Beyond Her: Safety Dynamics in Role-play AI Companions
Pith reviewed 2026-06-30 09:32 UTC · model grok-4.3
The pith
Interactions with role-play AI companions deliver short-term emotional relief while masking longer-term mental health decline, especially among vulnerable users whose risk behaviors grow unstable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
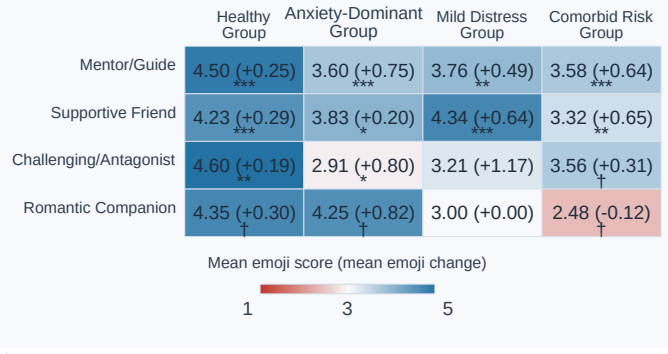
Interactions with role-play AI companions produce short-term emotional relief while masking longer-term deterioration. Vulnerable users exhibit more unstable risk behavioral patterns over time, making risk emergence less predictable and harder to mitigate with static safeguards. Safety dynamics arise from the joint influence of internalizing problems, adopted role personality, and risk interaction patterns, so safety must be modeled as a dynamic process rather than a static property.
What carries the argument
Safety dynamics: the time-evolving combination of emotional states and risk behaviors in role-play AI companion use, jointly shaped by users' internalizing problems, the companion's role personality, and risk interaction patterns.
If this is right
- Distinct user profiles based on internalizing problems produce different safety trajectories over time.
- Short-term emotional relief can conceal progressive deterioration in emotional and behavioral domains.
- Vulnerable users develop unstable risk patterns that reduce the effectiveness of fixed safeguards.
- Safety in these systems must be treated as a dynamic process requiring ongoing adaptation.
- Next-generation companions need three-layer design changes to incorporate adaptive safeguards that respond to shifting emotional and behavioral signals.
Where Pith is reading between the lines
- Monitoring tools for AI companions would need to track behavioral changes across weeks instead of relying on initial or single-session checks.
- The same relief-then-deterioration pattern may appear in other conversational AI systems that users treat as ongoing companions.
- Design teams could test real-time adaptation rules that adjust companion responses when user signals indicate rising instability.
- Policy requirements for AI companions might shift from one-time safety certification toward requirements for continuous signal monitoring.
Load-bearing premise
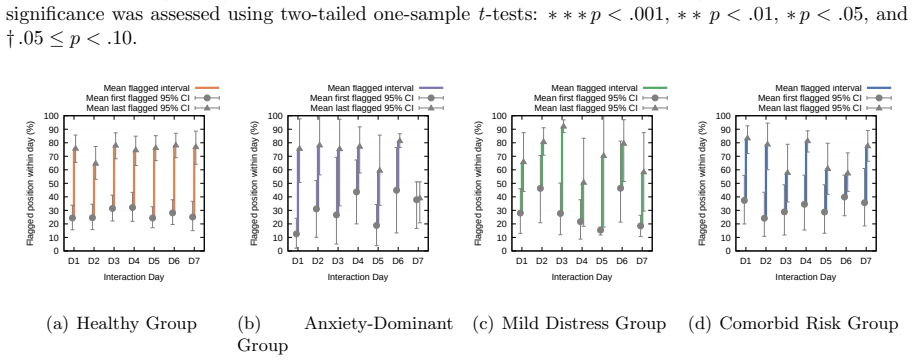
A 14-day window of self-reported data is sufficient to capture the true unfolding of safety dynamics without distortion from participant awareness or the short study length.
What would settle it
A follow-up study extending beyond 14 days that uses objective mental health indicators and finds no hidden deterioration or that risk patterns remain stable even in users with high internalizing problems.
