DistilledGemma: Balanced Efficiency-Accuracy for Person-Place Relation Extraction from Multilingual Historical Articles
Pith reviewed 2026-06-30 07:57 UTC · model grok-4.3
The pith
Distilling from a 26B teacher to a 2.3B student preserves strong reasoning for person-place relation extraction from historical articles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By distilling knowledge from the 26B teacher to the 2.3B student, we preserved strong reasoning capabilities while reducing the deployed model size to approximately 2.3B effective parameters; this configuration ranked 2nd in the balanced efficiency-accuracy profile across both the standard and binary test sets.
What carries the argument
The three-stage response-level knowledge distillation pipeline that transfers chain-of-thought traces generated by the QLoRA-tuned 26B teacher into the compact student model.
If this is right
- Knowledge distillation supplies a practical route to competitive performance on multilingual historical relation extraction at far lower inference cost.
- The merged student model can be deployed for large-scale processing of English, German, and French newspaper archives without excessive compute.
- The method demonstrates that response-level transfer of reasoning patterns works for this specific extraction task.
- High rankings in both standard and binary evaluations indicate the approach balances accuracy and efficiency effectively.
Where Pith is reading between the lines
- The same distillation steps could be reused on other information-extraction problems that involve historical or multilingual text.
- Performance differences across the three languages might reveal whether trace quality varies by language and could be measured directly on held-out data.
- Iterating the process with an ensemble of teachers might further improve the student without increasing its final size.
- If the task definition changes to include additional relation types, the same pipeline could be re-run to test transfer of the new reasoning patterns.
Load-bearing premise
The silver-standard chain-of-thought traces generated by the 26B teacher model are sufficiently accurate and transferable that response-level distillation into the 2.3B student will retain the teacher's reasoning quality on the unseen test articles.
What would settle it
Evaluating the 2.3B student model in isolation on the official test sets and obtaining mean scores substantially below 0.688 on the standard set or 0.8156 on the binary set would show that the distillation failed to preserve the claimed reasoning capabilities.
Figures
