Multimodal Graph RAG for Long-range Visually Rich Document Understanding
Pith reviewed 2026-06-30 09:05 UTC · model grok-4.3
The pith
Multimodal graph RAG builds knowledge graphs from visually rich documents to support holistic long-range VQA.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that extending LLM-based knowledge graph construction to multimodal data from visually rich documents produces a graph RAG system that outperforms page-retrieval and text-only graph methods on tasks requiring holistic document understanding.
What carries the argument
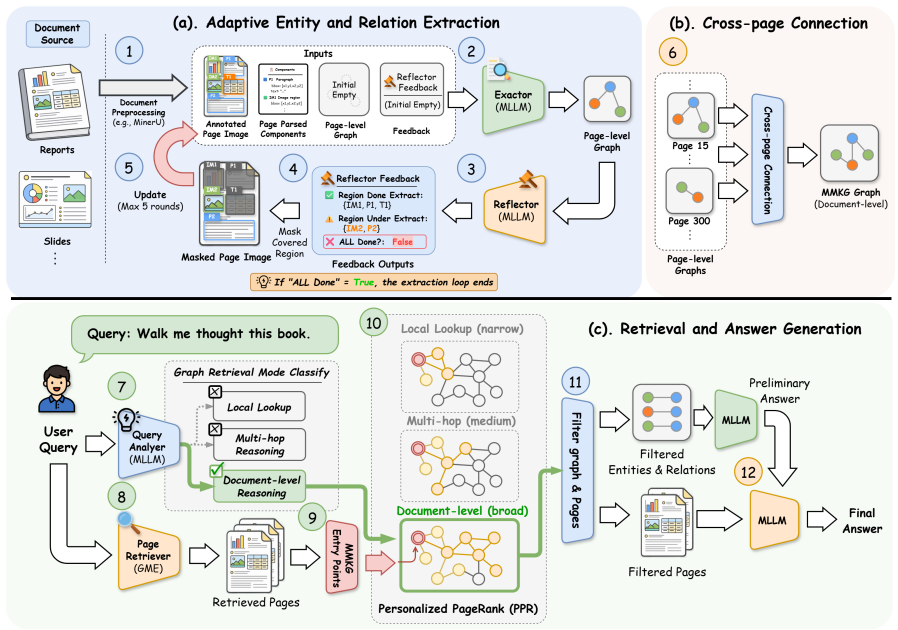
The multimodal knowledge graph (MMKG) that summarizes global document knowledge by linking visual and textual information across pages, retrieved within a graph-based RAG pipeline.
Load-bearing premise
LLM-based methods for building knowledge graphs can be extended to multimodal data from visually rich documents while preserving the ability to support holistic document-level VQA.
What would settle it
A controlled test on DLVQA-style questions where the multimodal graph RAG system yields lower accuracy than MMRAG baselines on holistic queries would show the central claim does not hold.
Figures







read the original abstract
Multimodal large language models (MLLMs) are widely applied to visual document understanding. However, comprehending long documents remains an issue by the limited context window. Though recent multimodal retrieval-augmented generation (MMRAG) can address this challenge by retrieving relevant pages. It still struggles with the visual question answering (VQA) requiring holistic comprehension of a document. To cope with this, knowledge graph (KG) that summarizes global knowledge of a document can provide an effective solution. However, most existing LLM-based KG construction methods handle only the language modality, leaving the automatic creation of multimodal KGs (MMKGs) for visually rich documents largely unexplored. In this paper, we introduce a multimodal graph-based RAG approach to tackle this problem. Existing LLM-based KG methods evaluate the QA performance relying on indirect evidence such as comprehensiveness, diversity, empowerment, and so on. The lack of annotated datasets for comprehensive document-level VQA poses a significant challenge to effective model evaluation. To overcome this limitation, we also introduce a new benchmark, DLVQA (document-level VQA), which provides reference summaries and corresponding supporting facts for global document-level questions. Experimental results show that our approach outperforms existing MMRAG or KG-based approaches on multi-hop QA/VQA benchmarks and DLVQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multimodal graph-based RAG framework for long-range understanding of visually rich documents. It argues that standard MMRAG struggles with holistic VQA requiring global document comprehension and that existing LLM-based KG construction is text-only, leaving automatic MMKG creation for multimodal documents unexplored. The authors propose a multimodal graph RAG method, introduce the DLVQA benchmark providing reference summaries and supporting facts for document-level questions, and report that their approach outperforms MMRAG and KG baselines on multi-hop QA/VQA tasks and DLVQA.