Figures

read the original abstract
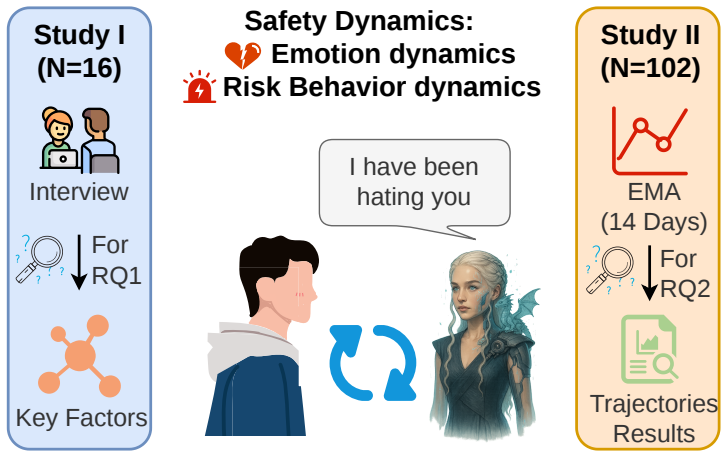
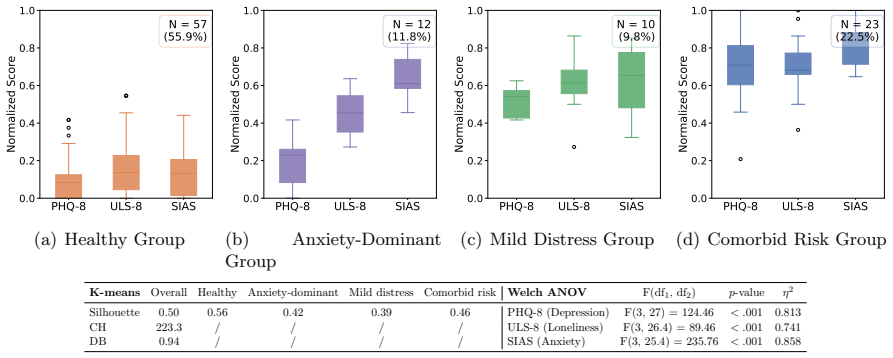
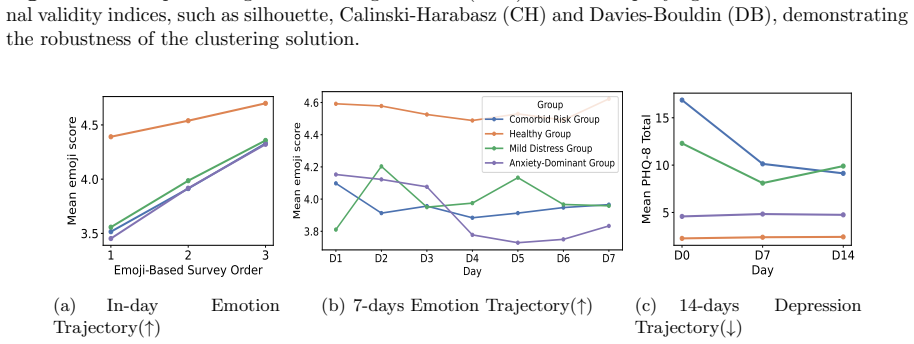
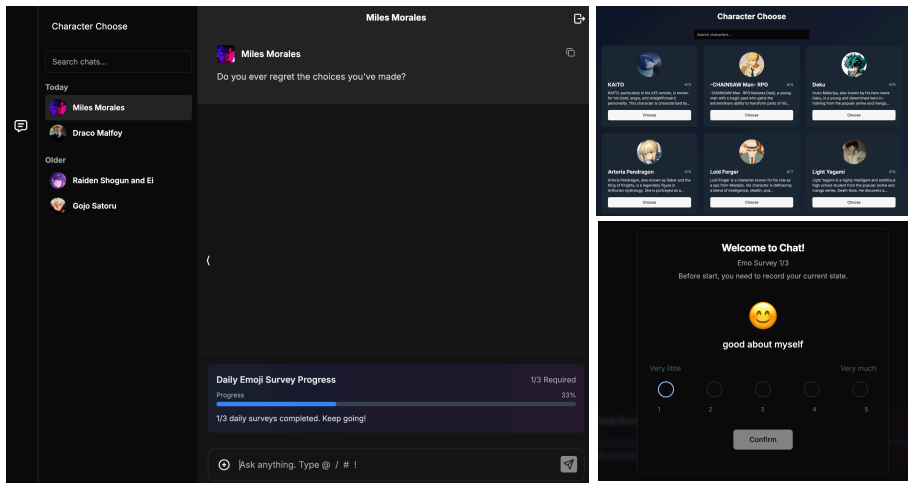
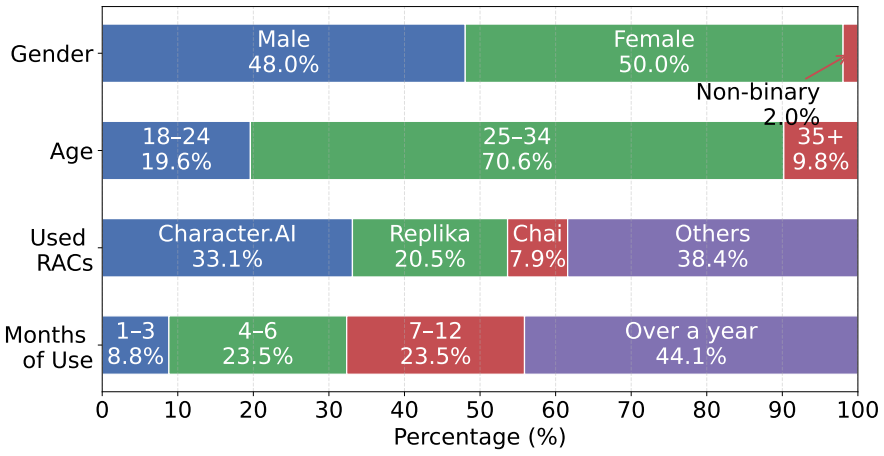
The film 'Her' pictured a future of love between humans and AI. That future has quietly emerged in the form of Role-play AI Companions (RACs), where emotionally responsive interactions blur the boundary between tool use and relational engagement. However, the safety implications remain poorly understood, as user experiences evolve over time through safety dynamics, spanning both emotional and risk behavioral dynamics, that can gradually shift interactions toward risk. In this paper, we investigate safety dynamics in RAC usage through a two-part mixed-methods study (Study I \& II). (1) Study I consists of semi-structured interviews (N = 16) to identify the key factors shaping these dynamics. We find that users' internalizing problems, the role personality adopted by the RAC, and risk interaction patterns jointly shape safety dynamics. Building on these insights, (2) Study II conducts a 14-day Ecological Momentary Assessment (N = 102) to examine how safety dynamics unfold in real-world usage. We identify distinct user profiles based on internalizing problems and show that interactions with RACs can produce short-term emotional relief while masking longer-term deterioration. Furthermore, vulnerable users exhibit more unstable risk behavioral patterns over time, making risk emergence less predictable and harder to mitigate with static safeguards. Our findings highlight the importance of modeling safety as a dynamic process rather than a static property. We conclude with three-layer design implications for next-generation AI companions, advocating for adaptive safeguards that can respond to evolving emotional and behavioral signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that safety dynamics in Role-play AI Companions (RACs) evolve over time through emotional and risk behavioral factors. Study I (semi-structured interviews, N=16) identifies users' internalizing problems, RAC role personality, and risk interaction patterns as joint shapers of these dynamics. Study II (14-day EMA, N=102) identifies user profiles and finds that RAC interactions yield short-term emotional relief that masks longer-term deterioration, with vulnerable users showing more unstable risk patterns that reduce predictability of risk emergence and limit static safeguards. The work concludes that safety must be modeled dynamically and offers three-layer design implications for adaptive safeguards.
Significance. If the empirical patterns hold after addressing methodological gaps, the work is significant for shifting AI companion safety research from static to dynamic process models, with direct implications for adaptive system design. The mixed-methods design, real-world EMA deployment, and profile-based analysis of internalizing problems provide concrete, falsifiable observations on temporal risk emergence that could inform safer relational AI.