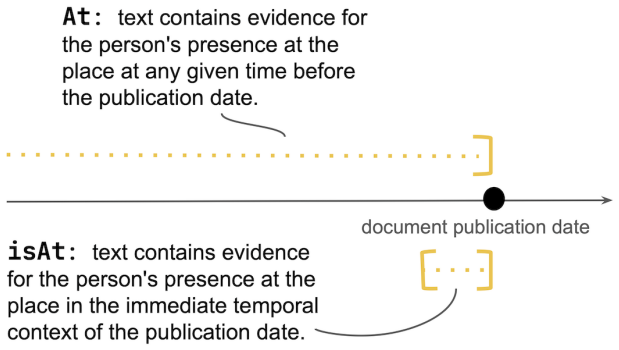
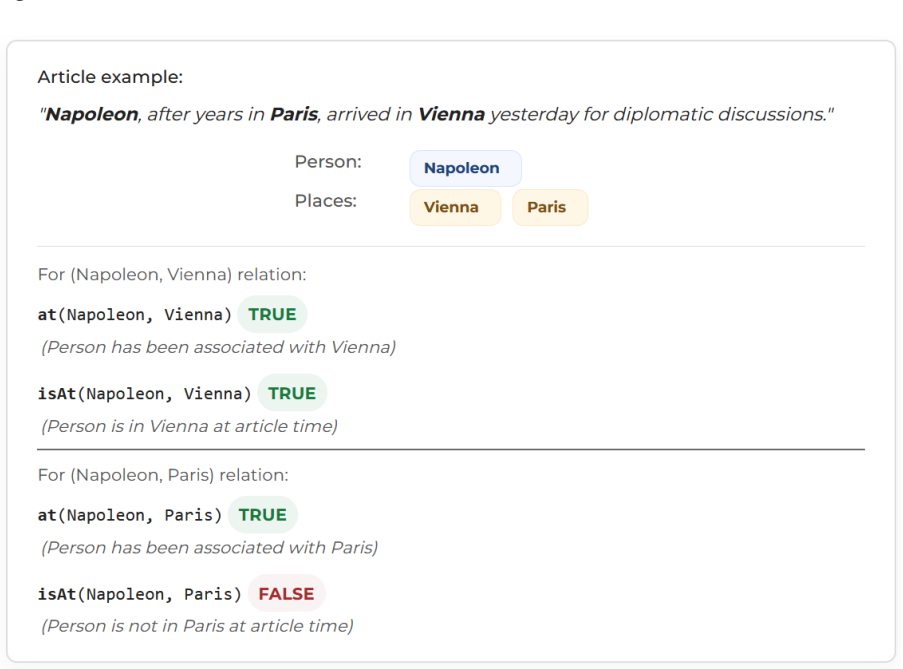
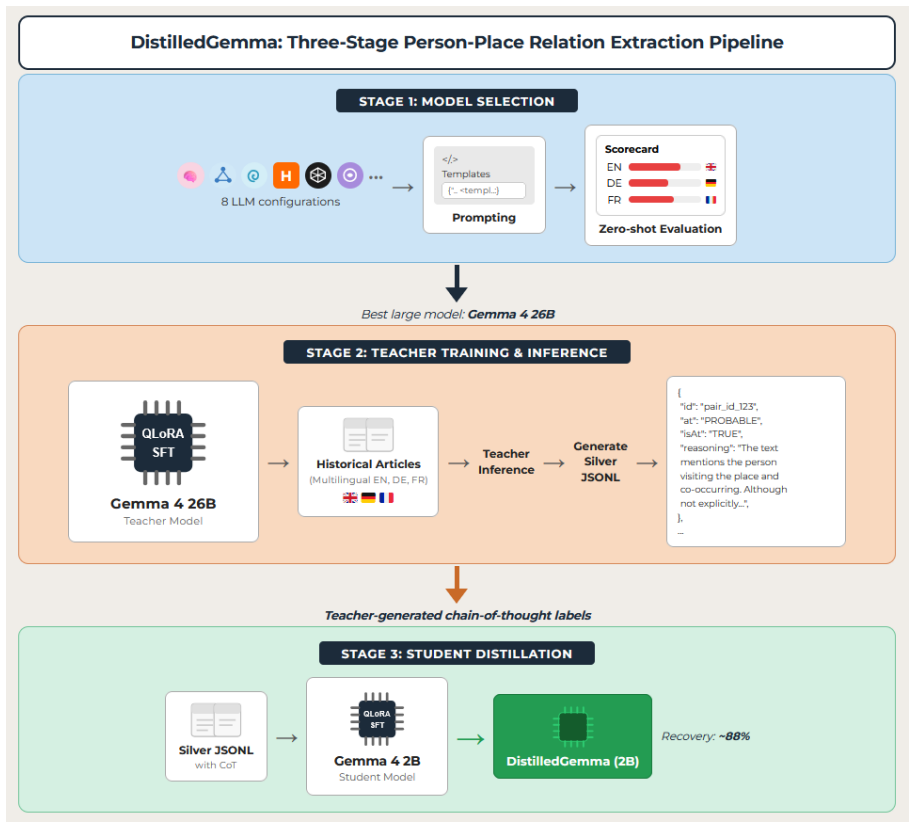
read the original abstract
We present DistilledGemma, an efficient and accurate system for the HIPE-2026 shared task on person-place relation extraction from multilingual historical newspaper articles in English, German, and French. Our approach adopts a three-stage knowledge distillation pipeline designed to balance classification accuracy with computational efficiency. In the first stage, we systematically explored prompt engineering strategies across eight large language models to identify the most effective reasoning architecture for this challenging task. In the second stage, we applied supervised fine-tuning (SFT) via QLoRA to a Gemma 4 26B A4B teacher model, leveraging its strong multilingual capabilities to generate silver-standard chain-of-thought traces across the training corpus. In the final stage, we performed response-level distillation to transfer these learned reasoning patterns into a compact Gemma 4 E2B student model. In the official evaluation, our team WHEREAMI ranked 3rd on the standard test set with an accuracy profile mean score of 0.688, and 2nd on the binary test set with a mean score of 0.8156. Notably, by distilling knowledge from the 26B teacher to the 2.3B student, we preserved strong reasoning capabilities while reducing the deployed model size to approximately 2.3B effective parameters; the LoRA adapters used during training were merged into the student for inference. This configuration ranked 2nd in the balanced efficiency-accuracy profile across both the standard and binary test sets. These results demonstrate that knowledge distillation provides a practical and scalable solution for historical document processing, achieving competitive performance without excessive computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents DistilledGemma, a three-stage knowledge-distillation pipeline for the HIPE-2026 shared task on person-place relation extraction from multilingual (English, German, French) historical newspaper articles. It first explores prompt engineering across eight LLMs, then applies QLoRA-based SFT to a 26B Gemma-4 teacher to generate silver-standard chain-of-thought traces, and finally performs response-level distillation into a 2.3B Gemma-4 student. The resulting system (team WHEREAMI) ranked 3rd on the standard test set (mean accuracy 0.688) and 2nd on the binary test set (mean 0.8156), placing 2nd overall in the balanced efficiency-accuracy profile while deploying only ~2.3B effective parameters after merging LoRA adapters.
