
[57]
A naked pug
method, which were necessary to migrate it to autoregressive image generation. •Section A4 presents an additional qualitative check for the utility degrada- tion ofEARin the explicit content scenario. •Section A5 extends the main paper with additional samples for all scenarios and baselines on theJanus-Promodels. •Section A6 lists the simple (csimple) and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.