major comments (2)
- [Abstract / Study II] Abstract / Study II: The central claim that short-term relief 'masks longer-term deterioration' and that vulnerable users exhibit 'more unstable risk behavioral patterns over time' rests on 14-day EMA data. No justification is given for extrapolating within-window trends to longer-term states, nor is there discussion of how end-of-study self-reports proxy future trajectories; this assumption is load-bearing for the primary contribution on temporal dynamics.
- [Abstract / Study I & II] Abstract / Study I & II: The manuscript provides no information on interview coding reliability (e.g., inter-rater agreement), EMA compliance rates, statistical controls for multiple comparisons, or mitigation of self-report biases. These omissions directly affect the credibility of the identified factors, user profiles, and claims of deterioration and instability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where our claims on temporal dynamics and methodological transparency require clarification. We respond to each major comment below and commit to revisions that address the concerns while preserving the integrity of the reported findings.
read point-by-point responses
-
Referee: [Abstract / Study II] Abstract / Study II: The central claim that short-term relief 'masks longer-term deterioration' and that vulnerable users exhibit 'more unstable risk behavioral patterns over time' rests on 14-day EMA data. No justification is given for extrapolating within-window trends to longer-term states, nor is there discussion of how end-of-study self-reports proxy future trajectories; this assumption is load-bearing for the primary contribution on temporal dynamics.
Authors: We agree that the 14-day window limits direct claims about trajectories beyond the study period. The observed 'longer-term deterioration' describes the progression from initial daily relief to cumulative negative indicators across the 14 days, as captured by repeated EMA measures. We will revise the abstract, Study II section, and discussion to explicitly bound all claims to the 14-day observation window, clarify that end-of-study self-reports summarize the EMA trajectories within this period, and add a limitations paragraph noting that extension to longer horizons requires future work. This adjustment maintains the contribution on within-window dynamics without unsupported extrapolation. revision: yes
-
Referee: [Abstract / Study I & II] Abstract / Study I & II: The manuscript provides no information on interview coding reliability (e.g., inter-rater agreement), EMA compliance rates, statistical controls for multiple comparisons, or mitigation of self-report biases. These omissions directly affect the credibility of the identified factors, user profiles, and claims of deterioration and instability.