Significance. If the central preservation claim holds, the work supplies a concrete, reproducible demonstration that response-level distillation can transfer multilingual reasoning patterns from a large teacher to a compact student for a low-resource historical-document task, achieving competitive shared-task rankings at substantially reduced inference cost. This would be useful for practitioners needing deployable models on historical corpora where both accuracy and efficiency matter.
major comments (1)
- [Abstract] Abstract and method description (second and third stages): the claim that distillation 'preserved strong reasoning capabilities' is load-bearing for the paper's contribution yet unsupported, because no teacher-model accuracy figures are reported on either the standard or binary test sets, no teacher-vs-student comparison on validation data is given, and no metric of CoT fidelity on unseen articles is supplied. Without these, the student's ranking cannot be attributed to transferred reasoning rather than the student simply fitting the silver labels.
minor comments (2)
- [Abstract] The abstract states that eight LLMs were evaluated for prompt engineering but neither names the models nor reports the selection criteria or per-model scores; adding a small table or appendix entry would clarify the first-stage design choices.
- No mention is made of whether the silver CoT traces were filtered or post-edited before distillation; a brief statement on trace quality control would strengthen reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger empirical support behind the distillation claims. We address the single major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description (second and third stages): the claim that distillation 'preserved strong reasoning capabilities' is load-bearing for the paper's contribution yet unsupported, because no teacher-model accuracy figures are reported on either the standard or binary test sets, no teacher-vs-student comparison on validation data is given, and no metric of CoT fidelity on unseen articles is supplied. Without these, the student's ranking cannot be attributed to transferred reasoning rather than the student simply fitting the silver labels.
Authors: We agree the current abstract phrasing overstates the evidence for reasoning transfer. The 26B teacher was not evaluated on the official test sets (computational cost and shared-task submission rules focused on the student system). We will revise the abstract to remove the 'preserved strong reasoning capabilities' claim, replacing it with a factual statement that the distillation pipeline produced a competitive student model. In the methods and results sections we will add (i) teacher vs. student accuracy on the validation split and (ii) a simple CoT fidelity metric (exact match of generated reasoning steps on a held-out validation sample) where these data exist. This is a partial revision because teacher test-set numbers cannot be supplied retroactively. revision: partial
Circularity Check
No circularity: pure empirical system report with external shared-task ranking
full rationale
The paper describes a three-stage empirical pipeline (prompt exploration, SFT on 26B teacher for silver CoT generation, response-level distillation to 2.3B student) and reports official HIPE-2026 rankings (3rd/2nd). No equations, no fitted parameters renamed as predictions, no self-citations invoked as uniqueness theorems, and no derivation chain that reduces any claim to its own inputs by construction. The 'preserved reasoning' assertion is an empirical interpretation of external test-set scores rather than a self-referential definition or statistical forcing. This matches the default expectation of a non-circular empirical report.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Opitz, C
J. Opitz, C. Raclé, E. Boros, A. Michail, M. Romanello, M. Ehrmann, S. Clematide, Clef hipe-2026: Evaluating accurate and efficient person–place relation extraction from multilingual historical texts, in: European Conference on Information Retrieval, Springer, 2026, pp. 354–363
2026
-
[2]
Opitz, C
J. Opitz, C. Raclé, A. Michail, M. Romanello, M. Ehrmann, S. Clematide, Overview of HIPE-2026: Person– Place Relation Extraction from Multilingual Historical Texts, in: M. Hagen, M. Potthast, B. Stein, P. Schaer, E. Zangerle, S. MacAvaney, J. M. Struß, E. Sánchez Salido, A. Barrón-Cedeño, A. García Seco de Herrera (Eds.), Experimental IR Meets Multilingua...
2026
-
[3]
Opitz, C
J. Opitz, C. Raclé, A. Michail, M. Romanello, E. Boros, S. Gabay, M. Ehrmann, S. Clematide, Extended Overview of HIPE-2026: Evaluating Accurate and Efficient Person–Place Relation Extraction from Multilingual Historical Texts, in: E. Sánchez Salido, A. Barrón-Cedeño, A. García Seco de Herrera, S. MacAvaney, J. M. Struß (Eds.), CLEF 2026 Working Notes, CEU...