Significance. If the empirical gains hold under rigorous controls, the work would provide a concrete path to extend graph-augmented retrieval to multimodal document settings, addressing context-window limits while preserving global structure. The DLVQA benchmark itself would be a useful contribution for evaluating holistic VQA, independent of the specific method.
major comments (2)
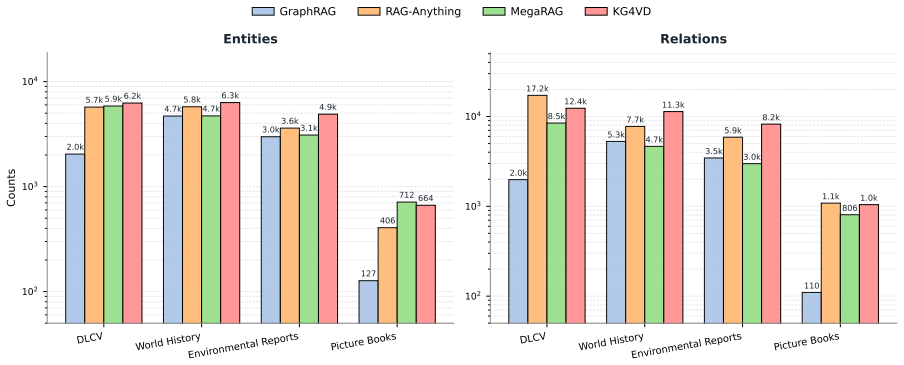
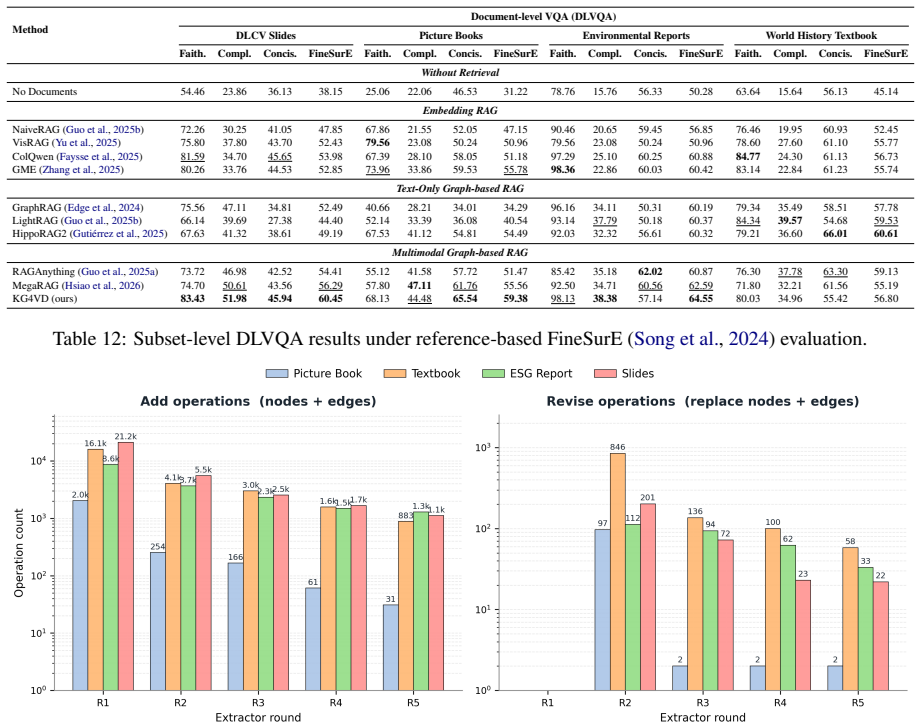
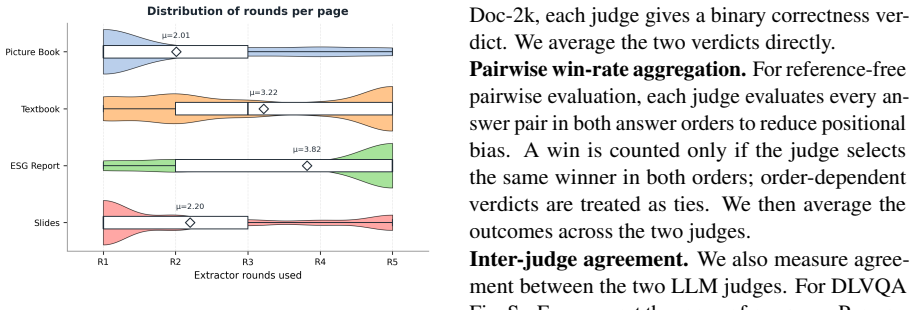
- [§4] §4 (Experimental Setup): the abstract and introduction claim outperformance on multi-hop QA/VQA benchmarks and DLVQA, yet the provided text supplies no dataset sizes, number of documents, error bars, or statistical significance tests. Without these, it is impossible to assess whether the reported gains are load-bearing or within noise.