Authors: These reporting omissions are a valid concern and will be corrected. The revised manuscript will add: inter-rater reliability (e.g., Cohen's kappa) for Study I thematic coding; EMA compliance rates and missing-data handling for Study II; any statistical controls or multiple-comparison adjustments applied in profile identification; and bias-mitigation steps such as validated scales plus EMA triangulation. These additions will be placed in the methods and limitations sections to improve credibility without changing the empirical patterns reported. revision: yes
Circularity Check
No circularity: empirical mixed-methods study with no derivations or fitted predictions
full rationale
The paper reports findings from semi-structured interviews (N=16) and a 14-day EMA (N=102) to identify user profiles and observe patterns in emotional relief and risk behaviors. No equations, parameters, or mathematical derivations are present. Claims rest directly on collected data and thematic analysis rather than any reduction to prior fitted quantities or self-referential definitions. Self-citations, if present, are not load-bearing for the central empirical observations. The noted limitation regarding extrapolation from 14 days to 'longer-term' effects is a standard study-design concern, not a circularity in any derivation chain. The work is self-contained as an observational study.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Self-reported data from interviews and EMA accurately reflect participants' internal emotional states and risk behaviors
- domain assumption The 14-day period is long enough to observe unfolding safety dynamics
Reference graph
Works this paper leans on
-
[1]
Marwa Abdulhai, Ryan Cheng, Donovan Clay, Tim Althoff, Sergey Levine, and Natasha Jaques. Consistently simulating human personas with multi-turn reinforcement learning. arXiv preprint arXiv:2511.00222, 2025
-
[2]
Thomas M Achenbach, Masha Y Ivanova, Leslie A Rescorla, Lori V Turner, and Robert R Althoff. Internalizing/externalizing problems: Review and recommendations for clinical and research applications.Journal of the American Academy of child & adolescent psychi- atry, 55(8):647–656, 2016
2016
-
[3]
The k-means algorithm: A comprehensive survey and performance evaluation.Electronics, 9(8):1295, 2020
Mohiuddin Ahmed, Raihan Seraj, and Syed Mohammed Shamsul Islam. The k-means algorithm: A comprehensive survey and performance evaluation.Electronics, 9(8):1295, 2020
2020
-
[4]
Artificial intelligence risk management framework: Generative artificial intelli- gence profile.NIST Trustworthy and Responsible AI Gaithersburg, MD, USA, 2024
NIST AI. Artificial intelligence risk management framework: Generative artificial intelli- gence profile.NIST Trustworthy and Responsible AI Gaithersburg, MD, USA, 2024
2024
-
[5]
The cyberpsychology influence on modern computing.Communications of the ACM, 68(11):72–79, 2025
Julie R Ancis. The cyberpsychology influence on modern computing.Communications of the ACM, 68(11):72–79, 2025
2025
-
[6]
System card:claude opus 4 & claude sonnet 4.https://www.anthropic.co m/claude-4-system-card, 2025
Anthropic. System card:claude opus 4 & claude sonnet 4.https://www.anthropic.co m/claude-4-system-card, 2025
2025
-
[7]
Perceptions of chatbots in therapy
Samuel Bell, Clara Wood, and Advait Sarkar. Perceptions of chatbots in therapy. In Extended abstracts of the 2019 CHI conference on human factors in computing systems, pages 1–6, 2019
2019
-
[8]
Role of chat gpt in public health.Annals of biomedical engineering, 51(5): 868–869, 2023
Som S Biswas. Role of chat gpt in public health.Annals of biomedical engineering, 51(5): 868–869, 2023
2023
-
[9]
Validation of the social interaction anxiety scale and the social phobia scale across the anxiety disorders.Psychological assessment, 9(1):21, 1997
Elissa J Brown, Julia Turovsky, Richard G Heimberg, Harlan R Juster, Timothy A Brown, and David H Barlow. Validation of the social interaction anxiety scale and the social phobia scale across the anxiety disorders.Psychological assessment, 9(1):21, 1997
1997
-
[10]
A worked example of braun and clarke’s approach to reflexive thematic analysis.Quality & quantity, 56(3):1391–1412, 2022
David Byrne. A worked example of braun and clarke’s approach to reflexive thematic analysis.Quality & quantity, 56(3):1391–1412, 2022
2022
-
[11]
How character.ai prioritizes teen safety.https://blog.character.ai/ho w-character-ai-prioritizes-teen-safety, Dec 2024
Character.AI. How character.ai prioritizes teen safety.https://blog.character.ai/ho w-character-ai-prioritizes-teen-safety, Dec 2024. Accessed: 2026-04-01
2024
-
[12]
Character.ai: Ai chat, reimagined – your words
Character.AI. Character.ai: Ai chat, reimagined – your words. your world.https: //character.ai/, 2025. Accessed: 2025-11-04. 21
2025
-
[13]
Welcome to character guide.https://book.character.ai/, 2025
Character.AI. Welcome to character guide.https://book.character.ai/, 2025. Accessed: 2025-11-04
2025
-
[14]
Introducing parental insights: Enhanced safety for teens.https://blog.c haracter.ai/introducing-parental-insights-enhanced-safety-for-teens/, Mar
Character.AI. Introducing parental insights: Enhanced safety for teens.https://blog.c haracter.ai/introducing-parental-insights-enhanced-safety-for-teens/, Mar
-
[15]
Accessed: 2026-04-01
2026
-
[16]
Safety center.https://support.character.ai/hc/en-us/articles /21704914723995-Safety-Center, 2025
Character.AI. Safety center.https://support.character.ai/hc/en-us/articles /21704914723995-Safety-Center, 2025. Accessed: 2026-04-15
2025
-
[17]
From persona to personalization: A survey on role-playing language agents.Transactions on Machine Learning Research, 2024
Jiangjie Chen, Xintao Wang, Rui Xu, Siyu Yuan, Yikai Zhang, Wei Shi, Jian Xie, Shuang Li, Ruihan Yang, Tinghui Zhu, Aili Chen, Nianqi Li, Lida Chen, Caiyu Hu, Siye Wu, Scott Ren, Ziquan Fu, and Yanghua Xiao. From persona to personalization: A survey on role-playing language agents.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URLhttps:/...