2026
-
[4]
Wadhwa, S
S. Wadhwa, S. Amir, B. C. Wallace, Revisiting relation extraction in the era of large language models, in: Annual Meeting of the Association for Computational Linguistics, 2023
2023
-
[5]
Z. Wan, F. Cheng, Z. Mao, Q. Liu, H. Song, J. Li, S. Kurohashi, Gpt-re: In-context learning for relation extraction using large language models, in: EMNLP, 2023
2023
-
[6]
Y. Zhang, V. Zhong, D. Chen, G. Angeli, C. D. Manning, Position-aware attention and supervised data improve slot filling, in: M. Palmer, R. Hwa, S. Riedel (Eds.), Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Copenhagen, Denmark, 2017, pp. 35–45. URL: https://aclanthology...
-
[7]
Pathak, P
D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, A. A. Efros, Context encoders: Feature learning by inpainting, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2536–2544
2016
-
[8]
L. Baldini Soares, N. FitzGerald, J. Ling, T. Kwiatkowski, Matching the blanks: Distributional similarity for relation learning, in: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, 2019, pp. 2895–2905. URL: https://aclanthology.org/ P19-1279/. doi:10.18653/v1/P19-1279
-
[9]
W. Zhou, M. Chen, An improved baseline for sentence-level relation extraction, in: Y. He, H. Ji, S. Li, Y. Liu, C.-H. Chang (Eds.), Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Association f...
-
[10]
D. Ye, Y. Lin, P. Li, M. Sun, Packed levitated marker for entity and relation extraction, in: S. Muresan, P. Nakov, A. Villavicencio (Eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Dublin, Ireland, 2022, pp. 4904–4917. URL: https://aclanthol...
-
[11]
A. Conneau, K. Khandelwal, N. Goyal, V. Chaudhary, G. Wenzek, F. Guzmán, E. Grave, M. Ott, L. Zettlemoyer, V. Stoyanov, Unsupervised cross-lingual representation learning at scale, in: D. Jurafsky, J. Chai, N. Schluter, J. Tetreault (Eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Association for Computation...
-
[12]
R. Ri, I. Yamada, Y. Tsuruoka, mLUKE: The power of entity representations in multilingual pretrained language models, in: S. Muresan, P. Nakov, A. Villavicencio (Eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Dublin, Ireland, 2022, pp. 7316–...
2022
-
[13]
Y. Yao, D. Ye, P. Li, X. Han, Y. Lin, Z. Liu, Z. Liu, L. Huang, J. Zhou, M. Sun, DocRED: A large-scale document- level relation extraction dataset, in: A. Korhonen, D. Traum, L. Màrquez (Eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, 2019, pp. 764–...
-
[14]
A. Plum, T. Ranasinghe, C. Purschke, Guided distant supervision for multilingual relation extraction data: Adapting to a new language, in: N. Calzolari, M.-Y. Kan, V. Hoste, A. Lenci, S. Sakti, N. Xue (Eds.), Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), ELRA and ...
2024
-
[15]
X. Xu, X. Chen, N. Zhang, X. Xie, X. Chen, H. Chen, Towards realistic low-resource relation extraction: A benchmark with empirical baseline study, in: Y. Goldberg, Z. Kozareva, Y. Zhang (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2022, Association for Computational Linguistics, Abu Dhabi, United Arab Emirates, 2022, pp. 413–42...
-
[16]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. V. Le, D. Zhou, Chain-of-thought prompting elicits reasoning in large language models, in: S. Koyejo, S. Mohamed, A. Agarwal, D. Bel- grave, K. Cho, A. Oh (Eds.), Advances in Neural Information Processing Systems, volume 35, Curran Associates, Inc., 2022, pp. 24824–24837. URL: https:/...