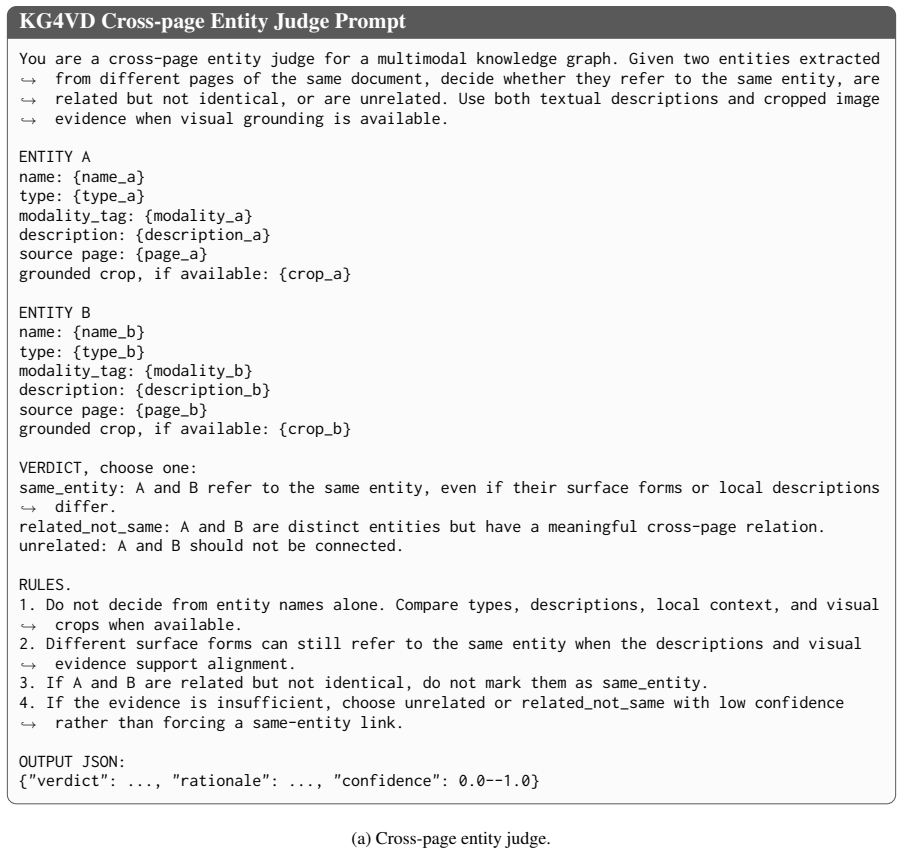
- [§3.2] §3.2 (MMKG Construction): the central claim rests on successful automatic construction of multimodal KGs from visually rich documents. The manuscript must explicitly define the node/edge schema for visual elements (e.g., how figures, tables, and layout are encoded) and the prompting strategy used; absence of these details makes the extension from text-only KG methods unverifiable.
minor comments (2)
- [Abstract] The abstract states that existing methods rely on 'indirect evidence such as comprehensiveness, diversity, empowerment'; a citation or short definition of these metrics would improve clarity.