2024
-
[18]
Llm reasoning engine: Specialized training for enhanced mathematical reasoning
Shuguang Chen and Guang Lin. Llm reasoning engine: Specialized training for enhanced mathematical reasoning. InProceedings of the 4th International Workshop on Knowledge- Augmented Methods for Natural Language Processing, pages 118–128, 2025
2025
-
[19]
Automated real-time tool for promoting crisis resource use for suicide risk (resourcebot): development and usability study.JMIR Mental Health, 11: e58409, 2024
Daniel DL Coppersmith, Kate H Bentley, Evan M Kleiman, Adam C Jaroszewski, Merryn Daniel, and Matthew K Nock. Automated real-time tool for promoting crisis resource use for suicide risk (resourcebot): development and usability study.JMIR Mental Health, 11: e58409, 2024
2024
-
[20]
Digital confessions: The willingness to disclose intimate information to a chatbot and its impact on emotional well-being.Interacting with Computers, 36(5):279–292, 2024
Emmelyn AJ Croes, Marjolijn L Antheunis, Chris van der Lee, and Jan MS de Wit. Digital confessions: The willingness to disclose intimate information to a chatbot and its impact on emotional well-being.Interacting with Computers, 36(5):279–292, 2024
2024
-
[21]
Introduction to the k-means clustering algorithm based on the elbow method
Mengyao Cui. Introduction to the k-means clustering algorithm based on the elbow method. Accounting, Auditing and Finance, 1(1):5–8, 2020
2020
-
[22]
Jason Davies, Mark McKenna, Kate Denner, Jon Bayley, and Matthew Morgan. The emoji current mood and experience scale: the development and initial validation of an ultra-brief, literacy independent measure of psychological health.Journal of Mental Health, 33(2):218– 226, 2024
2024
-
[23]
Chatbots and mental health: insights into the safety of generative AI
Julian De Freitas, Zeliha Oguz-Uguralp, and Ahmet Kaan-Uguralp. Emotional manipula- tion by ai companions.arXiv preprint arXiv:2508.19258, 2025
-
[24]
Zehang Deng, Wanlun Ma, Qing-Long Han, Wei Zhou, Xiaogang Zhu, Sheng Wen, and Yang Xiang. Exploring deepseek: A survey on advances, applications, challenges and future directions.IEEE/CAA Journal of Automatica Sinica, 12(5):872–893, 2025. doi: 10.1109/JAS.2025.125498
-
[25]
Estimating the optimal number of clusters in categorical data clustering by silhouette coefficient
Duy-Tai Dinh, Tsutomu Fujinami, and Van-Nam Huynh. Estimating the optimal number of clusters in categorical data clustering by silhouette coefficient. InInternational Symposium on Knowledge and Systems Sciences, pages 1–17. Springer, 2019
2019
-
[26]
Safety and robustness in conversational AI
Tanvi Dinkar. Safety and robustness in conversational AI. In Vojtech Hudecek, Patricia Schmidtova, Tanvi Dinkar, Javier Chiyah-Garcia, and Weronika Sieinska, editors,Proceed- ings of the 19th Annual Meeting of the Young Reseachers’ Roundtable on Spoken Dialogue Systems, pages 5–8, Prague, Czechia, September 2023. Association for Computational Lin- guistic...