2022
-
[17]
Ehrmann, M
M. Ehrmann, M. Romanello, A. Flückiger, S. Clematide, HIPE-2022: Evaluation of named entity processing and entity linking in historical newspapers and classical commentaries, in: Proceedings of the Second Workshop on Language Technologies for Historical and Ancient Languages (LT4HALA 2022), European Language Resources Association, 2022
2022
-
[18]
Ehrmann, M
M. Ehrmann, M. Romanello, S. Najem-Meyer, A. Doucet, S. Clematide, Extended overview of HIPE-2022: Named entity recognition and linking in multilingual historical documents, in: Experimental IR Meets Multilinguality, Multimodality, and Interaction, Springer, 2023
2022
-
[19]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, J. Dean, Distilling the knowledge in a neural network, 2015. URL: https://arxiv.org/ abs/1503.02531.arXiv:1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[20]
Y. Kim, A. M. Rush, Sequence-level knowledge distillation, in: J. Su, K. Duh, X. Carreras (Eds.), Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Austin, Texas, 2016, pp. 1317–1327. URL: https://aclanthology.org/D16-1139/. doi:10.18653/ v1/D16-1139
2016
-
[21]
V. Sanh, L. Debut, J. Chaumond, T. Wolf, Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter, 2020. URL: https://arxiv.org/abs/1910.01108.arXiv:1910.01108
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[22]
Y. Gu, L. Dong, F. Wei, M. Huang, Minillm: Knowledge distillation of large language models, in: International Conference on Learning Representations, volume 2024, 2024, pp. 32694–32717
2024
-
[23]
Agarwal, N
R. Agarwal, N. Vieillard, Y. Zhou, P. Stanczyk, S. Ramos Garea, M. Geist, O. Bachem, On-policy distillation of language models: Learning from self-generated mistakes, in: International Conference on Learning Representations, volume 2024, 2024, pp. 21246–21263
2024
-
[24]
C.-Y. Hsieh, C.-L. Li, C.-k. Yeh, H. Nakhost, Y. Fujii, A. Ratner, R. Krishna, C.-Y. Lee, T. Pfister, Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes, in: Findings of the Association for Computational Linguistics: ACL 2023, Association for Computational Linguistics, 2023, pp. 8003–8017. URL: ht...
-
[25]
Orca: Progressive Learning from Complex Explanation Traces of GPT-4
S. Mukherjee, A. Mitra, G. Jawahar, S. Agarwal, H. Palangi, A. Awadallah, Orca: Progressive learning from complex explanation traces of GPT-4, arXiv preprint arXiv:2306.02707 (2023). URL: https://arxiv.org/abs/ 2306.02707. doi:10.48550/arXiv.2306.02707
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.02707 2023
-
[26]
Rafailov, A
R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, C. Finn, Direct preference op- timization: Your language model is secretly a reward model, in: Advances in Neural Informa- tion Processing Systems, volume 36, 2023. URL: https://papers.nips.cc/paper_files/paper/2023/hash/ a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html
2023
-
[27]
M. Choi, H. Lim, J. Choo, PRiSM: Enhancing low-resource document-level relation extraction with relation- aware score calibration, in: Findings of the Association for Computational Linguistics: IJCNLP-AACL 2023 (Findings), Association for Computational Linguistics, 2023, pp. 39–47. URL: https://aclanthology.org/2023. findings-ijcnlp.4/. doi:10.18653/v1/20...
-
[28]
E. J. Hu, Y. Shen, P. Wallis, Z. Allen-Zhu, Y. Li, S. Wang, L. Wang, W. Chen, LoRA: Low-rank adaptation of large language models, in: International Conference on Learning Representations (ICLR), 2022
2022
-
[29]
QLoRA: Efficient Finetuning of Quantized LLMs
T. Dettmers, A. Pagnoni, A. Holtzman, L. Zettlemoyer, Qlora: Efficient finetuning of quantized llms, 2023. URL: https://arxiv.org/abs/2305.14314.arXiv:2305.14314
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Google, gemma-4-e2b-it: Instruction-tuned 2.3b parameter model, https://huggingface.co/google/ gemma-4-E2B-it, 2026
2026
-
[31]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
M. A. Team, Ministral 3: A family of efficient small language models, arXiv preprint arXiv:2601.08584 (2026). URL: https://arxiv.org/abs/2601.08584
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [33]
-
[34]
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, I. Stoica, Efficient memory management for large language model serving with pagedattention, in: Proceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[35]
URL: https://ai.google.dev/gemma/docs/ core/model_card_4, accessed: May 27, 2026
Google DeepMind, Gemma 4: Open models for edge devices, 2026. URL: https://ai.google.dev/gemma/docs/ core/model_card_4, accessed: May 27, 2026
2026
-
[36]
Sokolova, G
M. Sokolova, G. Lapalme, A systematic analysis of performance measures for classification tasks, Information processing & management 45 (2009) 427–437
2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.