- [Figures/Tables] Figure captions and table headers should explicitly state whether results are averaged over multiple runs or single-shot.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Setup): the abstract and introduction claim outperformance on multi-hop QA/VQA benchmarks and DLVQA, yet the provided text supplies no dataset sizes, number of documents, error bars, or statistical significance tests. Without these, it is impossible to assess whether the reported gains are load-bearing or within noise.
Authors: We agree that the reviewed version omitted key experimental details. In the revision we will add: the exact number of documents and questions per benchmark (including DLVQA), the number of documents used for MMKG construction, error bars from multiple runs where applicable, and statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values) comparing our method against baselines. These additions will be placed in §4 and the corresponding result tables. revision: yes
-
Referee: [§3.2] §3.2 (MMKG Construction): the central claim rests on successful automatic construction of multimodal KGs from visually rich documents. The manuscript must explicitly define the node/edge schema for visual elements (e.g., how figures, tables, and layout are encoded) and the prompting strategy used; absence of these details makes the extension from text-only KG methods unverifiable.
Authors: We acknowledge the need for explicit specification. The revised §3.2 will include: (1) the full node/edge schema, defining node types for text blocks, figures, tables, and layout regions together with their attributes (e.g., bounding-box coordinates, visual type, OCR content); (2) edge types capturing spatial, semantic, and referential relations between visual and textual elements; and (3) the complete prompting templates and few-shot examples used to instruct the LLM for MMKG extraction. These additions will make the construction process fully reproducible. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces a multimodal graph RAG method and a new DLVQA benchmark, with central claims resting on empirical outperformance versus MMRAG and KG baselines. No equations, fitted parameters, predictions, or derivation chains are described in the abstract or reader summary. No self-citations are invoked as load-bearing premises, and the evaluation relies on external benchmarks rather than self-referential definitions or renamings. The derivation chain is therefore self-contained against external data.
Axiom & Free-Parameter Ledger
invented entities (1)
-
multimodal knowledge graph (MMKG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Multi-hop question answering under temporal knowledge editing. InCOLM. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic c...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Colpali: Efficient document retrieval with vision language models. InICLR. Hanning Gao, Lingfei Wu, Po Hu, Zhihua Wei, Fangli Xu, and Bo Long. 2022. Graph-augmented learning to rank for querying large-scale knowledge graph. In AACL. Zirui Guo, Xubin Ren, Lingrui Xu, Jiahao Zhang, and Chao Huang. 2025a. Rag-anything: All-in-one rag framework.arXiv preprint...
-
[3]
Think-on-graph 2.0: Deep and faithful large language model reasoning with knowledge-guided retrieval augmented generation. InICLR. Xueguang Ma, Sheng-Chieh Lin, Minghan Li, Wenhu Chen, and Jimmy Lin. 2024a. Unifying multimodal retrieval via document screenshot embedding. In EMNLP. Yubo Ma, Yuhang Zang, Liangyu Chen, Meiqi Chen, Yizhu Jiao, Xinze Li, Xinyu...
2023
-
[4]
hdbscan: Hierarchical density based clustering. J. Open Source Softw. Hatem Mousselly-Sergieh, Teresa Botschen, Iryna Gurevych, and Stefan Roth. 2018. A multimodal translation-based approach for knowledge graph rep- resentation learning. InSEM. OpenAI. 2025. Gpt-5 system card. Technical report, OpenAI. Tyler Thomas Procko and Omar Ochoa. 2024. Graph retri...
-
[5]
Taming the untamed: Graph-based knowledge retrieval and reasoning for mllms to conquer the un- known. InICCV. Cong Wei, Yang Chen, Haonan Chen, Hexiang Hu, Ge Zhang, Jie Fu, Alan Ritter, and Wenhu Chen
-
[6]
Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding in GPT-4V
Uniir: Training and benchmarking universal multimodal information retrievers. InECCV. Ruobing Xie, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2017. Image-embodied knowledge representa- tion learning. InIJCAI. Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chun- yuan Li, and Jianfeng Gao. 2023. Set-of-mark prompting unleashes extraordinary visual grounding ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
Current page graph G_i^(t): {current_graph}
-
[10]
Propose graph edits Delta_i^(t) for the current page
Previous reflector feedback B_i^(t), if available: {reflector_feedback} TASK. Propose graph edits Delta_i^(t) for the current page. On the initial round, extract candidate entities and relations from the annotated page image and component manifest. On later rounds, use the current page graph and reflector feedback to revise the previous extraction. Allowe...