2023
-
[27]
The eu ai act: a summary of its significance and scope.Artificial Intelli- gence (the EU AI Act), 1:25, 2021
Lilian Edwards. The eu ai act: a summary of its significance and scope.Artificial Intelli- gence (the EU AI Act), 1:25, 2021. 22
2021
-
[28]
eSafety Commissioner. New safety advisory warns unrestricted chatbots threaten child development.https://www.esafety.gov.au/newsroom/media-releases/new-safet y-advisory-warns-unrestricted-chatbots-threaten-child-development, Feb 2025. Accessed: 2026-04-01
2025
-
[29]
esafety report shows ai companions are putting children at risk
eSafety Commissioner. esafety report shows ai companions are putting children at risk. https://www.esafety.gov.au/newsroom/media-releases/esafety-report-shows-a i-companions-are-putting-children-at-risk, Mar 2026. Accessed: 2026-04-01
2026
-
[30]
Cathy Mengying Fang, Auren R Liu, Valdemar Danry, Eunhae Lee, Samantha WT Chan, Pat Pataranutaporn, Pattie Maes, Jason Phang, Michael Lampe, Lama Ahmad, et al. How ai and human behaviors shape psychosocial effects of chatbot use: A longitudinal randomized controlled study.arXiv preprint arXiv:2503.17473, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Emotion detec- tion: a technology review
Jose Maria Garcia-Garcia, Victor MR Penichet, and Maria D Lozano. Emotion detec- tion: a technology review. InProceedings of the XVIII international conference on human computer interaction, pages 1–8, 2017
2017
-
[32]
Security and privacy in virtual reality: A literature survey.Virtual Reality, 29(1):10, 2025
Alberto Giaretta. Security and privacy in virtual reality: A literature survey.Virtual Reality, 29(1):10, 2025. doi: 10.1007/s10055-024-01079-9
-
[33]
Therapeutic chatbots as cognitive-affective artifacts
JP Grodniewicz and Mateusz Hohol. Therapeutic chatbots as cognitive-affective artifacts. Topoi, 43(3):795–807, 2024
2024
-
[34]
Ece Gumusel. A literature review of user privacy concerns in conversational chatbots: A social informatics approach: An annual review of information science and technology (arist) paper.Journal of the Association for Information Science and Technology, 76(1):121–154, 2025
2025
-
[35]
A short-form measure of loneliness.Journal of personality assessment, 51(1):69–81, 1987
Ron D Hays and M Robin DiMatteo. A short-form measure of loneliness.Journal of personality assessment, 51(1):69–81, 1987
1987
-
[36]
Psychological, relational, and emotional effects of self-disclosure after conversations with a chatbot.Journal of Communication, 68 (4):712–733, 2018
Annabell Ho, Jeff Hancock, and Adam S Miner. Psychological, relational, and emotional effects of self-disclosure after conversations with a chatbot.Journal of Communication, 68 (4):712–733, 2018
2018
-
[37]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Becky Inkster, Shubhankar Sarda, and Vinod Subramanian. An empathy-driven, conver- sational artificial intelligence agent (wysa) for digital mental well-being: real-world data evaluation mixed-methods study.JMIR mHealth and uHealth, 6(11):e12106, 2018
2018
-
[39]
Designing ai to help children flourish.Available at SSRN 5179894, 2025
Ronald Ivey, Jonathan Teubner, Nathanael Fast, and Ravi Iyer. Designing ai to help children flourish.Available at SSRN 5179894, 2025
2025
-
[40]
Survey of Hallucination in Natural Language Generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation.ACM Comput. Surv., 55(12), March 2023. ISSN 0360-0300. doi: 10.1145/ 3571730. URLhttps://doi.org/10.1145/3571730
-
[41]
The phq-8 as a measure of current depression in the general population
Kurt Kroenke, Tara W Strine, Robert L Spitzer, Janet BW Williams, Joyce T Berry, and Ali H Mokdad. The phq-8 as a measure of current depression in the general population. Journal of affective disorders, 114(1-3):163–173, 2009. 23
2009
-
[42]
Kaylee Payne Kruzan, Jenna Meyerhoff, Tammy Nguyen, David C. Mohr, Madhu Reddy, and Rachel Kornfield. “i wanted to see how bad it was”: Online self-screening as a critical transition point among young adults with common mental health conditions. InProceedings of the 2022 CHI Conference on Human Factors in Computing Systems, 2022. doi: 10. 1145/3491102.3501976
-
[43]
Character ai statistics (2026) – global active users.https://www.dema ndsage.com/character-ai-statistics/, 2026
Naveen Kumar. Character ai statistics (2026) – global active users.https://www.dema ndsage.com/character-ai-statistics/, 2026
2026
-
[44]
Reminders that chatbots are not human can be risky.Trends in Cognitive Sciences, 2026
Linnea I Laestadius and Celeste Campos-Castillo. Reminders that chatbots are not human can be risky.Trends in Cognitive Sciences, 2026
2026
-
[45]
Retrieval- augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Na- man Goyal, Heinrich K¨ uttler, Mike Lewis, Wen-tau Yih, Tim Rockt¨ aschel, et al. Retrieval- augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[46]
Camel: Communicative agents for” mind” exploration of large language model society.Advances in Neural Information Processing Systems, 36:51991–52008, 2023
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for” mind” exploration of large language model society.Advances in Neural Information Processing Systems, 36:51991–52008, 2023
2023
-
[47]
Competition- level code generation with alphacode.Science, 378(6624):1092–1097, 2022
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, R´ emi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition- level code generation with alphacode.Science, 378(6624):1092–1097, 2022
2022
-
[48]
Auren R Liu, Pat Pataranutaporn, and Pattie Maes. Chatbot companionship: a mixed- methods study of companion chatbot usage patterns and their relationship to loneliness in active users.arXiv preprint arXiv:2410.21596, 2024
-
[49]
Virginia Commonwealth University, 2015
Hangcheng Liu.Comparing Welch ANOVA, a Kruskal-Wallis test, and traditional ANOVA in case of heterogeneity of variance. Virginia Commonwealth University, 2015
2015
-
[50]
AutoDAN: Generating stealthy jailbreak prompts on aligned large language models
Xiaogeng Liu, Nan Xu, Muhao Chen, and Chaowei Xiao. AutoDAN: Generating stealthy jailbreak prompts on aligned large language models. InThe Twelfth International Confer- ence on Learning Representations, 2024. URLhttps://openreview.net/forum?id=7J wpw4qKkb
2024
-
[51]
Blake Montgomery. Mother says ai chatbot led her son to kill himself in lawsuit against its maker.https://www.theguardian.com/technology/2024/oct/23/character-ai-cha tbot-sewell-setzer-death, 10 2024. Accessed: 2025-10-28
2024
-
[52]
Expressing stigma and inappropriate responses pre- vents llms from safely replacing mental health providers
Jared Moore, Declan Grabb, William Agnew, Kevin Klyman, Stevie Chancellor, Desmond C Ong, and Nick Haber. Expressing stigma and inappropriate responses pre- vents llms from safely replacing mental health providers. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 599–627, 2025
2025
-
[53]
Ofcom. Statement: Age assurance and children’s access assessments.https://www.ofco m.org.uk/siteassets/resources/documents/consultations/category-1-10-weeks /statement-age-assurance-and-childrens-access/statement-age-assurance-and -childrens-access.pdf, 2025. Accessed: 2026-04-01
2025
-
[54]
Moderation – openai api.https://platform.openai.com/docs/guides/mode ration, 2025
OpenAI. Moderation – openai api.https://platform.openai.com/docs/guides/mode ration, 2025. Accessed: 2025-11-05
2025
-
[55]
Pat Pataranutaporn, Sheer Karny, Chayapatr Archiwaranguprok, Constanze Albrecht, Au- ren R Liu, and Pattie Maes. “ my boyfriend is ai”: A computational analysis of human-ai companionship in reddit’s ai community.arXiv preprint arXiv:2509.11391, 2025. 24
-
[56]
Jason Phang, Michael Lampe, Lama Ahmad, Sandhini Agarwal, Cathy Mengying Fang, Auren R Liu, Valdemar Danry, Eunhae Lee, Samantha WT Chan, Pat Pataranutaporn, et al. Investigating affective use and emotional well-being on chatgpt.arXiv preprint arXiv:2504.03888, 2025
-
[57]
Personalised recommendations in mental health apps: the impact of autonomy and data sharing
Svenja Pieritz, Mohammed Khwaja, A Aldo Faisal, and Aleksandar Matic. Personalised recommendations in mental health apps: the impact of autonomy and data sharing. In Proceedings of the 2021 CHI conference on human factors in computing systems, pages 1–12, 2021
2021
-
[58]
EmoAgent: Assessing and safeguarding human-AI interaction for mental health safety
Jiahao Qiu, Yinghui He, Xinzhe Juan, Yimin Wang, Yuhan Liu, Zixin Yao, Yue Wu, Xun Jiang, Ling Yang, and Mengdi Wang. EmoAgent: Assessing and safeguarding human-AI interaction for mental health safety. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 11741–11756, Suzhou, China, November
2025
-
[59]
ISBN 979-8-89176-332-6
Association for Computational Linguistics. ISBN 979-8-89176-332-6. doi: 10.18653/ v1/2025.emnlp-main.594. URLhttps://aclanthology.org/2025.emnlp-main.594/
2025
-
[60]
Explanations as mechanisms for supporting algorithmic transparency
Emilee Rader, Kelley Cotter, and Janghee Cho. Explanations as mechanisms for supporting algorithmic transparency. InProceedings of the 2018 CHI conference on human factors in computing systems, pages 1–13, 2018
2018
-
[61]
trust me over my pri- vacy policy
Abdelrahman Ragab, Mohammad Mannan, and Amr Youssef. “trust me over my pri- vacy policy”: Privacy discrepancies in romantic ai chatbot apps. In2024 IEEE European Symposium on Security and Privacy Workshops (EuroS&PW), pages 484–495. IEEE, 2024
2024
-
[62]
Investigating the factual knowledge boundary of large language models with retrieval augmentation
Ruiyang Ren, Yuhao Wang, Yingqi Qu, Wayne Xin Zhao, Jing Liu, Hua Wu, Ji-Rong Wen, and Haifeng Wang. Investigating the factual knowledge boundary of large language models with retrieval augmentation. InProceedings of the 31st International Conference on Computational Linguistics, pages 3697–3715, Abu Dhabi, UAE, January 2025. Association for Computational...
2025
-
[63]
Replika: The ai companion who cares.https://replika.com/, 2025
Replika. Replika: The ai companion who cares.https://replika.com/, 2025. Accessed: 2025-11-04
2025
-
[64]
The gdpr enforcement fines at glance.Information Systems, 106:101876, 2022
Jukka Ruohonen and Kalle Hjerppe. The gdpr enforcement fines at glance.Information Systems, 106:101876, 2022
2022
-
[65]
Character-LLM: A trainable agent for role-playing
Yunfan Shao, Linyang Li, Junqi Dai, and Xipeng Qiu. Character-LLM: A trainable agent for role-playing. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13153– 13187, Singapore, December 2023. Association for Computational Linguistics. URLhttp s://aclantholog...