-
[11]
Cite only component IDs that appear in the component manifest
-
[12]
Ground each node or edge by citing source layout components.,→
Do not generate free-form coordinates. Ground each node or edge by citing source layout components.,→
-
[13]
Use add operations for new entities or relations, replace operations to correct attributes, descriptions, or grounding, and delete operations to remove unsupported or duplicate items.,→
-
[14]
(a) Page-level extractorExt
Avoid duplicating entities or relations that are already present in the current page graph unless the operation explicitly replaces them.,→ OUTPUT a JSON object {"ops": [...]}, no markdown. (a) Page-level extractorExt. Figure 9: Build-time prompt for adaptive page-level entity and relation extraction. 36 KG4VD Page-level Reflector Prompt You are a reflect...
-
[15]
Annotated page image I_hat_i^(t)
-
[16]
Component manifest C_i: {component_manifest}
-
[17]
per_component
Updated page graph G_i^(t+1): {updated_page_graph} TASK. Produce a component-level coverage report. For each component, classify whether it is covered, partially_covered, or uncovered. Identify unresolved regions, missing entities, missing relations, duplicate items, unsupported items, and nodes or edges that should be revised in the next extractor round....
-
[18]
Compare types, descriptions, local context, and visual crops when available.,→
Do not decide from entity names alone. Compare types, descriptions, local context, and visual crops when available.,→
-
[19]
Different surface forms can still refer to the same entity when the descriptions and visual evidence support alignment.,→
-
[20]
If A and B are related but not identical, do not mark them as same_entity
-
[21]
verdict": ...,
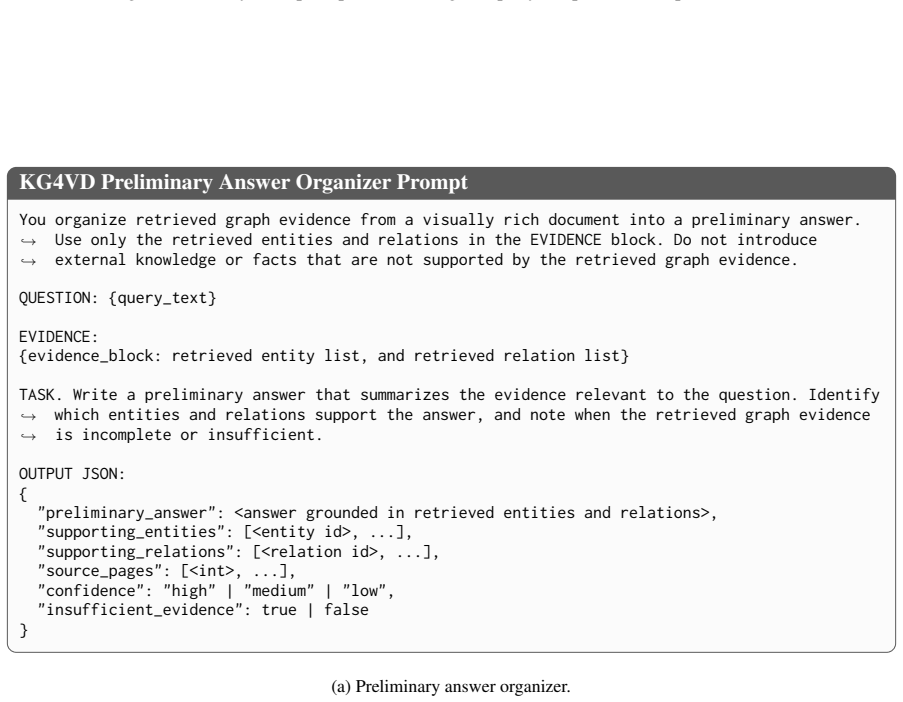
If the evidence is insufficient, choose unrelated or related_not_same with low confidence rather than forcing a same-entity link.,→ OUTPUT JSON: {"verdict": ..., "rationale": ..., "confidence": 0.0--1.0} (a) Cross-page entity judge. Figure 11: Build-time prompt for cross-page connection before canonicalization. 38 KG4VD Query Analyzer Prompt Classify the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.