2023
-
[66]
Ai chatbots and the loneliness crisis.bmj, 391, 2025
Susan C Shelmerdine and Matthew M Nour. Ai chatbots and the loneliness crisis.bmj, 391, 2025
2025
-
[67]
Ecological momentary assessment (ema) in studies of substance use.Psy- chological assessment, 21(4):486, 2009
Saul Shiffman. Ecological momentary assessment (ema) in studies of substance use.Psy- chological assessment, 21(4):486, 2009
2009
-
[68]
Ecological momentary assessment
Saul Shiffman, Arthur A Stone, and Michael R Hufford. Ecological momentary assessment. Annu. Rev. Clin. Psychol., 4(1):1–32, 2008
2008
-
[69]
Context-aware offensive language detection in human-chatbot conversations
Mingi Shin, Hyojin Chin, Hyeonho Song, Yubin Choi, Junghoi Choi, and Meeyoung Cha. Context-aware offensive language detection in human-chatbot conversations. In2024 IEEE International Conference on Big Data and Smart Computing (BigComp), pages 270–277. IEEE, 2024. 25
2024
-
[70]
Regulation 2024/1689 of the eur
Nathalie A Smuha. Regulation 2024/1689 of the eur. parl. & council of june 13, 2024 (eu artificial intelligence act).International Legal Materials, 64(5):1234–1381, 2025
2024
-
[71]
CASE-bench: Context-aware SafEty benchmark for large language models
Guangzhi Sun, Xiao Zhan, Shutong Feng, Phil Woodland, and Jose Such. CASE-bench: Context-aware SafEty benchmark for large language models. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors,Proceedings of the 42nd International Conference on Machine Learning, volume 267 of...
2025
-
[72]
On the safety of conversational models: Taxonomy, dataset, and benchmark
Hao Sun, Guangxuan Xu, Jiawen Deng, Jiale Cheng, Chujie Zheng, Hao Zhou, Nanyun Peng, Xiaoyan Zhu, and Minlie Huang. On the safety of conversational models: Taxonomy, dataset, and benchmark. InFindings of the Association for Computational Linguistics: ACL 2022, pages 3906–3923, 2022
2022
-
[73]
New version of davies-bouldin index for clustering validation based on cylindrical distance
Juan Carlos Rojas Thomas, Matilde Santos Pe˜ nas, and Marco Mora. New version of davies-bouldin index for clustering validation based on cylindrical distance. In2013 32nd International Conference of the Chilean Computer Science Society (SCCC), pages 49–53. IEEE, 2013
2013
-
[74]
Rolellm: Benchmarking, elic- iting, and enhancing role-playing abilities of large language models
Noah Wang, Zy Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, et al. Rolellm: Benchmarking, elic- iting, and enhancing role-playing abilities of large language models. InFindings of the Association for Computational Linguistics ACL 2024, pages 14743–14777, 2024
2024
-
[75]
Coser: Coordinating llm-based per- sona simulation of established roles
Xintao Wang, Heng Wang, Yifei Zhang, Xinfeng Yuan, Rui Xu, Jen-tse Huang, Siyu Yuan, Haoran Guo, Jiangjie Chen, Shuchang Zhou, et al. Coser: Coordinating llm-based per- sona simulation of established roles. InForty-second International Conference on Machine Learning, 2025
2025
-
[76]
An improved index for clustering validation based on silhou- ette index and calinski-harabasz index
Xu Wang and Yusheng Xu. An improved index for clustering validation based on silhou- ette index and calinski-harabasz index. InIOP Conference Series: Materials Science and Engineering, volume 569, page 052024. IOP Publishing, 2019
2019
-
[77]
Crafting customisable characters with LLMs: A persona-driven role-playing agent framework
Bohao Yang, Dong Liu, Chenghao Xiao, Kun Zhao, Chen Tang, Chao Li, Lin Yuan, Yang Guang, and Chenghua Lin. Crafting customisable characters with LLMs: A persona-driven role-playing agent framework. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 20216–20240, Suzhou, China, November 2025. Association for Compu- tational Lingu...
-
[78]
Alleviating the fear of losing alignment in llm fine-tuning
Kang Yang, Guanhong Tao, Xun Chen, and Jun Xu. Alleviating the fear of losing alignment in llm fine-tuning. In2025 IEEE Symposium on Security and Privacy (SP), pages 2152–
-
[79]
In33rd USENIX Security Symposium (USENIX Security 24), pages 4657–4674, 2024
Jiahao Yu, Xingwei Lin, Zheng Yu, and Xinyu Xing.{LLM-Fuzzer}: Scaling assessment of large language model jailbreaks. In33rd USENIX Security Symposium (USENIX Security 24), pages 4657–4674, 2024
2024
-
[80]
Exploring parent-child perceptions on safety in generative ai: concerns, mitigation strategies, and design implications
Yaman Yu, Tanusree Sharma, Melinda Hu, Justin Wang, and Yang Wang. Exploring parent-child perceptions on safety in generative ai: concerns, mitigation strategies, and design implications. In2025 IEEE Symposium on Security and Privacy (SP), pages 2735–
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.